
배경
앞선 글들에서 atlas search 도입기와 spring boot 연동을 통해 검색 기능이 제대로 동작하는 것을 확인했다. 여기서 마무리되었다면 좋았겠지만,,, 우리는 현재 MySQL을 주 db로 쓰고 있기에 MongoDB와 MySQL 속 데이터가 일치할 수 있도로 동기화하는 작업이 필요했다. 이 과정에서 내가 겪은 부분들을 정리해보았다.
동기화
기존에 새로 발매된 노래를 collect하는 배치 작업을 담은 SongCollector가 있었기에 이 로직을 그대로 사용하기로 했다.
하루에 한번 MySQL에 없는 노래 mongoDB에 저장
@Async
@Scheduled(cron = "0 30 0 * * *")
public void syncMongo() {
log.info("song mongo sync started!");
int page = 0;
int size = 1000;
Slice<Song> songPage;
do {
songPage = songQueryRepository.findAll(PageRequest.of(page, size));
List<Long> batchSongIds = songPage.stream()
.map(Song::getId)
.toList();
List<Long> existingIdsInMongo = songMongoQueryRepository.findAllIdByIdIn(batchSongIds);
List<SongMongo> songsToSave = songPage.stream()
.filter(song -> !existingIdsInMongo.contains(song.getId()))
.map(SongMongo::of)
.toList();
if (!songsToSave.isEmpty()) {
songMongoCommandRepository.saveAll(songsToSave);
log.info("synced {} songs from MySQL into MongoDB", songsToSave.size());
}
page++;
} while (songPage.hasNext());
}- 먼저 하루에 한번씩 MySQL을 훑어보면서 mongoDB에 아직 저장되지 않은 노래들을 저장하는 코드를 작성했다.
- MySQL에서 Song 데이터를 페이지 단위(1000개씩)로 조회.
- 각 페이지마다 MySQL의 노래 ID 목록을 가져와, MongoDB에 존재하는 ID와 비교.
- MongoDB에 없는 노래 데이터만 songMongoCommandRepository.saveAll()로 MongoDB에 저장.
- 페이지가 더 있을 때까지 반복해서 모든 노래 데이터를 MySQL → MongoDB로 동기화.
새로운 노래 collect시 MongoDB에도 저장
@Scheduled(cron = "0 0 * * * *")
public void collect() {
log.info("song collector starts collecting!");
List<Artist> artists = artistQueryRepository.findAll();
for (Artist artist : subList(artists)) {
List<Song> newSongs = getSongs(artist)
.stream()
.filter(this::notRegistered)
.toList();
newSongs = songCommandRepository.saveAll(newSongs);
try {
songMongoCommandRepository.saveAll(
newSongs.stream().map(SongMongo::of).toList()
);
} catch (Exception e) {
log.warn("MongoDB saveAll failed for {} songs. Cause: {}. Stacktrace: ", newSongs.size(),
e.getMessage(), e);
}
...
}
}원래 노래를 collect해서 MySQL에 저장하는 로직에 해당 곡들을 mongoDB에도 저장할 수 있도록 작성했다. 이 때 SongMongo에는 mysql에 저장된 ID 값이 필요하다. 이를 위해서는 songCommandRepository.saveAll을 아래와 같이 수정해야 했다.
수정 전
@Override
public void saveAll(List<Song> songs) {
jdbcTemplate.batchUpdate(
insertQuery,
songs,
songs.size(),
(ps, song) -> {
ps.setLong(1, song.getArtist().getId());
ps.setString(2, song.getSpotifyId());
ps.setString(3, song.getName());
ps.setDate(4, java.sql.Date.valueOf(song.getReleaseDate()));
ps.setString(5, song.getAlbumName());
ps.setString(6, song.getImageUrl());
ps.setString(7, LocalDateTime.now().toString());
ps.setInt(8, 0);
ps.setString(9, EntityStatusEnum.IN_USE.toString());
ps.setInt(10, 0);
}
);
}수정 후
@Override
public List<Song> saveAll(List<Song> songs) {
jdbcTemplate.execute(con -> {
PreparedStatement ps = con.prepareStatement(
insertQuery,
Statement.RETURN_GENERATED_KEYS
);
for (Song song : songs) {
ps.setLong(1, song.getArtist().getId());
ps.setString(2, song.getSpotifyId());
ps.setString(3, song.getName());
ps.setDate(4, java.sql.Date.valueOf(song.getReleaseDate()));
ps.setString(5, song.getAlbumName());
ps.setString(6, song.getImageUrl());
ps.setString(7, LocalDateTime.now().toString());
ps.setInt(8, 0);
ps.setString(9, EntityStatusEnum.IN_USE.toString());
ps.setInt(10, 0);
ps.addBatch();
}
ps.executeBatch();
return ps;
}, (PreparedStatementCallback<Void>) ps -> {
ResultSet rs = ps.getGeneratedKeys();
List<Long> generatedIds = new ArrayList<>();
while (rs.next()) {
generatedIds.add(rs.getLong(1));
}
for (int i = 0; i < songs.size(); i++) {
songs.get(i).setId(generatedIds.get(i));
}
return null;
});
return songs;
}기존에는 jdbcTemplate.batchUpdate를 사용해 단순히 데이터를 일괄 저장(batch insert)만 수행했고, 저장된 엔티티의 id 값은 반환받을 수 없었다.
이를 개선하기 위해 PreparedStatement를 Statement.RETURN_GENERATED_KEYS 옵션과 함께 사용하고, executeBatch() 실행 후 getGeneratedKeys()를 통해 DB에서 생성된 id 값을 가져와 각 Song 객체에 매핑하도록 수정했다.
참고로 ResultSet은 테이블 모양이라서 "컬럼 인덱스"로 값을 꺼내는데, getGeneratedKeys()가 돌려주는 ResultSet은 보통 1개의 컬럼(id)만 존재한다. 따라서 rs.getLong(1)로 생성된 id를 가져올 수 있다.
즉, saveAll 메서드가 단순히 저장만 하는 것이 아니라, DB에서 발급된 id 값을 포함한 List<Song>을 반환하도록 수정했다.
결과
실제로 해당 방식으로 곡 collect시, MongoDB에도 정상적으로 데이터 값이 들어오는 것을 확인할 수 있었다.
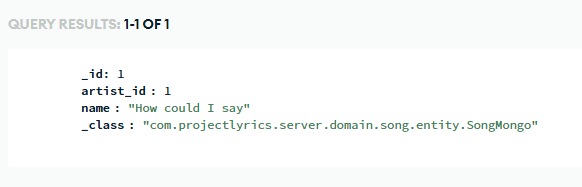
참고
- Statement.RETURN_GENERATED_KEYS
https://blogshine.tistory.com/275
