
배경
이전 글에서 Altas Search를 활용해 altas search index를 설계하고 실제 검색 쿼리까지 작성해 테스트해보았다. 이번에는 실제 해당 검색 기능을 프로젝트와 연동하면서 겪었던 과정들에 대해 정리해보고자 한다.
구조
사용자 검색 요청
│
▼
MongoDB Atlas Search (ID 조회)
│
├─ 결과 있음 → IdsWithHasNext → MySQL 조회 → DTO 변환 → API 응답
│
└─ 결과 없음 (Mongo 실패) → MySQL LIKE 조회 → DTO 변환 → API 응답
실제 코드를 보기 전 내가 설계한 구조를 한 번 그림으로 표현해보았다. 이 구조를 생각하면서 아래 글을 읽으면 도움이 될 것 같다.
연동
먼저 Spring boot에서 Atlas search 및 MongoDB를 사용하기 위해서는 build.gradle에 다음을 추가해야 한다.
implementation 'org.springframework.boot:spring-boot-starter-data-mongodb'yml에서도 mongoDB 접속 정보를 적어준다.
data:
mongodb:
uri: mongodb+srv://<사용자>:<비밀번호>@<클러스터이름>.oggkgjf.mongodb.net/<DB이름>?retryWrites=true&w=majority&appName=<앱이름>먼저 Song의 데이터 중 MongoDB에 저장할 데이터만 담은 SongMong 엔티티를 저장해주었다. JPA는 엔티티를 조회할 때 반드시 기본 생성자가 필요하며 private 생성자는 사용할 수 없다. 반면, Spring Data MongoDB는 리플렉션으로 private 생성자도 호출할 수 있어, final 필드 기반의 immutable Document를 쉽게 설계할 수 있다.
SongMongo
@Document(collection = "songs")
public class SongMongo {
@Id
@Getter
private final Long id;
@Field("name")
private final String name;
private SongMongo(Long id, String name) {
this.id = id;
this.name = name;
}
public static SongMongo of(Song song) {
return new SongMongo(song.getId(), song.getName());
}
}
이를 바탕으로 Repository를 작성해보았다.
SongMongoCommandRepository
@Repository
public interface SongMongoCommandRepository extends MongoRepository<SongMongo, Long> {
}SongMongoQueryRepository
public interface SongMongoQueryRepository {
IdsWithHasNext searchSongsByName(String query, int offset, int limit);
}SongMongoQueryRepositoryImpl
@Repository
public class SongMongoQueryRepositoryImpl implements SongMongoQueryRepository {
private final MongoTemplate mongoTemplate;
public SongMongoQueryRepositoryImpl(MongoTemplate mongoTemplate) {
this.mongoTemplate = mongoTemplate;
}
@Override
public IdsWithHasNext searchSongsByName(String query, int offset, int limit) {
// nori + english + edgeGram autocomplete
int queryLength = query.length();
// 길이에 따라 가중치 동적 조정
int autocompleteBoost = queryLength <= 3 ? 2 : 1;
int textBoost = queryLength <= 3 ? 1 : 2;
AggregationOperation searchStage = context -> new Document("$search",
new Document("index", "songs_search_index")
.append("compound", new Document("should", Arrays.asList(
new Document("text", new Document()
.append("query", query)
.append("path", Arrays.asList(
"name",
new Document("value", "name").append("multi", "englishAnalyzer")
))
.append("score", new Document("boost", new Document("value", textBoost)))
),
new Document("autocomplete", new Document()
.append("query", query)
.append("path", "name")
.append("tokenOrder", "any")
.append("score",
new Document("boost", new Document("value", autocompleteBoost)))
)
)))
);
AggregationOperation projectStage = Aggregation.project("_id");
AggregationOperation skipStage = Aggregation.skip(offset);
AggregationOperation limitStage = Aggregation.limit(limit + 1);
Aggregation aggregation = Aggregation.newAggregation(
searchStage,
projectStage,
skipStage,
limitStage
);
AggregationResults<Document> results =
mongoTemplate.aggregate(aggregation, "songs", Document.class);
List<Long> ids = results.getMappedResults().stream()
.map(doc -> doc.get("_id", Long.class))
.toList();
boolean hasNext = ids.size() > limit;
if (hasNext) {
ids = ids.subList(0, limit);
}
return new IdsWithHasNext(ids, hasNext);
}
}MongoTemplete
MongoTemplate은 복잡한 MongoDB 쿼리와 aggregation 파이프라인을 직접 다룰 수 있게 해주는 도구이다. 일반적인 쿼리는 @Query나 Aggregation 어노테이션으로도 구현 가능하지만, Atlas Search처럼 $search 스테이지가 들어가는 고급 검색 기능은 MongoTemplate으로 직접 Document를 구성해야 하므로, 사실상 Atlas Search 구현 시 필수적으로 사용된다.
