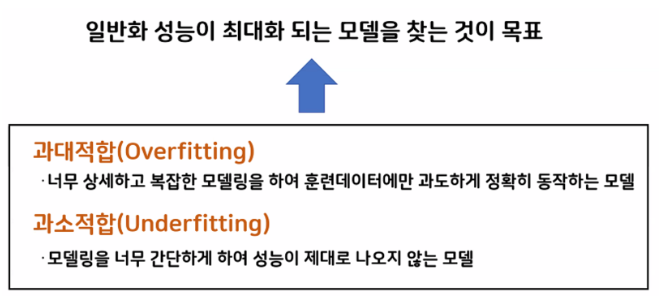
과대적합(Overfitting)
훈련 세트에 너무 맞추어져 있어 테스트 세트의 성능 정하
과소적합(Underfitting)
훈련 세트를 충분히 반영하지 못해 훈련 세트, 테스트 세트에서 모두 성능이 저하
일반화(Generalization)
훈련 세트로 학습한 모델이 테스트 세트에 대해 정확히 예측 하도록 하는 것
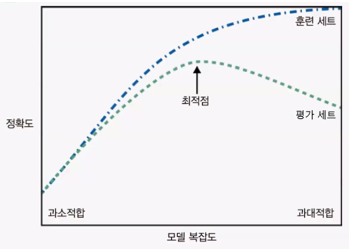
- 과소적합 - 일반화 - 과대적합
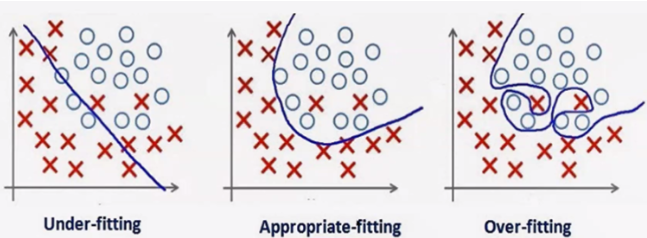
- 모델 복잡도 곡선
- 과대, 과소적합 해결 방법
-한쪽으로 편중되지 않고 다양성을 갖춘 훈련데이터로 모델을 학습시킴
-일반적으로 데이터의 양이 많아지면 일반화에 도움이 됨
-규제(Regularization)을 통해 모델의 복잡도를 적정선으로 설정함
KNN분류모델(K-Nearest Neighbors)
- 머신러닝 모델 개략도
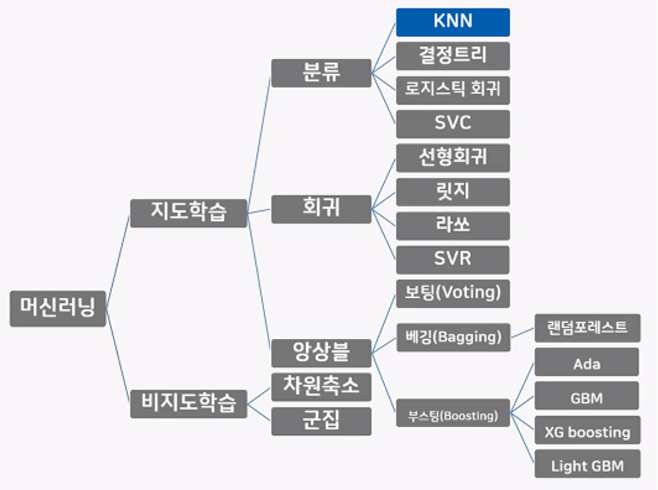
-
K - 최근접 이웃 알고리즘
-새로운 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측
-K 값에 따라 가까운 이웃의 수를 결정
-분류와 회귀에 모두 사용 가능 -
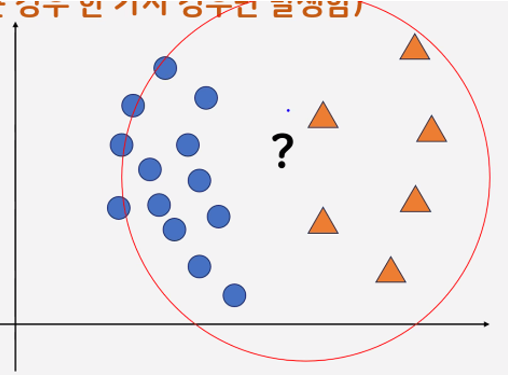
K가 3일 때

-
K를 5로 늘렸을 때

-k 값이 작을수록 모델의 복잡도가 상대적으로 증가(과대적합)
-k 값이 클수록 모델의 복잡도가 낮아진다.(과소적합)
-100개의 데이터를 학습하고 k를 100개로 설정하여 예측하면 빈도가 가장 많은 클래스 레이블로 분류
- k가 작은 경우 다양한 경우가 발생할 수 있음
(훈련 데이터가 민감 = 모델의 복잡도가 높다)
k 값이 작으면 작을수록 과대적합

