- 가상 메모리 시스템의 동작 원리 :
- 매핑 테이블의 역할 :
- 페이징 기법의 구현 과정 :
- 동적 주소 변환 과정 :
- 세그먼테이션 기법의 구현 :
가상 메모리 개요
요리사가 주방 크기를 고려하여 레시피를 개발하면 제약사항이 너무 많다.
-> 프로그래머가 메모리 크기를 고려하여 개발하기는 어렵기 때문에 가상 메모리를 사용한다.
가상 메모리
- 프로세스가 물리 메모리보다 큰 공간을 사용할 수 있게 한다.
- 내가 돌리고자 하는 프로그램보다 메모리가 작아도 실행할 수 있게 한다.
프로세스가 바라보는 메모리 영역과 메모리 관리자가 바라보는 메모리 영역으로 나뉜다.
프로세스는 가상 주소 공간을 바라보고, 메모리 관리자는 물리 메모리와 스왑 영역을 바라본다.
-
가상 메모리의 크기 : 물리 메모리와 스왑 영역을 합한 크기이다.
-
가상 메모리의 주소
- 동적 주소 변환
DAT;Dynamic Address Translation: 가상 주소 -> 물리 주소로 변환한다.- DAT를 거치면 프로세스가 사용자의 데이터를 물리 메모리에 배치할 수 있다.
- DAT를 거치면 프로세스가 사용자의 데이터를 물리 메모리에 배치할 수 있다.
- 동적 주소 변환
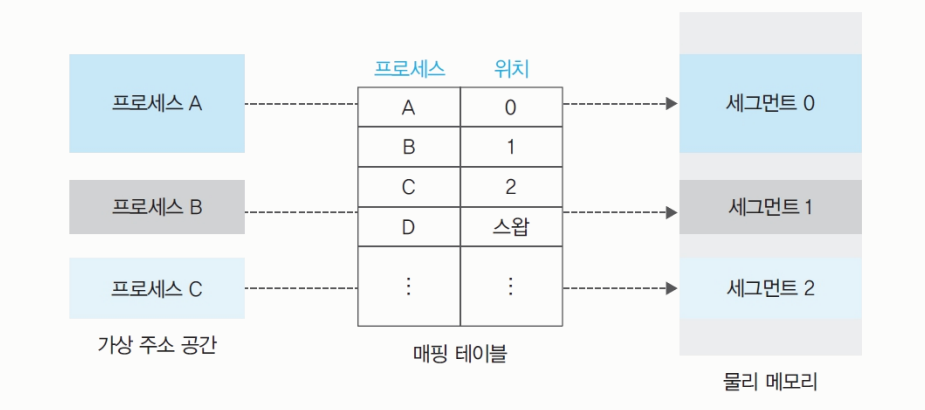
매핑 테이블
-
필요성 : 가상 주소와 물리 주소를 효과적으로 저장한다.
-
역할
- 메모리 관리자는 가상 주소와 물리 주소를 일대일 매핑 테이블로 관리한다.
- 페이지가 커질수록 매핑 테이블의 사이즈가 작아진다.
물리 주소로 데이터들을 찾는 역할을 한다.
만약 어떤 프로세스의 50번째 내용을 찾으려 할 때,
프로세스 위치가 1100이면, 1100+50을 하여 물리 주소로 찾는다.
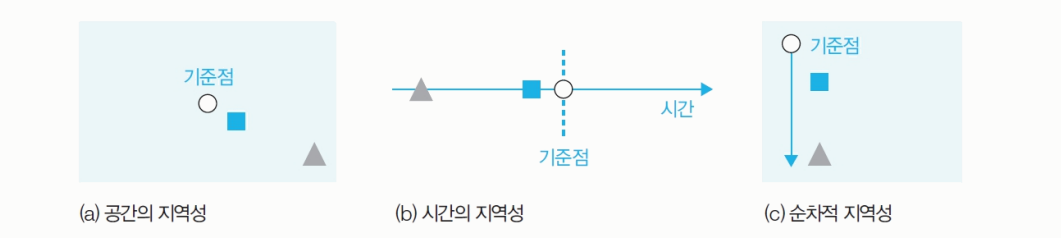
지역성
Locality : 어떤 기준으로 swap out할지 정하는 기준이다.
- 기억장치에 접근하는 패턴이 메모리의 특정 영역에 집중되는 성질이다.
-
공간의 지역성
spatial locality: 현위치에서 가까운 데이터에 접근할 확률이 높다.
- 네모에 접근할 가능성이 높다. -
시간의 지역성
temporal locality: 가까운 시간에 접근한 데이터에 접근할 확률이 높다.
- 네모가 사용될 가능성이 높다. 안 쓴지 오래된 것을 버린다. -
순차적 지역성
sequential locality: 작업이 순서대로 진행된다.
-
지역성의 예시
- 캐시 : 지역성 이론을 활용하여 캐시의 hit rate를 최대화한다.
- 페이지 교체 알고리즘
page replacement algorithm
페이징 기법
- 고정 분할 방식을 이용한 가상 메모리 관리 기법이다.
- 물리 주소 공간을 일정한 크기로 나눈다.
- 가상 주소는 항상 0번지부터 시작하고 프로세스 입장에서 바라본 메모리 공간이다.
페이지와 프레임
- 페이지
page: 가상 메모리에 분할된 영역이다. 번호로 관리된다.- 프레임
frame: 물리 메모리의 각 영역이다. 번호로 관리된다.
-
페이지와 프레임의 크기는 같다. -> 페이지는 어떤 프레임에도 배치될 수 있다.
-
페이지 테이블 : 어떤 페이지가 어떤 프레임에 있는지 연결 정보를 저장한다.
