바퀴를 다시 발명하지 마라(Don't reinvent the wheel)
- Python의 구성요소

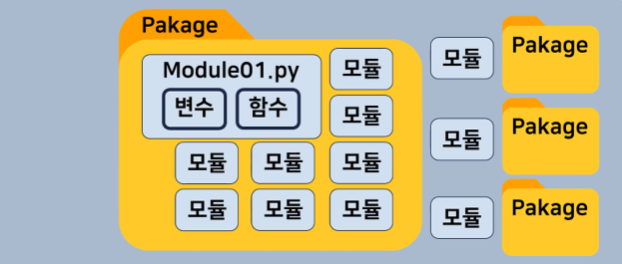
- Module : 함수들이 모여있는 파일
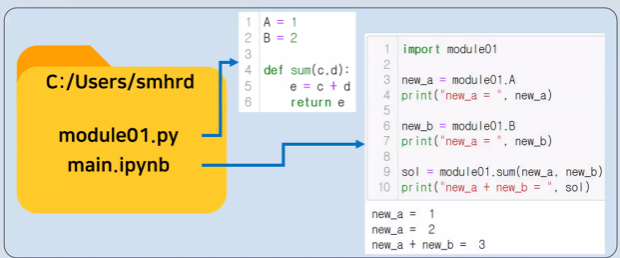
- Pakage : 여러 모듈을 포함하는 디렉토리
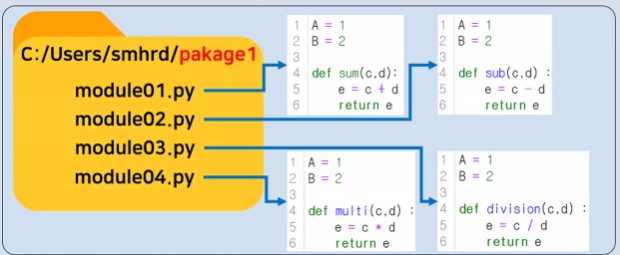
- Library : 여러 패키지와 모듈을 포함하는 코드 모음
Numpy
- "Nmerical Python"의 약자(numpy)
- Python에서 수치계산을 위한 핵심 라이브러리
- ndarray(N-dimensional array) 자료 구조를 지원
- 행, 열 계산에 최적화 된 패키지를 보유
- Numpy 라이브러리 로딩
import numpy as np
ndarray(N-dimensional array)
- 다양한 수학함수 지원
- 빠른 연산 속도
- 브로드 캐스팅(차원을 동일시 하는 기능)
- 1차원, 2차원, 3차원 등 다차원의 배열 지원
-array 내부에는 동일한 자료형을 가짐
-각 값들은 인덱스(index)가 부여되어 있음(순서가 있다.)
-
ndarray 생성하기
np.array(리스트 or 튜플)-
ndarray 생성하기 : 1차원(첫번째 방법)
# 시퀀스 자료형을 형변환 하는 방법 # list 생성 list1 = [1,2,3,4,5] arr1 = np.array(list1) arr1 -
ndarray 생성하기 : 1차원(두번째 방법)
# 직접 array화 시켜주는 방법 # list 생성 arr2 = np.array([2,3,4,5,6]) arr2 -
ndarray 생성하기 : 2차원
list2 = [[1,2,3],[4,5,6]] arr3 = np.array(list2) arr3 -
브로드 캐스팅
# 차원 수를 동일시하는 기능 # 리스트의 경우 문자열을 연결하듯이, 하나의 리스트로 이어붙임 list1 = [1,2,3] list2 = [4,5,6] print(list1 + list2, end = "\n\n") # ndarray의 경우 차원을 인식해서 각각의 요소들의 연산을 수행 arr1 = np.array(list1) arr2 = np.array(list2) print(arr1 + arr2, end = "\n\n") # 2차원과 1차원을 더했더니, 각각의 요소들을 찾아서 연산을 수행 arr3 = np.array([[1,2,3],[4,5,6]]) arr4 = np.array([7,8,9]) print(arr3 + arr4) # 1차원과 0차원(요소 하나)를 곱했더니, 각각의 요소들을 찾아서 연산을 수행 arr5 = np.array([1,1,1]) arr5 * 5
-
-
ndarray 확인하기 → "속성"이나 "키워드"(함수가 아님)
-
array의 모양(크기) 확인하기
# 2차원 → (행,열) # 1차원 → (요소개수,) print(arr3.shape) print(arr4.shape) -
array의 차원 확인
print(arr3.ndim) print(arr4.ndim) -
array의 전체 요소개수 확인하기
# len() → 배열의 첫 번째 차원의 "길이"를 반환 # size → 각각의 요소들의 개수를 반환 print(arr3.size) print(arr4.size) -
실습
# 일일이 print문으로 array의 속성들을 확인하려면 귀찮음... # 그래서 함수화 시켜줄거임! def array_info(array) : print(array) print(f"shape(모양) : {array.shape}") print(f"ndim(차원수) : {array.ndim}") print(f"size(요소 전체 개수) : {array.size}") print(f"dtype(데이터 타입) : {array.dtype}")
-
