AdaBoost(Adaptive Boosting)
- RF처럼 의사결정 트리 기반의 모델 → 각각의 트리들이 독립적으로 존재하지 않음
-동작 순서
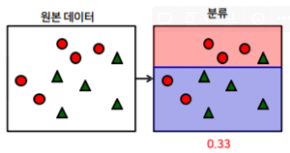
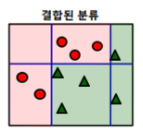
(1) 첫 번째 의사결정 트리를 생성 → 위쪽 빨간 원이 3개 있는 곳을 대충 분류시킴
→ 2개의 빨간 원과 1개의 녹색 세모가 잘못 구분됨
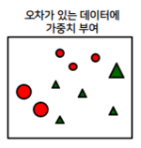
(2) 잘못된 2개의 빨간 원과 1개의 녹색 세모에 높은 가중치를 부여하고 맞은 것에는 빨간 원 3개와 녹색 세모 4개는 낮은 가중치 부여
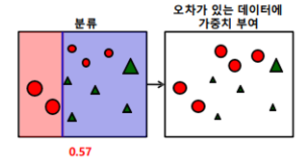
(3) 가중치를 부여한 상태에서 다시 분류 시킴 → 잘못된 3개의 빨간 원에 높은 가중치를 부여하고 맞은 5개의 녹색 세모는 낮은 가중치를 부여
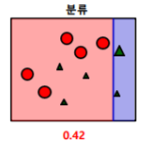
(4) 가중치를 부여한 상태에서 다시 분류 시킴
(5) 진행한 분류들을 결합한다.
- 주요 매개변수(Hyperparameter)
scikit-learn의 경우

-트리의 개수 : n_estimators
-선택할 데이터의 시드 : random_state
- 장단점
-보통 트리의 깊이를 깊게하지 않기 때문에 예측 속도는 비교적 빠르다.
-이전 트리의 오차를 반영해서 새로운 트리를 만 들기 때문에 학습속도
가 느리다.
-특성의 스케일을 조정하지 않아도 된다.
-희소한 고차원 데이터에는 잘 동작하지 않는다
-머신러닝의 성능을 마지막까지 쮜어짜야 할 때 활용
GBM(Gradient Booting Machine)
- 주요 매개변수(Hyperparameter)
scikit-learn의 경우

-트리의 개수 : n_estimators
-학습률 : learning_rate (높을수록 오차를 많이보정)
-트리의 깊이 : max_depth
-선택할 데이터의 시드 : random_state
Xgboost
- GBM의 단점 : 느림, 과대적합 문제
- 대규모 머신러닝 문제에 그래디언트 부스팅을 적용하려면 xgboost 패키지를 사용 → 분산환경을 고려
- GBM보다 빠름 → Early Stopping 제공
- 과대적합 방지를 위한 규제 포함
- CART (Classification And Regression Tree)을 기반으로 함 → 분류 와 회귀가 모두 가능
- 주요 매개변수(Hyperparameter)
scikit-learn의 경우

