
배경
사이드 프로젝트에서 사용하던 Elasticsearch가 갑자기 제대로 동작하지 않는 오류가 발생했다.
사실 이전부터 OpenSearch(Elasticsearch) 사용 비용이 부담스럽다는 이야기가 있어, 이번 기회에 검색 엔진을 교체하기로 했다.
물론 EC2에 직접 OpenSearch를 올리면 비용 부담은 줄일 수 있겠지만, 그 경우 운영·모니터링·장애 대응을 모두 직접 해야 한다는 점이 걸렸다.
그래서 나는 MongoDB Atlas Search를 선택했다!
내가 Atlas Search를 고른 이유는 다음과 같다.
Free Plan 제공
기본적으로 무료 요금제에서 512MB 저장소와 3개의 인덱스를 제공한다. 프로젝트 성격에 따라 다르겠지만, 검색용으로는 이 정도면 충분하다고 판단했다.
다양한 분석기 지원
Nori, Edge N-gram 등 여러 분석기를 손쉽게 활용할 수 있다. Atlas Search는 MongoDB Atlas에 내장된 전문 검색 솔루션으로, 별도의 검색 시스템 없이 데이터베이스 내부에서 고성능 관련성 기반(Full-text) 검색 기능을 제공한다.
운영 편의성
Atlas Search를 사용하면 운영 관리, 모니터링, 장애 대응을 Atlas가 알아서 처리해 준다. 따라서 사용자는 인덱스 설계와 쿼리 작성에만 집중할 수 있다.
참고로 내가 저번 글에서 다양한 검색 기능들을 분석하였는데, 자세한 내용이 궁금하다면, 해당 글을 참고해도 좋을 것 같다.
MongoDB Atlas Search 설정
Atlas Search에서 사용방법을 매우 자세히 알려주고 있다. 가입 및 클러스터, 컬렉션 생성 방법은 상세히 설명하고 있는 다른 블로그가 많기에 생략하겠다.
아래에 내가 참고한 블로그들을 정리해두겠다. 이를 바탕으로, 클러스터 및 컬렉션들을 생성했다.
데이터베이스 설계
컬렉션을 생성했다면, 이제 해당 데이터베이스를 어떻게 설계할지 고민할 차례이다.
내가 구현해야 하는 검색 기능은 크게 두 가지였다.
1. 가수 이름 검색
2. 곡 이름 검색
데이터베이스를 설계하는 과정에서 마주친 주요 고민은 다음과 같다.
1. 검색 필드를 따로 저장할 것인가?
‘가수 이름 검색’을 구현하면서, 가수 데이터에는 name, second_name, third_name처럼 여러 동의어를 저장할 필요가 있었다. (예를 들어, 아이유를 IU로도 검색할 수 있게 하기 위함이다.)
처음에는 이 세 필드를 MongoDB에도 각각 저장하려고 했다.
그러나 검색 대상이 세 필드 전부라면, 세 값을 이어붙여 search_names (예: "아이유 IU")라는 하나의 필드에 합쳐 저장하는 것이 더 효율적이지 않을까 생각했다.
장점
- 데이터 저장 공간 절약:
특히 나처럼 512MB 프리티어 환경에서는 매우 중요한 요소이다. - 검색 성능 향상:
- 단일 필드를 대상으로 하므로 쿼리 성능이 좋아진다.- 예를 들어, 필드를 따로 저장하면 아래처럼 should(OR) 조건이 3개나 필요한 쿼리를 써야 한다.
이런 방식은 쿼리 복잡성 증가 → 성능 저하로 이어질 수 있다. 실제로 공식 문서에서도 이 문제를 언급하고 있다.{ "index": "default", "compound": { "should": [ { "text": { "query": "", "path": "name" }}, { "text": { "query": "", "path": "second_name" }}, { "text": { "query": "", "path": "third_name" }} ] } }
- 예를 들어, 필드를 따로 저장하면 아래처럼 should(OR) 조건이 3개나 필요한 쿼리를 써야 한다.