-
invalid: 페이지 테이블의invalid는 해당 페이지가 스왑 영역에 있다는 의미이다.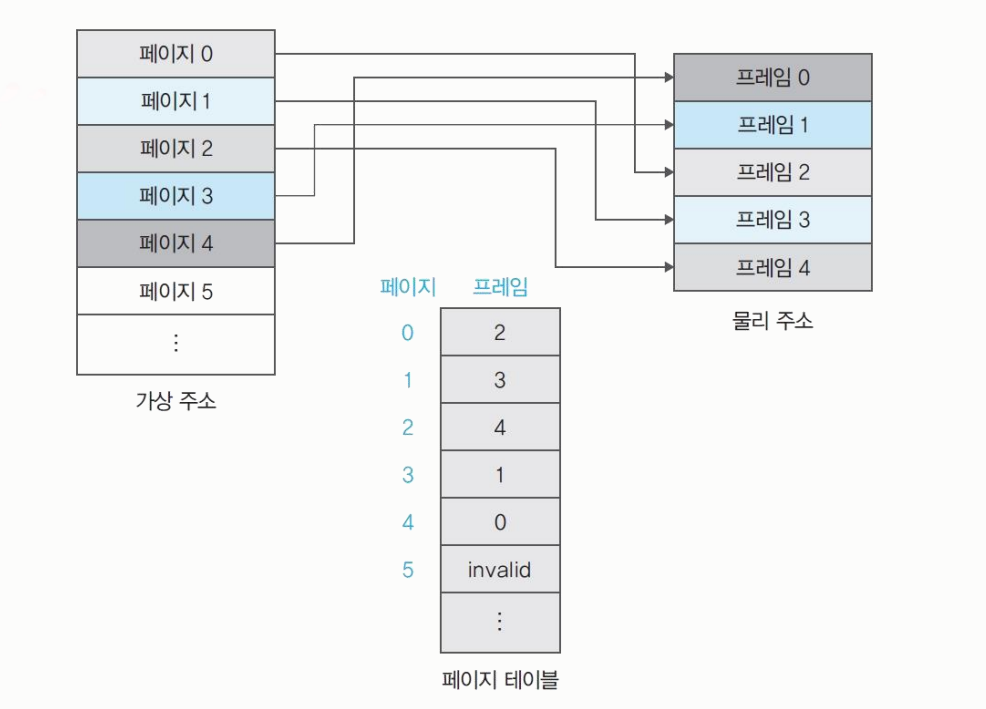
주소 변환 과정
페이징 기법의 주소 변환은 페이지 테이블과
메모리 관리 유닛 MMU;Memory Manage mentUnit이 사용된다.
- 가상 주소의 페이지 번호와
offset추출
- 가상 주소를 구성하는 비트를 페이지 번호와
offset으로 나눈다.- 페이지 번호는 페이지 테이블에서 해당 페이지의 위치를 찾는 데 사용된다.
offset은 페이지 내에서 실제 데이터 위치를 찾는 데 사용된다.
- 페이지 테이블 조회 : 페이지 번호를 사용하여 페이지 테이블에서 해당 페이지의 물리 정보를 찾는다. 이 정보는 프레임 번호
frame number로 표시된다.
- 물리 주소 생성 : 프레임 번호와 가상 주소의
offset을 조합하여 최종적인 물리 주소를 생성한다.
-
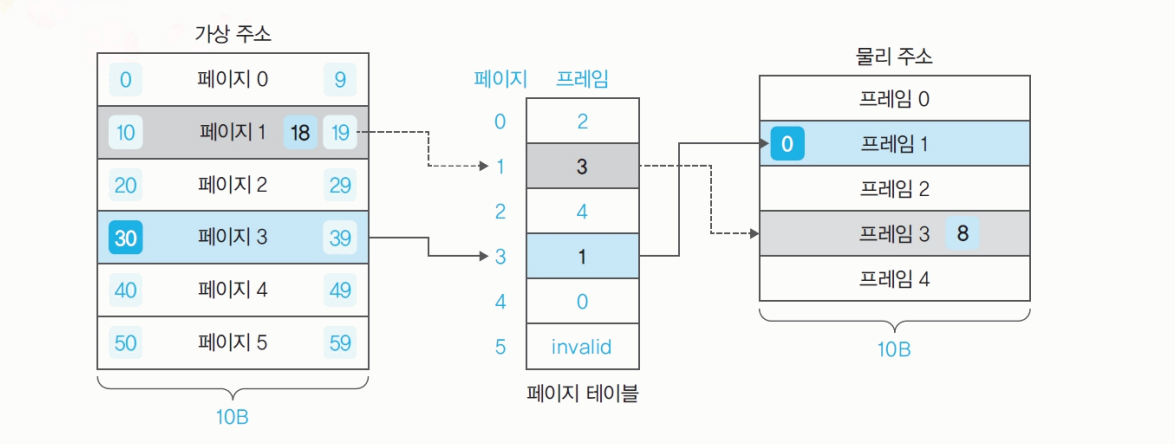
가상 18번지 -> 물리 주소 38번지
-
1페이지=1프레임=10 byte로 가정한다.
-
offset=distance : 8
18번지 가상 주소는 10과 8만큼 떨어져있다. -
물리 주소 : 38번지
1페이지와 1프레임이 10byte이므로
물리 주소의 3번 프레임의 시작주소는 30번지이다.
30+distance=38이다.
가상 주소와 물리 주소에서distance는 같다.
-
-
가상 주소 30번지 -> 물리 주소 10번지
-
가상 주소 55번지 -> 물리 주소에 할당되지 않았다. swap 영역에 있다.
물리 주소의 프레임 2를 내쫓을 경우, 물리 주소 20번지에 배치된다.
정형화된 주소 변환
- VA : 가상 주소
virtual address- P :
page- D : 페이지의 처음 위치에서 해당 주소가지의 거리
distance또는offset
- PA : 물리 주소
- F :
frame- D :
distance
- VA=<P,D> -> PA<F,D>
- 페이지 테이블을 사용하여 P를 F로 바꾸고 D는 그대로 쓴다.
