한글데이터 사용하기 위한 환경설정
-
환경 변수 설정
-파이썬에서 자바 기능 사용하기 위해 자바 관련 환경 변수 설정
-window키 > 시스템 환경 변수 편집 -
가상환경 만들기
-window > anaconda prompt
-conda create -n konlpy python=3.8
: konlpy 라는 이름의 가상환경 생성
: python 버전은 3.8-activate konlpy
: konlpy 환경 접근하기-conda env list
: 접근 가능한 환경 리스트 보여주기-pip install scikit-learn pandas numpy matplotlib jupyter
: 필요한 라이브러리 설치-jupyter notebook
: jupyter notebook 실행하기
기초
!pip install JPype1-1.1.2-cp38-cp38-win_amd64.whl
- 한글 형태소 분류기
!pip install konlpy
from konlpy.tag import Okt, Kkmaokt = Okt()
kkma = Kkma()okt.morphs('아버지가방에들어가신다')
kkma.morphs('아버지가방에들어가신다')
- 구분 가능한 형태소
okt.tagset
kkma.tagset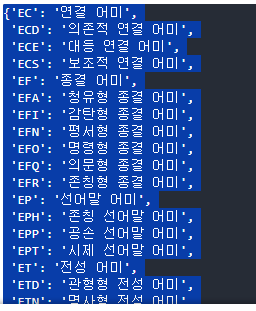
kkma.pos('아버지가방에들어가신다')
- 기존방법
# BOW(countVectorizer)를 사용해서 글자의 빈도를 세어서 사용
# 띄어쓰기를 기준으로 글자를 나눴다.- 기존방법 + konlpy(한글 형태소 분류기)
# BOW(countVectorizer)를 사용해서 글자의 빈도를 세어서 사용
# konlpy를 기준으로 글자를 나눈다.from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Okttext = [
'수고했어요~ 날 추우니까 다들 따뜻하게 입고다니고 집에 조심히들 가요~',
'그리고 지각 그만해요 이번주 지각 자들은 목요일에 나랑 이야기할꺼니까~',
'다들 종례 시트 확인하시고 당번들은 잘진행하세용~'
]textBow = CountVectorizer()
okt = Okt()textBow.fit(text)
- Bow만 사용해서 단어사전 구축하기
textBow.vocabulary_
- okt로 형태소 분류하기
-morphs
def myTokenizer(text) :
# 모든 형태소 구분하기
return okt.morphs(text)
# okt + Bow
test_bow_okt = CountVectorizer(tokenizer=myTokenizer)test_bow_okt.fit(text)
# okt + Bow의 단어사전
test_bow_okt.vocabulary_
-nouns
def myTokenizer(text) :
# 모든 형태소 구분하기
# return okt.morphs(text)
# 명사만 추출하기
return okt.nouns(text)
# okt + Bow
test_bow_okt = CountVectorizer(tokenizer=myTokenizer)test_bow_okt.fit(text)
# okt(명사만 추출) + Bow의 단어사전
test_bow_okt.vocabulary_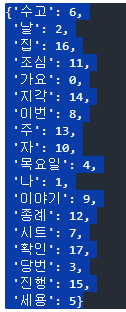
ex09_네이버 영화 리뷰 분석
- 문제정의

- 데이터 수집
import pandas as pd
text_train = pd.read_csv('ratings_train.txt', delimiter='\t')
text_test = pd.read_csv('ratings_test.txt', delimiter='\t')text_train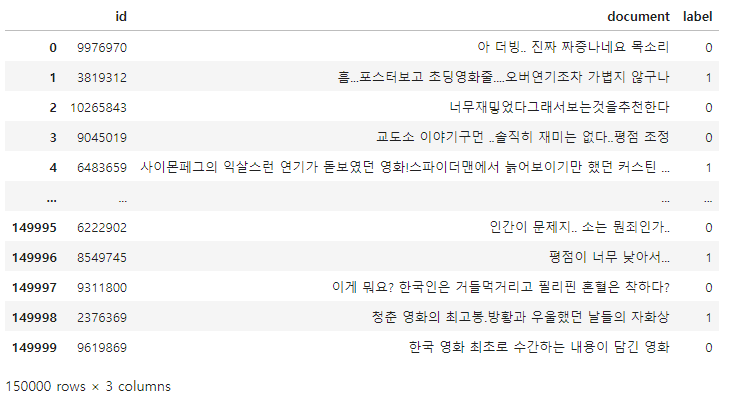
text_train.shape, text_test.shape
- 데이터 전처리
- train
