텍스트 마이닝(Text Mining)
- 텍스트 마이닝이란?
- 텍스트 마이닝은 정형 및 비정형 데이터를 자연어 처리 방식(Natural Language Processing)과 문서처리 방법을 적용하여 유용한 정보를 추출하여 가공하는 것을 목적으로 하는 기술
- 텍스트 마이닝은 데이터로부터 유용한 인사이트를 발굴하는 데이터 마이닝(Data Mining), 언어를 정보로 변환하기 위한 자연어 처리, 정보검색 등 다양한 분야가 접목되어 발전한 학문, 기술
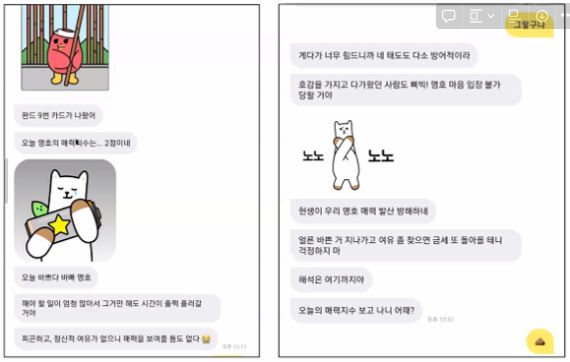
- 텍스트 마이닝 사례 - 챗봇
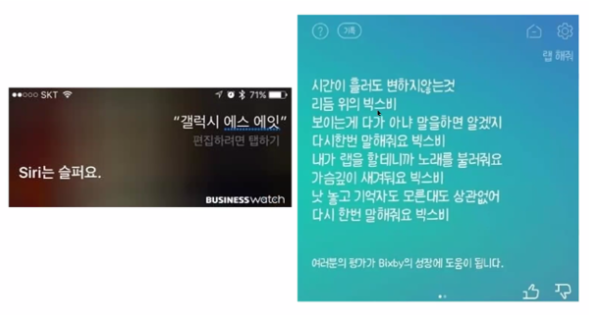
- 텍스트 마이닝 사례 - 인공지능
- 텍스티 마이닝 사례 - 기업에서의 분석 사례
1. 지식 경영(Knowledge management)
많은 양의 데이터 중 의미 있는 데이터만 뽑아내고 효율적으로 관리 할 수 있다.
2. 사이버 범죄 예방(Cybercrime prevention)
텍스트 마이닝을 이용한 범죄 예방 어플리케이션 등
3. 고객 관리 서비스(Customer care service)
고객에게 빠르고 자동화된 응답을 제공하기 위해 활용
4. 고객 클레임 분석을 통한 부정행위 탐지 (Fraud detection through claims investigation)
보험회사는 텍스트 마이닝을 통해 사기를 방지하고 빠르게 클레임을 처리
5. 콘텐츠 강화(Content enrichment)
다양한 목적에 따라 그에 적합한 내용으로 정리하고 요약
6. 소셜 미디어 데이터 분석(Social media data analysis)
해당 브랜드나 제품에 대한 다양한 의견과 감성 반응을 살펴봄
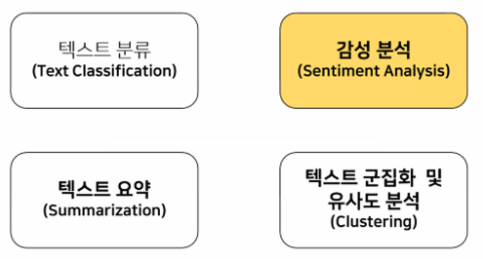
- 텍스트 마이닝 기술 영역
- 텍스트 데이터의 구조

→ 형태소 : 가장 작은 단위
→ 말뭉치(corpus) : 분석을 위해 수집된 문서들의 집합(텍스트 데이터들의 모음)- 말뭉치는 여러 개의 문서가 존재
- 문서는 여러 개의 단락으로 구성
- 단락은 여러 개의 문장으로 구성
- 문장은 여러 개의 단어로 구성
- 단어 중 여러 개의 형태소로 구성
텍스트 마이닝 분석 프로세스

