Ensemble Model
bagging / boosting, RandomForest, GBM, Xgboost
Ensemble(앙상블)
여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법

- Decision Tree Ensemble(결정트리 앙상블)
- 개별 결정트리의 과대적합되는 단점을 보완하는 모델
- 다수결 법칙 또는 평균 등으로 통합하여 예측 정확성을 향상
- 결정트리 모델들이 서로 독립적
- 결정트리 모델들이 무작위 예측을 수행하는 모델보다 성능이 좋을 경우
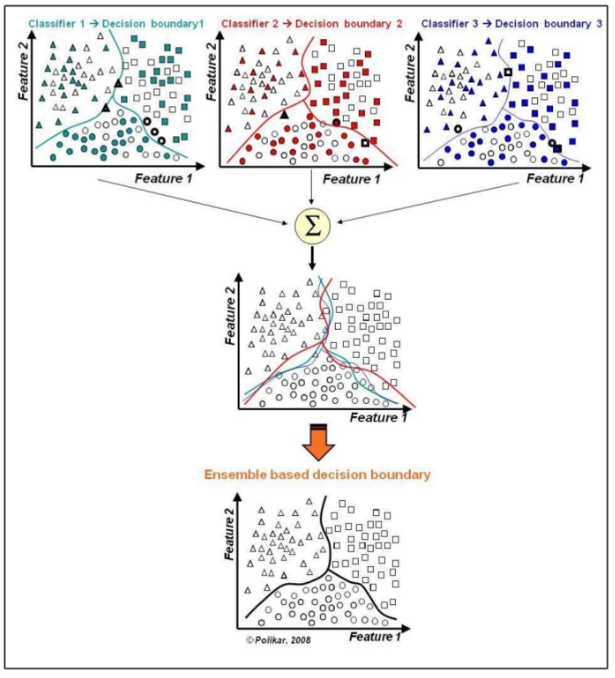
→ 서로 독립적인 다양한 모델을 만들자
-모델마다 결과가 다를 때 통합하는 방법의 일종 → 예측 모델들의 평균값을 사용
→ 모델이 많아지면 평균값이 모델의 실제 데이터와 유사해짐
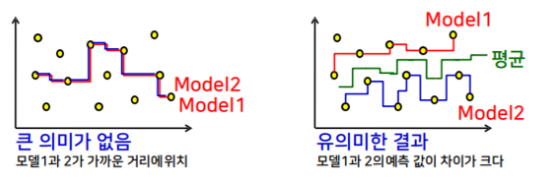
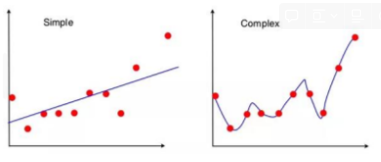
-높은 bias로 인한 underfitting, 높은 variance로 인한 overfitting을 줄이기위해 앙상블 기법 사용 → 알고리즘의 안정성과 정확성 향상
-bias 오차 : 예측값과 실제값 간의 차이
-variance 오차 : 학습된 모델 간에 예측한 값들의 차이
- Bagging vs Boosting
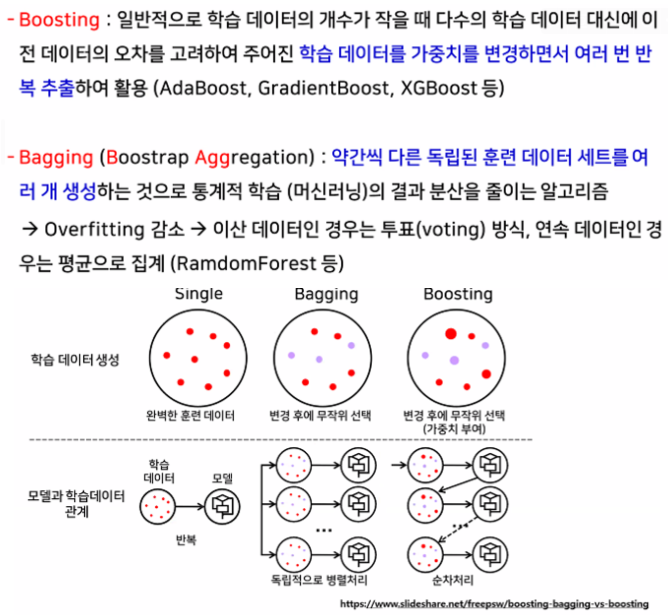
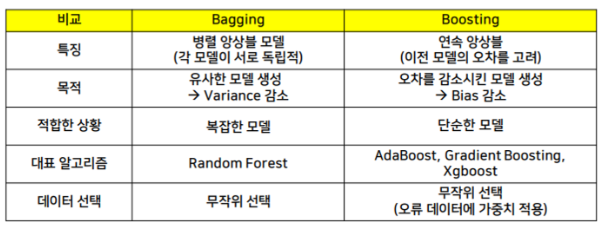
