빅데이터환경설정
1.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 0. 개요

회사 빅데이터 분석 환경 구축을 위한 프로세스 과정을 기록하기 위하여 글을 작성하게 됨단계를 나눠서 프로젝트를 발전 시키고 싶음관련 내용으로 개발경험이 존재하지 않아서 리서치 & 스터디를 하며 구축할 예정 전일자 하루치 데이터를 기반으로 분석하여 분석 결과 도출그로
2.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 1. 하둡 Cluster 구성도 및 node의 역활
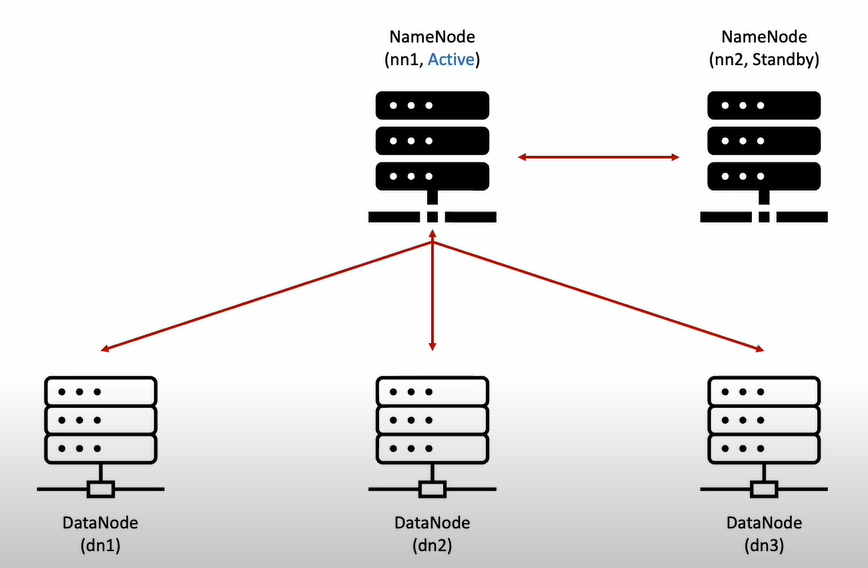
빅데이터 분석에 기초가 되는 하둡 클러스터를 세팅해보고 PySpark를 통해 기초 데이터 분석까지 실행해 볼 예정이다.2대의 Namenode 와 3대의 Datanode로 구성되어 있다.Active Namenode의 Failover 대비로 Standby Namenode
3.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 2. Centos base docker Java & Hadoop 설치
이제부터 Centos docker 기반 세팅할 예정
4.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 3. Centos base docker Spark & ZooKeeper 설치
이번 챕터에서는 2강에 이어서 CentOS 기반 base image 생성을 진행해볼 예정이다. 🎈Python 설치 1. Python & PySpark 설치 2. CentOS Python 환경설정 🎈Spark 설치 1. Spark 설치 및 압축 해제 google에
