- 메모리 관리의 복잡성과 이중성:
- 메모리 관리자의 역할:
- 논리 주소와 물리 주소의 의미 및 변환 과정:
- 메모리 오버레이:
- 스왑 기법:
- 메모리 관리 방식인 가변 분할 방식과 고정 분할 방식:
- 버디 시스템:
메모리 관리
메모리 주소
1Byte씩 나눠진 메모리의 각 영역의 구분자이다.- 보통 0번지부터 시작한다.
CPU가 메모리 내용을 가져오거나 연산 결과를 메모리에 저장하기 위해 사용한다.
메모리 관리의 복잡성
일괄 처리 시스템: 초기의 운영체제에서 사용된 일정 기간 동안 데이터를 모아서 처리하는 방식.
-
일괄 처리 시스템: 도마 1개에 재료 1개
-> 관리가 단순하다. -
시분할 시스템: 도마 1개에 여러 개 재료
-> 시분할 시스템에서는 여러 재료가 올라오기 때문에 메모리 관리가 중요하다.
메모리 관리의 이중성
-
프로세스: 메모리를 독차지 하려 한다.
-
메모리 관리자: 효율적인 관리를 원한다.
메모리 공간을 나누어 프로세스가 주어진 영역만 독차지하도록 한다.
컴파일러
- 특징 : 소스코드를 기계어로 번역한 후 한꺼번에 실행한다.
- c, java 등
java는 원래 인터프리터 언어로 알려져 있지만
소스코드->기계어->JVM->HardWare과정 중
소스코드->기계어부분은 컴파일러가 1차 번역을 하고,
JVM->HardWare과정에서 인터프리터로 2차 번역을 한다.
-
단점 : 컴파일 중간에 문제가 생기면 처음부터 다시 컴파일 해야 한다.
-
장점 : 실행 속도가 빠르다.
- 소스코드 최적화 가능 : 컴파일 과정에서 필요 없는 부분들(쓰이지 않는 부분들)을 버릴 수 있다.
-
컴파일러 방식의 목적
- 오류 발견 : 소스코드 전체에서 오류를 발견할 수 있다.
인터프리터는 한 줄씩 실행하기 때문에 오류 발견이 어렵다. - 소스코드 최적화 : 소스코드를 간결하게 정리하여 실행속도를 빠르게 한다.
- 오류 발견 : 소스코드 전체에서 오류를 발견할 수 있다.
-
컴파일러의 컴파일 과정
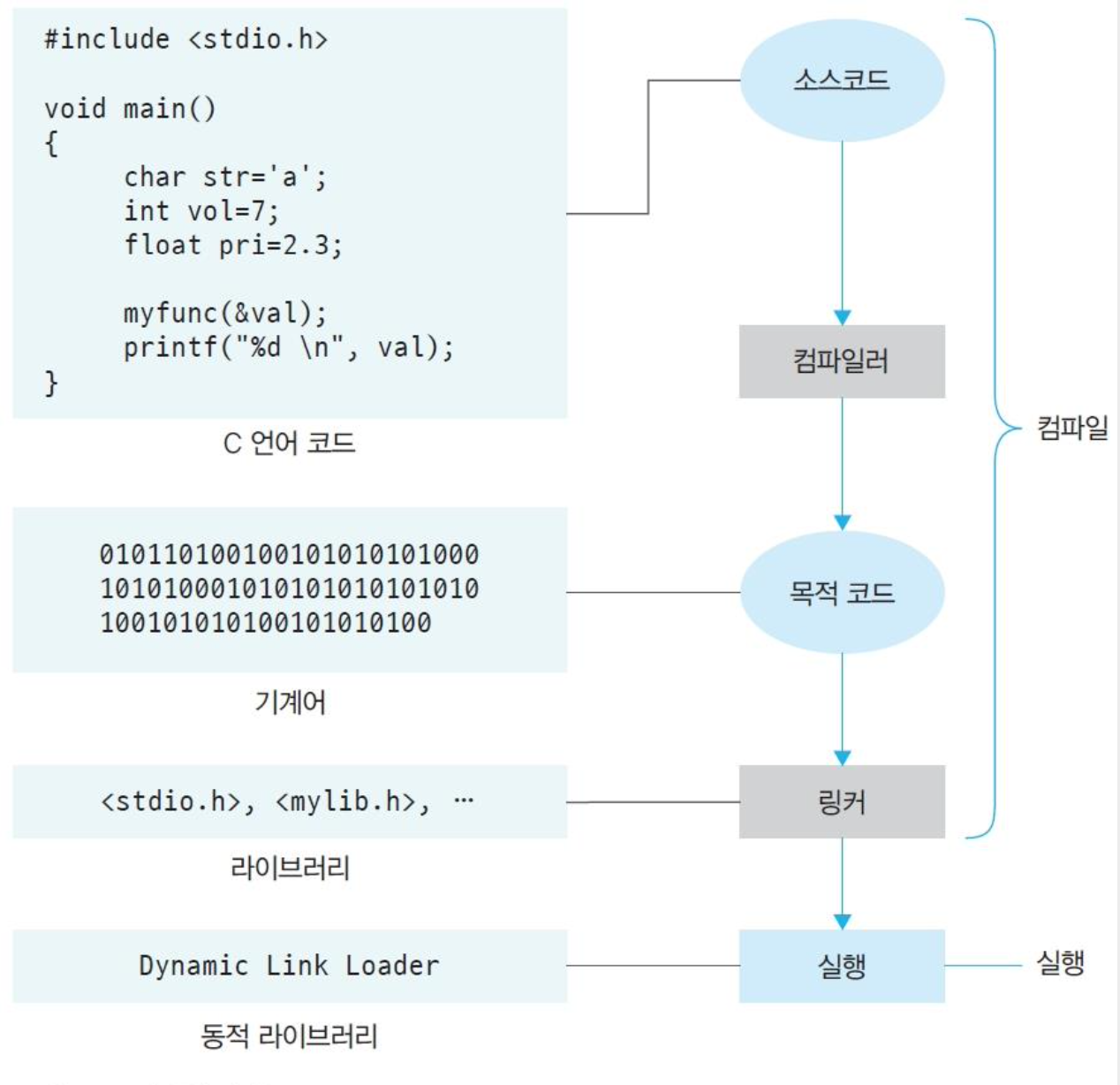
-
c언어 코드 : main()의 1,2,3행은 쓰이지 않기 때문에 컴파일 최적화로 인해 컴파일되지 않는다.