단점
- 원본 필드 파싱 필요:
검색 결과 중에서 특정 원본(예: "IU") 값만 리턴하려면, 합쳐진 문자열을 다시 파싱해야 한다. - 동기화 복잡 :
데이터 수정 시 동의어를 합치는 로직을 항상 신경 써야 한다.
하지만 나의 경우, 원본 데이터(name, second_name, third_name)는 이미 MySQL에 각각 저장돼 있고 MongoDB는 오직 검색을 위한 용도로만 사용한다. 따라서 search_names만 저장해도 문제 없겠다는 결론에 도달했다.
이는 Single Source of Truth(SSOT)와도 관련이 있다.
즉, MySQL이 상세 데이터의 최종·유일한 원본(Single Source of Truth, SSOT) 역할을 하고, MongoDB는 검색 인덱스 전용으로만 사용되는 구조이다.
2. _id vs id 필드 사용
Atlas Search의 목적은 특정 가수나 곡의 id 리스트를 빠르게 반환하는 것이다.
MongoDB 문서에는 기본적으로 _id 필드(고유 ObjectId)가 존재한다.
처음에는 MySQL의 artists.id나 songs.id를 별도 id 필드에 저장하고, _id로는 자동 생성되는 ObjectId를 그대로 두려고 했다.
그러나 문득 이런 의문이 들었다.
_id에 MySQL의 id 값을 바로 넣는 것이 더 직관적이지 않을까?
장점 (_id=MySQL id)
-
매핑 단순화:
MongoDB와 MySQL 간 매핑 로직이 단순해진다.
Document의 _id만 봐도 어떤 MySQL row와 연결되는지 바로 알 수 있어, 디버깅·로그 분석·API 응답 처리가 훨씬 직관적이다. -
메모리 절약:
불필요하게 id 필드를 따로 둘 필요가 없다.
작은 데이터셋에서는 티가 안 나지만, 수만 건 이상 쌓이면 스토리지와 인덱스 관리 효율에 영향을 줄 수 있다.
단점
- MongoDB ObjectId의 이점 상실:
ObjectId가 제공하는 생성 시간 정보, 전역 고유성, 기본 정렬 등의 장점을 잃는다. - 데이터 충돌 위험:
한 컬렉션에 여러 테이블 데이터를 섞어 저장한다면 id가 겹칠 수 있다. 따라서 이 경우에는 prefixed id 같은 구분 방안이 필요하다.
나는 ObjectId의 고유성, 생성시간 정보가 필요하지 않고, 여러 테이블을 한 컬렉션에 섞어 저장할 계획도 없기 때문에, _id에 MySQL의 artists.id나 songs.id를 그대로 넣는 구조를 선택했다.
3. 곡 데이터에 artistId도 포함할 것인가?
곡 이름 검색은 크게 두 가지로 나뉜다.
1. 전체 곡을 대상으로 이름 검색
2. 특정 가수의 곡을 대상으로 이름 검색
처음에는 2번을 해결하기 위해 MongoDB 곡 데이터에 artistId도 포함하려 했다. 하지만 생각해보니, 애초에 가수가 특정되면 곡의 개수가 확 줄어들 텐데, 이 정도는 MySQL의 LIKE 검색으로도 충분히 괜찮은 성능이 나올 것 같았다. 오히려 불필요하게 artistId를 포함하는 것은 무료 티어의 특성상 저장 공간 낭비가 될 수 있다.
궁금해서 노래를 가장 많이 낸 가수는 몇 곡 정도 발표했는지 찾아보았다.

2000곡이면 like로도 충분하겠다는 생각이 들었다!
바로 곡 데이터에서 artistId를 지웠다.
그래서 결국 내가 설계한 데이터 구조는 다음과 같다.
