- 실습

- 결정트리모델 개요

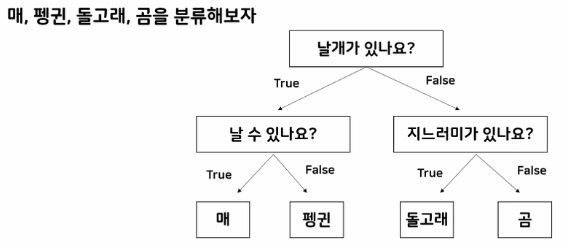
결정트리모델
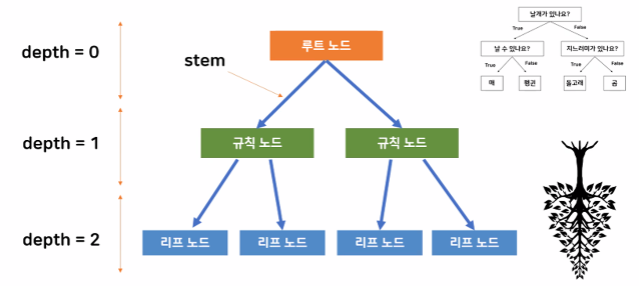
→ 나무가 거꾸로있는 모습과 비슷하다.
- Decision Tree(의사결정 나무)란?
- 스무고개 하듯이 예 / 아니오 질문을 반복하며 학습
- 특정 기준(질문)에 따라 데이터를 구분하는 모델
- 분류와 회귀에 모두 사용 가능
- 어떻게 노드를 분할하는지 시각화 가능
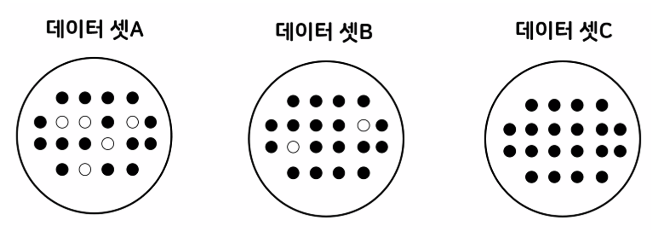
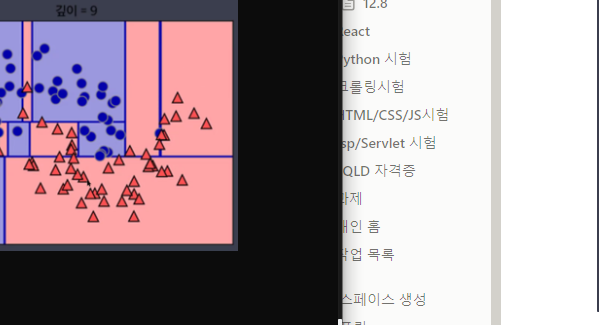
- Decision Tree 최적의 분리를 찾는 방법 : 불순도가 낮아지는 방향
즉, 어떤 기준을 통해 나타난 불순도(impurity)가 낮을수록 더 좋은 의사결정 나무
- 다음 중 가장 순도가 높은 데이터 셋은?
데이터 셋 A
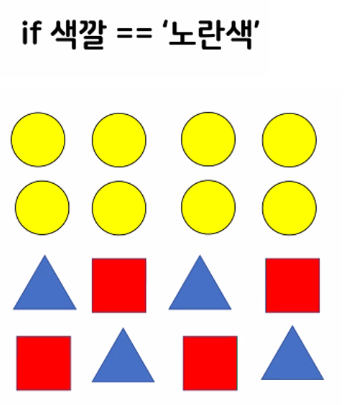
- 가장 첫 번째로 만들어져야 하는 규칙 조건은?
- 실습

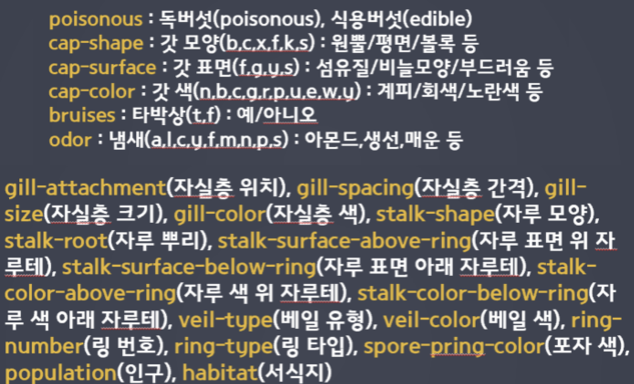
- Decision Tree 실습
-Label 인코딩 or One-hot 인코딩 방식을 이용해 수치화

