데이터 스케일링(Data scaling)
데이터의 크기 조절
- 특성(Feature)들의 범위(range)를 정규화 해주는 작업
- 특성마다 다른 범위를 가지는 경우 머신러닝 모델들이 제대로 학습되지 않을 가능성이 있다.(KNN, SVM, Neural network 모델, Clustering 모델 등)

-
장점
-특성들을 비교 분석하기 쉽게 만들어준다.
-Linear Model, Neural network Model 등에서 학습의 안정성과 속도를 개선시킨다. -
단점
-하지만 특성에 따라 원래 범위를 유지하는게 좋을 경우는 scaling을 하지 않아도 된다.
- 데이터 스케일링 종류
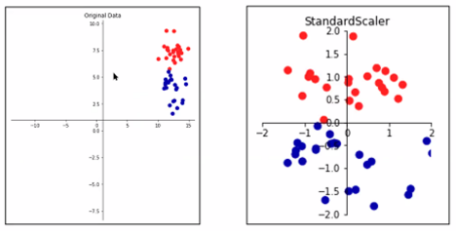
StandardScaler
- 변수의 평균, 분산을 이용해 정규분포 형태로 변환(평균 0, 분산 1)
- 데이터가 정규분포인 경우에 사용
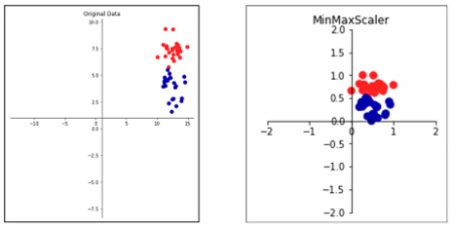
MinMaxScaler
- 변수의 최대값 1, 최소값을 0으로 하여 변환(0~1 사이 값으로 변환)
- 데이터가 비정규분포인 경우에 사용
- 이상치(Outlier)에 크게 영향을 받는다 → 이상치가 있는 경우 사용 못함
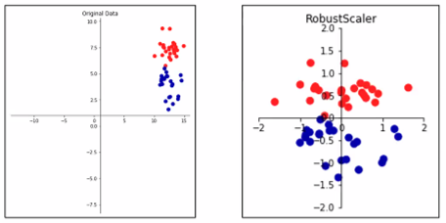
Robust
- 변수의 1/4지점을 0으로 3/4지점을 1로 하여 변환
- 이상치(Outlier)가 있는 경우 사용
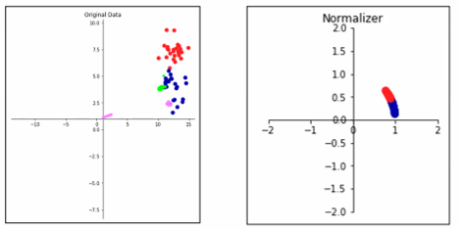
Normalizer
- 특성 벡터의 유클리디안 길이가 1이 되도록 조정(지름이 1인 원에 투영)
- 특성 벡터의 길이는 상관 없고 데이터의 방향(각도)만 중요할 때 사용
주의점
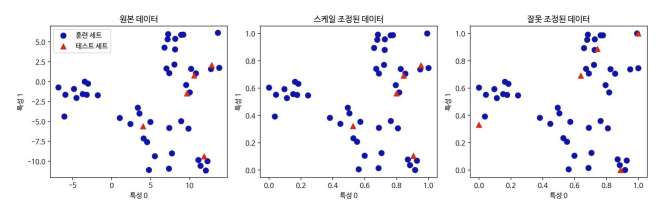
- 훈련세트와 테스트세트에 같은 변환을 적용해야 한다.
- 예를 들어 훈련세트의 평균과 분산을 이용해 훈련세트를 변환하고, 테스트세트의 평균
과 분산을 이용해 테스트세트를 각각 변환하면 잘못된 결과가 나올 수 있다.
→ 값의 범위가 다를 수 있으므로
실전
- 문제정의

- 문제정의
- 데이터 수집

- 데이터 수집
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()cancer.keys()
# malignant : 암
# benign : 암이 아니다
cancer['target_names']
cancer['feature_names']
- 데이터 전처리

