- 정리
-
문제정의
-
데이터 수집
-
데이터 전처리
-PassengerId 삭제
-Embarked 결측치 채우기
-Fare 결측치 채우기
-Age 결측치 채우기
-Cabin 결측치 채우기 -
탐색적 데이터 분석
-Cabin 시각화
-Pclass 시각화
-Cabin과 Pclass 시각화
-Sex 시각화
-Embarked 시각화
-Sex, Age, Survived 시각화
-Sex, Fare, Survived 시각화
SibSp(형제자매수), Parch(부모자식수) 확인해보기
→ Family_Size, Family_Group 컬럼 생성(특성공학)
Name 컬럼 호칭만 뽑아오기 → Title 컬럼 생성
Ticket 확인해보기 → 특징이 없어서 삭제
타입 변경 : Name, Sex, Ticket, Cabin, Embarked -
모델 선택 및 하이퍼 파라미터 튜닝
KNN, DecisionTree 모델 사용하기
새로운 모델 사용해보기(Ensemble 계열 모델)
→ RandomForest, AdaBoost -
학습
-
평가 및 예측
*교차검증
타입 변경 : Name, Sex, Ticket, Cabin, Embarked
실습
-
문제정의
타이타닉 데이터를 사용해서 생존자와 사망자 예측해보기 -
데이터 수집
kaggle 사이트로부터 train, test 데이터 다운로드
import pandas as pd
train = pd.read_csv('./titanic/train.csv')
test = pd.read_csv('./titanic/test.csv')
train.shape, test.shape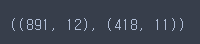
train.head()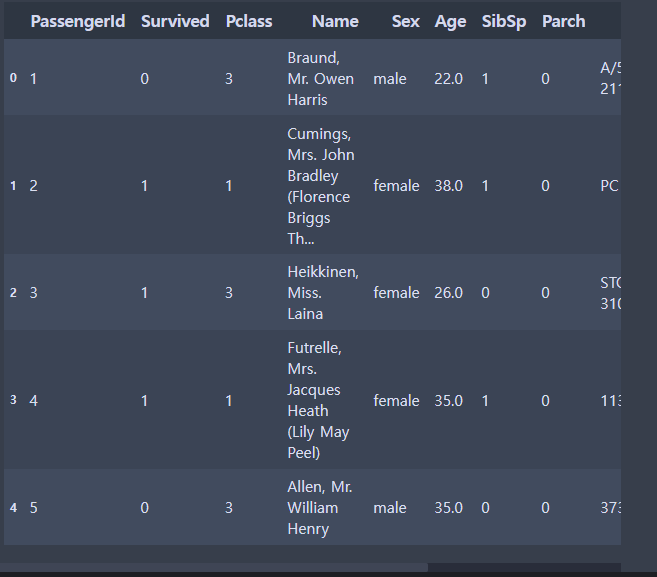
- 데이터 전처리
-
결측치 처리
-
이상치 처리
-
train
# 결측치 : Age, Cabin, Embarked
# 타입 변경 : Name, Sex, Ticket, Cabin, Embarked
train.info()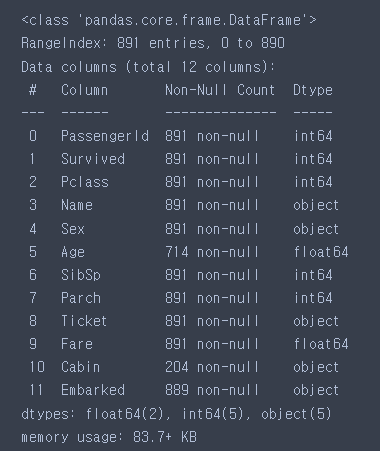
- test
# 결측치 : Age, Cabin, Fare
# 타입 변경 : Name, Sex, Ticket, Cabin, Embarked
test.info()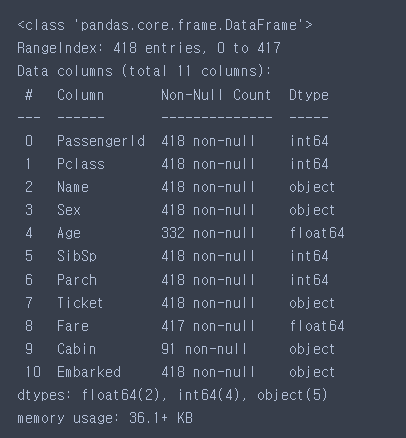
- 정답 컬럼 분리
y_train = train['Survived']train.head()
Passengerld 삭제
- Survived를 예측하는데 도움이 안될 것 같다.