-트리의 개수 : n_estimators
-학습률 : learning_rate (높을수록 오차를 많이보정)
-트리의 깊이 : max_depth
-선택할 데이터의 시드 : random_state
실습
from sklearn.ensemble import AdaBoostClassifier
abc = AdaBoostClassifier(n_estimators=45)
abc.fit(X_train, y_train)
prd_abc = abc.predict(X_test)
sub['Survived'] = prd_abc # 예측결과 집어넣기
sub.to_csv('abc_pre.csv', index=False)cross_val_score(abc, X_train, y_train, cv=5).mean()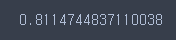
- Decision Tree 기반 모델들은 특성의 중요도를 계산
abc.feature_importances_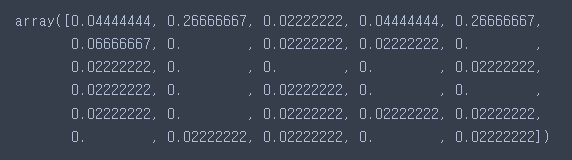
- 시각화
import matplotlib.pyplot as plt
# 특성의 갯수
num_feature = len(X_train.columns)
# 특성의 이름
name_feature = X_train.columns
# 특성 중요도
feature_importance = abc.feature_importances_- AdaBoost 모델 중요도 결과
import numpy as np
plt.barh(range(num_feature), feature_importance)
plt.yticks(np.arange(num_feature), name_feature)
plt.xlabel('importance')
plt.ylabel('attr')
plt.show()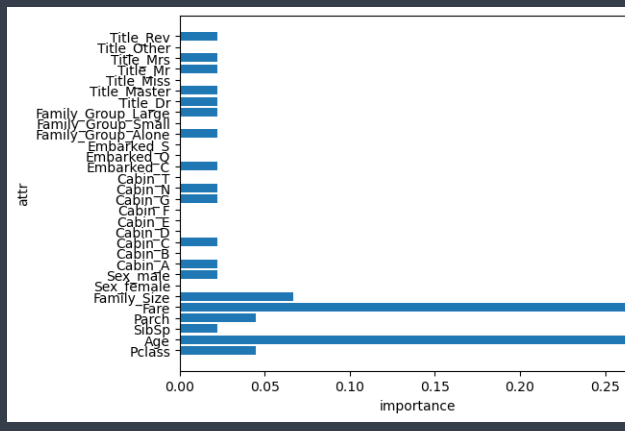
- RandomForest 모델 중요도 결과
# 특성의 갯수
num_feature = len(X_train.columns)
# 특성의 이름
name_feature = X_train.columns
# 특성 중요도
feature_importance = rf.feature_importances_
plt.barh(range(num_feature), feature_importance)
plt.yticks(np.arange(num_feature), name_feature)
plt.xlabel('importance')
plt.ylabel('attr')
plt.show()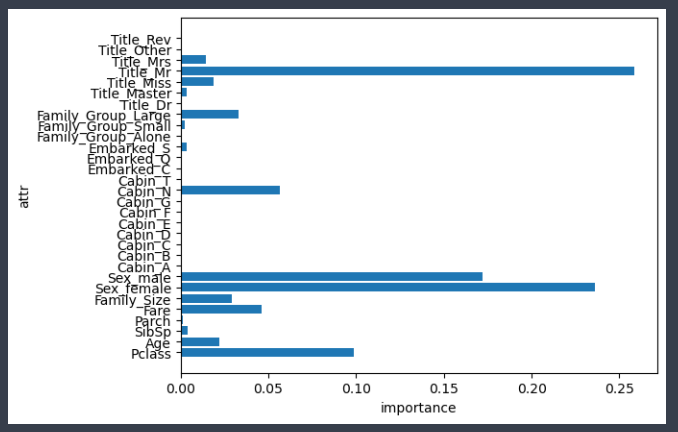
- GBM
from sklearn.ensemble import GradientBoostingClassifier
# GradientBoostingClassifier 학습
gbc = GradientBoostingClassifier(n_estimators=50, learning_rate=0.15)
gbc.fit(X_train, y_train)
# GradientBoostingClassifier 평가 → Kaggle 업로드
print(cross_val_score(gbc, X_train, y_train, cv=5).mean())
prd_gbc = gbc.predict(X_test)
# 제출 파일 불러오기
sub = pd.read_csv('./titanic/gender_submission.csv')
sub['Survived'] = prd_gbc # 예측결과 집어넣기
sub.to_csv('gbc_pre.csv', index=False)
# GradientBoostingClassifier 중요도 그래프 그리기
# 특성의 갯수
num_feature = len(X_train.columns)
# 특성의 이름
name_feature = X_train.columns
# 특성 중요도
feature_importance = gbc.feature_importances_
plt.barh(range(num_feature), feature_importance)
plt.yticks(np.arange(num_feature), name_feature)
plt.xlabel('importance')
plt.ylabel('attr')
plt.show()
- Kaggle 업로드


노는게 제일 좋아~!