-
기계어 : 변수가 주소값으로 바뀌고, 논리 영역에서 0번지부터 차례로 주소를 할당한다.
-
라이브러리 : 링커를 통해 static 라이브러리를 불러온다.
-
동적 라이브러리 : 여러 프로세스들이 동시에 메모리에 저장될 수 있다.
인터프리터
- 특징 : 소스코드를 한 줄씩 번역하여 실행한다. 동시통역과 같다.
- 파이썬, 자바스크립트 등
- 장점
- 부분실행이 가능하다.
- 융통성 : 소스코드를 실행 중간에 변경할 수 있다.
- 단점
- 컴파일 중에 소스코드 최적화가 불가능하다.
- 실행 속도가 느리다.
메모리 관리 작업
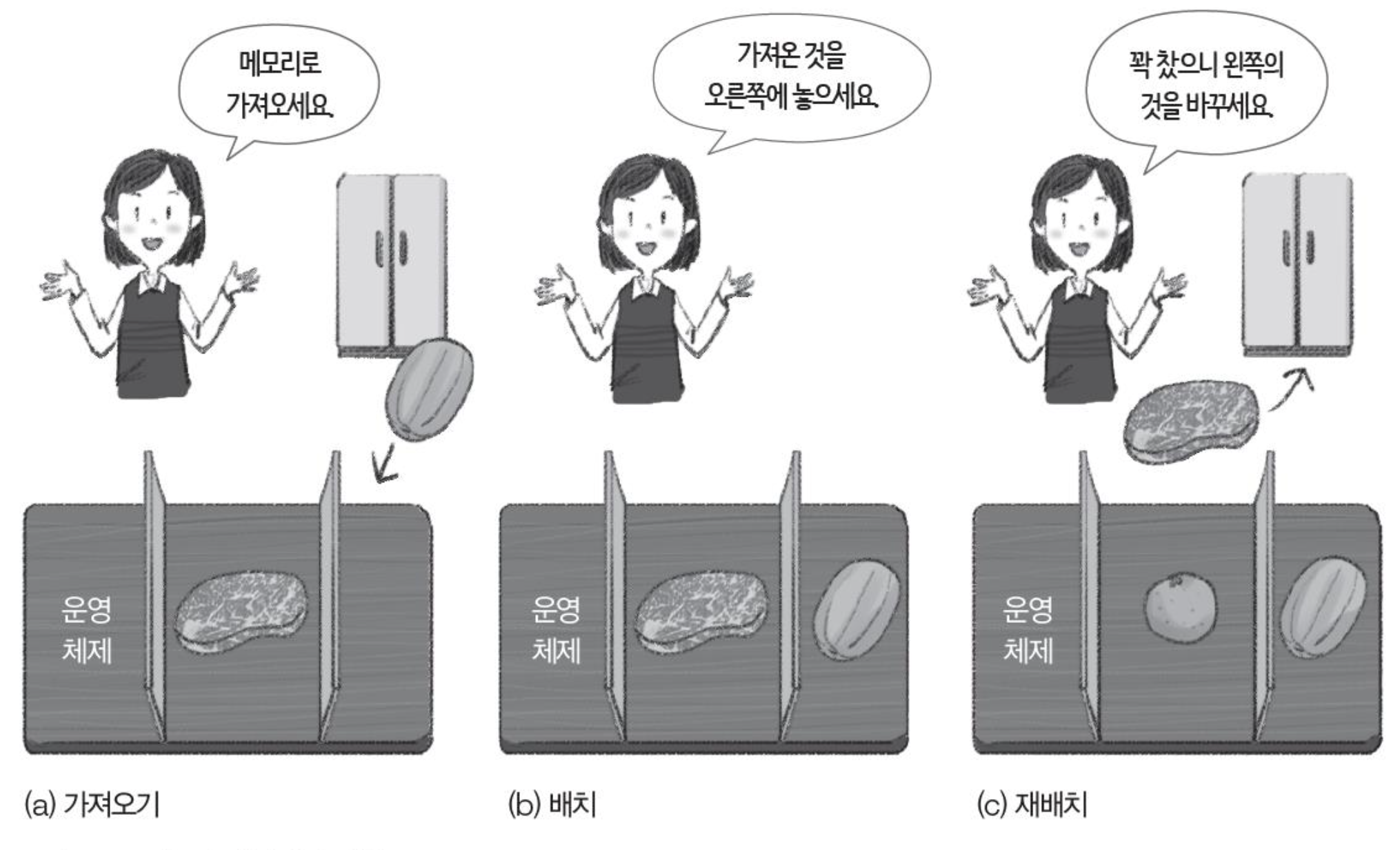
-
메모리 가져오기
fetch: 프로세스를 언제 메모리에 올릴지 관리한다.- 프로세스를 메모리로 가져온다.