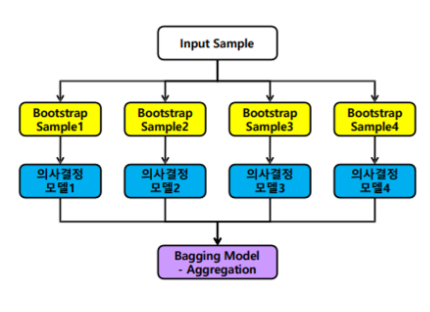
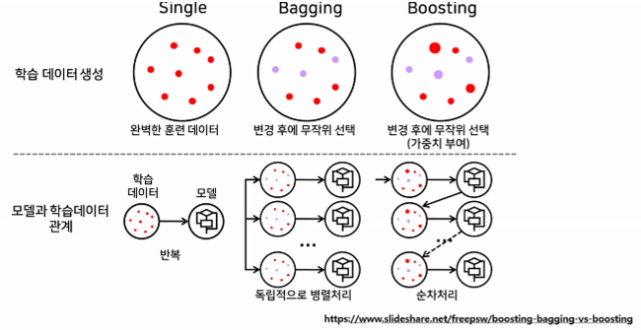
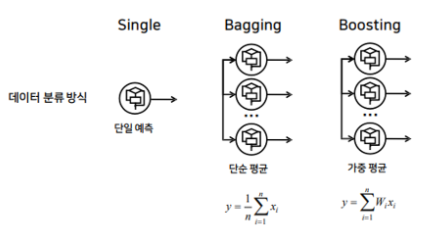
-
서로 다른 방향으로 과대적합된 트리를 많이 만들고 평균을 내어 일반화 시키는 모델
-
다양한 트리를 만드는 방법 두 가지
- 트리를 만들 때 사용하는 데이터 포인트 샘플을 무작위로 선택한다. (행)
- 노드 구성 시 기준이 되는 특성을 무작위로 선택하게 한다. (열)
- 건강위험도를 예측하기 위한 의사결정트리
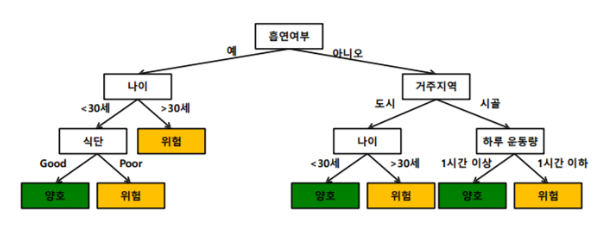
- 건강위험도를 예측하기 위한 랜덤포레스트
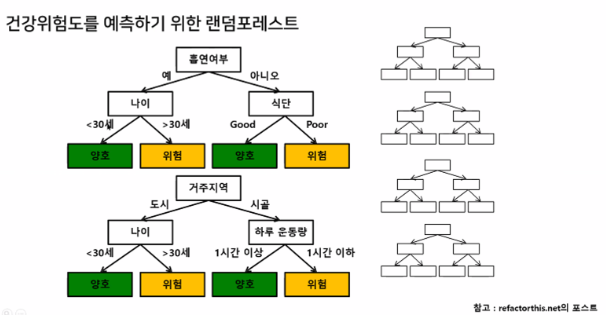
-다수의 의사결정트리의 의견이 통합되지 않는다면
→ 투표에 의한 다수결의 원칙을 따름 → 앙상블 방법(Ensemble Methods)
-장점: 실제값에 대한 추정값 오차 평균화, 분산 감소, 과적합 감소
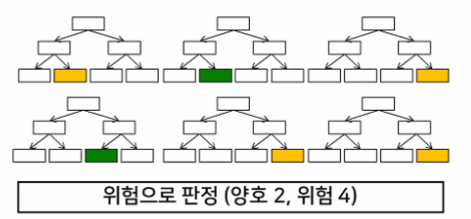
- Ensemble Model - RandomForest
주요 매개변수(Hyperparameter)
scikit-learn의 경우

-트리의 개수 : n_estimators
-선택할 특징의 최대 수 : max_features (1로 하면 특성을 고려하지 않으며 큰 값이면 DT와 비슷해짐)
-선택할 데이터의 시드 : random_state
- 장단점
- 텍스트 데이터와 같은 희소한 데이터에는 잘 동작하지 않는다.