5.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 4. On-Premise 서버 간 ssh 통신 네트워크 세팅 및 도커 실행
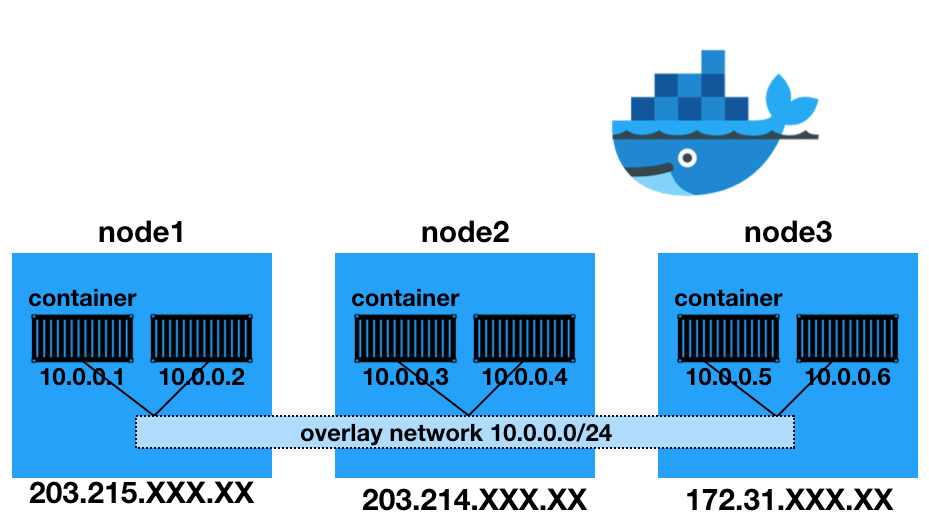
On-Premise 서버 간 네트워크 통신을 위해 Overlay 네트워크를 구성하고 hostname, rpc 통신을 위한 static IP 할당
6.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 5. Hadoop Ecosystem 구동
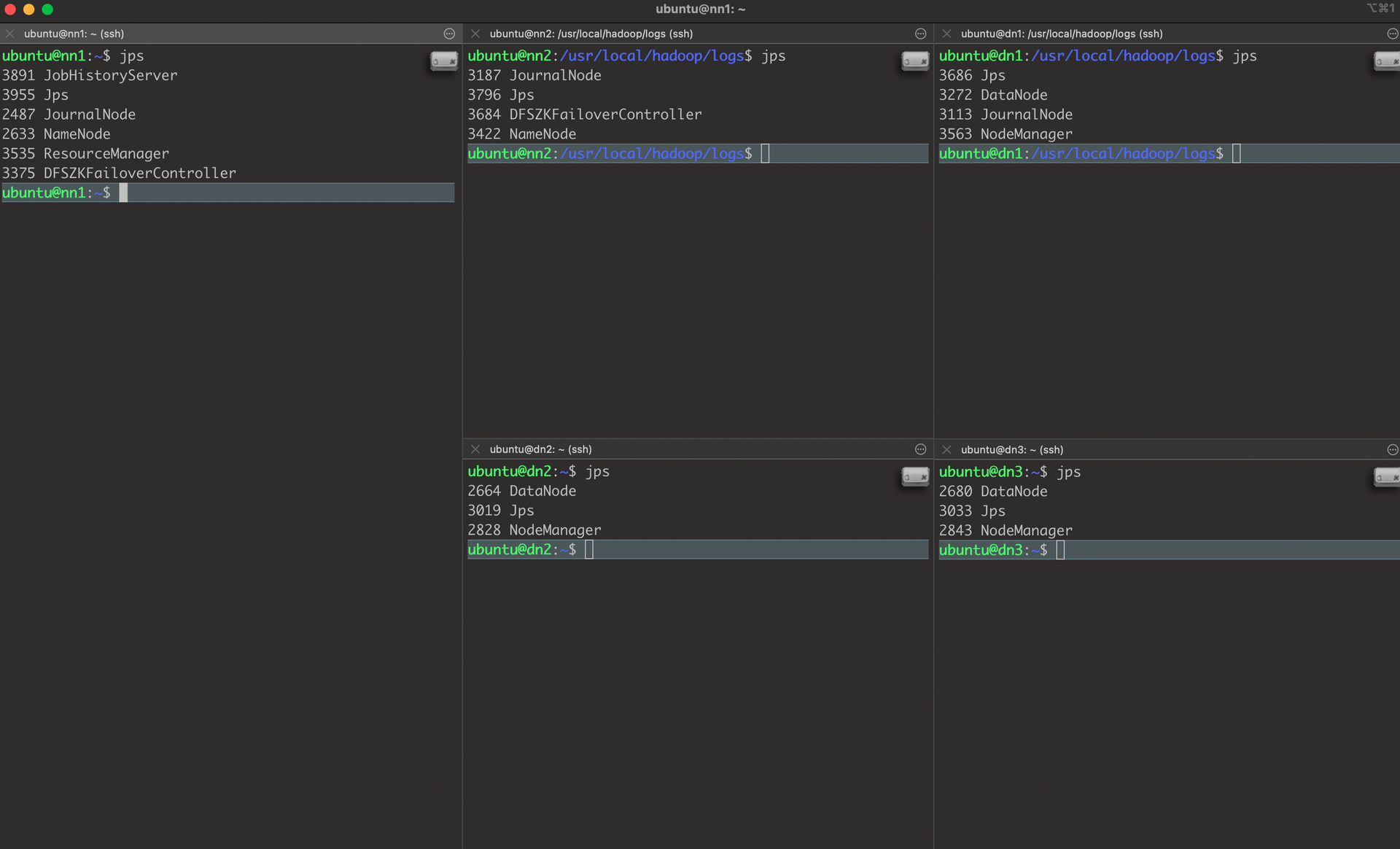
Zookeeper, Hadoop & yarn, Spark Cluster & PySpark 실행 확인(WEB UI로 확인)전체 시작,종료 Script 작성하여 장애대응을 할 수 있도록 준비할 예정이다.해당 내용은 추후 전체 시작 스크립트에서 수정 가능하도록 반영할 예정h
7.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 6. 전체 재실행 스크립트

Hadoop, Yarn, Spark, Zookeeper 를 모두 실행 가능한 sh파일 권한 확인Hadoop, Yarn, Spark, Zookeeper 를 모두 중지 가능한 sh재실행 스크립트 (cluster-restart-all.sh)Hadoop, Yarn, Spark
8.[hadoop] 빅데이터 분석 환경 구축 On-Premise - 7. Zeppelin 설치 & PySpark 실행
지금까지 설정한 Hadoop, Yarn, Spark, Zookeeper 클러스터 환경에 Zeppelin을 연동하기 위해 설치 및 환경설정을 진행한다.: Apache Zeppelin은 Spark를 통한 데이터 분석의 불편함을 Web기반의 Notebook을 통해서 해결해보