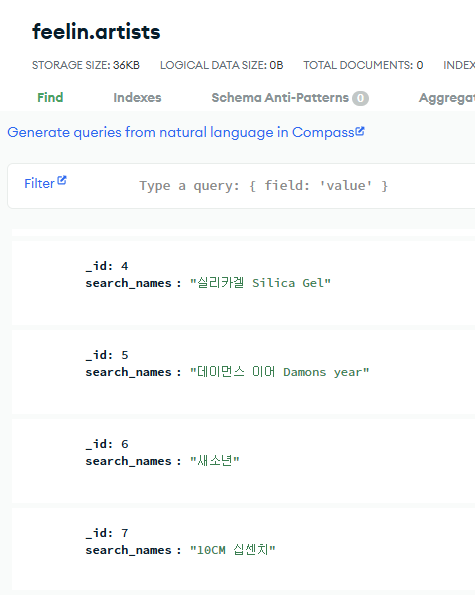 | 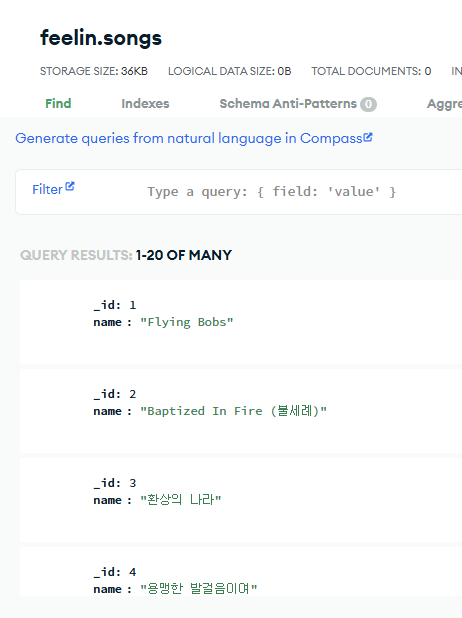 |
|---|
index 설정
가수 이름 검색: Nori vs. Autocomplete
처음에는 가수 이름 검색을 한국어 형태소 분석기인 Nori를 사용해서 구현하려고 했다. 하지만 Atlas Search의 analyzer를 공부하면서 이 방식에 의문이 들었다.
대부분의 가수 이름은 "실리카겔"처럼 고유명사이다. 이런 이름을 "실리", "카", "겔"과 같이 형태소로 분리하는 것은 검색에 전혀 도움이 되지 않는다. 실제로 사용자는 "실"이나 "실리카"처럼 이름의 일부를 입력하며 검색할 가능성이 높기 때문이다.
따라서 중요한 것은 자동완성(autocomplete) 기능을 구현하는 것이다. MongoDB Atlas Search는 바로 이런 목적에 최적화된 autocomplete 연산자를 제공한다.
전체 index 구조는 다음과 같다.
{
"mappings": {
"dynamic": false,
"fields": {
"search_names": {
"foldDiacritics": true,
"maxGrams": 10,
"minGrams": 1,
"tokenization": "edgeGram",
"type": "autocomplete"
}
}
}
}| 옵션명 | 설명 |
|---|---|
| dynamic: false | 색인 시 명시적으로 정의되지 않은 필드는 자동으로 생성하지 않는 설정이다. 즉, 미리 맵핑에 정의한 필드만 색인/검색 대상이 되어, 예기치 않은 필드 생성이나 인덱스 크기 증가를 방지한다. 색인을 엄격하게 관리할 때 주로 사용된다. |
| type: "autocomplete" | 자동완성 검색에 특화된 토큰화 과정을 사용하도록 지정하는 필드 타입. |
| tokenization: "edgeGram" | 단어의 시작 부분부터 점진적으로 토큰을 생성한다. 예를 들어 "실리카겔"은 "실", "실리", "실리카", "실리카겔"로 토큰화된다. 이를 통해 입력하는 이름 앞부분에 대해 즉각적인 검색 결과 제공이 가능하다. |
| minGrams: 1, maxGrams: 10 | 토큰의 최소 및 최대 길이이다. minGrams가 1이므로 한 글자 입력부터 검색 가능하며, maxGrams 10으로 최대 10글자까지의 토큰을 인덱싱한다. 아 방식으로 대부분의 가수 이름 길이 커버가 가능하도록 했다. |
| foldDiacritics: true | 발음 부호(diacritics)를 제거하는 옵션이다. |
곡 이름 검색: Multi Analyzer 활용
곡 이름은 가수 이름보다 길고, 사용자가 일부 단어만 기억하는 경우가 많다. 예를 들어, "어제는 당신 꿈을 꿨어요"라는 곡을 사용자가 "당신"이나 "꿈"이라는 단어만으로 검색할 수도 있다. 따라서 단순히 이름의 앞부분만 검색하는 autocomplete만으로는 부족하다고 판단했다.
