오늘은 이론 공부는 없었고 실습 코드만 하루종일 돌렸다.
실습 진행하면서 기억 해야할 몇 가지를 적어봐야지
📝 오늘 공부한 내용
DataFrame Index
X = pd.DataFrame()
X[1] = train[train.num==1].target
X[2] = train[train.num==2].target
X[59] = train[train.num == 59].target # 118320 ~ 120359까지
X[60] = train[train.num == 60].target # 120360 ~ 122399까지
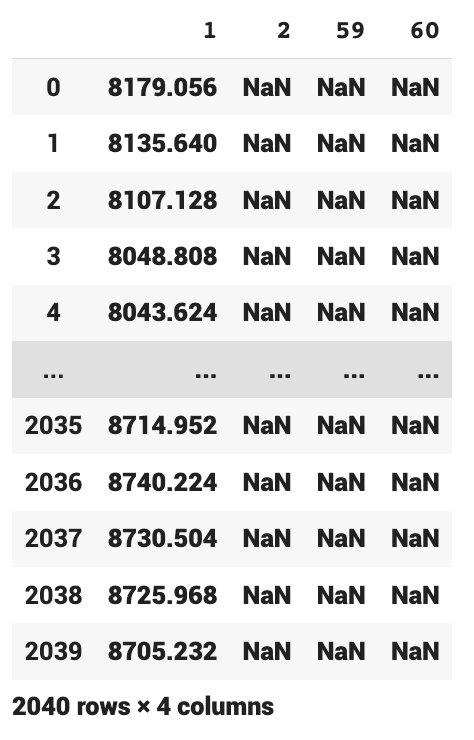
X #0 ~ 2039까지만 출력 / 2040부터는 옆으로 붙여야되는데 밑으로 붙이게 되니까 NaN값이 나온다# NaN --> 인덱스가 안 맞아서
으로 데이터를 붙일 때는 자동으로 인덱스를 바꾸는 것이 아니라서
처음 들어간 데이터를 바탕으로 DataFrame인덱스가 설정된다.
예를 들어, train[train.num==1].target 의 인덱스는 0~2039라서 train[train.num==2].target, train[train.num==3].target 같이 뒤에 들어간 다른 데이터들은 인덱스가 맞지 않아 NaN값이 나온다.
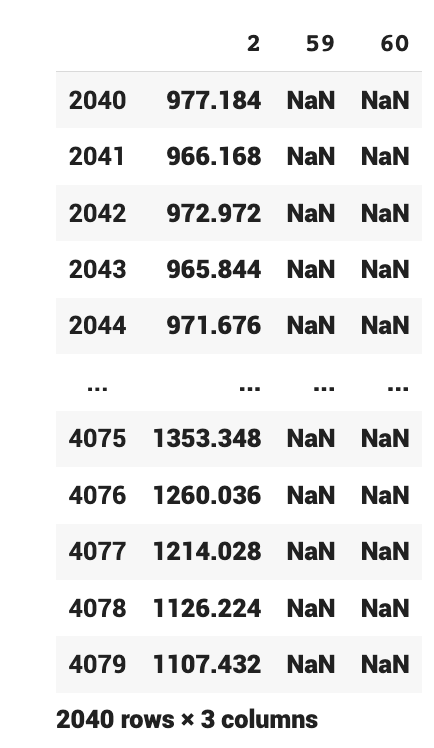
아래 상황도 살펴보자. train[train.num==2].target를 넣었을 때,
X = pd.DataFrame()
X[2] = train[train.num==2].target
X[59] = train[train.num == 59].target # 118320 ~ 120359까지
X[60] = train[train.num == 60].target # 120360 ~ 122399까지
X #0 ~ 2039까지만 출력 / 2040부터는 옆으로 붙여야되는데 밑으로 붙이게 되니까 NaN값이 나온다# NaN --> 인덱스가 안 맞아서
Solution
for num in range(1, 61):
X[num] = train[train.num==num].target.reset_index(drop=True)이런 식으로 reset_index()를 해주어야 한다.
선형 보간법 Linear Interpolation
위키에 따르면 끝점의 값이 주어졌을 때 그 사이에 위치한 값을 추정하기 위하여 직선 거리에 따라 선형적으로 계산하는 방법
sns.lineplot(test.temperature.interpolate(method='linear')) # (O)🌷 느낀점
오늘 무슨 이유인지 fit()이 30분 넘게 실행이 되지 않았다.
강사님 코드는 사람들 말대로 6분만에 돌아갔다🥲.. 뭐가 다른지 확인해 보는데..(솔직히 아직까지 이유는 모르겠지만...) 현타가 심하게 와서 자습시간에 코드가 안 잡혔다. 그래서 내일 있을 논문 리뷰를 하는데 집중이 쉽지 않았지만 또 내일을 위해 더 힘내야지! 이렇게 삽질도 해보고 맨땅에 헤딩도 해보고 하는 모든 경험들이 나에게 좋은 양분이 되길 바라면서 TIL을 마무리 해본다!