text_train.info()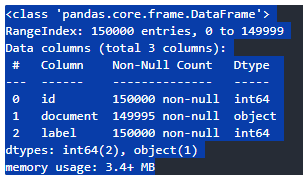
- test
text_test.info()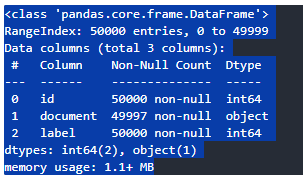
- 결측치 삭제
# train → 5개의 결측치 삭제
# test → 3개의 결측치 삭제
# 결측치를 가지고 있는 행을 삭제
text_train.dropna(inplace=True)
text_test.dropna(inplace=True)- 확인하기
# 추가적인 전처리를 진행한다고 하면
# 정규 표현식을 사용해서 한글만 남기기
text_train.info()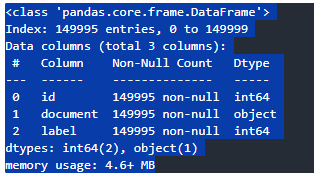
X_train = text_train['document'][:10000]
y_train = text_train['label'][:10000]
X_test = text_test['document'][:2000]
y_test = text_test['label'][:2000]-확인하기
X_train.shape, y_train.shape, X_test.shape, y_test.shape
- 한글 형태소 구분하기
from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Kkmakkma = Kkma()- 명사만 추출하는 토큰화 도구 생성
def myTokenizer(text) :
return kkma.nouns(text)bow_kkma = CountVectorizer(tokenizer=myTokenizer)
bow_kkma.fit(X_train) # 단어사전 구축
X_train = bow_kkma.transform(X_train)
X_test = bow_kkma.transform(X_test)len(bow_kkma.vocabulary_)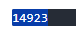
X_train
- TFIDF 토큰화 사용하기
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(tokenizer=myTokenizer)
X_train = text_train['document'][:10000]
X_test = text_test['document'][:2000]
tfidf.fit(X_train)
X_train = tfidf.transform(X_train)
X_test = tfidf.transform(X_test)- 탐색적 데이터 분석

- 모델 선택 및 하이퍼 파라미터 튜닝
from sklearn.linear_model import LogisticRegression- 학습
lr = LogisticRegression()
lr.fit(X_train,y_train)
- 평가
- train
# bow + kkma
lr.score(X_train, y_train)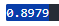
# tfidf + kkma
# 결과가 다소 안좋아짐
# 리뷰데이터는 하나의 문서가 하나의 리뷰 → 문서 자체의 데이터가 크지 않아서 의미가 다소 떨어짐
lr.score(X_train, y_train)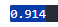
- test
# bow + kkma
lr.score(X_test, y_test)
# tfidf + kkma
lr.score(X_test, y_test)
- pipeline으로 tfidf + kkma + logisticRegression
from sklearn.pipeline import make_pipeline
pipe_model = make_pipeline(
TfidfVectorizer(tokenizer=myTokenizer),
LogisticRegression()
)
text_train = text_train['document'][:10000]