- 페이지와 프레임 크기를 똑같이 나누었기 때문에 D가 같다.
- P와 F는 다르다.
- 가상 주소 18번지 -> 물리 주소
- VA<P,D> = 18<1, 8>
- PA<F,D> = 38<3, 8>
페이지의 크기가 다양할 경우 변환 공식
페이지 크기가 정해지지 않았을 경우에는가상주소/한 페이지의 크기의 몫을 페이지 번호로 정한다.
- P = (가상 주소 / 한 페이지) 의 몫
- D = (가상 주소 / 한 페이지) 의 나머지
- 한 페이지 크기 : 512B인 가상 메모리 시스템에서 VA 2049번지인 경우
- P = (2049/512) = 4
- D = (2049%512) = 1
16bit CPU 컴퓨터에서 한 페이지의 크기가 2^10일때 페이징 시스템
페이지 테이블 관리
-
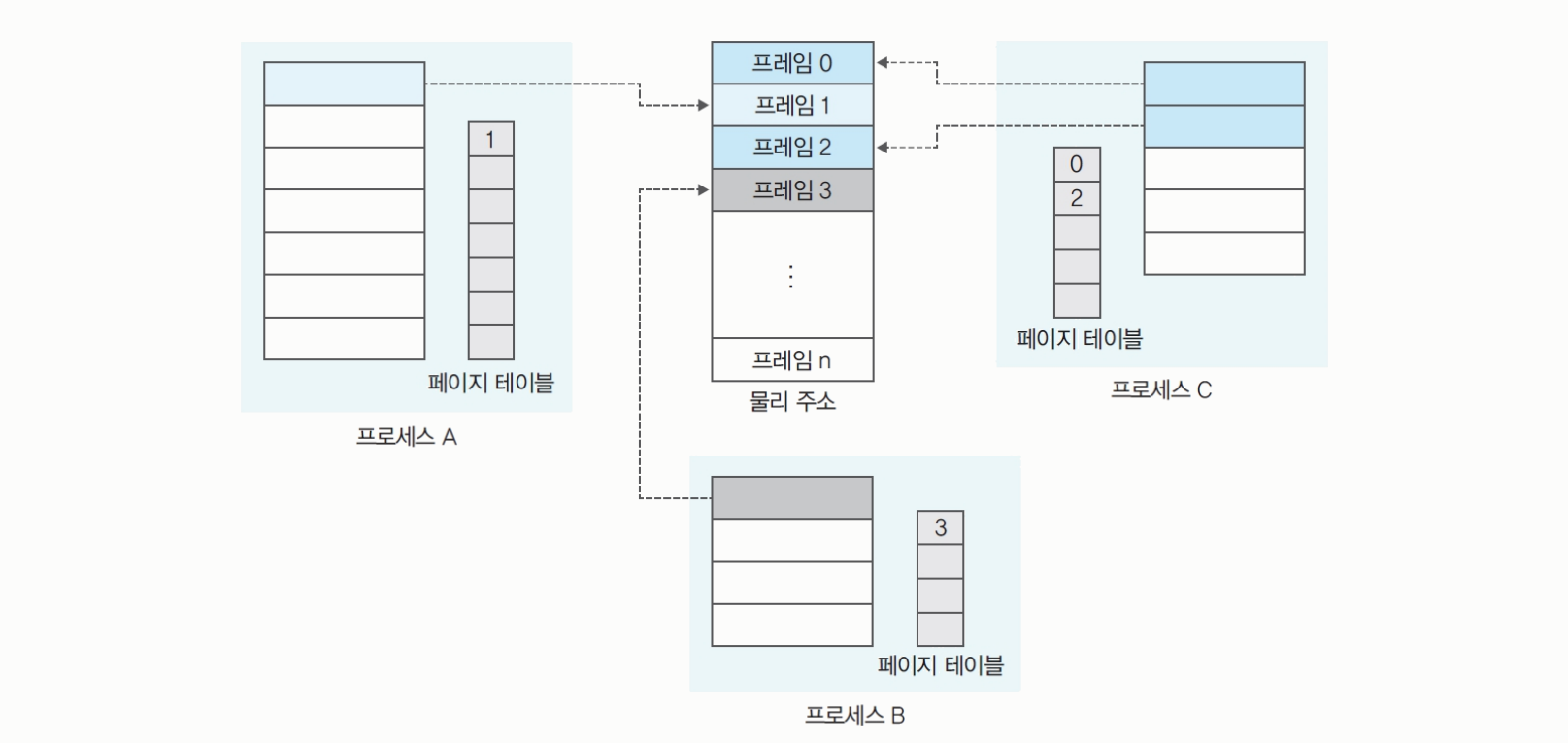
메모리 공유
- 프로세스마다 해당 페이지 내에 페이지 테이블이 존재한다.
- 프로세스 수가 많아지면 페이지 테이블 크기가 커지고, 프로세스가 사용할 공간이 줄어든다.
- 페이지 테이블의 크기를 적당하게 유지해야 한다.