- 범주형(이산형) 특성이기 때문에 인코딩 필요
(categorical feature)
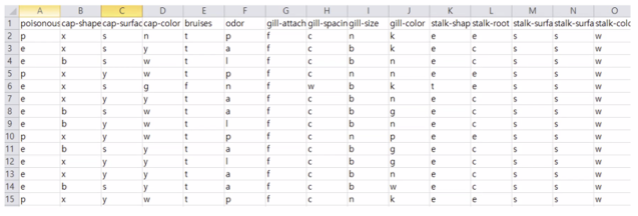
- 레이블 인코딩(Label Encoding)
단순 수치 값으로 mapping하는 작업
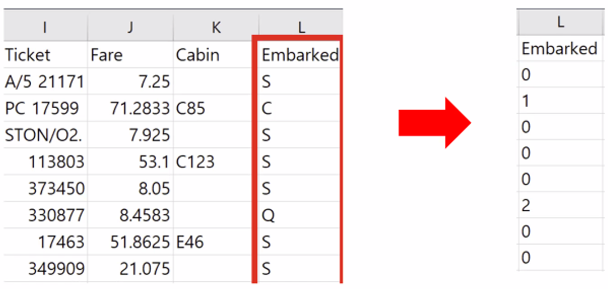
- One-hot Encoding
0 or 1의 값을 가진 여러 개의 새로운 특성으로 변경하는 작업
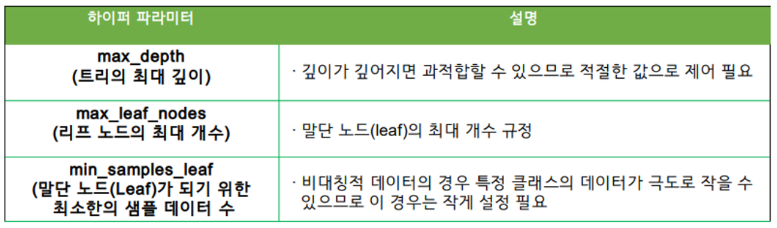
- 결정 트리 주요 하이퍼파라미터
Decision Tree(의사결정 나무) 하이퍼파리미터
- 노드 특성 분석하기
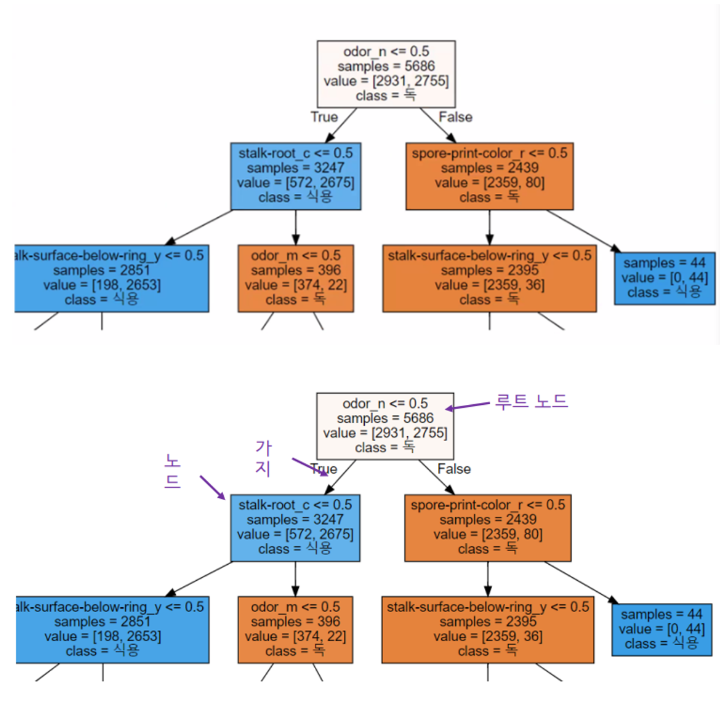
- 정리
- 문제정의
- 머신러닝을 사용해서 어떤 문제를 해결할것인지
- 식용버섯과 독버섯을 구분하자
- 데이터수집
- 정의된 문제를 해결하기 위한 데이터 수집
- 사이트에서 다운로드 받기, 크롤링해서 찾기, DB에서 가져오기
- 데이터 전처리
- 데이터 크기확인
- 결측치 확인
- 문제와 정답으로 나누기
- 통계치 확인하기
- 값을 숫자로 변경
→ 레이블 인코딩, 원핫인코딩(많이 사용)
- 탐색적 데이터 분석(생략 가능)
- 데이터를 더 자세하게 바라보자
- 통계기법 사용하기
- 그래프로 그리기
- 모델 선택 및 하이퍼 파라미터 튜닝
- 모델 선택 : 목적과 데이터에 맞는 모델 고르기
- 하이퍼 파라미터 튜닝 : 모델 적합하게 수정하기
- train_test_split → 데이터 전처리가 완료된 후에 진행 > 5단계는 데이터 전처리가 완료된 시점
- DecisionTree 모델 불러오기
- 학습
- 5단계에서 만든 모델에 전처리 완료된 데이터로 학습하기
- 예측 및 평가
- 모델의 성능을 평가
- 테스트 데이터로 예측하기
Decision Tree
- 주요 매개변수(Hyperparameter)
scikit-learn의 경우
DecisionTreeClassifier(max_depth, max_leaf_nodes, min_sample_leaf)
-트리의 최대 깊이 : max_leaf_nodes (값이 클수록 모델의 복잡도가 올라간다.)
-리프 노드의 최대 개수 : max_leaf_nodes
-리프 노드를 구성하는 최소 샘플의 개수 : min_samples_leaf
-
장단점 및 주요 매개변수(Hyperparameter)
-
장점
-만들어진 모델을 쉽게 시각화 할 수 있어 이해하기 쉽다. (white box model)
-각 특성이 개별 처리되기 떄문에 데이터 스케일에 영향을 받지 않아 특성의 정규화나 표준화가 필요 없다.
-트리 구성 시 각 특성의 중요도를 계산하기 때문에 특성 선택(Feature selection)에 활용될 수 있다. -
단점
-훈련데이터 범위 밖의 포인트는 예측 할 수 없다. (ex : 시계열 데이터)
-가지치기를 사용함에도 불구하고 과대적합되는 경향이 있어 일반화 성능이 좋지 않다.
-
- Decision Tree(결정트리)
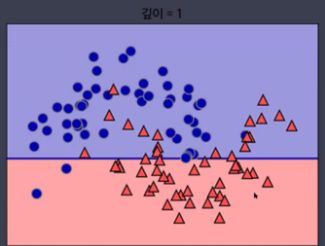
▼
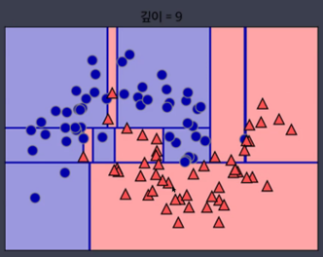
- 선형모형에는 적합하지 않음
교차검증
- Cross validation
학습-평가 데이터 나누기를 여러 번 반복하여 일반화 에러를 평가하는 방법