-train
# train = train.frop('PassengerId', axis = 1)
# inplace = True : 변경된 결과 저장
train.drop('PassengerId', axis=1, inplace=True)-test
test.drop('PassengerId', axis=1, inplace=True)- train
train
Embarked 결측치 채우기
-
탑승한 항구
-
train에 2개의 결측치 존재
-
value_counts() : 값의 갯수 세어주는 함수
train['Embarked'].value_counts()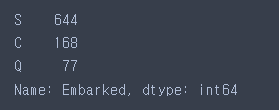
- 최빈값으로 결측치 채우기
train['Embarked'] = train['Embarked'].fillna('S')train.info()
Fare 결측치 채우기
test['Fare']
test.info()
- 통계치 확인하기
test['Fare'].describe()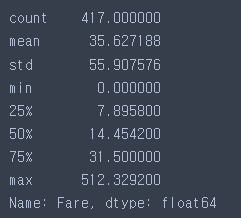
test['Fare'].fillna(14.45, inplace=True)test.info()
Age 결측치 채우기
- 단순 통계치가 아니라 다른 컬럼간의 상관관계를 이용해보자
train.iloc[5]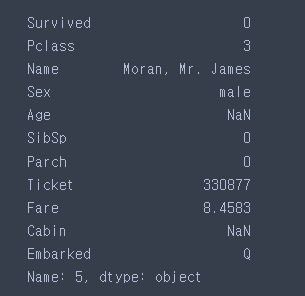
- 상관관계 확인하기
# 피어슨 상관계수
# 두 변수간의 선형 상관관계를 수치적으로 표현
# 두 값이 비례관계면 양의 숫자(최대값 1) > 양의 상관관계
# 두 값이 반비례관계면 음의 숫자(최대값 -1) > 음의 상관관계
# 0에 가까울수록 관계가 없다
train.corr()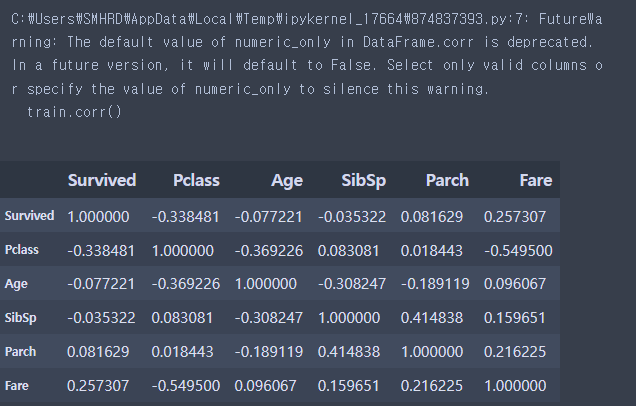
- Pclass, Sex를 기준으로 Age 결측치를 채워보자
# Age에 결측치가 존재한다 => Pclass와 Sex를 확인하고 해당하는 값으로 결측치 채움
# Age에 결측치가 존재하지 않는다 => 그 값을 그대로 사용한다.
age_table = train[['Pclass', 'Sex','Age']].groupby(by=['Pclass', 'Sex']).median()train.iloc[17]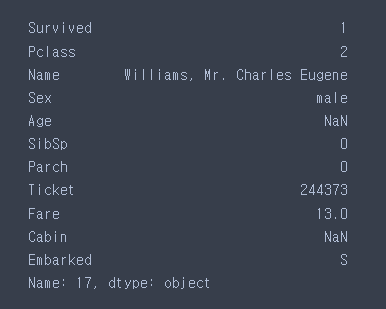
- apply
# 행이나 열 단위로 복잡한 작업(커스텀 함수)을 할 때 사용
# 결측치 채우는 함수 만들기
import numpy as np
def fill_age(data): # data는 하나의 행 데이터(한 사람의 데이터)