-
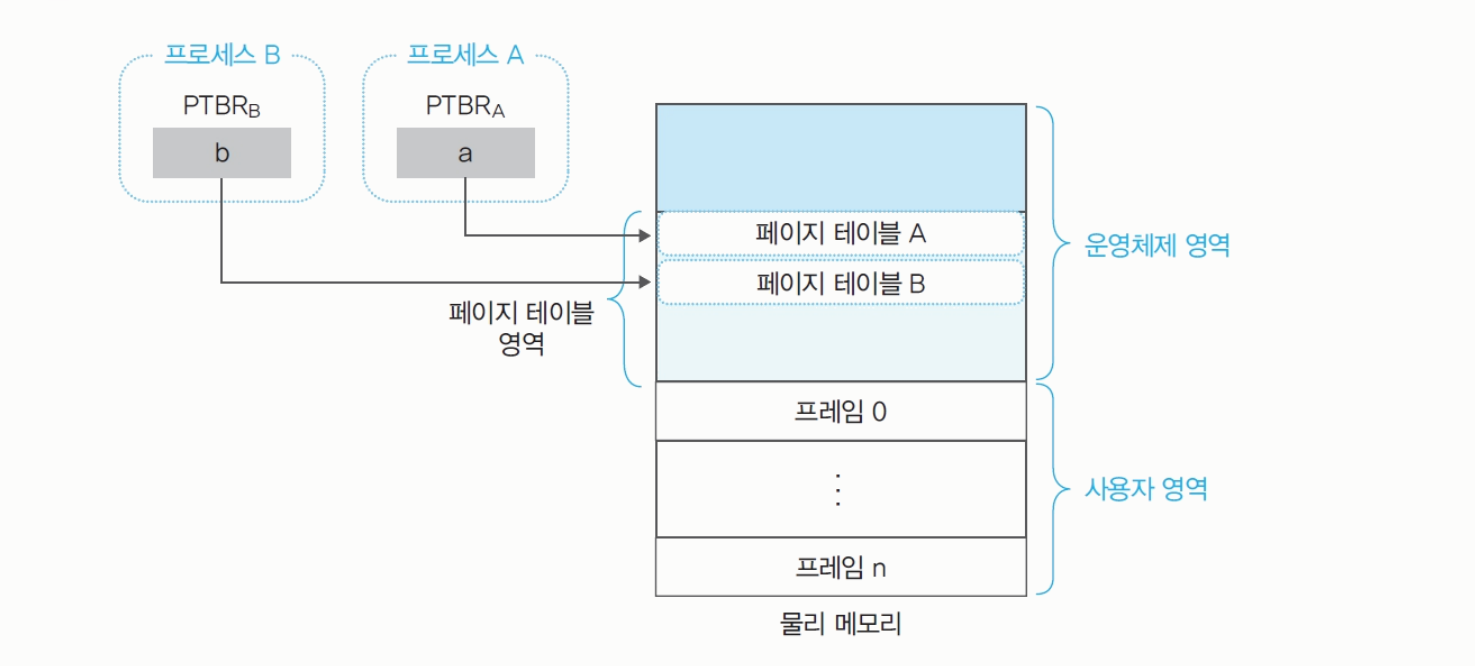
물리 메모리 내의 페이지 테이블의 구조
- 페이지 테이블 기준 레지스터
PTBR; Page Table Base Register: 페이지 테이블의 시작 주소를CPU내PTBR에 보관한다.- 물리 메모리의 크기가 작을 때는 페이지 테이블의 일부도 스왑 영역으로 옮겨진다.
- 운영체제 영역 내에 페이지 테이블이 있다.
- 페이지 테이블 기준 레지스터
-
쓰기 시점 복사
Copy-on-Write: 새 프로세스 생성 시 부모 프로세스와 같은 페이지를 가리키고 서로 다른 일을 하면 페이지를 분리한다.-
데이터 공유 :
fork()호출하여 새 프로세스가 생성될 때 부모 프로세스와 메모리를 공유한다. -
수정 시도 : 한 프로세스가 수정을 시도할 때 시스템은 수정을 허용하지 않고 쓰기 시점 복사 매커니즘을 트리거한다.
-
복사 수행 : 수정을 시도한 프로세스에 새로운 메모리 페이지를 할당하고 원본 데이터를 복사하고 새로 할당된 페이지에 저장하여 분리한다.
-
优: 자원 절약 缺: 복잡한 구현, 복사 시 오버헤드
-
-
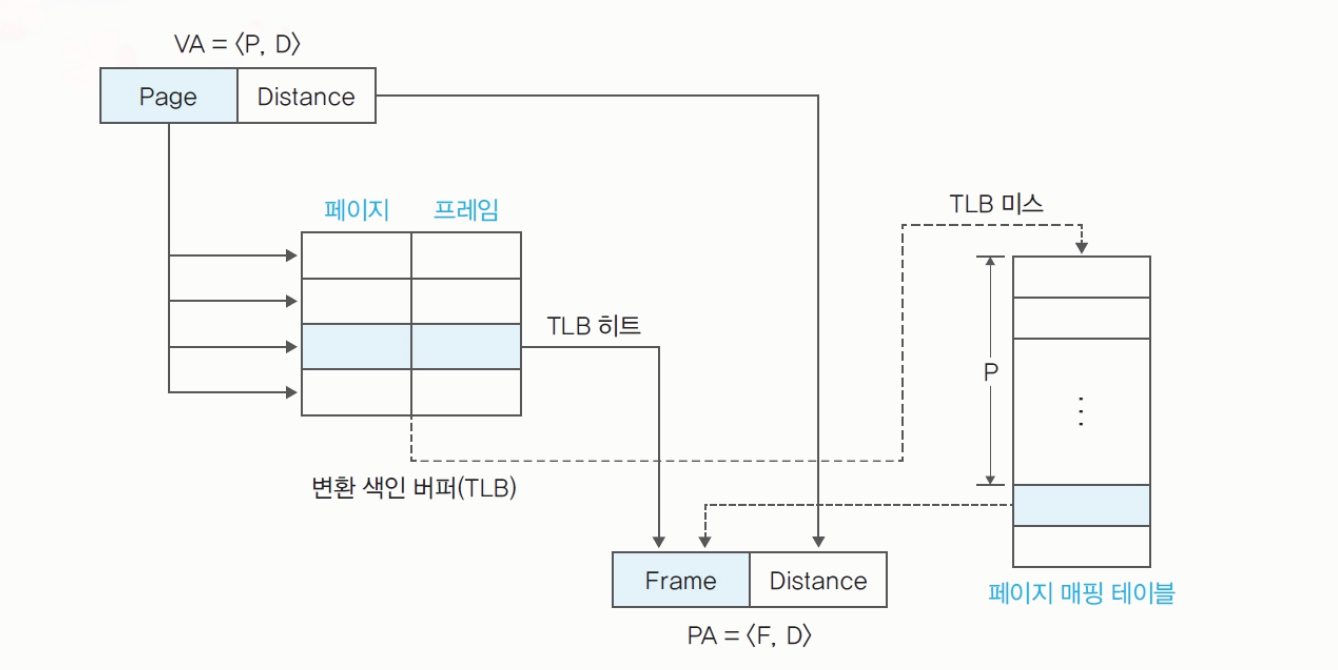
변환 색인 버퍼
TLB;Translation Lookaside Buffer:TLB를 이용하여 1번의 메모리 접근만으로 주소 변환이 가능하다.기존에는 가상 주소를 물리 주소로 변환하려면 메모리에 두 번 (페이지 테이블, 물리 주소)접근해야 한다. -> 메모리에 접근하면 느려지므로 메모리 접근을 줄여야 한다.