-
메모리 배치
placement: 프로세스를 어떤 위치에 놓을 지 관리한다.- 메모리에 공간을 만들고 배치한다.
-
메모리 재배치
replacement: 메모리가 꽉 찼을 경우, 누구를 쫓을지 결정한다.- 내쫓으면 하드디스크에 저장된다.
- 다음에 실행될 가능성이 낮은 것을 내쫓는다.
메모리 주소
32bit CPU와 64bit CPU의 차이
- 비트: 한 번에 다룰 수 있는 데이터의 최대 크기
-
32bit CPUCPU내의 레지스터 크기는 모두32bit이고,ALU(산술논리 연산장치), 버스의 대역폭, 하나의 데이터가32bit이다.- 한 번에 가져와서 계산할 수 있는 양이 최대
32bit이다. - 표현할 수 있는 메모리 주소의 범위가
0~2^32-1로 총2^23개이다. - 16진수로 나타내면 00000000~FFFFFFFF, 총 크기는
2^32B이다.
-
64bit CPU0~2^64-1번지의 주소 공간을 제공한다.- 총 크기가
2^64B로 거의 무한대에 가까운 메모리이다.
메모리 영역의 구분
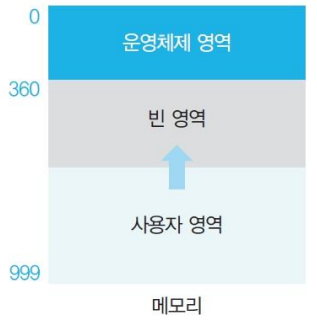
- 단순 메모리 구조
-
일괄 처리 시스템에서 볼 수 있다.
-
운영체제 영역과 사용자 영역으로 나눈다.
-
사용자 프로세스 적재 방법 : 운영체제 영역과 겹치지 않게 적재한다.
운영체제 공간이 부족할 경우 사용자 영역을 침범하면 위험하다.
- OS 크기에 따라 주소가 달라지면 번거롭기 때문에 사용자 프로세스를 메모리 최상위(맨 아래)부터 사용한다.
- 주소를 변경하는 것이 복잡하므로 잘 쓰이지 않는다.
-
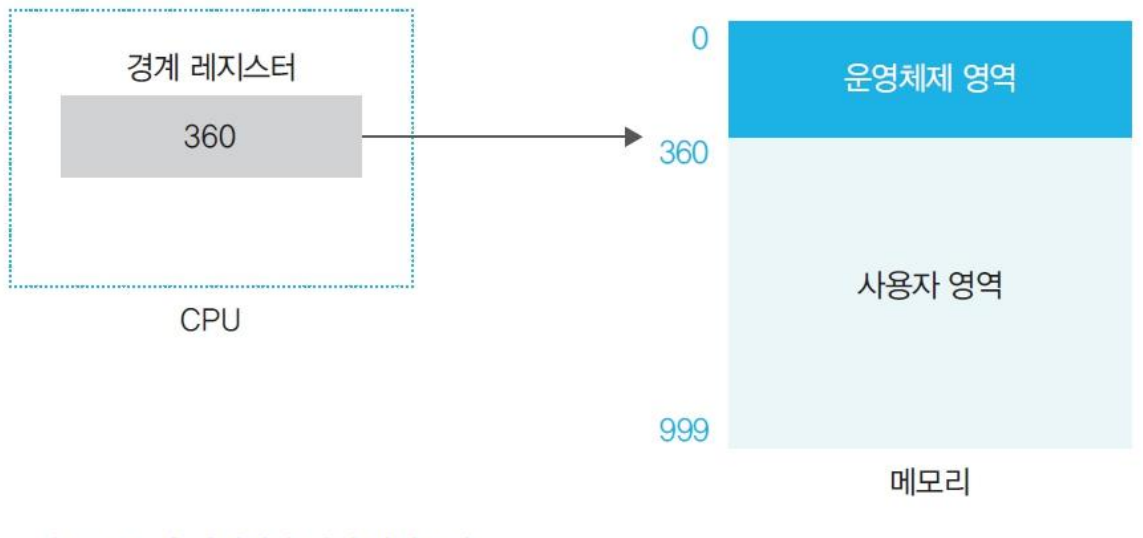
- 경계 레지스터 :
운영체제 영역과사용자 영역경계 지점의 주소를 가진다.CPU내에 있다.사용자 영역이운영체제 영역을 침범하는 것을 막는다.- 사용자가 작업 요청을 할 때마다 경계를 침범하는지 검사한다.
- 침범하는 작업을 요청하면 해당 프로세스를 종료시킨다.
물리 주소와 논리 주소
-
물리 주소
physical address: 메모리 입장의 주소이다.- 메모리 주소 레지스터가 사용하는 실제 주소이다.