이런 점을 고려해, Nori와 autocomplete를 함께 사용하는 방식을 채택했다. 또한 데이터를 분석한 결과 약 1/3의 곡 제목이 영어로 되어 있어, 영어 검색을 위해 English Analyzer도 Multi Analyzer 형식으로 추가했다.
참고로 여러 번 테스트 해본 결과 MongoDB Atlas Search에서 Multi Analyzer는 기본적으로 Lucene 기반 분석기들만을 대상으로 하는 것 같았다. 실제로 autocomplete와 Nori를 multi로 연결해보려고 했지만 잘 되지 않았다. 이유가 나와 있는 문서를 찾지는 못했지만, 토큰 분리 방식이 다르기에 문제가 되는 것 같다. (Nori analyzer는 형태소 기반 토큰을 생성하는 반면, autocomplete(edge n-gram)은 단어의 접두사부터 점진적으로 토큰을 나누어 생성한다.)
결국 autocomplete는 Multi Analyzer가 아닌 Sub-field 형식으로 선언했다.
Multi Analyzer vs Sub-field
Multi Analyzer: 한 필드에 여러 분석기를 동시에 적용함. 쿼리 단순, 색인 구조 깔끔하지만, 분석기 조합 제한(Lucene 계열) 있음.
Sub-field: 같은 필드를 여러 서브필드로 나눠 각각 다른 분석기 적용 가능. 분석기의 제한은 없지만, 쿼리 시 모든 필드를 따로 검색해야 함.
전체 index 구조는 다음과 같다.
{
"mappings": {
"dynamic": false,
"fields": {
"name": [
{
"analyzer": "lucene.nori",
"multi": {
"englishAnalyzer": {
"analyzer": "lucene.english",
"type": "string"
}
},
"type": "string"
},
{
"foldDiacritics": true,
"maxGrams": 7,
"minGrams": 1,
"tokenization": "edgeGram",
"type": "autocomplete"
}
]
}
}
}| 항목 | 설명 |
|---|---|
| multi Analyzer | 하나의 필드에 대해 여러 분석기를 적용하기 위한 옵션. 예) 한국어(Nori)와 영어 분석기(English) 동시에 적용 |
| analyzer: lucene.nori | 한국어 형태소 분석기로, 한국어 텍스트를 형태소 단위로 분리해 인덱싱함. 키워드 검색에 유용 |
| analyzer: lucene.english | 영어 텍스트에 대해 어간 추출, 소문자 변환 등을 수행해 다양한 형태의 단어 변형을 통합 검색 가능 |
| type: autocomplete | 자동완성 검색을 지원하는 인덱스 타입. 사용자가 입력하는 문자열 앞부분에 대해 실시간 결과 제공 |
| tokenization: edgeGram | 단어 앞부분부터 점진적으로 n-gram 토큰 생성. 예: "어제는" → "어", "어제", "어제는" |
| minGrams / maxGrams | 토큰 길이 범위 지정. minGrams=1은 한 글자만 입력해도 검색 가능, maxGrams=7은 최대 7글자길이까지 커버 |
검색 쿼리 정하기
가수 이름 검색
앞서 설계한 index를 기반으로 실제 검색 쿼리를 작성해보았다.
[
{
"$search": {
"index": "artists_search_index",
"autocomplete": {
"query": "실리",
"path": "search_names",
"tokenOrder": "any"
}
}
}
]tokenOrder
tokenOrder: "any"
쿼리의 토큰들이 문서 내에서 어떤 순서로든 나타날 수 있음을 의미한다. 즉, 토큰들이 순서에 상관없이 문서 내에 존재하기만 하면 매칭된다.
tokenOrder: "sequential"
쿼리의 토큰들이 문서 내에서 쿼리 입력 순서대로 연속적으로 나타나는 경우에만 결과로 포함된다. 즉, 토큰 순서가 쿼리와 동일한 순서로 일치해야 한다.