if np.isnan(data['Age']): # 결측치면 True, 아니면 False
# 결측치라면 Pclasss와 Sex를 확인하고 해당 값으로 age_table에서 검색
# 나온 값으로 결측치 채우기
return age_table.loc[data['Pclass'], data['Sex']][0]
else:
# 값이 있기 때문에 그대로 사용
return data['Age']fill_age() # 함수를 사용하겠다
fill_age # 함수를 가져오겠다- apply는 한 행씩(axis=1) 데이터를 가져와서 fill_age 함수에 집어넣음
train['Age'] = train.apply(fill_age, axis=1)
test['Age'] = test.apply(fill_age, axis=1)train.info()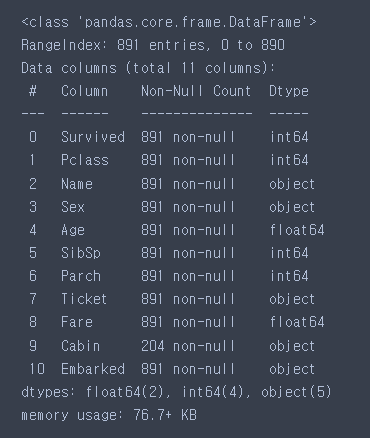
Cabin 결측치 채우기
- 891개 데이터 중에서 204개가 결측치가 아님, 687개가 결측치이다
train['Cabin'].unique()
- 앞 한글자만 가져오기
train['Cabin'] = train['Cabin'].str[0]
test['Cabin'] = test['Cabin'].str[0]train['Cabin'].unique()
- 결측치를 하나의 데이터로 생각
train['Cabin'].fillna('N', inplace=True)
test['Cabin'].fillna('N', inplace=True)train.info()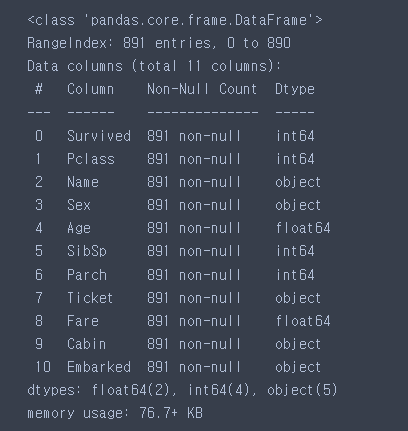
- 탐색적 데이터 분석
- 데이터 더 자세하게 살펴보자
- 통계치, 그래프
- 정답(생존유무)와 얼마나 연관이 있는가
- 그래프 그리는 라이브러리
# matplolib : 사용하기 어려운 편, 자세하게 사용 할 수 있음
# seaborn : 사용하기 쉬운 편, 자세하게 사용하기는 힘듦
import seaborn as sns# data = 사용 할 데이터
# x = x축에 사용 할 데이터
# hue = 데이터 분리 기준
# 결측치로 채운 N데이터가 생존과 사망이 분리가 되어있어서 데이터로 사용하자
sns.countplot(data = train, x = 'Cabin', hue = 'Survived')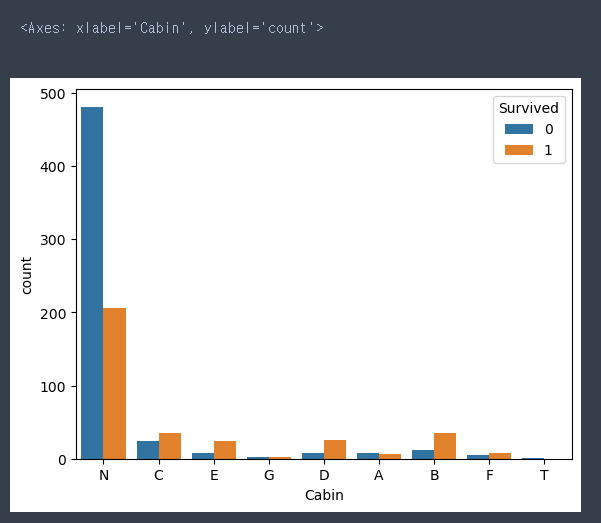
Pclass 시각화
# 1등급에 탑승한 사람은 많이 생존
# 3등급에 탑승한 사람은 많이 사망
sns.countplot(data = train, x = 'Pclass', hue = 'Survived')