→ 테스트 세트에 맞게 학습 될 수 있다.
▼
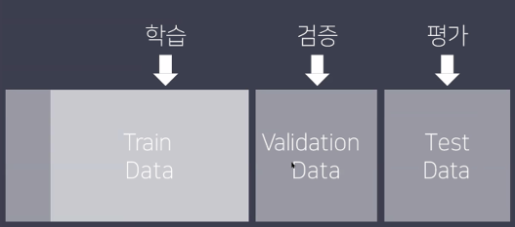
- K-fold cross-validation 동작 방법
- 데이터 셋을 k개로 나눈다.
- 첫 번째 세트를 제외하고 나머지에 대해 모델을 학습한다. 그리고 첫 번째 세트를 이용해서 평가를 수행한다.
- 2번 과정을 마지막 세트까지 반복한다.
- 각 세트에 대해 구했던 평가 결과의 평균을 구한다.


-
cross-validation 장/단점
- 데이터의 여러 부분을 학습하고 평가해서 일반화 성능을 측정하기 때문에 안정적이고 정확하다. (샘플링 차이 최소화)
- 모델이 훈련 데이터에 대해 얼마나 민감한지 파악가능 (점수 대역 폭이 넓으면 민감)
- 데이터 세트 크기가 충분하지 않은 경우에도 유용하게 사용 가능하다.
(단점)
- 여러 번 학습하고 평가하는 과정을 거치기 때문에 계산량이 많아진다.

노는게 제일 좋아~!