페이지네이션
검색 결과를 페이지네이션을 통해 제공해야 한다. MongoDB에서는 skip, limit 연산자를 제공하기에 이들을 활용했다.
또한 api 응답를 제공하는데 필요한 전체 데이터는 MySQL을 통해서 가져올 수 있도록 id만 추출해서 리턴하는 형식으로 코드를 짰다. 따라서 searchSongsByName은 IdsWithHasNext을 리턴하도록 했다. IdsWithHasNext는 List ids, boolean hasNext를 멤버로 가지는 레코드이다.
SongQueryService
@Service
@Transactional(readOnly = true)
@RequiredArgsConstructor
public class SongQueryService {
private final SongQueryRepository songQueryRepository;
private final SongMongoQueryRepository songMongoQueryRepository;
public OffsetBasePaginatedResponse<SongSearchResponse> searchSongs(String query, int pageNumber, int pageSize) {
if (Objects.isNull(query) || query.isEmpty()) {
return getSongsByNoteCount(pageNumber, pageSize);
}
IdsWithHasNext idsWithHasNext = songMongoQueryRepository.searchSongsByName(
query,
pageNumber * pageSize,
pageSize
);
List<Long> songsIds = idsWithHasNext.ids();
if (songsIds.size() == 0 && pageNumber == 0) {
return OffsetBasePaginatedResponse.of(songQueryRepository.findAllByQuery(query,
PageRequest.of(pageNumber, pageSize))
.map(SongSearchResponse::from)
);
}
List<SongSearchResponse> songs = songQueryRepository.findAllByIdsInOrder(songsIds).stream()
.map(SongSearchResponse::from)
.toList();
return OffsetBasePaginatedResponse.of(
pageNumber,
idsWithHasNext.hasNext(),
songs
);
}
...
}fall-back 구조
pageNumber가 0일 때만 MongoDB Atlas Search의 결과가 없을 경우 MySQL LIKE 검색을 시도하는 폴백(fall-back) 구조를 사용했다. 이는 사용자가 새로운 검색을 시작하는 시점(pageNumber 0)에 최대한 정확한 결과를 제공하기 위함이며, 이미 검색 결과가 있는 다음 페이지(pageNumber > 0)부터는 불필요한 MySQL 검색을 방지하여 시스템 부하를 줄이고 효율성을 높이기 위한 전략이다. 이를 통해 사용자는 더 나은 검색 경험을 얻을 수 있고, 두 데이터베이스의 동기화 문제에 관계없이 안정적으로 검색 기능을 제공할 수 있다.
MySQL과 조인
먼저 songMongoQueryRepository에 쿼리와 offset 및 limit을 가지고 검색을 한다. 이렇게 얻어온 id를 바탕으로 mysql에서 해당 데이터를 조회해 반환한다. 이 때, findAllByIdsInOrder은 실제 id 리스트 속 순서대로 결과를 리턴해야 한다. 이 순서를 보장하기 위해 findAllByIdsInOrder는 다음과 같이 작성했다.