text_test = text_test['document'][:2000]
pipe_model.fit(text_train, y_train)
pipe_model.predict(['영화재미있어요'])
pipe_model.steps
tfidf = pipe_model.steps[0][1]
logi = pipe_model.steps[1][1]voca = tfidf.vocabulary_
df = pd.DataFrame([voca.keys(), voca.values()])
df.head()
- 전치
voca = tfidf.vocabulary_
df = pd.DataFrame([voca.keys(), voca.values()])
# 데이터프레임 가로세로 변경하기 → 전치
df = df.T
df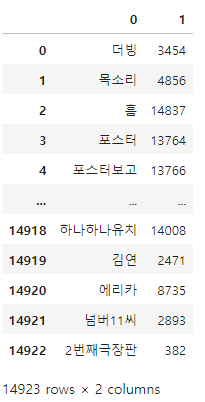
- 1번열 기준으로 정렬
voca = tfidf.vocabulary_
df = pd.DataFrame([voca.keys(), voca.values()])
# 데이터프레임 가로세로 변경하기 → 전치
df = df.T
# 1번 열(단어사전에 등록된 단어의 번호) 기준으로 정렬
df_sorted = df.sort_values(by = 1)
df_sorted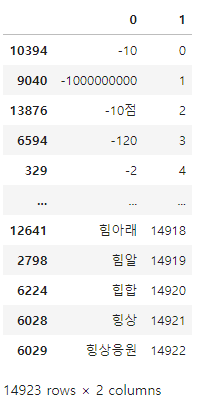
- 가중치 컬럼 추가하기
voca = tfidf.vocabulary_
df = pd.DataFrame([voca.keys(), voca.values()])
# 데이터프레임 가로세로 변경하기 → 전치
df = df.T
# 1번 열(단어사전에 등록된 단어의 번호) 기준으로 정렬
df_sorted = df.sort_values(by = 1)
# 가중치 컬럼 추가하기
df_sorted['weight'] = logi.coef_[0]
df_sorted.head()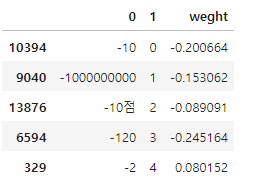
- 가중치 기준으로 정렬
voca = tfidf.vocabulary_
df = pd.DataFrame([voca.keys(), voca.values()])
# 데이터프레임 가로세로 변경하기 → 전치
df = df.T
# 1번 열(단어사전에 등록된 단어의 번호) 기준으로 정렬
df_sorted = df.sort_values(by = 1)
# 가중치 컬럼 추가하기
df_sorted['weight'] = logi.coef_[0]
# 가중치 기준으로 정렬
df_sorted.sort_values(by = 'weight', inplace=True)
df_sorted.head()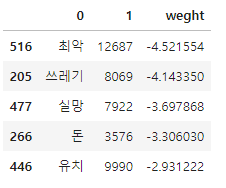
- tail
df_sorted.tail()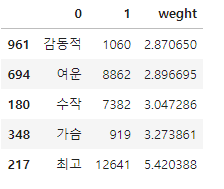
시각화하기
- 긍정/부정의 top20으로 dataframe 생성하기
top20_df = pd.concat(
[
df_sorted.head(20), df_sorted.tail(20)
]
)
top20_df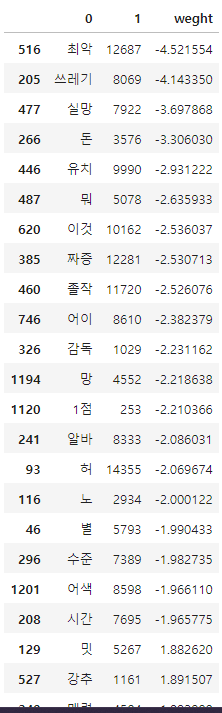
- 한글폰트 적용하기
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="C:\Windows\Fonts\malgun.ttf").get_name()
rc('font',family=font_name)- -기호 표시하기
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
# -기호 표시하기import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
plt.bar(top20_df[0], top20_df['weigth'])
plt.xticks(rotation = 90)
plt.show()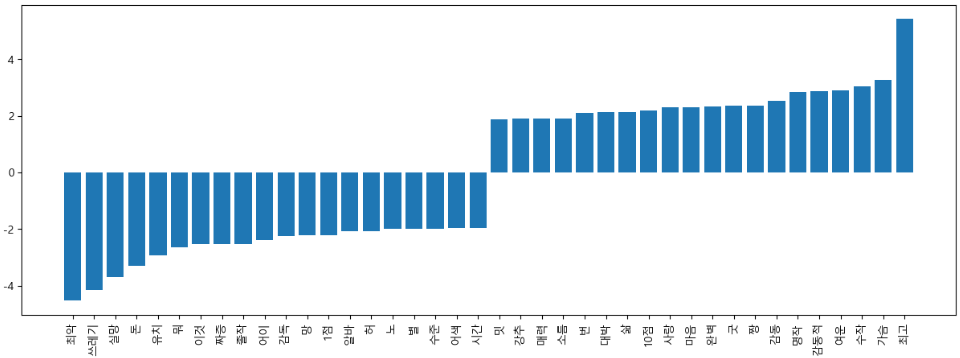

노는게 제일 좋아~!