- 문제정의
- 텍스트 데이터 수집 : SNS/뉴스/블로그 등 텍스트 데이터 수집
- 텍스트 전처리 : 컴퓨터가 이해하기 쉽게 텍스트를 변환하는 과정
- 토큰화 : 단어단위로 나누는 과정(텍스트 데이터의 사용 단위/텍스트 전처리 과정 후에 사용)
- 특징 값 추출 : 중요한 단어를 선별하는 과정
- 데이터 분석 : 머신러닝, 딥러닝 등 분석 모델 사용
-
텍스트 데이터 수집

- Crawling을 이용한 Web 데이터 수집(SNS/블로그/카페 등)
- 빅카인즈(BIG Kinds) 뉴스 데이터 제공 사이트
- NDSL(www.ndsl.kr) : 국내외 논문, 특허, 연구보고서 통합 정보 제공 사이트
-
텍스트 전처리

- 전처리는 용도에 맞게 텍스트를 사전에 처리하는 작업
- 궁극적으로 ‘중요한 특징 값’을 선택하는 것이 중요
- 오탈자 제거, 띄어쓰기 교정
- 불용어 제거 : 데이터에서 큰 의미가 없는 단어 제거
- 정제(cleaning) : 가지고 있는 코퍼스로부터 노이즈 데이터를
- 정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만든다.
-
토큰화

- 토큰화(tokenization) : 주어진 코퍼스(corpus, 말뭉치)에서 토큰(token)이라 불리는 단위로 나누는 작업(공백기준, 형태소기준, 명사기준)
- 기준은 분석 방법에 따라 다르다.
- 감성 분석한다면, 감성을 나타내는 품사가 동사, 형용사 쪽에 가깝기 때문에 형태소 분석기를 사용해서 동사, 형용사 위주로 추출한다.
-
특징 값 추출

- ’중요한 단어’를 선별하는 과정
- ’중요한 단어’로서의 특징은 적은 수의 문서에 분포되어 있어야 하고, 문서 내에서도 빈번하게 출현해야 한다.
- 특정 텍스트를 통해 문서를 구분 짓는 것이기 때문에 어떤 단어가 모든 문서에 분포되어 있다면 이는 차별성 없는 단어
-
데이터 분석

- 머신러닝
-Linear Regression
-Logistic Regression
-Random Forest
-XGBoost - 딥러닝
-CNN
-RNN
-LSTM
-GRU
- 머신러닝
- 토큰화(tokenize)의 종류
- 단어(word) 단위
- 글자(character) 단위
- n-gram 단위
- n-gram 단위
- n개의 연속된 단어를 하나로 취급하는 방법
- 예를 들어 “러시아 월드컵”이라는 표현을 “러시아”와 “월드컵” 두 개의 독립된 단어로만 취급하지 않고 두 단어로 구성된 하나의 토큰으로 취급한다.
- n=2경우를 bi-gram이라고도 부른다.
- 단어의 개수가 늘어난 효과를 얻는다.
-
토큰화(n-gram)
-
텍스트 : “어제 러시아에 갔다가 러시아 월드컵을 관람했다”
-
단어 토큰 : {”어제”, “러시아”, “갔다”, “월드컵”, “관람”}
2-gram 토큰 : {”어제 러시아”, “러시아 갔다”, “갔다 월드컵”, “월드컵 관람”} -
n-gram을 허용하면 토큰화 대상의 수가 크게 증가한다.
-
토큰화 한 결과를 수치로 만드는 방법
→ 원 핫(one-hot) 인코딩
→ BOW(단어모음)
→ 단어벡터(Word Vector) 방법
-
- 원핫 인코딩(one-hot) 인코딩
토큰에 고유 번호를 배정하고 모든 고유번호 위치의 한 컬러만 1, 나머지 컬럼은 0인 벡터로 표시하는 방법- 텍스트 : “어제 러시아에 갔다가 러시아 월드컵을 관람했다”
- 토큰사전 : {”어제” : 0, “러시아” : 1, “갔다” : 2, “월드컵” : 3, “관람” : 4}
어제 = {1, 0, 0, 0, 0}
러시아 = {0, 1, 0, 0, 0}
갔다 = {0. 0. 1. 0. 0}
월드컵 = {0, 0, 0, 1, 0}
관람 = {0, 0, 0, 0, 1}
- BOW(Bag Of Word, 단어모음)
”문장”을 하나의 벡터로 만드는 방법- 단어사전 : {”어제” : 0, “오늘” : 1, “미국” : 2, “러시아” : 3, “갔다” : 4, “축구” : 5, “월드컵” : 6, … , “중국” : 4999}
- Text_1 : “어제 러시아에 갔다가 러시아 월드컵을 관람했다”를 BOW로 표현(문장에 들어있는 단어의 컬럼만 1로 나머지 컬럼은 0으로 표현)