@Override
public List<Song> findAllByIdsInListOrder(List<Long> songIds) {
String idCsv = songIds.stream()
.map(String::valueOf)
.collect(Collectors.joining(","));
NumberExpression<Integer> orderExpression =
Expressions.numberTemplate(
Integer.class,
"FIELD({0}, " + idCsv + ")",
song.id
);
return jpaQueryFactory
.selectFrom(song)
.leftJoin(song.notes, note).fetchJoin()
.join(song.artist, artist).fetchJoin()
.where(song.id.in(songIds))
.orderBy(orderExpression.asc())
.fetch();
}MySQL FIELD 연산자
MongoDB에서 점수가 높은 순서대로 리스트를 만들어 반환했으므로, findAllByIdsInOrder에서도 인자로 주어진 id 리스트 속 순서대로 결과를 리턴해야 한다. 이 순서를 보장하기 위해 FIELD를 사용했다. FIELD 함수는 첫 번째 인자로 주어진 값(song.id)이 두 번째 인자 이후의 목록(songIds 리스트)에서 몇 번째 위치에 있는지를 숫자로 반환한다. 이를 통해, song.id가 songIds에 지정된 순서대로 정렬될 수 있도록 한다.
전체 과정을 보면 다음과 같다.
-
- songIds리스트([3,1,2])를 "3,2,1"와 같은 CSV(Comma Separated Values) 형태로 변환
-
- Expressions.numberTemplate을 통해 JPA에서 지원하지 않은 FIELD 함수를 정의
- FIELD({0}, "3,1,2") 템플릿은 최종적으로 데이터베이스에서 FIELD(song.id, 3, 1, 2) SQL 함수로 실행.
- 이 함수는 song.id 값(즉, {0}에 해당하는 값)이 뒤따르는 목록(3, 1, 2)에서 몇 번째 위치에 있는지를 정수로 반환
-
- 리턴된 정수 값을 기준으로 오름차순(asc) 정렬
기타
이밖에도 create, delete api에도 MongoDB에서 똑같은 데이터가 삽입/삭제되는 로직을 작성해주어야 한다. 찾아보면 예제가 많기에 이 부분은 이 글에서 생략했다.