-
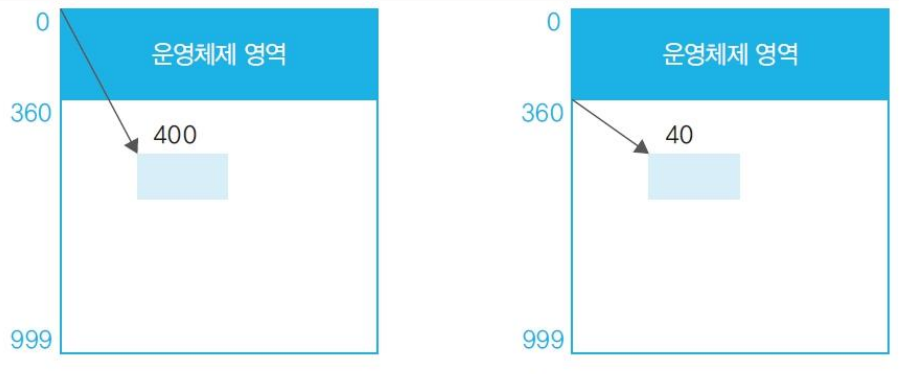
논리 주소
logical address: 프로세스 입장의 주소이다.- 항상 0번지부터 시작하기 때문에 편리하다.
offset: 논리 메모리에서 사용하는 상대적인 주소base: 논리 메모리 0번지의 실제 물리 주소이다.- 만약 변수 val의
offset이 3번지이고,base가 300번지로 할당된다고 가정하면, val의 실질적인 물리 주소는 303번지이다.
-
논리 주소를 물리 주소로 변환하는 과정
-
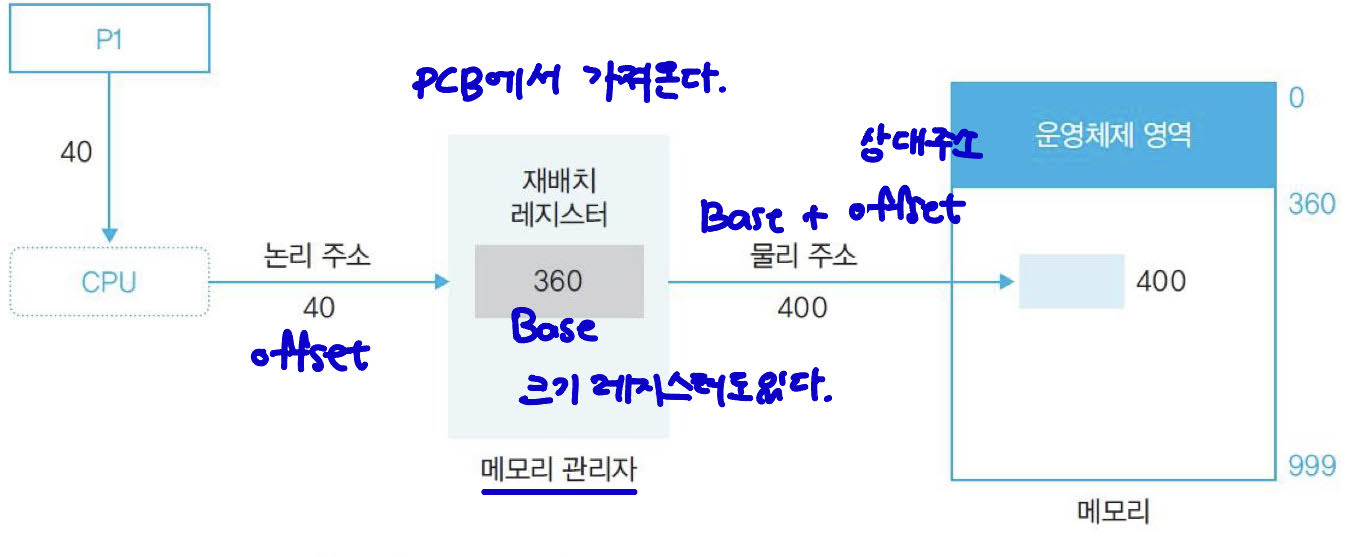
사용자 프로세스
P1이 논리 주소 40번지의 데이터를 요청한다. -
CPU가 40번지 데이터를 가져오라고메모리 관리자에게 요청한다. -
메모리 관리자가 재배치 레지스터를 사용해 400번지(base+offset)에 저장된 데이터를 가져온다.
-
재배치 레지스터 : 현재
CPU에서 수행 중인 프로세스의 물리 메모리 시작 주소를 갖고 있다.
단일 프로그래밍 환경의 메모리 할당
메모리 오버레이
-
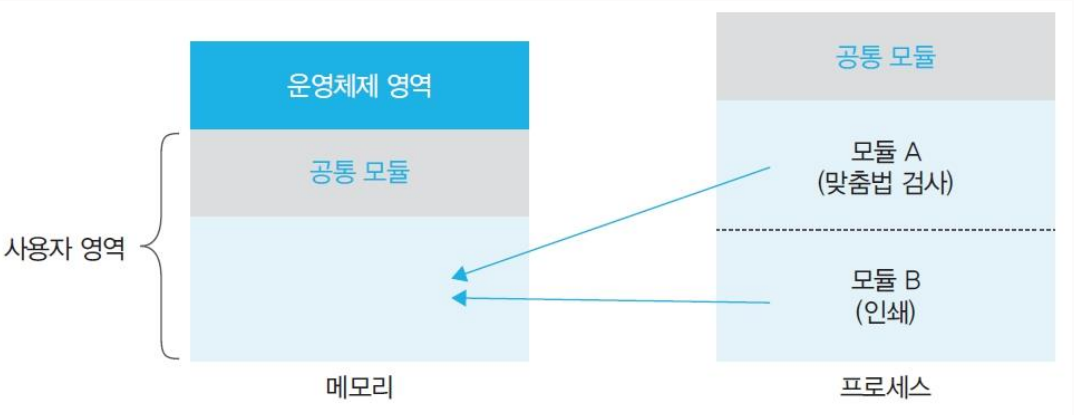
메모리 오버레이 : 프로그램의 크기가 물리 메모리보다 클 때 잘라서 가져오는 기법
-
작동 방식 : 필요한
모듈만 메모리에 올려 실행한다.
