지금까지 설정한 Hadoop, Yarn, Spark, Zookeeper 클러스터 환경에 Zeppelin을 연동하기 위해 설치 및 환경설정을 진행한다.
Zeppelin 설치
: Apache Zeppelin은 Spark를 통한 데이터 분석의 불편함을 Web기반의 Notebook을 통해서 해결해보고자 만들어진 어플리케이션이다.
Q : Notebook Style이란?
A : Web기반 Notebook 스타일 환경이란 Web에 워드프로세서 처럼 아무거나 입력 가능한 하얀 화면이 뜨고 여기에 코드를 작성-실행-결과확인-코드수정을 반복하면서 원하는 결과를 만들어 낼수있는 작업환경을 말한다.
1. Zeppelin 설치
# 디렉토리 이동
cd /install_dir
# Zeppelin 다운로드
sudo wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz
# Zeppelin 압축 해제
sudo tar -zxvf zeppelin-0.10.1-bin-all.tgz -C /usr/local/
# Zeppelin 디렉토리 이름 변경
sudo mv /usr/local/zeppelin-0.10.1-bin-all/ /usr/local/zeppelin
# root 계정 사용하지 않는 부분에서는 소유주 변경을 해야한다.
# docker container를 하나의 프로그램이라 생각하여 root를 사용하였다.
# Zeppelin 디렉토리 소유자 변경
sudo chown -R $USER:$USER /usr/local/zeppelin2. CentOS Zeppelin 환경설정
# 시스템 환경변수 편집
sudo vim /etc/profile
# 아래 내용 추가 후 저장
PATH 뒤에 ":/usr/local/zeppelin/bin" 추가
ZEPPELIN_HOME=/usr/local/zeppelin
# 시스템 환경변수 활성화
source /etc/profile
# 사용자 환경변수 편집
sudo echo 'export ZEPPELIN_HOME=/usr/local/zeppelin' >> ~/.bash_profile
# 사용자 환경변수 활성화
source ~/.bash_profile3. zeppelin-site.xml 수정
# Zeppelin 환경설정 디렉토리 이동
cd /usr/local/zeppelin/conf
# zeppelin-site.xml 파일 복사
cp zeppelin-site.xml.template zeppelin-site.xml
# zeppelin-site.xml 파일 편집
vim zeppelin-site.xml