위와 동일한 방식으로 가수 이름 검색 기능도 구현했다.
결과
실제로 postman에서 search가 정상적으로 되는 것을 확인해볼 수 있었다.
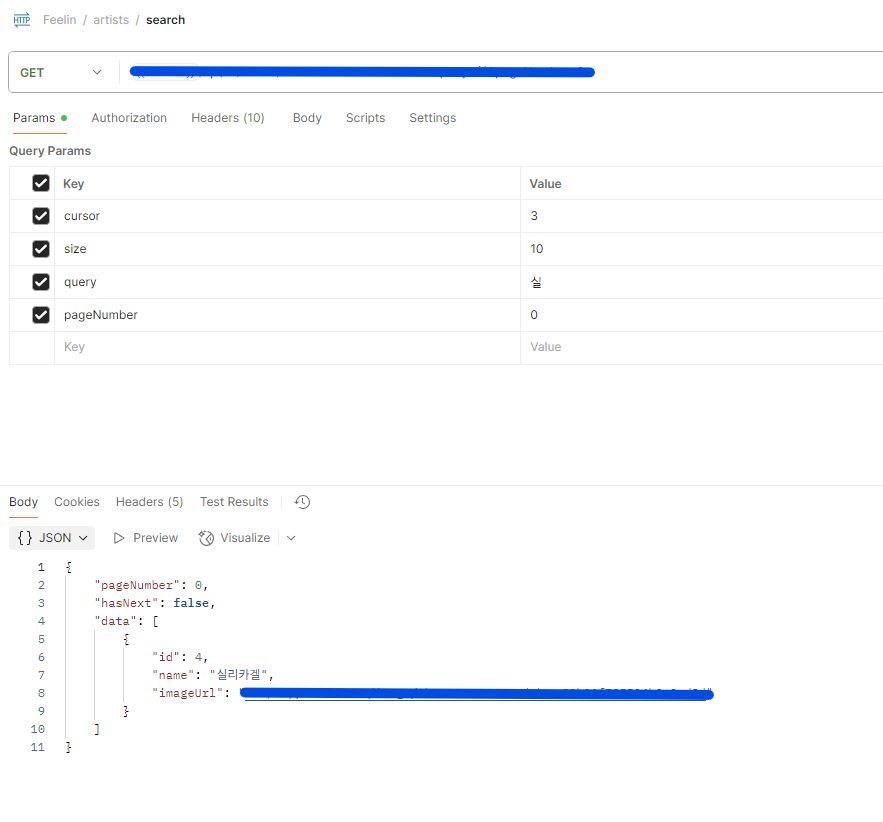
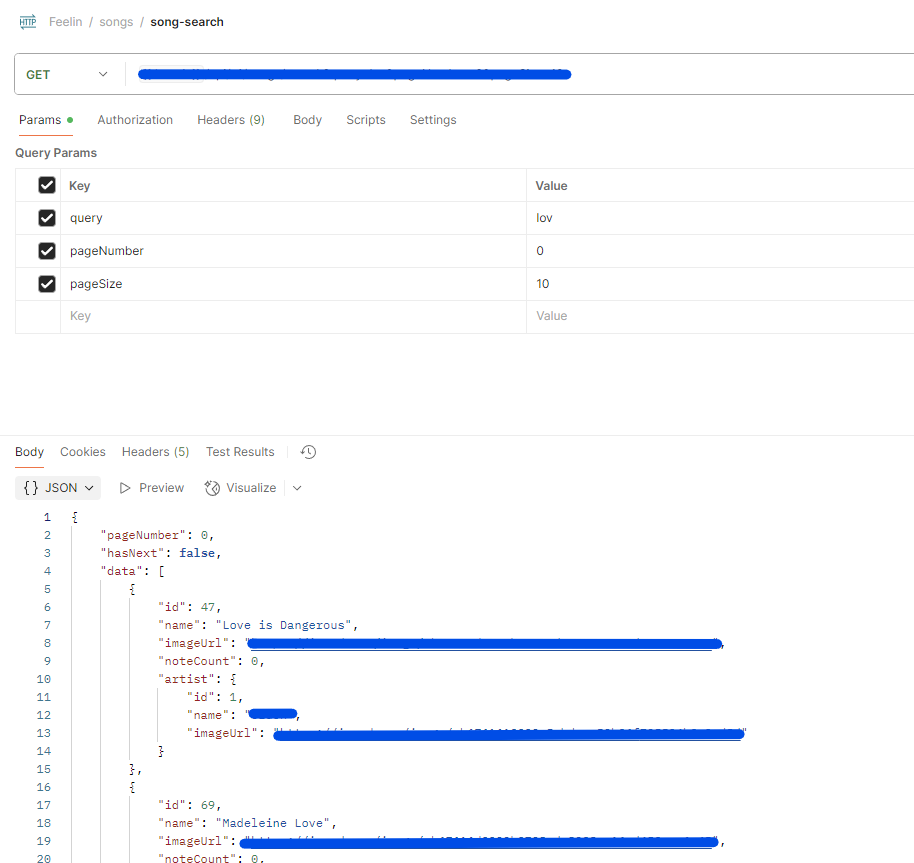
테스트
@SpringBootTest
@ActiveProfiles("local")
@Disabled("성능 측정용이라 기본 실행에서 제외함")
class SongSearchPerformanceTest {
@Autowired
private SongMongoCommandRepository songMongoCommandRepository;
@Autowired
private SongMongoQueryRepository songMongoQueryRepository;
@Autowired
private SongQueryRepository songQueryRepository;
@Autowired
private SongQueryService songQueryService;
@BeforeEach
void setup() {
songMongoCommandRepository.deleteAll();
long startBulk = System.currentTimeMillis();
List<Song> existingSongs = songQueryRepository.findAll();
List<SongMongo> mongoBatch = existingSongs.stream()
.map(SongMongo::of)
.toList();
songMongoCommandRepository.saveAll(mongoBatch);
long endBulk = System.currentTimeMillis();
System.out.println("Bulk insert " + mongoBatch.size() + "개 걸린 시간: " + (endBulk - startBulk) + " ms");
}
@Test
void searchPerformanceTest() {
List<String> keywords = List.of(
"Flying", "Bobs", "불세례", "환상", "용맹", "발걸음",
...