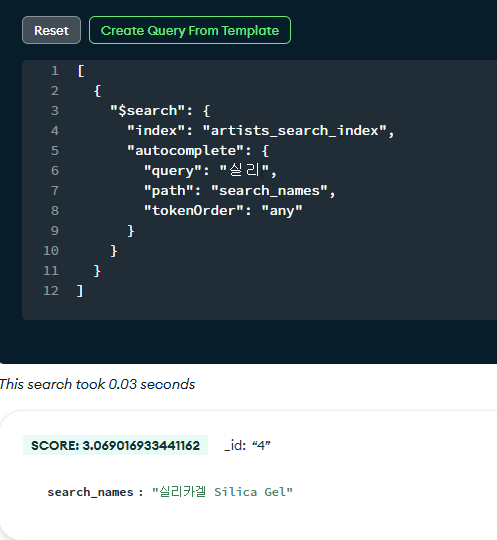
Search Tester를 통해 실제 제대로 동작함을 확인해볼 수 있었다.
곡 이름 검색
곡 검색 쿼리는 다음과 같다.
[
{
"$search": {
"index": "songs_search_index",
"compound": {
"should": [
{
"text": {
"query": "love",
"path": [
"name",
{
"value": "name",
"multi": "englishAnalyzer"
}
],
"score": {
"boost": {
"value": 3
}
}
}
},
{
"autocomplete": {
"query": "love",
"path": "name",
"tokenOrder": "any",
"score": {
"boost": {
"value": 1
}
}
}
}
]
}
}
}
]| 항목 | 설명 |
|---|---|
| compound | 여러 개의 검색 조건을 결합하는 연산자. 한 쿼리 내 여러 하위 쿼리를 조합하여 복합적인 검색 조건을 만드는 데 사용. |
| should | compound 내의 조건 배열 중 하나 이상이 일치하면 문서가 선택되는 조건. 논리적 OR 역할을 하며, 여러 조건 중 하나라도 맞으면 통과. |
| multi (text.path) | text 쿼리의 path가 배열 형태로 되어 있으며, "multi" 필드를 통해 해당 필드를 특정 분석기(예: englishAnalyzer)로 추가 인덱싱하여 사용하는 설정. |
| score | 각 쿼리의 검색 점수 부스트(가중치)를 지정. 예를 들어, text 쿼리에 3의 부스트, autocomplete 쿼리에는 1의 부스트를 주어, 결과 랭킹에 영향을 줌. |
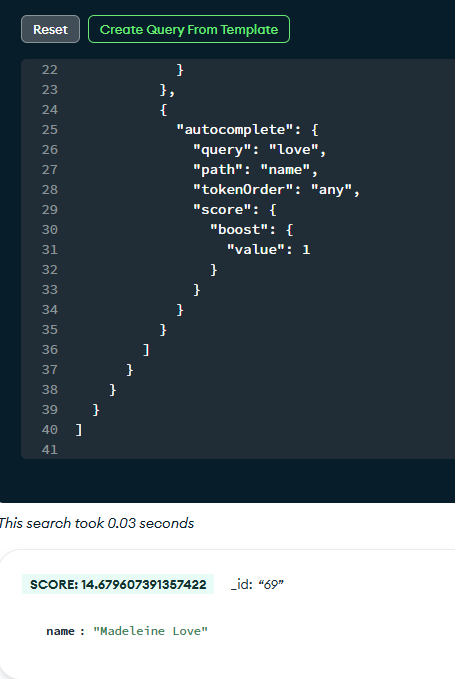
이번 쿼리는 검색어 길이에 따라 다른 전략을 적용하도록 설계했다.