Cabin과 Pclass 시각화
# N구역은 사망자의 비율이 높고, 3등급의 객실 사람이 많다.
# A,B,C구역은 1등급만 존재(좋은, 비싼 구역이지 않을까?)
sns.countplot(data = train, x = 'Cabin', hue = 'Pclass')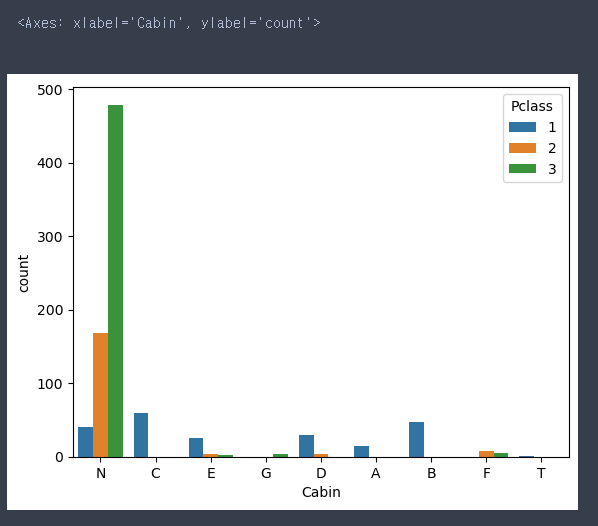
sns.countplot(data = train, x = 'Sex', hue = 'Survived')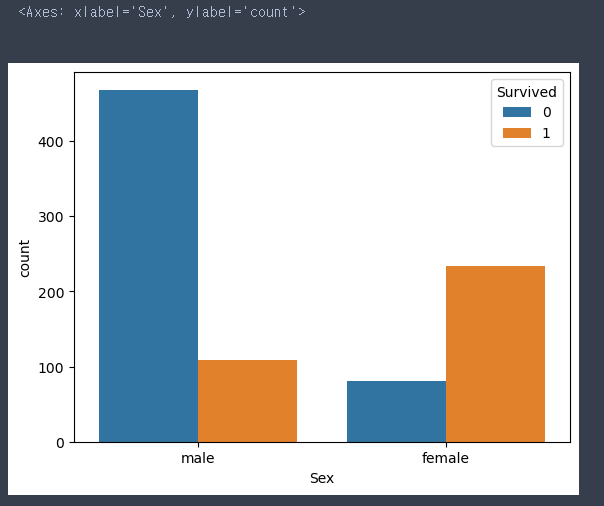
Embarked 살펴보기
sns.countplot(data = train, x = 'Embarked', hue = 'Survived')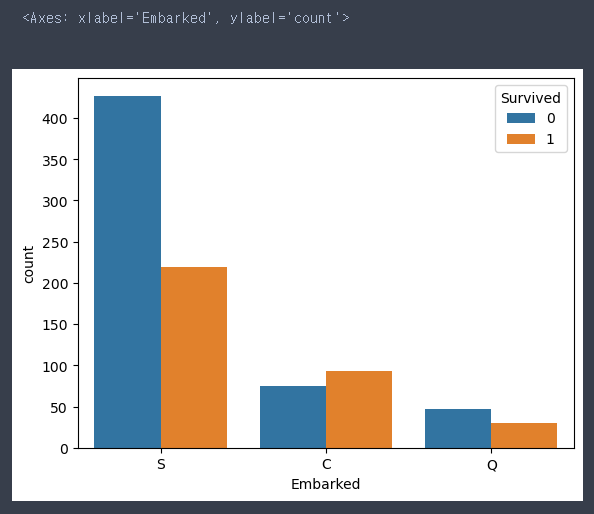
sns.countplot(data = train, x = 'Embarked', hue = 'Pclass')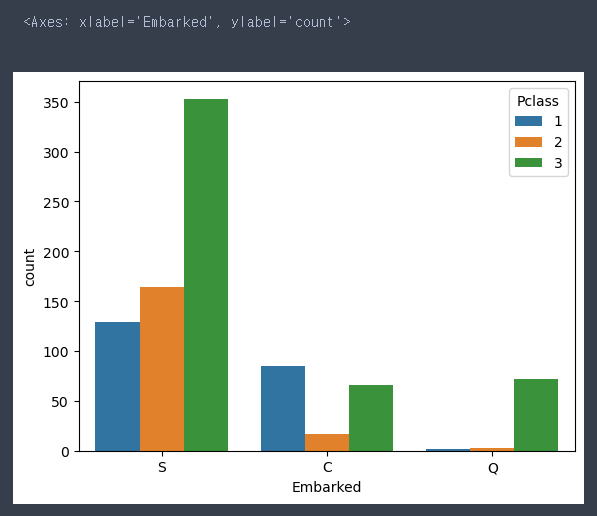
Sex, Age, Survived 시각화
- 데이터의 분포를 확인
sns.violinplot(data = train, x = 'Sex', y = 'Age', hue = 'Survived', split = True)
# 20대가 많이 탑승했다
# 남아는 많이 살았고 여아는 많이 죽었다 > 남아선호사상?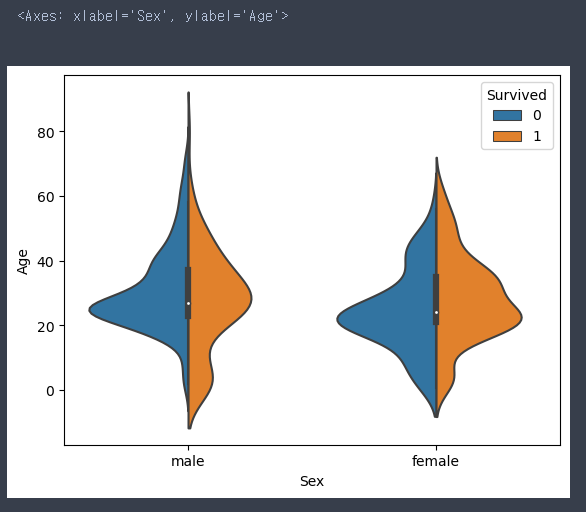
sns.violinplot(data = train, x = 'Sex', y = 'Fare', hue = 'Survived', split = True)
# 요금이 저렴할수록 죽은 사림이 더 많다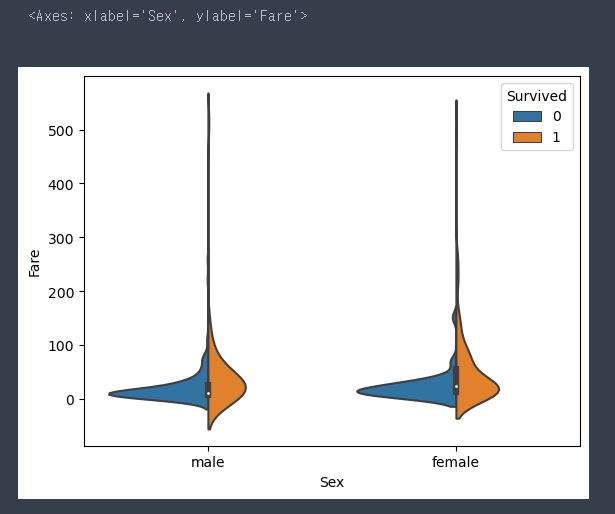
Family_Size 만들기
- SibSp + Parch + 1(나 자신)
- 특성공학 : 컬럼에 연산을 통해서 의미있는 새로운 정보를 추출하는 행위
- train