-
의미
- 메모리보다 큰 프로그램 실행 가능하다.
- 프로그램 일부만 실행이 가능하다.
스왑
-
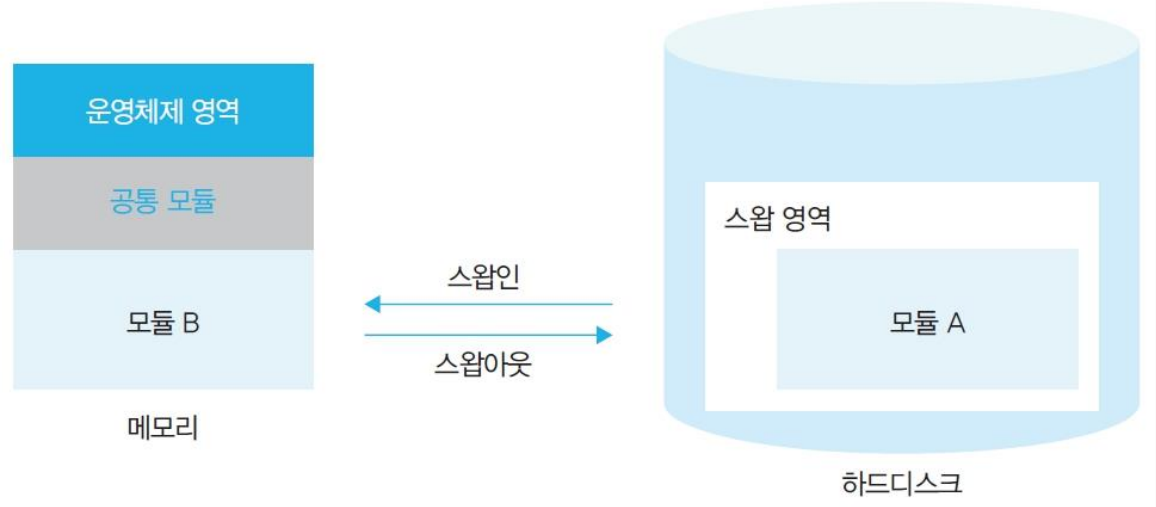
스왑 영역
swap area: 메모리에서 쫓겨난 프로세스를저장장치의 특정 공간에 모아두는 영역- 메모리 관리자가 관리한다.
저장장치는 장소만 빌려준다. - 사용자가 인식하는
전체 메모리 크기=메모리 크기+스왑 영역 크기
- 메모리 관리자가 관리한다.
-
스왑인
swap in:스왑 영역->메모리 -
스왑아웃
swap out:메모리->스왑 영역
다중 프로그래밍 환경의 메모리 할당
메모리 분할 방식
메모리에 여러 개 프로세스를 배치하는 방법 2가지
-
가변 분할 방식
variable-size partitioning: 프로세스 크기에 따라 메모리를 나눈다.- 프로세스마다 크기가 다르므로 각 영역이 모두 다르다.
- 장점 : 연속 메모리 할당 방식이다.
- 단점 : 다른 프로세스들의 자리를 옮기면서 빈 공간을 합쳐야 하기 때문에 구현이 복잡하다.
-
고정 분할 방식
fixed-size partitioning: 고정된 크기로 메모리를 나누고 프로세스를 조각내서 배치한다.- 장점 : 조각 모음 하지 않아도 되므로 관리가 편하다.
- 단점
- 비연속 메모리 할당이다.
-> 프로세스 실행 시 복잡하다. - 작은 조각으로 인해 메모리 낭비가 발생한다.
- 비연속 메모리 할당이다.
가변 분할 방식의 메모리 관리
-
세그먼테이션
segmentation기법 : 프로세스 크기에 맞춰 메모리를 할당한다. -
단편화
fragmentation발생- 프로세스가 종료되면 생기는 빈 공간이 일치하지 않는다.
- 빈 공간(조각) 이 프로세스 바깥에 위치하여 외부 단편화
external fragmentation이라고 한다.
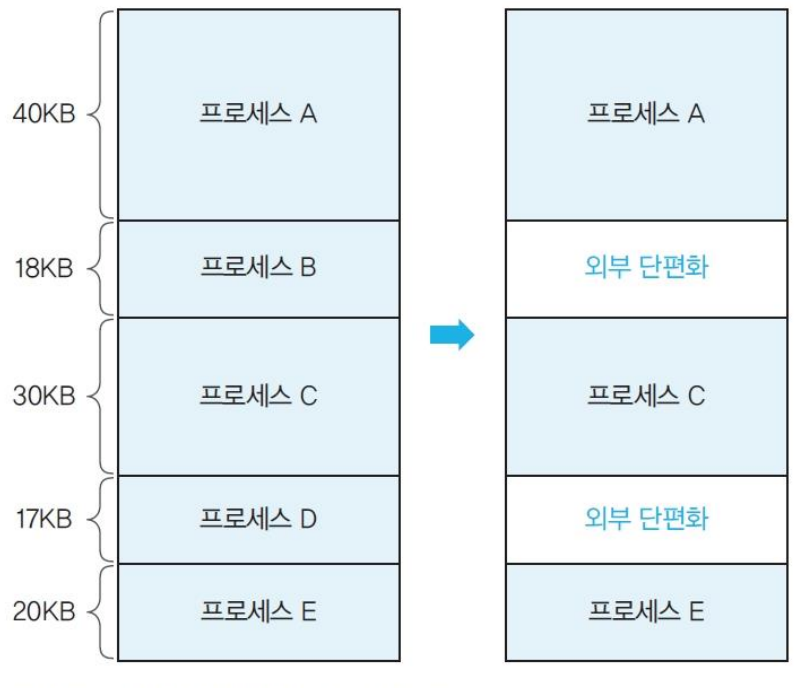
-
외부 단편화의 해결
(메모리 배치 방식, 조각 모음)-
메모리 배치 방식 : 작은 조각이 생기지 않도록 프로세스를 배치한다.
