빅데이터 분석에 기초가 되는 하둡 클러스터를 세팅해보고 PySpark를 통해 기초 데이터 분석까지 실행해 볼 예정이다.
하둡 클러스터 서버 구성도
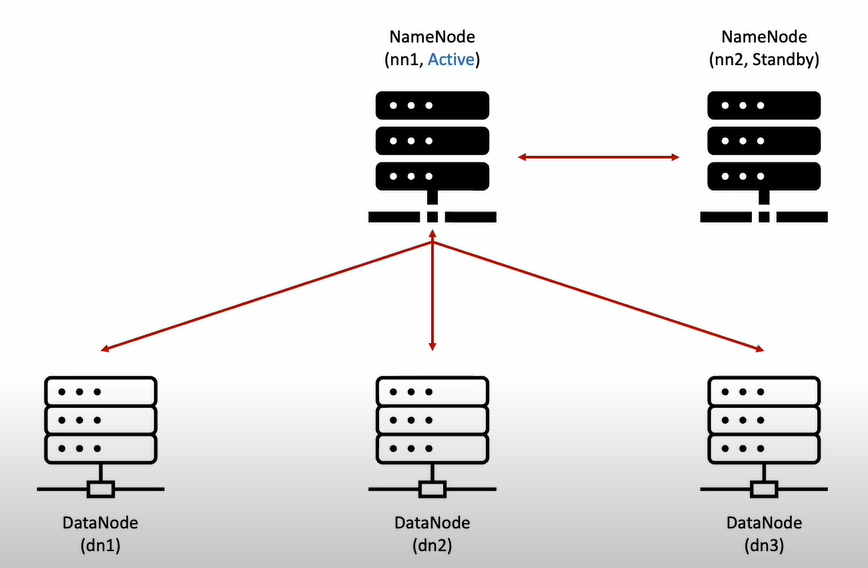
- 2대의 Namenode 와 3대의 Datanode로 구성되어 있다.
- Active Namenode의 Failover 대비로 Standby Namenode 또한 대기시켜놓는다.
- 환경 구성
Apache Hadoop 3.2.3 + Yarn
Apache Spark 3.2.1
Apache Zookeeper 3.8.0
Apache Zeppelin 0.10.1Node 종류 및 역활
Namenode
-
Meta Data 관리
- Fsimage 파일
네임스페이스와 블록 정보 - Edits 파일
파일의 생성, 삭제에 대한 트랜잭션 로그
메모리에 저장하다가 주기적으로 생성
VERSION: 현재 실행 중인 HDFS의 ID, 타입 등 정보 edits_0000xxx-0000xxx: 트랜잭션 정보. edits_트랜잭션시작번호-트랜잭션종료번호 까지의 정보를 저장 eidts_inprogress_000xx: 최신 트랜잭션 정보. 압축되지 않은 정보 fsimage_000xxx: 000xxx 까지 트랜잭션 정보가 처리된 fsimage fsimage_000xxx.md5: fsiamge의 해쉬값 committed-txid: 현재 트랜잭션 ID추가) 현재 파일럿프로젝트
hdfs-site.xml의 journalnode dir 위치에서 확인 가능하다.