train['Family_Size'] = train['SibSp'] + train['Parch'] + 1- test
test['Family_Size'] = test['SibSp'] + test['Parch'] + 1train.head()
sns.countplot(data = train, x = 'Family_Size', hue = 'Survived')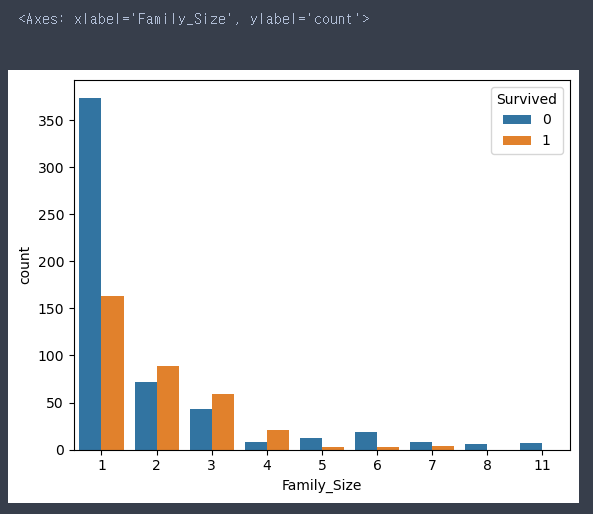
# 1명일때는 죽은 비율이 높다 > Alone
# 2~4명일때는 산 비율이 높다 > Small
# 5명 이상일때는 죽은 비율이 높다 > Large
# 수치형 > 범주형 : Binning# cut : 구간정보, 구간에 대한 이름을 통해서 수치형 값을 범주형으로 변경
# bins : 구간 정보
bins = [0,1,4,20]
# labels : 구간에 대한 이름
labels = ['Alone', 'Small', 'Large']train_cut = pd.cut(train['Family_Size'], bins = bins, labels = labels)
test_cut = pd.cut(test['Family_Size'], bins = bins, labels = labels)train['Family_Group'] = train_cut
test['Family_Group'] = test_cuttrain.head(10)
Name 컬럼 살펴보기
- 이름은 자체 특성상 거의 모든 값이 다름
- 영어이름은 중간에 호칭이 존재 → 호칭만 사용
- 특성공학을 통해 반정형 데이터로 변경
train['Name'][0]
# split : 매개변수값을 기준으로 앞과 뒤로 나눠준다.(리스트로 출력)
# strip : 문자열 맨 앞과 맨 뒤에 있는 공백 제거
train['Name'][0].split(',')[1].split('.')[0].strip()