-
TLB hit: 원하는 페이지 번호가TLB에 있는 경우이다. 바로 물리 주소로 변환한다.
1 cycle에 주소 변환이 가능하다. -
TLB miss: 원하는 페이지 번호가TLB에 없는 경우이다.- 메모리의 페이지 테이블에 접근해 변환한다.
메모리에 2번 접근해야 하지만 hit가 많이 나는 경우 성능 감소는 없다.
-
优: 메모리 접근 감소 缺: miss>hit 경우 성능 저하 발생, 캐시 일관성 문제, 캐시 일관성 프로토콜 구현
-
정형화된 주소 변환 :
VA = <P, D> -> PA = <F, D>TLB hit-> 바로PA로 변환한다.
-
-
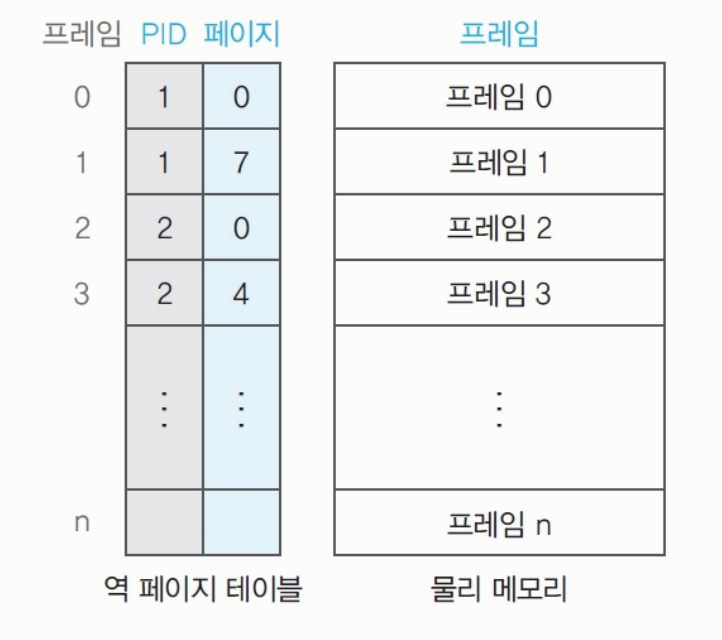
역 페이지 테이블 : 물리 메모리의 프레임 번호를 기준으로 테이블을 구성한다.
-
프레임 당 프로세스
pid와 몇 번 페이지가 올라와있는지 표시한다. -
테이블이 하나만 존재하므로 테이블 크기가 작다.
-
优: 프로세스와 페이지 테이블의 크기가 비례하지 않음 缺: 복잡한 구현, 최악의 경우 테이블 전체 탐색으로 성능 저하
-
-
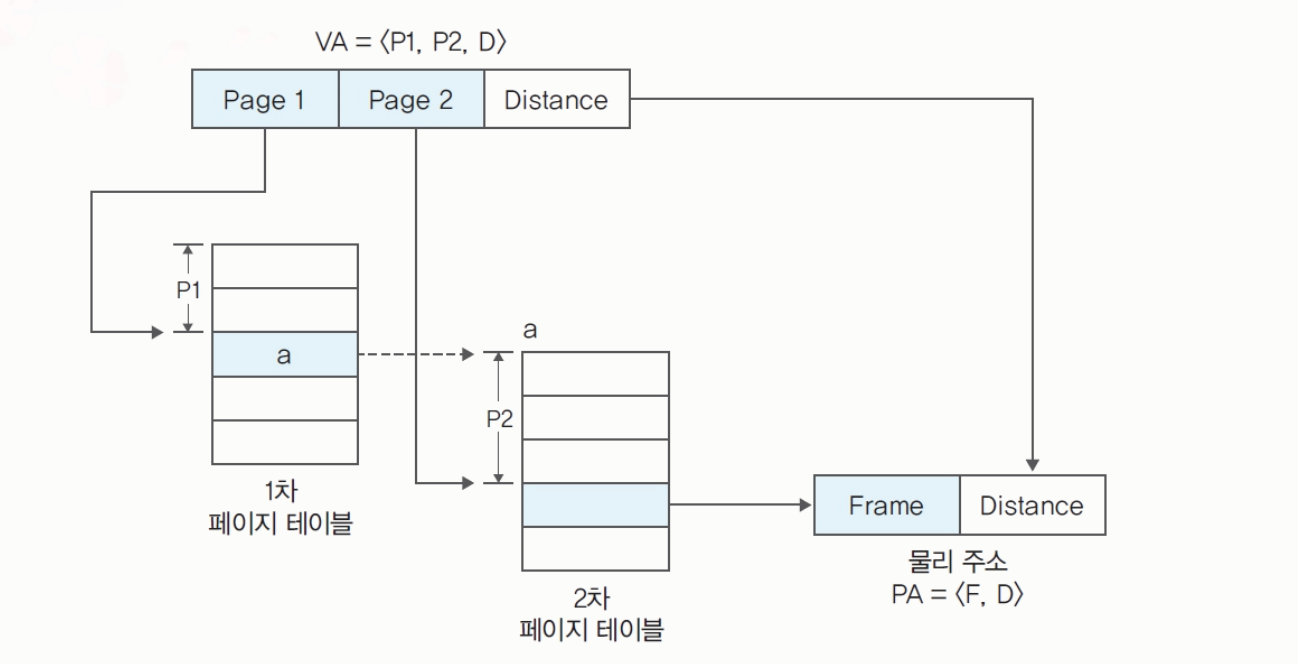
-
다단계 페이지 테이블 : 2단계 페이지; 페이지와 주소공간을 분리한다.
