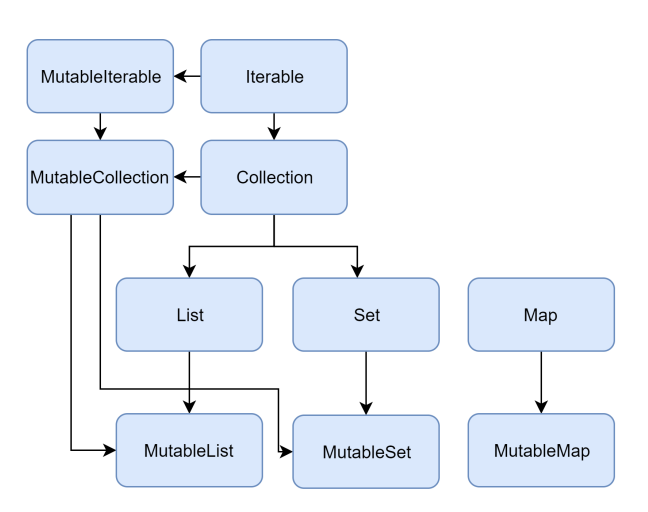
컬렉션 타입
코틀린 표준 라이브러리는 기본 컬렉션 타입인 List, Set, Map을 제공합니다.
또한 컬렉션은 두가지 종류로 나뉩니다.
불변 컬렉션(Immutable) : 읽기 전용 컬렉션
가변 컬렉션(Mutable) : 삽입, 수정, 삭제와 같은 쓰기 작업이 가능한 컬렉션
컬렉션 생성 방법
컬렉션을 생성할때 가장 일반적인 방법은 표준 라이브러리 함수를 사용입니다.
Immutable List 생성
val currencyList: List<String> = listOf("달러", "유로", "원")Mutable List 생성
val mutableCurrencyList = mutableListOf<String>()
mutableCurrencyList.add("달러")
mutableCurrencyList.add("유로")
mutableCurrencyList.add("원")Mutable 리스트에서 apply 메서드를 사용하면 가독성이 좋아집니다.
val mutableCurrencyList = mutableListOf<String>().apply {
add("달러")
add("유로")
add("원")
}Immutable Set 생성
val numberSet = setOf(1, 2, 3, 4)Mutable Set 생성
val mutableSet = mutableSetOf<Int>()Immutable Map 생성
코틀린의 Map에서는 to 라는 중위 함수로 key - value 구조를 전달합니다.
val numberMap = mapOf("one" to 1, "two" to 2)Mutable Map 생성
코틀린에서는 map.put("key",value)보다 아래와 같은 문법으로 key value를 선언하는 것을 선호합니다.
val mutableNumberMap = mutableMapOf<String, Int>()
mutableNumberMap["one"] = 1
mutableNumberMap["two"] = 2
mutableNumberMap["three"] = 3코틀린은 컬렉션 빌더를 사용하여 컬렉션을 생성할 수 있습니다.
buildList, buildSet, buildMap 3종류를 제공하며 build 내부에선 Mutable 즉 가변이고 반환시엔 Immutable 불변입니다.
// numberList는 ImmutableList
val numberList: List<Int> = buildList {
// buildList 내부는 MutableList
add(1)
add(2)
add(3)
}linkedList나 ArrayList 등 특정 구현체를 사용하고 싶은 경우 구현체의 생성자를 사용하면 됩니다.
val linkedList = LinkedList<Int>().apply {
add(1)
add(2)
add(3)
}컬렉션 반복하기
코틀린의 컬렉션은 Iterable의 구현체이므로 순차적 반복이 가능합니다.
val iterator = currencyList.iterator()
while (iterator.hasNext()) {
println(iterator.next())
}하지만 위와 같은 코드는 가독성이 좋지 않습니다.
코틀린도 자바에서 가장 많이 쓰이는 문법인 foreach를 사용한 iterable을 구현할 수 있기에 더 간결한 코드를 생성할 수 있습니다.
for (currency in currencyList) {
println(currency)
}코틀린 표준 라이브러리에는 컬렉션 사용시 자주 사용되는 패턴인 forEach, map, filter 와 같은 유용한 인라인 함수를 제공합니다.
currencyList.forEach {
println(it)
}
inline method - map
val lowerList = listOf("a", "b", "c", "d")
val upperList = mutableListOf<String>()
val upperList = lowerList.map { it.uppercase() }
println(upperList)
// [A, B, C, D]inline method - filter
val filteredList = upperList.filter { it == "A" || it == "C" }
println(filteredList)
// [A, C]자바8의 stream
자바의 스트림은 중간 연산자(map, filter, flatMap 등)만 사용했을땐 아무런 동작도 하지 않고 terminal operator를 사용해야 값을 얻어낼 수 있습니다.
val filteredList = upperList.stream().filter { it == "A" || it == "C" }; //
println(filteredList)
java.util.stream.ReferencePipeline$2@77b52d12
val filteredList = upperList.stream().filter { it == "A" || it == "C" }.collect(Collectors.toList());
println(filteredList)
// [A, C]코틀린에서도 sequence를 사용해 자바의 stream과 같이 Lazy하게 동작시킬 수 있습니다.