# 아래 내용 수정 후 저장
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server binding address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>18888</value>
<description>Server port.</description>
</property>4. zeppelin-env.sh 수정
# zeppelin-env.sh 파일 복사
cp zeppelin-env.sh.template zeppelin-env.sh
# zeppelin-env.sh 파일 편집
vim zeppelin-env.sh
# 아래 내용 수정 후 저장
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export HADOOP_HOME=/usr/local/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark
export SPARK_MASTER=yarn
export ZEPPELIN_PORT=18888
export PYTHONPATH=/usr/bin/python3
export PYSPARK_PYTHON=/usr/bin/python3
export PYSPARK_DRIVER_PYTHON=/usr/bin/python35. Zeppelin 실행
/usr/local/zeppelin/bin/zeppelin-daemon.sh start
# Zeppelin 실행결과 log
Zeppelin start [ OK ]6. Zeppelin Web UI 확인
http://[nn1의 Public IP]:18888 (기본 계정 : admin / admin)
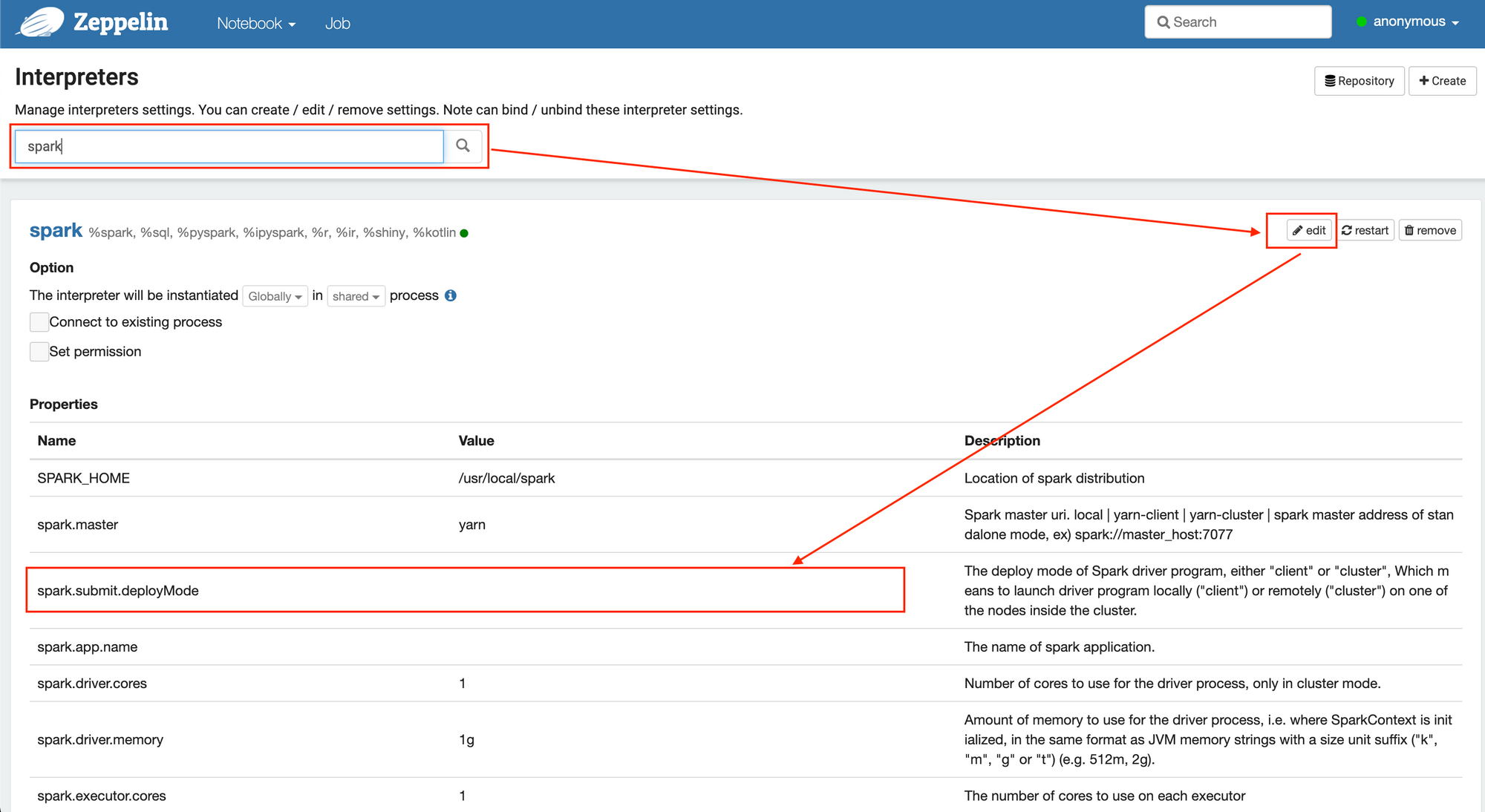
7. Zeppelin Web UI 환경설정
- 우측 상단 interpreter 클릭 후 spark 검색 -> "spark.submit.deployMode" 값을 "cluster"로 변경하여 저장
🎈Zeppelin 기반 PySpark 예제
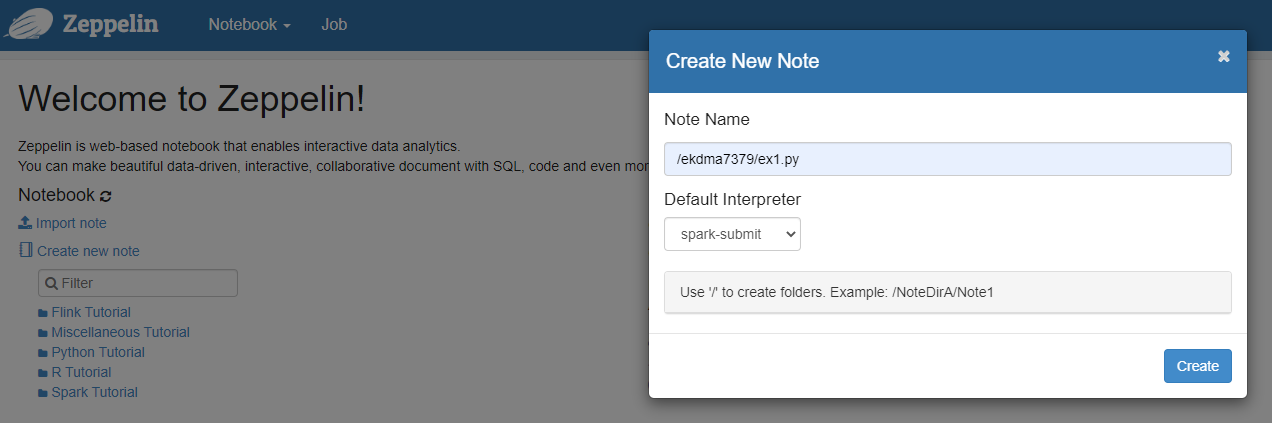
1. note 생성
- Zeppelin 홈 화면에서 “Create new note” 클릭 후 Note Name을 “/ekdma7379/ex1.py”로 지정하고 Default Interpreter를 “spark-submit”으로 설정
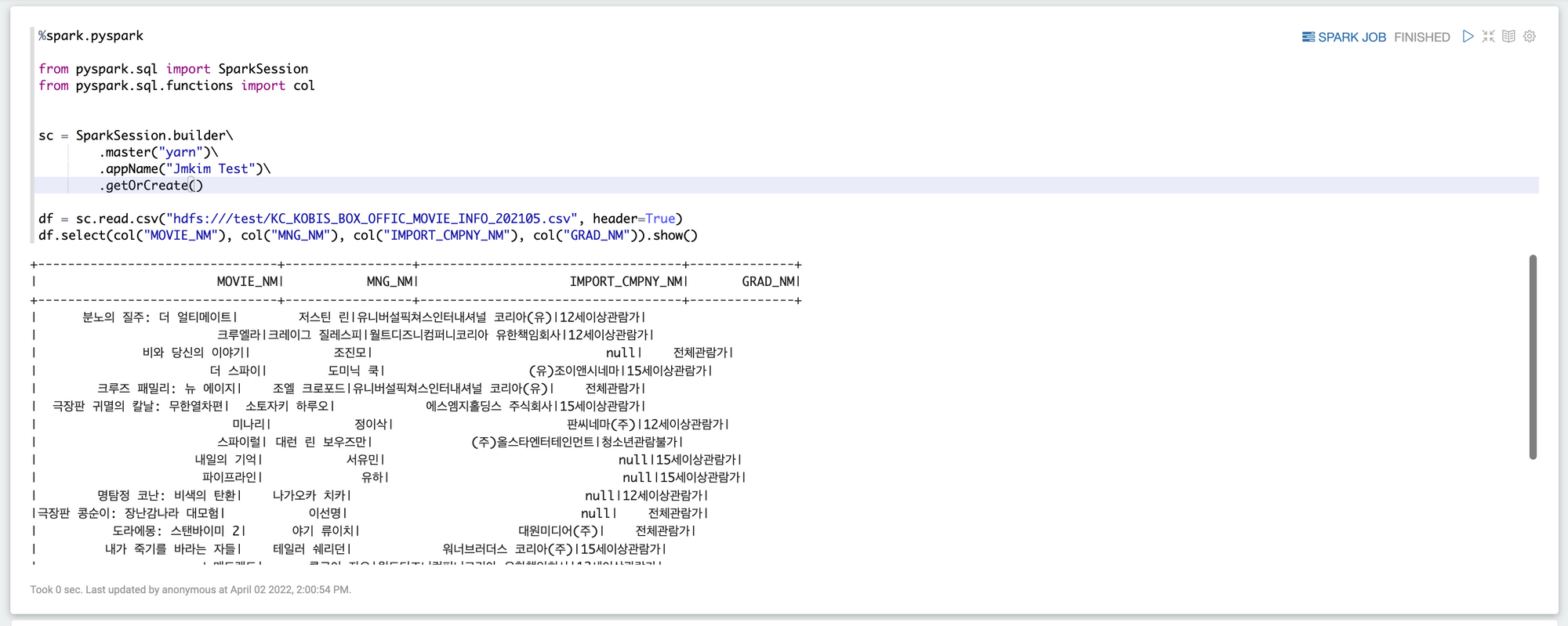
2. pySpark ex1 - csv 읽고 출력
%spark.pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
sc = SparkSession.builder\
.master("yarn")\
.appName("wontak Test")\