-
VA = <P1, P2, D>->PA = <F, D>- 1차 테이블: 주소를 저장한다.
- 2차 테이블: 페이지를 기준으로 프레임 번호를 저장한다.
-
메모리에 3번 접근하게 된다.
-
优: 메모리에 필요한 부분만 올려 절약, 검색 속도 향상 缺: 메모리 접근 증가, 복잡한 구현
-
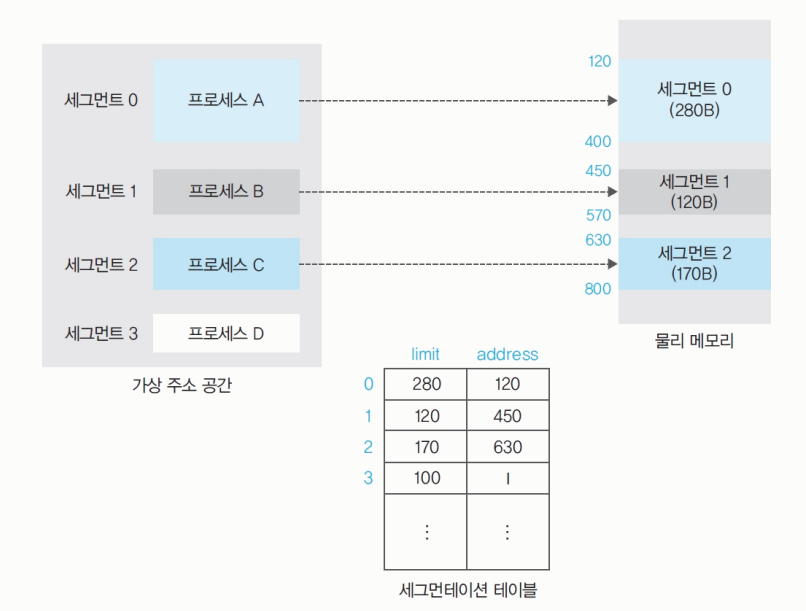
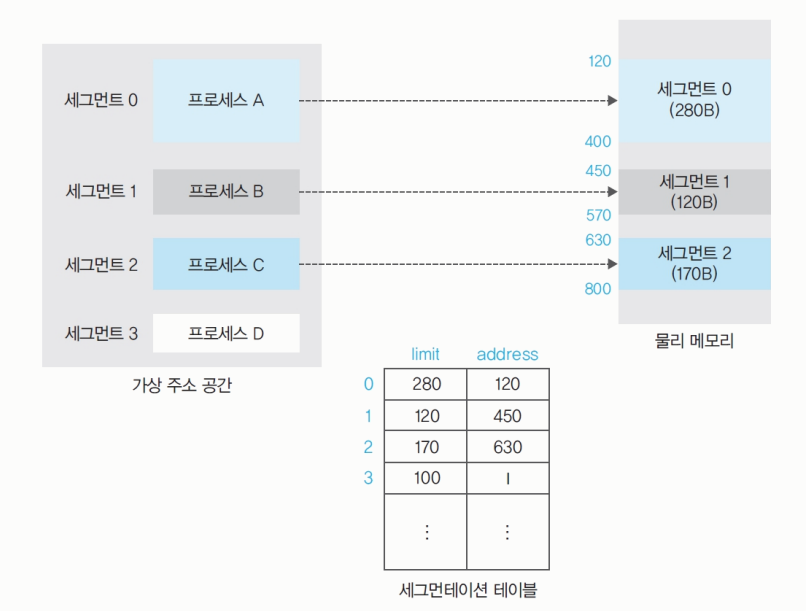
세그먼테이션 기법
-
segmentation table: 메모리를segment단위로 나눈다.-
세그먼트 당 1 프로세스가 할당된다.
-
세그먼테이션 테이블은
limit과addres로 나뉘어 있다.
주어진 세그먼트를 넘어가면 안 되므로 size가 아닌limit을 사용한다.
-
limit: 세그먼트의 크기이다.address: 세그먼트의 시작 주소이다.- 메모리가 부족할 때 스왑 영역으로 넘어간다.
i; invalid : 세그먼트가 스왑 영역에 있을 때 테이블의address에 표시된다.