-
tf-idf(term frequency-inverse document frequency)
많이 나올수록 중요함 / 여러 문서에서 나오면 안중요함 -
tf란 단어가 각 문서에서 발생한 빈도 (단어가 등장한 ‘문서’의 빈도를 df라 한다.)
-
적은 문서에서 발견될수록 가치 있는 정보라고 할 수 있다.
-
많은 문서에 등장하는 단어일수록 일반적인 단어이며 이러한 공통 적인 단어는 tf가 크다고 하여도 비중을 낮추어야 분석이 제대로 이루어질 수 있다.
-
따라서 단어가 특정 문서에만 나타나는 희소성을 반영하기 위해서 idf(df의 역수)를 tf에 곱한 값을 사용한다.
-
tf(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
-
df(t) : 특정 단어 t가 등장한 문서의 수
-
idf(t) : df(t)에 반비례하는 수
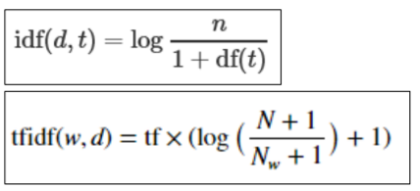
— TFIDF 방법론
-
많이 나왔는가 → 각 문서에서 발생한 빈도
-
문서에서 단어가 발생한 빈도 → 전체 문서 중에서 해당 단어가 들어가있는 문서의 수
→ 역수를 사용 → 적은 문서에서 발견될수록 가치있는 정보다 -
1번 값과 2번값을 곱해서 큰 수가 나올수록 중요한 단어

- prompt에서 base 말고 konlpy로 변경해서 jupyter notebook 열기
- conda env list
→ 생성 되어있는 가상 환경 확인 - activate konlpy
→ konlpy라는 환경에 접속하기 - jupyter notebook
→ jupyter notebook 열기
- conda env list
실습
- 문제정의

- 문제정의
- 데이터 수집

- 데이터 수집
-여러 개 파일을 한 번에 읽어오는 함수
from sklearn.datasets import load_filestrain_data_url = 'aclImdb/train'
test_data_url = 'aclImdb/test'reviews_train = load_files(train_data_url, shuffle=True)
reviews_train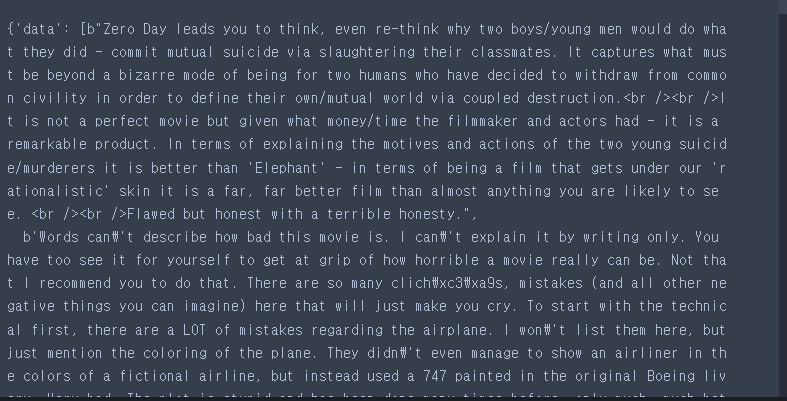
reviews_test = load_files(test_data_url, shuffle=True)
reviews_test
reviews_train.keys()
-b가 붙어있는 문자열 = 바이트 자료형
reviews_train['data'][0]
-train 데이터 : 25000개
len(reviews_train['data'])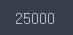
-test 데이터 : 25000개
len(reviews_test['data'])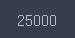
-정답 데이터 비율 확인
import numpy as np
np.bincount(reviews_train['target'])
# 데이터의 갯수는 고르게 분포해있는게 좋다.
# 한쪽에 치우쳐져 있으면 모델이 규칙을 잘 찾지 못함
reviews_train['target_names']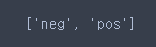
- 데이터 전처리