.getOrCreate()
df = sc.read.csv("hdfs:///test/KC_KOBIS_BOX_OFFIC_MOVIE_INFO_202105.csv", header=True)
df.select(col("MOVIE_NM"), col("MNG_NM"), col("IMPORT_CMPNY_NM"), col("GRAD_NM")).show()결과
2-1. csv 스키마 출력
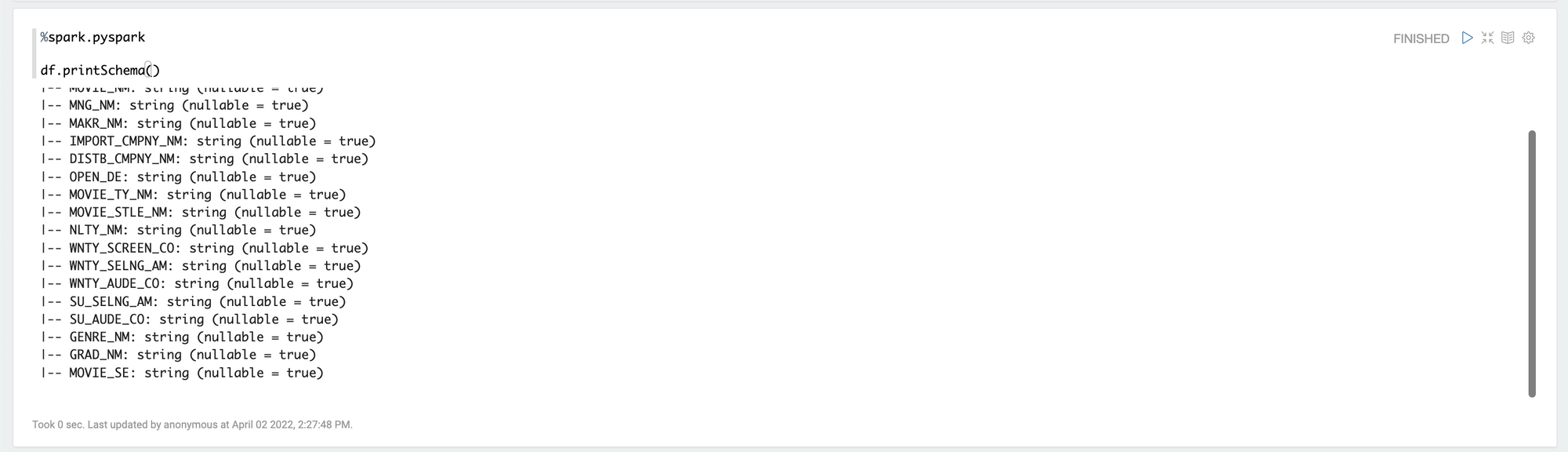
%spark.pyspark
df.printSchema()결과
2-2. csv View 생성 후 Spark sql
%spark.pyspark
df.createOrReplaceTempView("movie")
%spark.sql
select * from movie결과

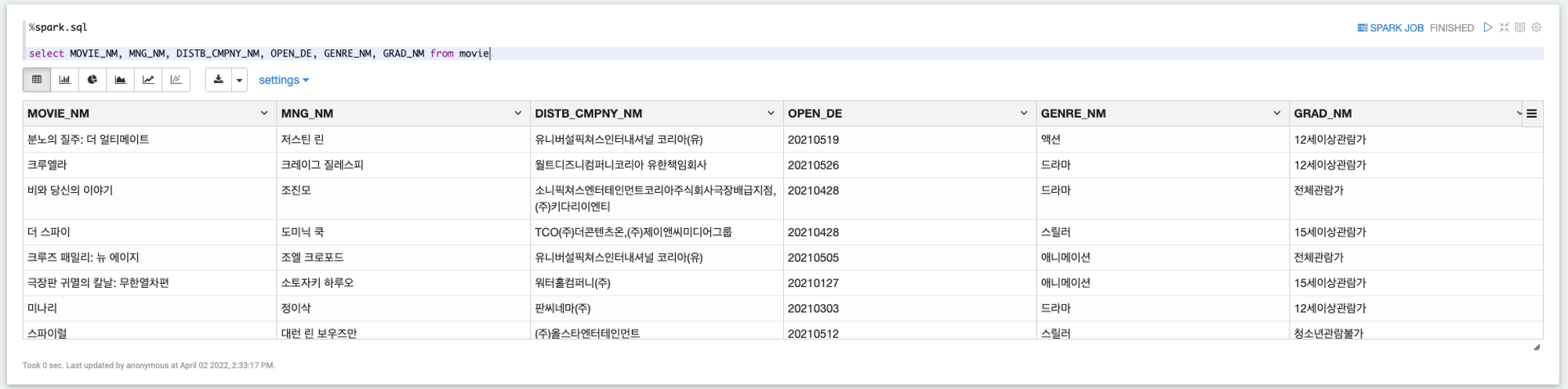
%spark.sql
select MOVIE_NM, MNG_NM, DISTB_CMPNY_NM, OPEN_DE, GENRE_NM, GRAD_NM from movie결과
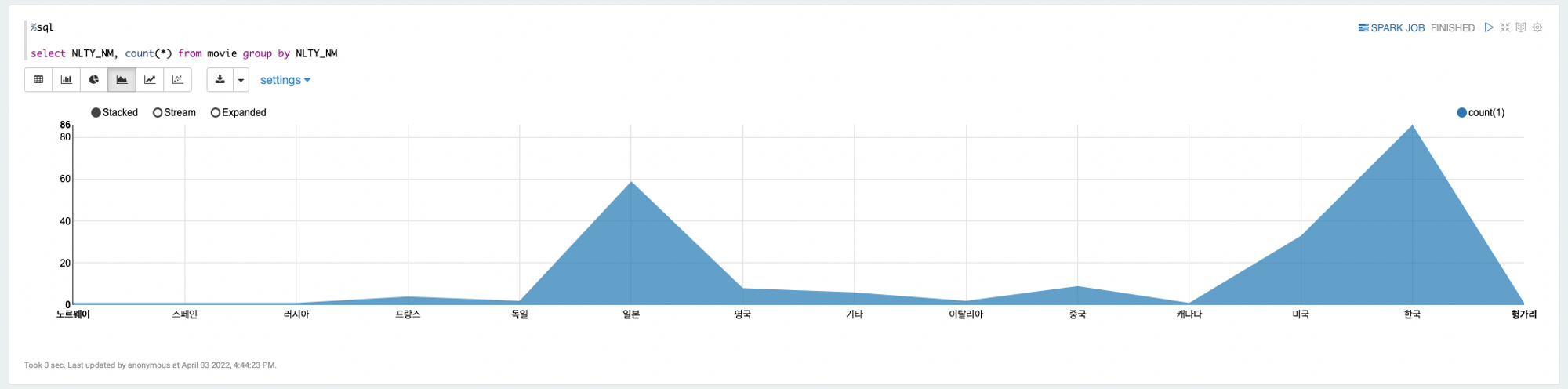
%spark.sql
select NLTY_NM, count(*) from movie group by NLTY_NM결과
[참고]

개발자입니다.