-
선처리에 해당한다.
-
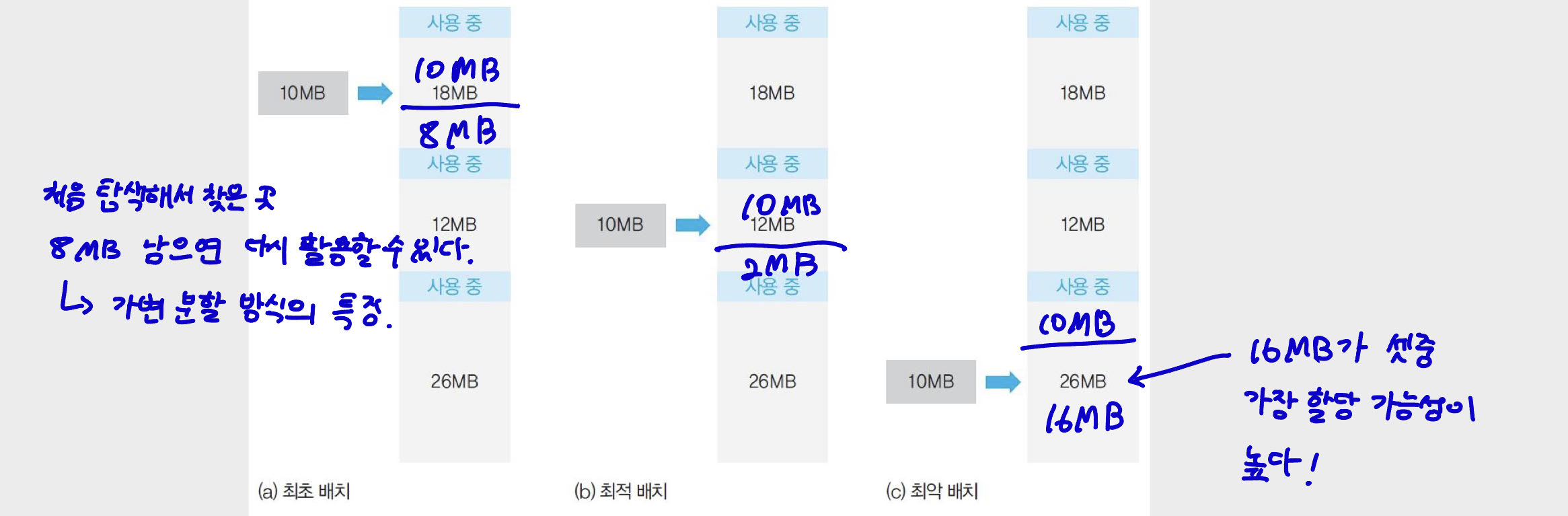
최초 배치
first fit: 제일 처음 찾은 맞는 공간에 배치한다.- 메모리를 list로 탐색한다.
- 장점 : list를 적게 탐색하므로 오버헤드가 적다.
- 단점 : 단편화가 많이 발생한다.
-
최적 배치
best fit: 맞는 빈 공간 중에서 가장 작은 공간에 배치한다.- 장점 : 단편화가 적게 발생한다.
- 단점 : list를 많이 탐색하므로 오버헤드가 크다.
-
최악 배치
worst fit: 가장 큰 공간에 배치한다.- 장점 : 남는 공간에 재배치가 가능하다.
- 단점 : 단편화가 많이 발생할 수 있다.
-
-
외부 단편화의 해결
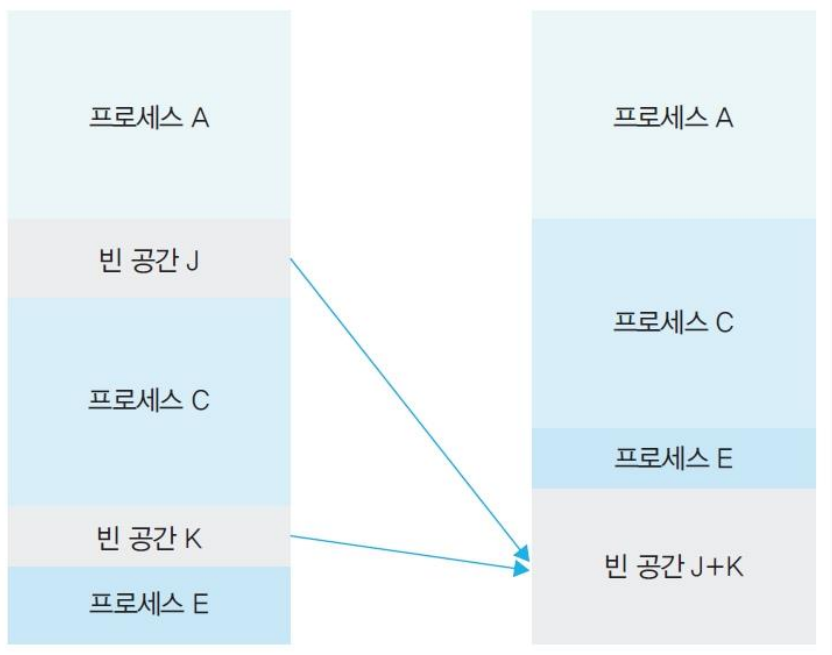
- 조각 모음
defragmentation: 배치된 프로세스를 옆으로 옮겨 작은 조각을 모아 큰 공간으로 만든다.- 후처리에 해당한다.