-
ndarray dtype 및 shape 변경
-
ndarray 생성 → 요소의 데이터 타입을 직접 지정해서 생성 가능
list3 = [[1.7, 4.2, 3.6], [4.1, 2.9, 5.8]] temp1 = np.array(list3) temp2 = np.array(list3, dtype = np.int64) array_info(temp1) print() array_info(temp2) -
만들어진 array의 요소 데이터 타입 바꾸기
astype(np.데이터타입)temp1 = temp1.astype(np.int64) array_info(temp1) -
array 모양 바꿔주기
# 2차원의 경우 행과 열의 값이 맞게 떨어져야 함! → size(요소 전체 개수)가 같아야함! # reshape(행, 열) temp1.reshape(3,2)
-
-
특정한 값으로 ndarray 생성하기
-
모든 값을 0으로 초기화
np.zeros((행,열)) → 2차원 이상의 array인 경우 튜플로 감싸주어야 함!arr_zeros = np.zeros((5,2)) arr_zeros -
모든 값을 1로 초기화
np.ones((행,열)) → 2차원 이상의 array인 경우 튜플로 감싸주어야 함!arr_ones = np.ones((5,2)) arr_ones = arr_ones.astype(np.int64) arr_ones -
모든 값을 원하는 값으로 초기화
np.full((행,열), 원하는 값) → 2차원 이상의 array인 경우 튜플로 감싸주어야 함!arr_full = np.full((5,2),10) arr_full -
랜덤값으로 배열 생성하기(int형)
# np.random.randint(시작값, 끝값, {size(행, 열)}) # random 라이브러리의 randint는 끝값을 포함했었음...→ 매우 번거로움! # np에서 제공하는 randint는 끝값을 포함하지 않음!! arr_randint = np.random.randint(1, 11, size = (3, 2)) arr_randint -
실습
# 1 ~ 50이 담긴 1차원 array 생성(리스트 활용) list4 = [] for i in range(1,51) : list4.append(i) arr = np.array(list4) arr -
ndarray로 범위 만들기
np.arange(시작값, 끝값, 증감량)arr2 = np.arange(1,51) arr2 = arr2.reshape(5,10) arr2 -
0 ~ 1까지의 랜덤 값으로 배열 생성
rand(행, 열) (행만 넣어도된다.)np.random.rand(5,5)
-
-
ndarray 연산
-ndarray의 특징은 요소별 연산에 특화
-브로드캐스팅 : 차원을 동일시하는 기능-
브로드 캐스팅
# 차원 수를 동일시하는 기능 # 리스트의 경우 문자열을 연결하듯이, 하나의 리스트로 이어붙임 list1 = [1,2,3] list2 = [4,5,6] print(list1 + list2, end = "\n\n") # ndarray의 경우 차원을 인식해서 각각의 요소들의 연산을 수행 arr1 = np.array(list1) arr2 = np.array(list2) print(arr1 + arr2, end = "\n\n") # 2차원과 1차원을 더했더니, 각각의 요소들을 찾아서 연산을 수행 arr3 = np.array([[1,2,3],[4,5,6]]) arr4 = np.array([7,8,9]) print(arr3 + arr4) # 1차원과 0차원(요소 하나)를 곱했더니, 각각의 요소들을 찾아서 연산을 수행 arr5 = np.array([1,1,1]) arr5 * 5 -
각각의 요소에 +3씩 연산