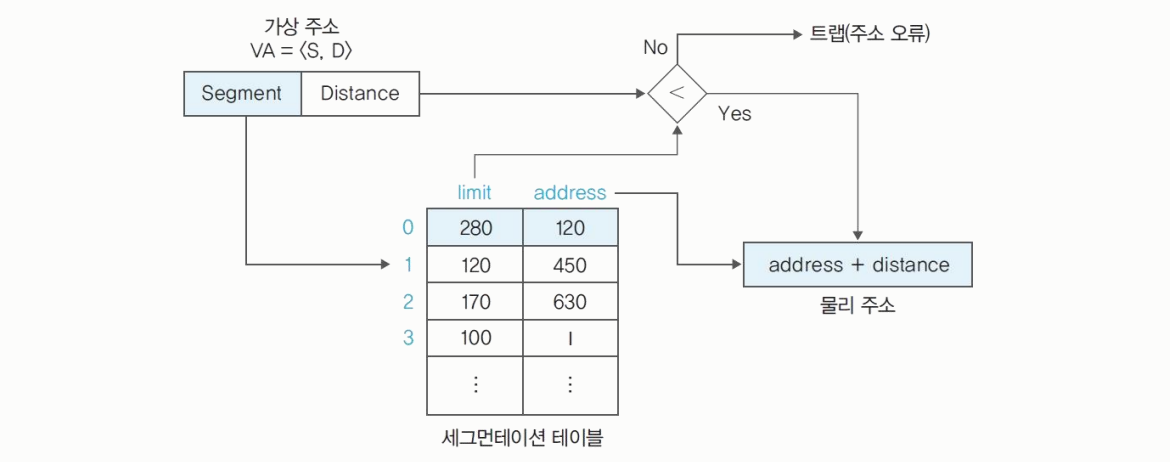
주소 변환 과정 : 프로세스 A의 32번에 접근하는 경우
- 가상 주소 : VA = <0, 32>
- 세그먼트 시작 주소 구하기 : 세그먼트 테이블에서 세그먼트 0의
address를 구한다. - 물리 주소 구하기 :
address + offset = 물리 주소
->120 + 32 = 152
캐시 매핑 기법
큰 영역 메모리 -> 작은 영역 캐시 으로 데이터를 옮길 때 주소값이 바뀌게 된다.
이 때 메모리와 캐시의 매핑이 필요하다.
CPU가 특정 주소를 필요로 할 때 캐시에 있다면 cache hit, 없다면 cache miss이다. cache miss이면 메모리에 접근하여 데이터를 가져온다.
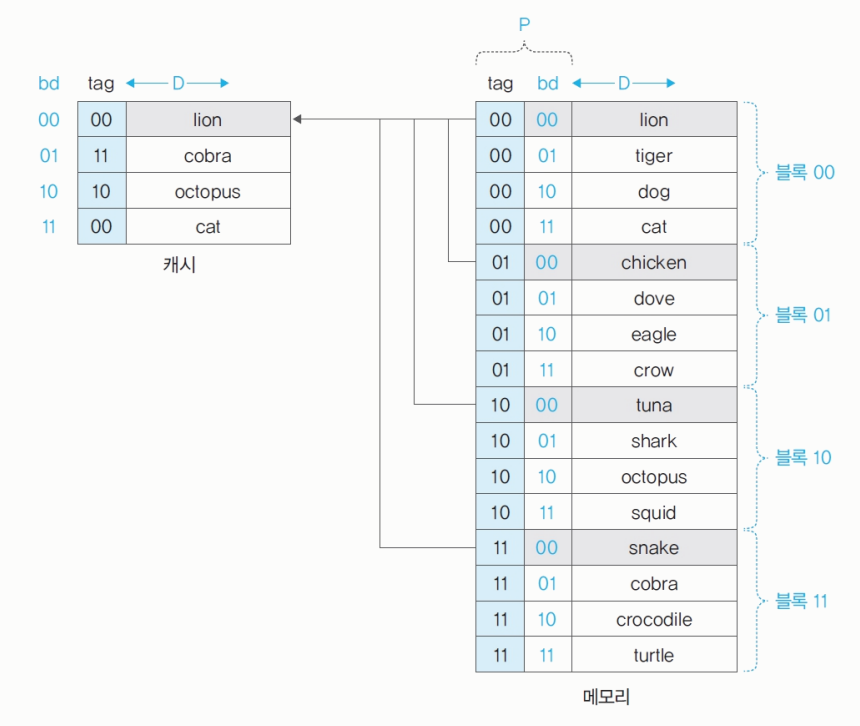
캐시 직접 매핑
메모리와 캐시를 똑같이 나누고 순서대로 매핑한다.
메모리의 특정 블록은 특정 캐시 라인에만 올라올 수 있다.
block: 메모리를 나누는 단위이다.line: 캐시를 나누는 단위이다.bd; block distance: 블록에서의 거리를 의미한다.tag: 캐시에 블록 번호를 명시한다. 메모리 주소 앞 2bit이다.
-
block과line의 크기는 동일하다. -
1.
tag확인 -> 2.bd확인 -
캐시와 페이지의
bd가 일치해야 한다.
-> 캐시는 어떤 블록 소속인지만 확인한다.
-> tag를 한번 더 확인하여lion인지chicken인지 확인한다. -
메모리 블록이 캐시로 올라올 때 항상 같은 위치에 올라온다.
-
메모리 주소 <tag, bd, D>, 캐시 주소 <tag, D>
-
优: 간단한 구현 缺: 충돌 자주 발생 -> 성능 저하 ; 서로 다른 블록이 동일한 라인에 매핑될 경우
- 예시
현재 캐시의 00line에 lion, chicken, tuna, snake 중 어떤 데이터가 올라왔는지 확인하기 위해 캐시에서 태그를 유지한다.
- CPU가 메모리의
1101 cobra가 필요한 경우, CPU는 캐시bd의01위치(마지막 2bit)를 확인하고tag가11인지 확인한다 ->tag가11이므로 cache hit이다.0111 crow가 필요한 경우, CPU는 캐시bd의 11위치(마지막 2bit)를 확인하고, 태그(앞 2bit)가01인지 확인한다. ->tag가00이므로 cache miss이다.
-
-
예시
캐시의 크기 : 16 word
메모리 크기 : 64 word
블록 1개의 크기 ==line의 크기 : 4 word -> 메모리의 총 블록 개수 : 64/4=16개64를 표현하려면 2^6=64이므로 6bit가 필요하다.
-> 첫 번째 워드 주소 :000 000
두 번째 워드 주소 :000 001...2진수의 특성에 의해 두 자리씩 보면
00 10 01 11 | 00 01 10 11-> 4 단위마다 반복된다.