짧은 검색어는 형태소 단위로 분석이 어렵기 때문에 autocomplete에 가중치(score)를 높게 주어 자동완성 방식 위주으로 결과를 가져오고, 긴 검색어는 Nori나 English 분석기에 가중치(score)를 높게 주어 텍스트 기반 위주의 검색을 수행하도록 했다.
두 조건은 compound의 should로 묶어 둘 중 하나만 만족해도 검색되도록 구성하고, 각각 score.boost를 달리 설정했다.
또한 multi 옵션을 사용해 같은 필드에서 한국어와 영어 분석기를 동시에 적용함으로써, 길고 복잡한 검색어도 효율적으로 처리할 수 있었다.
 | 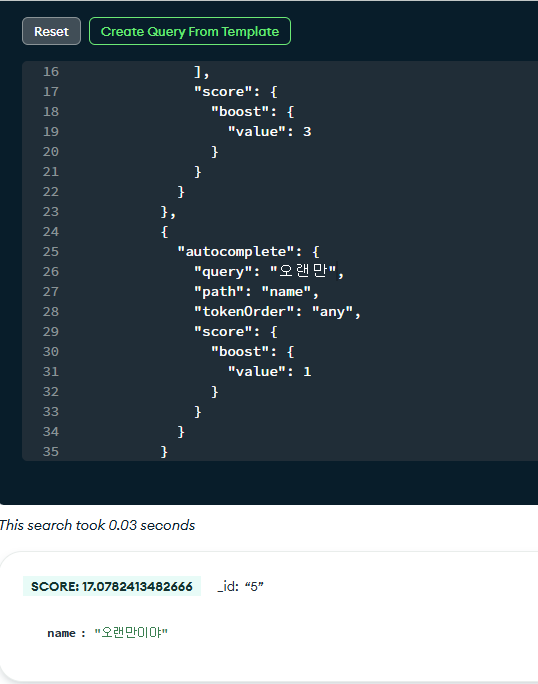 |
|---|
화면에서는 짤려서 잘 안 보이지만 Search Tester를 통해 한글 및 영어 검색어 모두 제대로 동작함을 확인해볼 수 있었다.
정렬
Atlas search를 공부하면서 여러 정렬 방식에 대해서도 알게 되었다. 이번 프로젝트 검색 기능에서는 쓰지 않았지만, 해당 부분들도 정리해두었다. 더 자세한 부분이 궁금하다면 이 블로그나 공식 문서들을 참고하면 좋을 것 같다.
1. 기본 방식
- 검색 결과는 기본적으로 점수(score) 내림차순으로 정렬되어 반환된다. 점수는 쿼리와 문서 간의 관련성(relevance)을 나타낸다고 할 수 있다.
2. $sort 사용
- 추가적인 정렬 기준을 지정할 때 사용한다.
예: { $sort: { price: 1 } } → 가격 오름차순 정렬. - 단점: 필터링과 정렬이 별도 프로세스로 처리되어 시간이 더 걸릴 수 있다.
3. storedSource & returnStoredSource
- storedSource : 검색 시 원하는 필드만 미리 저장(stored)해둬서 검색 속도를 높이는 기능이다.
- returnStoredSource: 검색 결과에 storedSource로 저장된 필드를 포함시켜 반환한다.
- 정렬 기준이 되는 필드을 storedSource로 설정하면 바로 접근할 수 있다.
4. near operator
- 위치 기반 정렬 시 사용한다.
예: 특정 좌표에 가까운 순서대로 문서를 정렬 가능. - 점수 기반 정렬과 결합할 수 있다.
5. score function
- 점수를 사용자 정의(custom) 방식으로 조정할 수 있다.
예: 특정 필드 가중치를 높이거나, 거리 기반 점수를 조합할 때 활용.
참고
Atlas-Search 및 스프링 부트 도입
Atlas-Search 인덱스 생성
Atlas-Search 공식 페이지
https://www.mongodb.com/ko-kr/docs/atlas/atlas-search/
고급 정렬
https://tech.inflab.com/202211-mongodb-atlas-search/ → 개인적으로 도움이 많이 되어서, altas search을 도입하시는 분들이라면 읽어보는 것을 추천하고 싶다.