- 큰 데이터 세트에도 잘 동작하지만 훈련과 예측이 상대적으로 느리다.
- 트리 개수가 많아질수록 시간이 더 오래 걸린다.
- feature_importance
-특성의 중요도를 관리
-Feature Selection에 활용

실습
(타이타닉 이어서)
- RandomForest 하이퍼파라미터 튜닝하기
# 5~7단계 모음
# 5단계 모델 생성 및 하이퍼파라미터 튜닝
rf = RandomForestClassifier(n_estimators=50,
max_features = 0.5,
max_depth=3,
min_samples_split=25,
min_samples_leaf=25)
# 6단계 학습
rf.fit(X_train, y_train)
# 7단계 평가
cross_val_score(rf, X_train, y_train, cv=5).mean()
from sklearn.model_selection import GridSearchCV
# 하이퍼파라미터 조절 쉽게하기
# 하이퍼파라미터 범위
param = {
'n_estimators' : [30, 40, 50, 60],
'max_features' : [0.3, 0.4, 0.5, 0.6],
'max_depth' : [3, 4, 5, 6],
'min_samples_split' : [20, 25, 30, 35],
'min_samples_leaf' : [20, 25, 30, 35]
}
# 4 * 4 * 4 * 4 * 4 = 1024번 학습
# 학습된 결과 중 가장 좋았던걸 남겨둠
grid_search = GridSearchCV(RandomForestClassifier(), param, cv=5)
grid_search.fit(X_train, y_train)
- 가장 좋았던 결과
grid_search.best_score_
- 가장 좋았을 때의 하이퍼파라미터
grid_search.best_params_
grid_search.predict(X_test)
- 예측 & 평가하기
# 예측
prd_rf_grid = grid_search.predict(X_test)
# 제출 파일 불러오기
sub = pd.read_csv('./titanic/gender_submission.csv')
sub['Survived'] = prd_rf_grid # 예측결과 집어넣기
sub.to_csv('rf_grid_pre.csv', index=False)param = {
'n_estimators' : [36, 38, 40, 42, 44],
'max_features' : [0.5, 0.55, 0.6, 0.65, 0.7],
'max_depth' : [5, 6, 7],
'min_samples_split' : [16, 18, 20, 22, 24],
'min_samples_leaf' : [16, 18, 20, 22, 24]
}
# 5 * 5 * 5 * 5 * 5 = 3125번 학습
# 학습된 결과 중 가장 좋았던걸 남겨둠
grid_search = GridSearchCV(RandomForestClassifier(), param, cv=5)
grid_search.fit(X_train, y_train)
- 가장 좋았던 결과
grid_search.best_score_
- 가장 좋았을 때의 하이퍼파라미터
grid_search.best_params_
- 예측 & 평가하기
# 예측
prd_rf_grid = grid_search.predict(X_test)
# 제출 파일 불러오기
sub = pd.read_csv('./titanic/gender_submission.csv')
sub['Survived'] = prd_rf_grid # 예측결과 집어넣기
sub.to_csv('rf_grid_pre1.csv', index=False)- kaggle 올리기


노는게 제일 좋아~!