따라서 마지막 2bit를bdblock offset이라고 하고 앞의 4bit를tagblock number라고 한다.
캐시 0 라인에는 블럭 0을 매핑, 캐시 1 라인에는 블럭 1을 매핑한다.
0 번line에는 워드 (0,1,2,3) 4개가 들어가고 1번line에는 (5,6,7,8) 4개가 들어간다. 1line== 1block이므로 1:1 매핑이 가능하다.
참고 : https://jhnyang.tistory.com/114
캐시 연관 매핑
- 메모리가 캐시의 아무데나 올라갈 수 있다. -> 캐시가 메모리의 주소를 전부 가지고 있다.
- 优: 자유로운 캐시 사용 -> 충돌 감소 缺: 검색 시간 지연
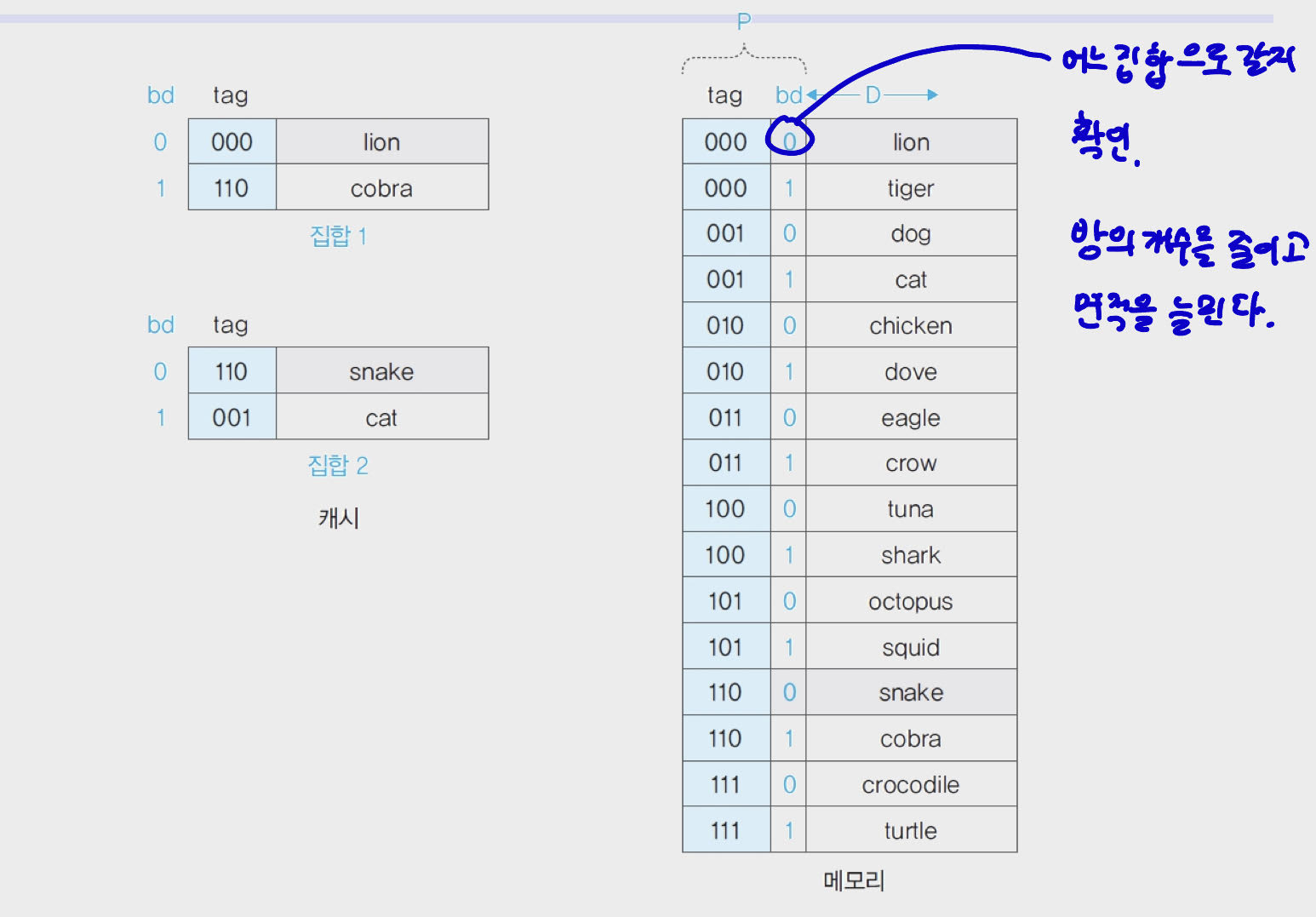
캐시 집합 - 연관 매핑
- 캐시를 K개의 집합으로 나누고 각 집합에 캐시 직접 매핑을 사용한다.
- 같은 끝자리를 가진 메모리가 K개가 된다 -> 충돌 완화
bd를 확인하고 어느 집합으로 갈 지 정해진다.- 직접 매핑을 사용하기 때문에 바로 캐시 히트 여부를 알 수 있다.
- 优: 충돌 완화; 같은
bd를 가진 메모리가 여러 개 되므로 缺: 복잡한 구현, 비싼 비용
-
예시
- 캐시를 2개의 집합으로 나눈다.
- 하나의 집합에 2개의 페이지를 사용한다.
bd: 주소 P의 4bit 중 마지막 1bit 이다.tag: 앞의 3bit 이다.
bd가0인 페이지 : 2개 집합 중 처음 찾은 빈 공간에 할당된다.bd가1인 페이지 : 2개 집합 중 마지막 빈 공간에 할당된다.
참고 : http://blog.skby.net/%EC%BA%90%EC%8B%9C-%EC%82%AC%EC%83%81mapping-%EA%B8%B0%EB%B2%95/