동작 방식
- 이동할 프로세스의 동작을 멈춘다.
- 프로세스를 적당한 위치로 이동한다.
- 작업을 마친 후 프로세스를 다시 시작한다.
- 조각 모음
defragmentation을 최소화하는 것이 좋다.
마우스 포인터가 돌아갈 때 메모리 단편화가 일어난다.
고정 분할 방식의 메모리 관리
-
페이징
paging기법 : 물리 메모리를 나눈다.-
단점 : 내부 단편화
- 페이지 크기보다 작은 프로세스가 배치될 경우 작은 조각이 생긴다
-> 페이지 크기를 줄인다 -> 관리 오버헤드
- 페이지 크기보다 작은 프로세스가 배치될 경우 작은 조각이 생긴다
-
장점 : 조각 모음을 할 필요가 없어 메모리 관리가 수월하다.
-
가변 분할 방식과 고정 분할 방식의 비교
구분 가변 분할 방식 (segmentation)고정 분할 방식 (paging)메모리 관리 기법 segmentationpaging특징 연속 메모리 할당 비연속 메모리 할당 장점 프로세스를 한 덩어리로 관리 가능 메모리 관리가 편리함 단점 빈 공간의 관리(조각 모음)가 어려움 프로세스가 분할되어 처리됨 단편화 외부 단편화 내부 단편화
버디 시스템
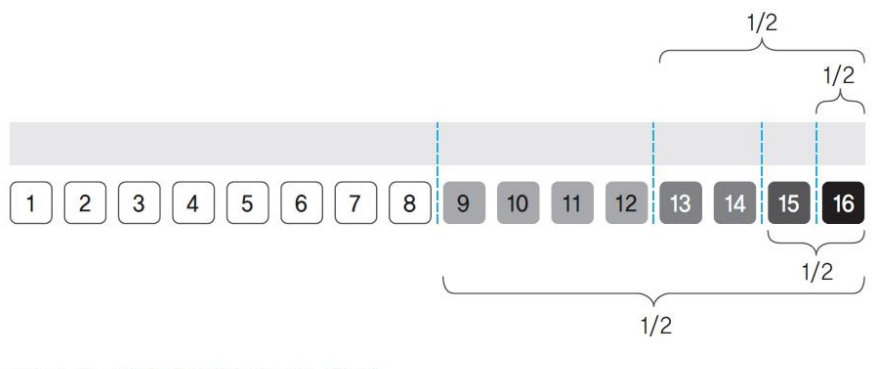
- 작동 방식
- 프로세스 크기에 맞게 메모리를 1/2로 나누고 프로세스를 메모리에 배치한다.
- 나뉜 메모리의 각 구역에는 프로세스가 1개만 들어간다.
- 프로세스가 종료되면 주변의 빈 조각과 합친다.
-
장점
-
메모리가 프로세스 크기대로 나뉘므로 연속 메모리 할당이다.
-
작은 조각을 모아 큰 조각을 만들 수 있다.
-
-
단점
- 내부 단편화가 발생한다.
고정 분할 방식처럼 하나의 구역에 다른 프로세스가 들어갈 수 없고, 조각이 생긴다.
다시 말해, 프로세스보다 메모리가 약간 크면 조각이 생긴다. - 조각을 합치는 오버헤드가 있다.
- 내부 단편화가 발생한다.
-
버디 시스템의 자리 배정 예
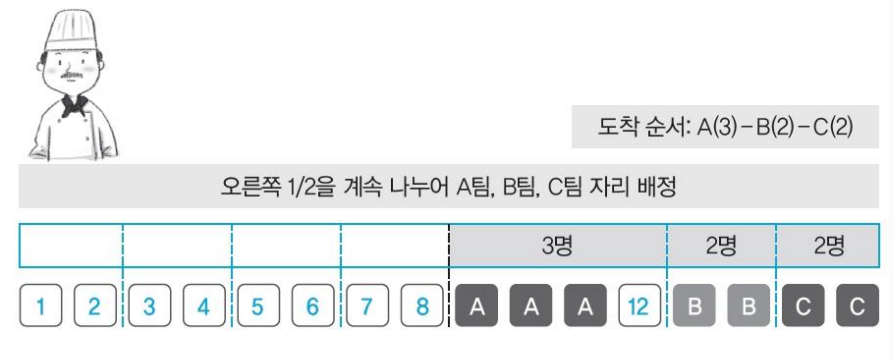
-
A 3명이 들어옴 -> 1/2 하여 8-8 -> 1/2 하여 4-4
-
2 < (A) 3명 < 4 이므로 크기 4인 공간에 배정된다.
-
이때, 12번은 내부 단편화가 발생한다.