- 데이터 전처리
-문제데이터
import pandas as pd
# 문제데이터
X = pd.DataFrame(cancer['data'], columns= cancer['feature_names'])
X.head()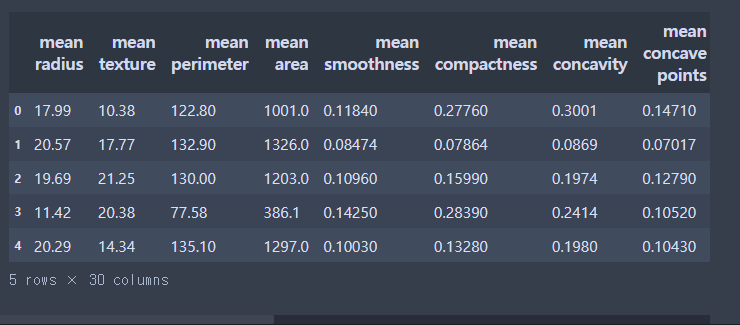
-정답데이터
# 정답데이터
y = pd.DataFrame(cancer['target'], columns=['cancer'])
y.head()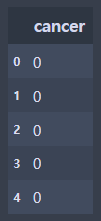
- 탐색적 데이터 분석

- 탐색적 데이터 분석
- 데이터 스케일링

- 데이터 스케일링
from sklearn.preprocessing import RobustScaler, StandardScaler, MinMaxScaler# 1. 스케일링 모델 불러오기
rbs = RobustScaler()
# 2. 가지고있는 데이터로 스케일링 모델에 학습 → 어떤값이 어떻게 변하는지 파악
rbs.fit(X)
# 3. 파악된 규칙을 통해서 값을 변형
X_rbs = rbs.transform(X)X.head()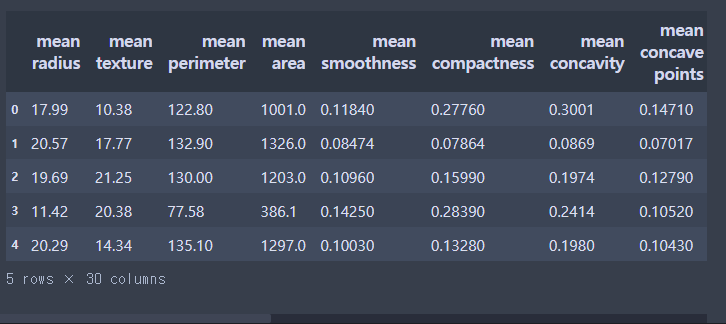
X_rbs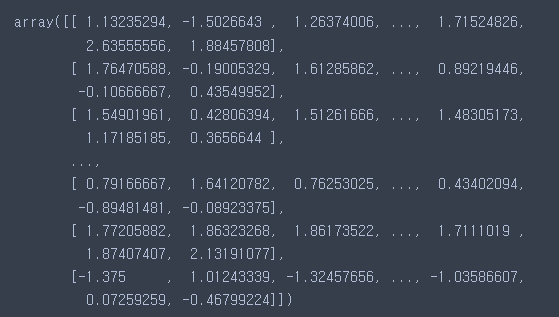
- 모델 선택 및 하이퍼 파라미터 튜닝

- 모델 선택 및 하이퍼 파라미터 튜닝
-train과 test로 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_rbs,y)-KNN모델 불러오기
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)- 학습

- 학습
knn.fit(X_train, y_train)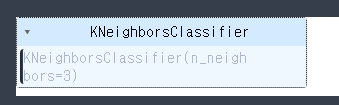
- 평가 및 예측

- 평가 및 예측
import warnings
warnings.filterwarnings(action='ignore')from sklearn.model_selection import cross_val_score
cross_val_score(knn, X_train, y_train, cv = 5).mean()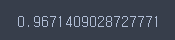
- StandardScaler / MinMaxScaler
-Standard
sds = StandardScaler()
sds.fit(X)
X_sds = sds.transform(X)-MinMax
mms = MinMaxScaler()
mms.fit(X)
X_mms = mms.transform(X)# 스케일러 사용 안함 : 0.92
# Robust 스케일러 사용 : 0.967
# Standard 스케일러 사용 : 0.969
# MinMax 스케일러 사용 : 0.955# 분류는 정확도라는 지표를 사용
# 몇 개 중에 몇 개 맞췄는가 100개 중에 92개 맞춤 = 0.92
# 암 vs 암 아닌지
# 모델 알고리즘(규칙) : 모든 사람은 암이다
# 암 환자 데이터 95개, 암 환자가 아닌 데이터 5개 = 0.95
노는게 제일 좋아~!
잘 보고 갑니다!