- 데이터 전처리
reviews_train['data'][0].replace(b'<br />', b' ')
# 리스트 내포
# 리스트 안에서 다양한 작업을 포함
text_train = [txt.replace(b"<br />", b" ") for txt in reviews_train['data']]
text_test = [txt.replace(b"<br />", b" ") for txt in reviews_test['data']]text_train = text_train[:5000]
text_test = text_test[:2000]
y_train = reviews_train['target'][:5000]
y_test = reviews_test['target'][:2000]# 토큰화 (BOW)
# 띄어쓰기를 기준으로 데이터를 나누기
# BOW = CountVectorizer
# 나온 단어의 갯수를 세어준다from sklearn.feature_extraction.text import CountVectorizertest_bow = CountVectorizer()text = [
'수고했어요~ 날 추우니까 다들 따뜻하게 입고다니고 집에 조심히들 가요~',
'그리고 지각 그만해요 이번주 지각 자들은 목요일에 나랑 이야기할꺼니까~',
'다들 종례 시트 확인하시고 당번들은 잘진행하세용~'
]# 띄어쓰기 기준으로 데이터를 나눴을 때 중복 제거하고 어떤 단어들이 있는지 파악
# = 단어사전 구축
test_bow.fit(text)
-단어사전 확인하기
# 숫자는 가나다 순으로 결정
# 배치된 순서는 문자열의 순서
test_bow.vocabulary_
transform = test_bow.transform(text)
transform
transform.toarray()
-실제 데이터 적용
movie_bow = CountVectorizer()
movie_bow.fit(text_train)
X_train = movie_bow.transform(text_test)
X_test = movie_bow.transform(text_test)-단어사전 확인하기
len(movie_bow.vocabulary_)
-세부조정하기
# min_df : 단어사전에 등록하기 위한 단어의 최소 등장 횟수
# max_df : 단어사전에 등록하기 위한 단어의 최대 등장 횟수
# ngram_range : 띄어쓰기 한 번이 기준이 아니라 2번 이상도 기준이 됨
movie_bow = CountVectorizer(min_df=20, max_df=500, ngram_range=(1, 2))
movie_bow.fit(text_train)
X_train = movie_bow.transform(text_train)
X_test = movie_bow.transform(text_test)-단어사전 확인하기
len(movie_bow.vocabulary_)
-
- 탐색적 데이터 분석