- apply 함수를 사용하기 위한 커스텀 함수 제작
# 이름을 하나씩 집어넣고 정해진 함수 사용
def split_title(name):
return name.split(',')[1].split('.')[0].strip()train['Title'] = train['Name'].apply(split_title)
test['Title'] = test['Name'].apply(split_title)train.head()
train.shape, test.shape
- 범주가 너무 많다.
# 1 or 2개인 데이터들이 많다. → 과대적합 유발 → 처리를 해줘야함
# 1 or 2개인 데이터들이 많다. → Other로 합치기
train['Title'].value_counts()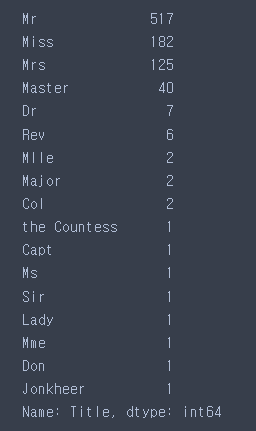
convert_name_dic = {
'Mr' : 'Mr' ,
'Mrs' : 'Mrs',
'Miss' : 'Miss',
'Master' : 'Master',
'Don' : 'Other',
'Rev' : 'Rev',
'Dr': 'Dr',
'Mme' : 'Other',
'Ms' : 'Other',
'Major' : 'Other',
'Lady' : 'Other',
'Sir' : 'Other',
'Mlle' : 'Other',
'Col' : 'Other',
'Capt' : 'Other',
'the Countess' : 'Other',
'Jonkheer' : 'Other',
'Dona' : 'Other'
}- train
train['Title'] = train['Title'].map(convert_name_dic)
train['Title'].value_counts()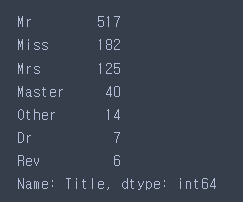
- test
test['Title'] = test['Title'].map(convert_name_dic)train.head()