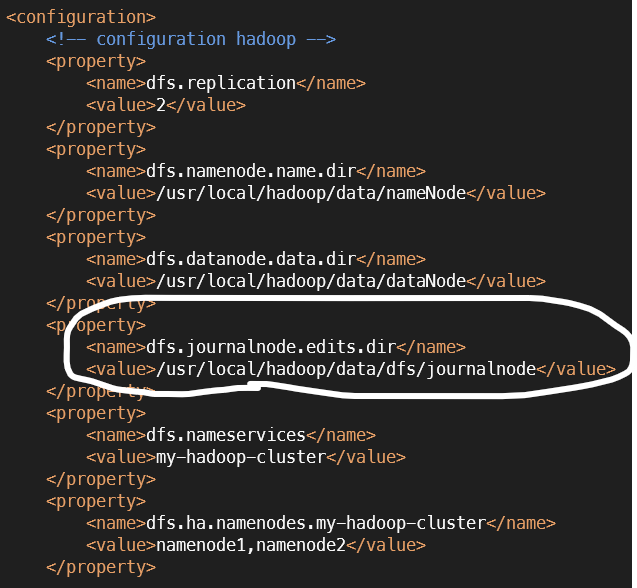

- Fsimage 파일
-
DataNode 관리(하트비트, 블럭리포트)
- 하트비트
dfs.heartbeat.interval
: 데이터노드가 주기적으로 살아있음을 알리는 통신 - 블록리포트
dfs.blockreport.intervalMsec
: HDFS에 저장된 파일에 대한 최신 정보 유지
- 하트비트
Datanode
- 파일 I/O
- Spark 연산처리
- Datanode 속 JournelNode
: 2분마다 Edit log(data block의 변경 이력을 남겨놔서 Namenode에서 최신 파일 정보 유지할 수 있도록 수정함) 작성
HDFS 작동 원리
네임노드 구동 과정
- Fsimage(디스크에 저장되어 있는 마지막 스냅샷)를 읽어 메모리에 적재합니다.
- JournelNode에서 만든 Edit log들을 읽어와 변경내역에 반영
- 현재 메모리 상태를 스냅샷으로 생성하여 Fsimage 생성
- 데이터 노드로부터 블록리포트를 수신하여 매핑정보 생성
- 서비스 시작
파일 읽기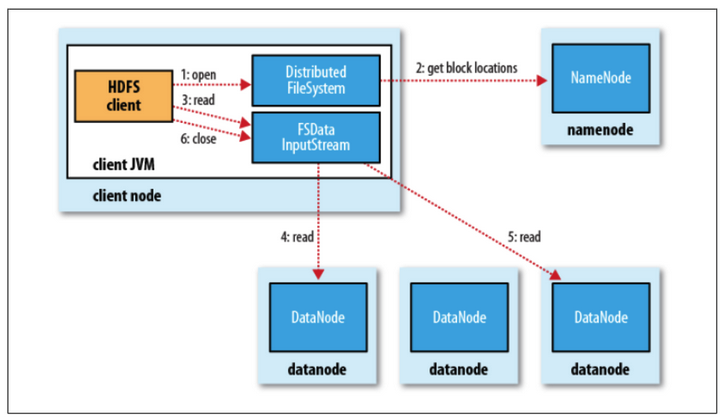
- Client에서 네임노드에 파일이 보관된 블록위치 요청
- Namenode가 블록 위치 반환
- 각 데이터 노드에 파일 블록을 요청
- 여기서 노드의 블록이 깨져있다면 네임노드에 이를 통지 후 다른 불록 확인
파일 쓰기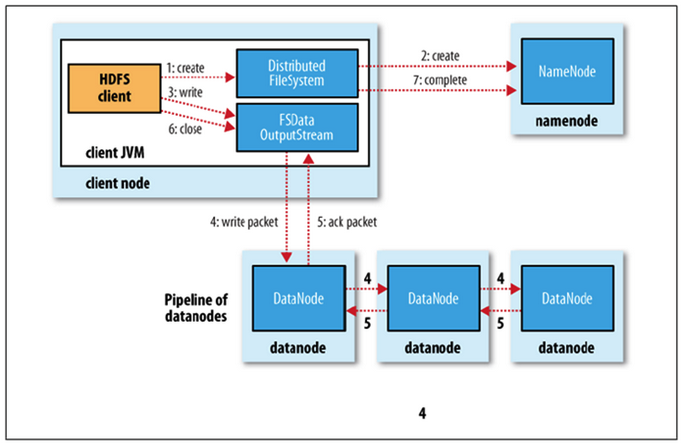
- Client가 네임노드에게 써야할 파일 전달
- Namenode가 해당 파일을 저장할 node 목록 반환
- 데이터 노드에 파일 쓰기 요청
- 데이터 노드간 복제가 진행
[참고]
- 빅데이터 - 하둡, 하이브로 시작하기 https://wikidocs.net/23582
- 하둡 데몬 메커니즘의 이해 https://likebnb.tistory.com/162

개발자입니다.