- k가 엄청나게 큰 경우 한 가지 경우만 발생함
(훈련 데이터가 민감하지 않다 = 모델의 복잡도가 낮다)
k의 값이 크면 클수록 과소적합
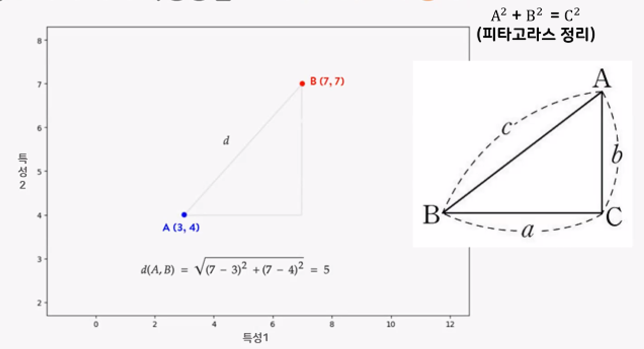
- 데이터 포인트 사이 거리 측정방법 → 피타고라스의 정리
- 주요 매개변수(Hyperparameter)

- 장단점
-이해하기가 매우 쉽고 큰 조정 없이도 나쁘지 않은 성능을 발휘하는 기초 모델
-훈련 데이터 세트의 크기(특성 수, 데이터 수)가 크면 예측이 느려짐
-거리를 측정하기 때문에 데이터의 스케일(Scale) 조정이 필요할 수 있음
-직접적인 예측에 사용되기 보단 주로 데이터를 파악하기 위한 용도로 가볍게 사용
풀이
from sklearn.neighbors import KNeighborsClassifier # 학습 모델 알고리즘
from sklearn import metrics # 평가를 위한 모듈# info() : 전체 행, 결측치 여부, 컬럼별 정보
bmi.info()
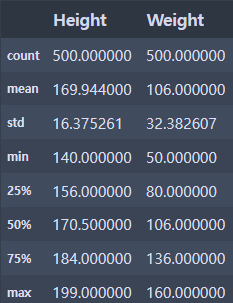
# 기술(요약)통계량 확인
bmi.describe()
# 인덱스의 중복을 제거한 값 확인하기
bmi.index.unique()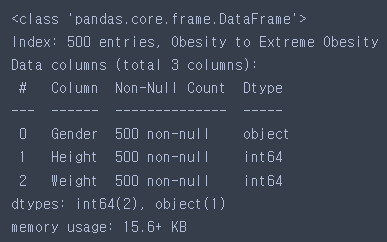

# label별 색을 넣어주는 함수 정의
def myScatter(label, color):
tmp = bmi.loc[label]
plt.scatter(tmp['Weight'],
tmp['Height'],
c = color,
label = label)# 문제데이터('Height부터 Weight')와 답데이터(Label)로 분리
# 문제데이터('Height부터 Weight') X라는 변수에 담기 (2차원)
# 답데이터(Label) y라는 변수에 담기 (1차원)
data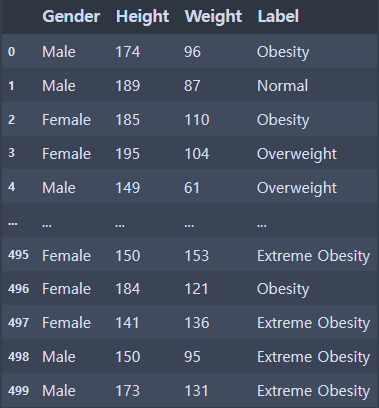
# 크기/모양 확인하기
print(X.shape)
print(y.shape)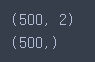
# 룬현세트와 테스트세트로 나누기
# 훈련세트 : 테스트세트 = 7:3
# X_train(0~349), X_test(350~), y_train(0~349), y_test(350~)
X_train = X.iloc[:350,:]
X_test = X.iloc[350:,:]
y_train = y.iloc[:350]
y_test = y.iloc[350:]
# 각 데이터 크기 확인하기
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)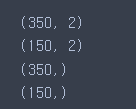
# 모델 생성
# 하이퍼파라미터 튜닝
knn_model = KNeighborsClassifier(n_neighbors= 10)# 학습/훈력 진행
# 모델명.fit(훈련용 문제, 훈련용 답)
knn_model.fit(X_train, y_train)
# 예측 진행
# 모델명.predict(테스트용 문제)
pre = knn_model.predict(X_test)
pre
# 성능 평가
y_test
pre
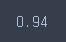
metrics.accuracy_score(pre, y_test)

# 활용하기
# 새로운 미지의 데이터 예측하기
knn_model.predict([[150,83],[185,43],[160,50]])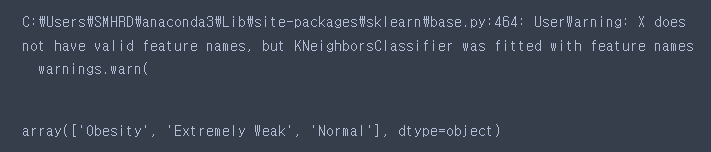

노는게 제일 좋아~!