Ticket 컬럼 확인해보기
# 문자열 끝엔 최소 4자리 숫자가 있다. → 한자리 숫자만 있는 경우도 존재
# 다른 탑승객과 똑같은 티켓을 가진 사람이 약 200명 → 공통된 데이터가 별로 없다.
# Ticket 데이터는 생존과 연관이 없어보임 → 삭제
len(train['Ticket'].unique())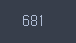
train.drop('Ticket', axis = 1, inplace=True)
test.drop('Ticket', axis = 1, inplace=True)train.shape, test.shape
train.columns
쓸모없는 데이터 삭제
- Survived : 이미 y_train으로 빼둠
- Name : 중간 호칭을 Title로 뺌
train.drop('Survived', axis=1, inplace=True)
train.drop('Name', axis=1, inplace=True)
test.drop('Name', axis=1, inplace=True)train.shape, test.shape
글자 데이터 → 숫자 데이터로 변경
- 원핫인코딩을 사용
- train과 test를 합쳐서 사용
→ 컬럼명은 동일하지만 값은 다를 수 있기 때문에
→ 값이 달라지면 생성되는 컬럼이 달라짐
- ignore_index = 기존 인덱스는 무시하고 재정렬
combined = pd.concat([train, test], ignore_index=True)
combined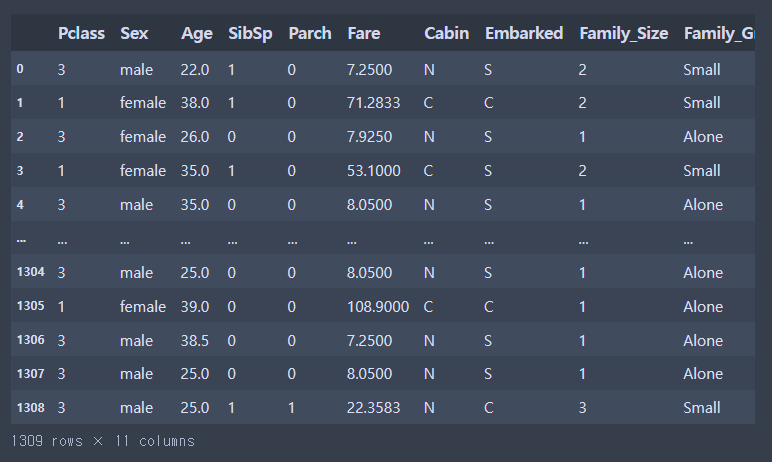
categorical_feature = ['Sex', 'Cabin', 'Embarked', 'Family_Group', 'Title']- 원핫인코딩
one_hot = pd.get_dummies(combined[categorical_feature])
one_hot.shape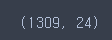
one_hot.columns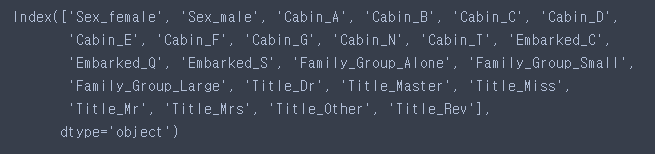
total = pd.concat([combined, one_hot], axis=1)
total.shape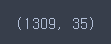
total.drop(categorical_feature, axis=1, inplace=True)
total.shape
X_train, X_test 나누기
X_train = total.iloc[:891]
X_test = total.iloc[891:]X_train.shape, X_test.shape
X_train.columns
- 모델 선택 및 하이퍼파라미터 튜닝
- KNN, Decision Tree 사용해보기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
knn = knn = KNeighborsClassifier()
tree = DecisionTreeClassifier()- RandomForest 사용하기
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()rf = RandomForestClassifier(n_estimators=50, max_features=0.5)- 학습
knn.fit(X_train, y_train)
tree.fit(X_train, y_train)
rf.fit(X_train, y_train)
- 예측 및 평가
knn.score(X_train, y_train)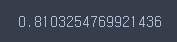
tree.score(X_train, y_train)
pre_knn = knn.predict(X_test)
pre_tree = tree.predict(X_test)- 예측값을 gender_submission 파일에 적고 업로드하기
sub = pd.read_csv('./titanic/gender_submission.csv')sub['Survived'] = pre_knn # 예측결과 집어넣기
sub.to_csv('knn_pre.csv', index=False) # csv파일로 출력하기sub['Survived'] = pre_tree # 예측결과 집어넣기
sub.to_csv('tree_pre.csv', index=False) # csv파일로 출력하기- 교차검증을 진행하면 과대적합여부를 조금 더 파악 가능
# 실제 점수와 유사한 결과를 출력
from sklearn.model_selection import cross_val_score
# train score : 0.81
# kaggle score : 0.6555
cross_val_score(knn, X_train, y_train, cv=5)
# train score : 0.98
# kaggle score : 0.70813
cross_val_score(tree, X_train, y_train, cv=5)
- 교차검증
# 교차검증 score : 0.72
cross_val_score(knn, X_train, y_train, cv=5).mean()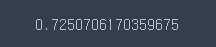
# 교차검증 score : 0.78
cross_val_score(tree, X_train, y_train, cv=5).mean()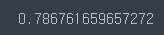
rf.score(X_train, y_train)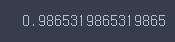
cross_val_score(rf, X_train, y_train, cv=5).mean()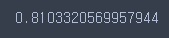
pre_rf = rf.predict(X_test)sub['Survived'] = pre_rf # 예측결과 집어넣기
sub.to_csv('rf_pre.csv', index=False) # csv파일로 출력하기- kaggle 업로드


노는게 제일 좋아~!