- 탐색적 데이터 분석
-
- 모델 선택 및 하이퍼 파리미터 튜닝
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import LinearSVCdt = DecisionTreeClassifier()
svm = LinearSVC()-교차검증
# 여러 모델 사용해보고 결과 좋은 모델 찾을 때 사용하기도 함
from sklearn.model_selection import cross_val_score-dt
cross_val_score(dt, X_train, y_train, cv=5)
-svm
cross_val_score(svm, X_train, y_train, cv=5)
- 학습
svm.fit(X_train, y_train)
- 예측 및 평가
-train
- 예측 및 평가
svm.score(X_train, y_train)
-test
svm.score(X_test, y_test)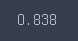
-세부조정하고 학습하고 예측 및 평가하면
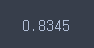
- 긍정
# 예측하기 위한 데이터에도 기존 전처리를 전부 진행해야함
# 1. 데이터 형식을 맞추기 위해서
# 2. 머신러닝 학습엔 숫자데이터만 가능
# 3. 기존 방법이 아닌 다른 방법으로 전처리를 진행하면 데이터의 의미가 달라짐
reviews = ['This movie so good'] # 긍정# br태그 제거
text_pred = [txt.replace("<br />", " ") for txt in reviews]
# bow → 토큰화하기
X_pred = movie_bow.transform(text_pred)# 0 : 부정, 1 : 긍정
svm.predict(X_pred)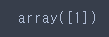
- 부정
# 부정
reviews = [''' ( SPOILERS) Absolute garbage and a waste of time. Full of plot twists that end up being nothing. Vision having holes in his body had nothing to do with the plot. Pietro having holes in his body had nothing to do with the plot. Pietro being from X'men was just a random coincidence. Also, every time a new male character walked into the show you knew he was either a wimp or evil. They even made pietros real last name "bohner" to make fun of manhood. Imagine if a female character everyone was stoked on turned out to be some random lady named "Vachina". Also, the physical vision just flew off for no reason, and digital vision never decided to tell wanda about his existence. Why? Lazy writing. Additionally at the end rhambeaou tells wanda "they will never know what you sacrificed". What the heck?! Like maybe apologize for trapping and tormenting these people every day for like a month. How on earth is wanda the victim or the "good-guy" in this show. She is literally a villain causing everyone pain, but it is "ok" because she did it out of a place of pain. Im sorry, almost all villains do evil out of a place of pain, that doesnt make it ok. Stupid, sexist show with bad plot that treats its audience like idiots. ''']# br태그 제거
text_pred = [txt.replace("<br />", " ") for txt in reviews]
# bow → 토큰화하기
X_pred = movie_bow.transform(text_pred)# 0 : 부정, 1 : 긍정
svm.predict(X_pred)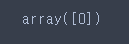
- 긍정과 부정에 영향을 많이 끼친 단어 알아보기
# 단어가 나온 순서대로 나열
voca = movie_bow.vocabulary_- 단어별 가중치
# 0번 단어부터 38955개까지 차례대로 나열
word_weight = svm.coef_len(word_weight[0])import pandas as pd
# 단어사전을 번호 기준으로 정렬
df = pd.DataFrame([voca.keys(), voca.values()])
df = df.T # 행과 열 바꾸기
df.head()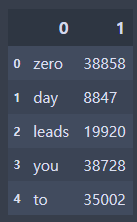
- 1 이름을 갖는 열(컬럼)을 기준으로 정렬
df_sorted = df.sort_values(by = 1)
df_sorted.head()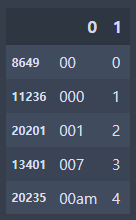
- 가중치 합치기
df_sorted['weight'] = word_weight[0]
df_sorted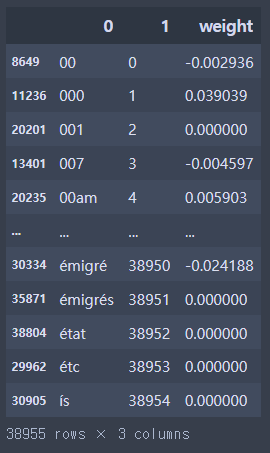
- 정렬
# 1번 컬럼기준으로 정렬했던 이유 = weight가 단어 번호로 정렬되어있었기 떄문
# 단어별 가중치를 확인해야하기 때문에 weight 기준으로 재정렬
df_sorted.sort_values(by = 'weight', inplace=True)-weight의 숫자가 작다 = 부정에 많은 영향을 끼쳤다.
# 상위 20개 단어 확인
df_sorted.head(20)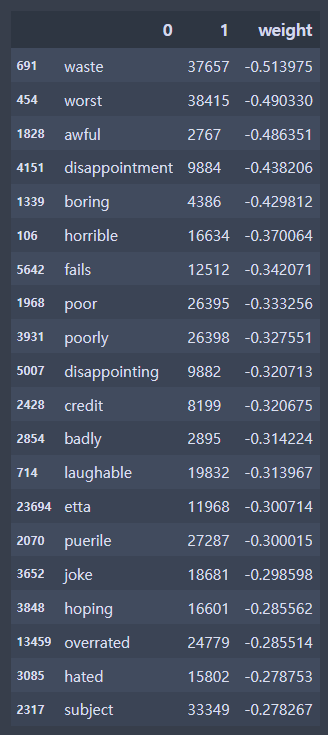
-weight의 숫자가 크다 = 긍정에 많은 영향을 끼쳤다.
df_sorted.tail(20)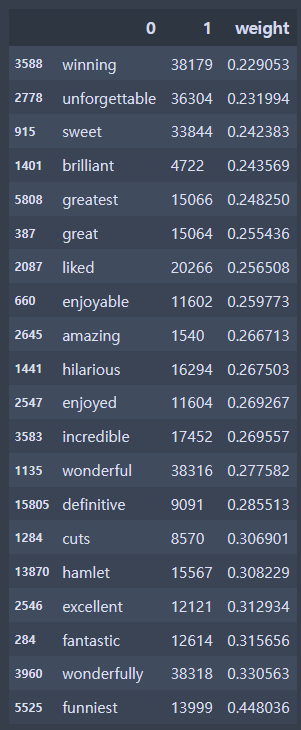
- 시각화해서 확인하기
top20_df = pd.concat(
[df_sorted.head(20), df_sorted.tail(20)]
)
top20_df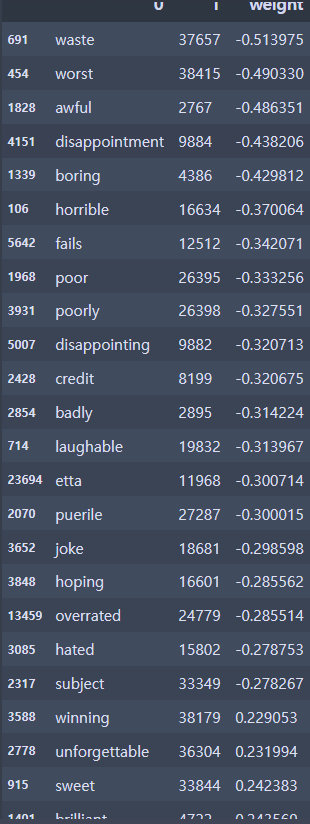
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 5)) # 그래프 크기 조절
plt.bar(top20_df[0], top20_df['weight'])
plt.xticks(rotation = 90) # x축 값들의 방향 돌리기
plt.show()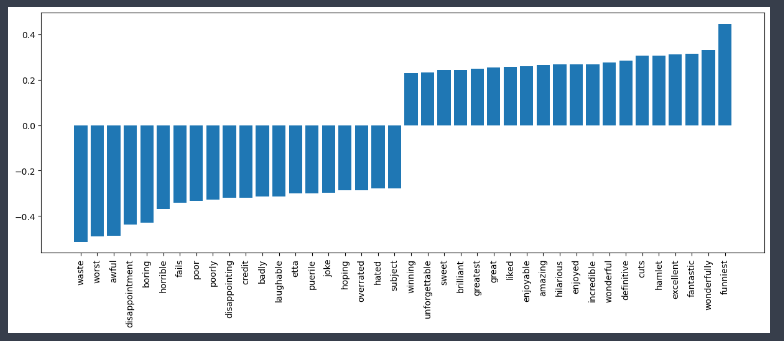
- PipeLine