);
// 각 케이스별 latency(ms) 저장
List<Long> mysqlLikeServiceLatencies = new java.util.ArrayList<>();
List<Long> mongoAtlasServiceLatencies = new java.util.ArrayList<>();
List<Long> mysqlLikeRepoLatencies = new java.util.ArrayList<>();
List<Long> mongoAtlasRepoLatencies = new java.util.ArrayList<>();
// MySQL LIKE 테스트 - service
for (String keyword : keywords) {
long start = System.nanoTime();
songQueryService.searchSongsWithLike(keyword, PageRequest.of(0, 12));
mysqlLikeServiceLatencies.add((System.nanoTime() - start) / 1_000_000);
}
// Mongo Atlas Search 테스트 - service
for (String keyword : keywords) {
long start = System.nanoTime();
songQueryService.searchSongs(keyword, 0, 12);
mongoAtlasServiceLatencies.add((System.nanoTime() - start) / 1_000_000);
}
// MySQL LIKE 테스트 - repository
for (String keyword : keywords) {
long start = System.nanoTime();
songQueryRepository.findAllByQuery(keyword, PageRequest.of(0, 5));
mysqlLikeRepoLatencies.add((System.nanoTime() - start) / 1_000_000);
}
// Mongo Atlas Search 테스트 - repository
for (String keyword : keywords) {
long start = System.nanoTime();
songMongoQueryRepository.searchSongsByName(keyword, 0, 12);
mongoAtlasRepoLatencies.add((System.nanoTime() - start) / 1_000_000);
}
java.util.function.Function<List<Long>, String> stats = (latencies) -> {
latencies.sort(Long::compare);
double avg = latencies.stream().mapToLong(Long::longValue).average().orElse(0.0);
long p99 = latencies.get((int) Math.ceil(latencies.size() * 0.99) - 1);
return String.format("평균=%.3f ms, P99=%d ms", avg, p99);
};
System.out.println("MySQL LIKE Repository -> " + stats.apply(mysqlLikeRepoLatencies));
System.out.println("Mongo Atlas Repository -> " + stats.apply(mongoAtlasRepoLatencies));
System.out.println("MySQL LIKE Service -> " + stats.apply(mysqlLikeServiceLatencies));
System.out.println("Mongo Atlas Service -> " + stats.apply(mongoAtlasServiceLatencies));
}
@AfterEach
void cleanup() {
songMongoCommandRepository.deleteAll();
}
}실제 dev의 dump을 사용해 로컬DB에 더미데이터를 로드해서, 100개 검색어에 대한 각각의 Repository단과 Service단의 검색 평균 속도와 p99 성능을 측정해보았다.
결과
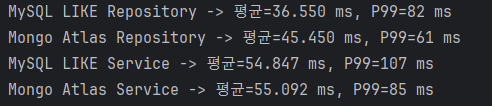
7만건 삽입시
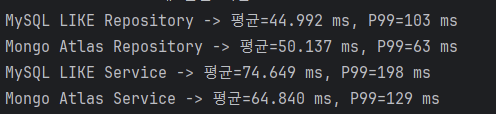
9만건 삽입시
결과 분석
이번 성능 테스트는 단순 문자열 매칭 방식인 MySQL LIKE 검색과, 자동완성 기능에 두 개의 언어 분석기와 점수 기반 랭킹까지 더한 Mongo Atlas의 복합 검색을 대상으로 진행했다. 흥미로운 점은 Mongo Atlas가 훨씬 더 복잡한 연산을 수행함에도 불구하고, 응답 시간의 안정성이 더 뛰어났다는 것이다. 구체적으로 서비스 레벨에서의 P99 성능을 비교했을 때, 7만건 데이터 기준으로 MySQL은 107ms를 기록한 반면 Mongo Atlas는 85ms로 약 20.6% 감소하였다. 데이터가 더 늘어난 10만건 기준에서는 MySQL 198ms, Mongo Atlas 129ms로 격차가 더욱 커지며 약 34.9% 감소 효과를 보였다.
서비스 계층에서는 Mongo Atlas에서 검색한 결과를 다시 MySQL에서 조회해 최종 응답을 구성하는 방식이라 분명 오버헤드가 존재한다. 그럼에도 불구하고 평균 응답 시간은 큰 차이를 보이지 않았으며, P99 기준에서는 오히려 Mongo Atlas가 안정적으로 동작했다. 따라서 Mongo Atlas 기반 검색은 복잡한 연산을 포함하고 있음에도 불구하고 안정성과 일관성을 확보할 수 있었고, 이로 인해 발생하는 추가적인 오버헤드는 충분히 감수할 만한 수준이라고 결론을 내렸다.
참고
FEILD
Atlas search + Spring boot