arr3 + 3
-
-
ndarray 인덱싱 & 슬라이싱
-인덱싱(indexing) : 값을 가리키다 → 자료 구조 내에서 "1개의 요소"에 접근하는 것
-슬라이싱(slicing) : 값을 잘라오다 → 자료 구조 내에서 "여러 개의 요소"에 접근하는 것
-인덱스(index) : 데이터의 순서 → 방 번호-
1차원 array 생성 후 인덱싱
arr_1 = np.arange(10) # 시작값 생략 가능 arr_1[7] -
슬라이싱
arr_1[3:9] -
슬라이싱을 하고 한번에 데이터 넣기
list1 = [] for i in range(10) : list1.append(i) # 리스트값 수정 # 리스트는 슬라이싱하고 값을 넣게 되면, 범위 자체가 하나의 요소로 반환 list1[3:8] = [10] print(list1) # array값 수정 # array는 슬라이싱 된 요소들에 각각 하나씩 값을 수정 arr_1[3:8] = 10 print(arr_1)
-
-
2차원 array 인덱싱 & 슬라이싱
-인덱싱 : array명[행값, 열값]
-슬라이싱 : array명[행의 시작값:행의 끝값, 열의 시작값:열의 끝값]- 2차원 array
arr2 = np.arange(1,51).reshape(5,10) arr2 - print(arr2[3][3]) 일반인덱싱 : 두 번의 연산을 수행
print(arr2[3,3]) # 튜플인덱싱 : 한 번의 연산을 수행 - 2차원 array 슬라이싱
array명[행의 시작값:행의 끝값, 열의 시작값:열의 끝값]arr2[2:5, :9] - 실습1
print(arr2[0:5,0]) # 선생님 풀이 print(arr2[:,0]) # 인덱싱과 슬라이싱 섞어서 가능! - 실습2
print(arr2[:4,:5]) - Fancy 인덱싱 → 다중 인덱싱(정수 배열 인덱싱)
array명[[행1, 행2,...],[열1, 열2,...]]arr2[[2,3],[2,3]]
- 2차원 array
-
ndarray 연산 함수
-
랜덤 array 생성
arr = np.random.randint(1, 10, size=(2,5)) arr -
sum() 함수 : 합계
# Python 내장함수 sum print(sum(arr)) # numpy sum print(arr.sum()) print(np.sum(arr)) # -> 더 직관적이라서 이걸 더 추천 -
mean() : 평균
print(arr.mean()) print(np.mean(arr)) -
sqrt() : 제곱근(루트)
# sqrt() 함수는 array에 접근해서 작성하는게 아닌, np에서 호출해서 인자값으로 던져주어야 함 # 각 함수 사용법들이 다르다!! # print(arr.sqrt()) print(np.sqrt(arr))
-
Universally 함수
-
이외에도 굉장히 많은 수학적 함수를 가지고 있음
-
단일 배열에서 사용하는 함수
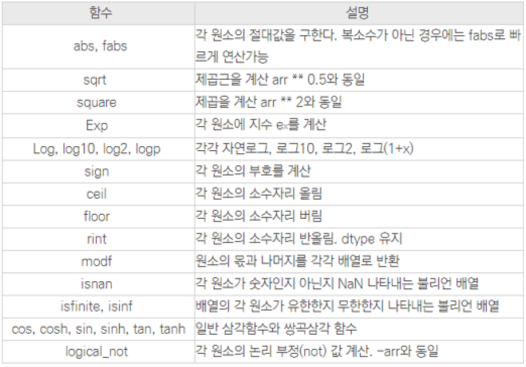
-
서로 다른 배열간에 사용하는 함수
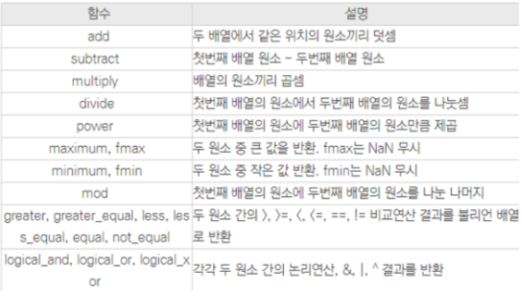
-
Boolean 인덱싱
-배열 안에서 조건을 충족(특정 조건을 만족)하는 True인 값들만 추출해주는 인덱싱 방법
-간단히 말해서 필터링을 연상하면 됨-
array 생성
score = np.array([80,75,55,96,30]) score -
80점 이상인 데이터만 추출
# 1.mask 만들기 mask = score >= 80 mask # 2.인덱싱 score[mask] score[score >= 80]
-