또 시퀀스 API도 자바의 stream API와 같이 최종 연산자를 사용해야 중간 연산자가 동작합니다.
val filteredList = upperList.asSequence().filter { it == "A" || it == "C" }
println(filteredList)
// kotlin.sequences.FilteringSequence@7f560810
val filteredList = upperList.asSequence().filter { it == "A" || it == "C" }.toList()
println(filteredList)
// [A, C]일반적으로 인라인 함수는 각각 함수가 동작할때마다 조건에 맞는 컬렉션을 생성합니다.
upperList
.filter { it == "A" } //컬렉션 생성
.filter { it == "C" } //컬렉션 생성
.filter { /.../ } //컬렉션 생성
// 총 3개의 컬렉션 생성, 원본 데이터 * 3의 메모리 사용시퀀스 API는 각각의 함수가 동작할때 시퀀스를 생성하고 최종 연산자를 호출할때 1개의 컬렉션을 생성합니다.
upperList.asSequence()
.filter { it == "A" }
.filter { it == "C" }
.filter { /.../ }
.toList() //컬렉션 생성
// 하나의 컬렉션만 생성일반적으론 인라인 함수가 빠르기 때문에 인라인 함수를 쓰고 대량의 데이터를 다룰때는 시퀀스 API를 사용을 권장합니다.
데이터 클래스
데이터를 보관하거나 전달하는 목적을 가진 객체를 만들때 사용합니다. ex) DTO
data class Person(val name: String, val age: Int)데이터 클래스를 사용하면 컴파일러가 equals(), hashCode(), toString(), componentN(), copy()와 같은 메서드들을 자동으로 생성해줍니다.
기존 자바에선 주로 Lombok을 사용
@Data
public class Person {
private final String name;
private final int age;
}또 제가 가장 좋아하는 record 클래스도 JDK 15 이상부터 지원해줍니다.
public record Person(String name, int age) {
}코틀린의 데이터 클래스는 데이터 저장을 목적으로 하는 클래스는 일반적으로 3가지 함수 toString, equals, hashCode를 재정의하는데 데이터 클래스를 사용하면 자동으로 생성해줍니다.
일반 클래스에서 toString, equals, hashCode를 쓸 경우 직접 구현하거나 IDE를 통해 생성해야합니다.
객체 동등성 비교 (equals)
일반적으로 두개의 인스턴스의 동등성 비교를 위해 equals를 재정의합니다.
객체의 동등성 비교시 결과에 대한 차이 일반 클래스
class Person(val name: String, val age: Int)
fun main() {
val person1 = Person(name = "tony", age = 12)
val person2 = Person(name = "tony", age = 12)
println(person1 == person2)
} // false
data class Person(val name: String, val age: Int)
fun main() {
val person1 = Person(name = "tony", age = 12)
val tony2 = Person(name = "tony", age = 12)
println(person1 == person2)
} // true
equals를 재정의할때 반드시 hashCode도 재정의 해야합니다.
JVM 언어 기준으로 객체 비교시 equals로 true를 반환하는 객체는 hashCode도 같아야합니다.
equals가 true인데 hashCode가 다르다면 Hash계열 자료구조에서 정상적으로 동작하지 않습니다. // ex) HashSet
불변성을 유지하며 복사 (copy)
- 데이터 클래스의 copy()를 사용하면 객체의 불변성을 쉽게 유지할 수 있습니다.
- var를 사용해 프로퍼티를 변경가능하도록 하면 불변이 아니게됩니다.
- 불변성이 깨졌을때의 문제점은 Hash계열 자료구조에서 의도치 않은 버그가 발생할 수 있기 때문에 꼭 불변성을 유지시켜주는 것이 좋습니다.
- multi thread 환경에서 객체의 불변성을 유지하는 것은 동기화 처리를 줄여주고 안정성을 유지하기 위해 중요합니다.
- 유지보수 관점에서도 여러 소스에서 객체의 프로퍼티를 각각 변경하고 있으면 코드를 파악하는데 어려움이 많습니다.
- 때문에 기존 객체를 수정하는 것보다 새로운 객체로 복사해서 사용하는 것이 좋습니다.
- copy를 사용하면 프로퍼티를 val로 유지해 불변성을 유지하는데 도움이 되고 원하는 프로퍼티만 변경하여 새로운 불변 객체를 생성할 수 있습니다.
copy 미사용
data class Person(var name: String, var age: Int)
fun main() {
val person1 = Person(name = "tony", age = 12)
val set = hashSetOf(person1)
println(set.contains(person1))
// true
person1.name = "strange"
println(set.contains(person1))
// false
}copy 사용
data class Person(val name: String, val age: Int)
fun main() {
val person1 = Person(name = "tony", age = 12)
val person2 = person1.copy(name= "strange")
println(person2.toString())
// Person(name=strange, age=12)
}componentN
componentN은 데이터 클래스에 정의된 프로퍼티를 정의된 순서대로 가져올 수 있습니다.
fun main() {
val person1 = Person(name = "tony", age = 12)
println("이름=${person1.component1()}, 나이=${person1.component2()}")
// 이름=tony, 나이=12
}코틀린에서는 구조분해할당을 사용해 좀 더 쉽고 안전하게 변수를 선언할 수 있습니다.
data class Person(val name: String, val age: Int)
fun main() {
val person1 = Person(name = "tony", age = 12)
val (name, age) = person1
println("이름=${name}, 나이=${age}")
// 이름=tony, 나이=12
}출처 : fastcampus