from sklearn.pipeline import make_pipeline
# Bow + SVM이 합쳐진 pipe model 완성
pipe_model = make_pipeline(CountVectorizer(), LinearSVC())-파이프 모델 학습하기
pipe_model.fit(text_train, y_train)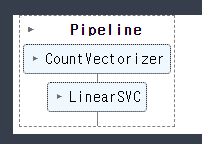
-train
pipe_model.score(text_train, y_train)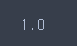
-test
pipe_model.score(text_test, y_test)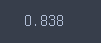
-predict
pipe_model.predict(reviews)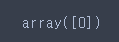
-pipe model이 가지고 있는 단계
pipe_model.steps
-파이프모델 GridSearch
from sklearn.model_selection import GridSearchCV
param = {
'countvectorizer__max_df' : [500, 700, 900],
'countvectorizer__min_df' : [20, 40, 60],
'countvectorizer__ngram_range' : [(1, 1), (1, 2)],
'linearsvc__C' : [0.5, 1, 1.5]
}
grid = GridSearchCV(pipe_model, param, cv = 5)grid.fit(text_train, y_train)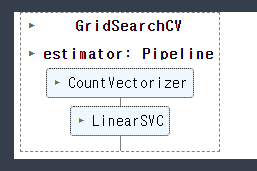
grid.best_score_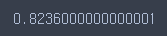
grid.best_params_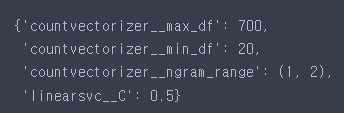
final_model = make_pipeline(CountVectorizer(max_df=700, min_df=20, ngram_range=(1, 2)),
LinearSVC(C=0.5)
)final_model.fit(text_train, y_train)
-train
final_model.score(text_train, y_train)
-test
final_model.score(text_test, y_test)