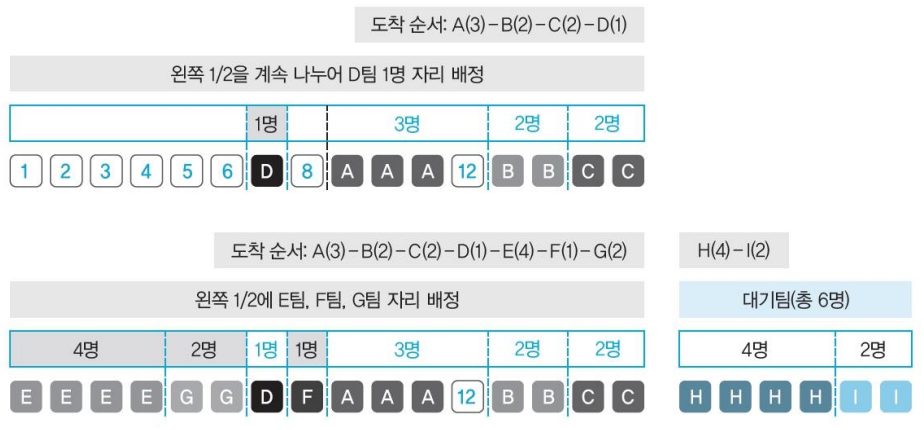
-
오른쪽에는 더이상 1자리가 만들어질 수 없으므로 왼쪽에 배치한다.
-
8 -> 1/2하여 4-4 -> 1/2하여 2-2 -> 1/2하여 만들어진 1-1에 D를 배정한다.
-
E 4명 배정 -> F 1명 배정 -> G 2명 배정했다.
-
H 4명 -> I 2명은 대기한다.
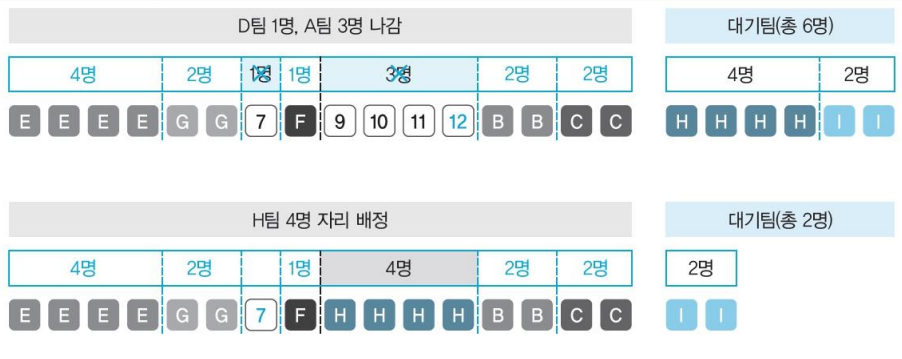
-
D 1명 종료 -> A 3명 종료
-
H 4명 배정되었지만 I는 공간이 없으므로 대기한다.
-
분할 컴파일과 메모리 관리
분할 컴파일
-
다중 소스코드
multiple source code: 여러 개 소스코드 파일로 하나의 실행 파일을 만든다. -
분할 컴파일 : 여러 개 소스코드를 각각 컴파일하여 하나의 실행파일로 만든다.
- 여러 명이 각자 컴파일한 목적 코드(기계어 코드)를 모아 같이 컴파일한다.
- 목적 코드는 오류 검사가 끝난 파일이므로 오류 없는 실행 파일이 된다.
변수와 메모리 할당
- 변수와 메모리
char str='a'; //변수 str을 문자열로 선언하고 a를 넣는다.
int vol=7; //변수 vol을 정수로 선언하고 7을 넣는다.
float pri=2.3; //변수 pri를 실수로 선언하고 2.3을 넣는다.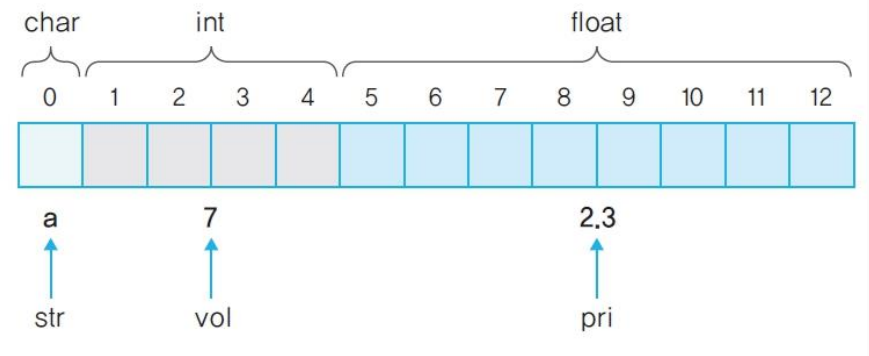
-
심벌 테이블 : 컴파일러가 모든 변수의 메모리를 확보하고 오류를 찾기 위해 유지한다.
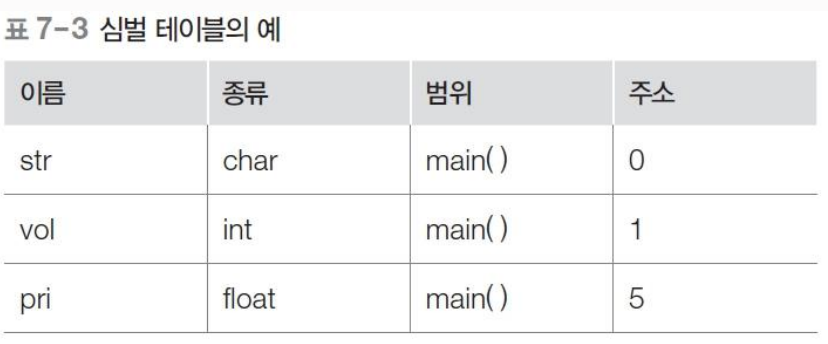
- 오류 점검 시 사용된다.
- 변수 사용할 때마다 사용 범위를 지키는지 점검한다.
- 컴파일러가 만든 변수의 주소는 논리 주소이다.
