Massive Text Embedding Benchmark (MTEB)
langchain을 활용하여 여러 임베딩 vectorDB를 활용한 RAG를 만들던 와중, 실험 목적을 위해 WIKI dump 파일을 통째로 local DB로 만들려고 시도하고 있었다.
하지만 기존 FAISS를 활용할 때 사용한 Embedding model는 text-embedding-ada-002로, OpenAI사의 유료모델이다. 하지만 wikipedia의 장대한 데이터를 전부 임베딩하려면, 비용면에서 큰 이슈가 발생할 것이 뻔하기 때문에, (이정도 가격이면 사실 openAI에서도 막을 것이다.)
적절한 임베딩 모델들을 찾던 와중, 아래의 리더보드를 찾을 수 있었다.
https://huggingface.co/spaces/mteb/leaderboard
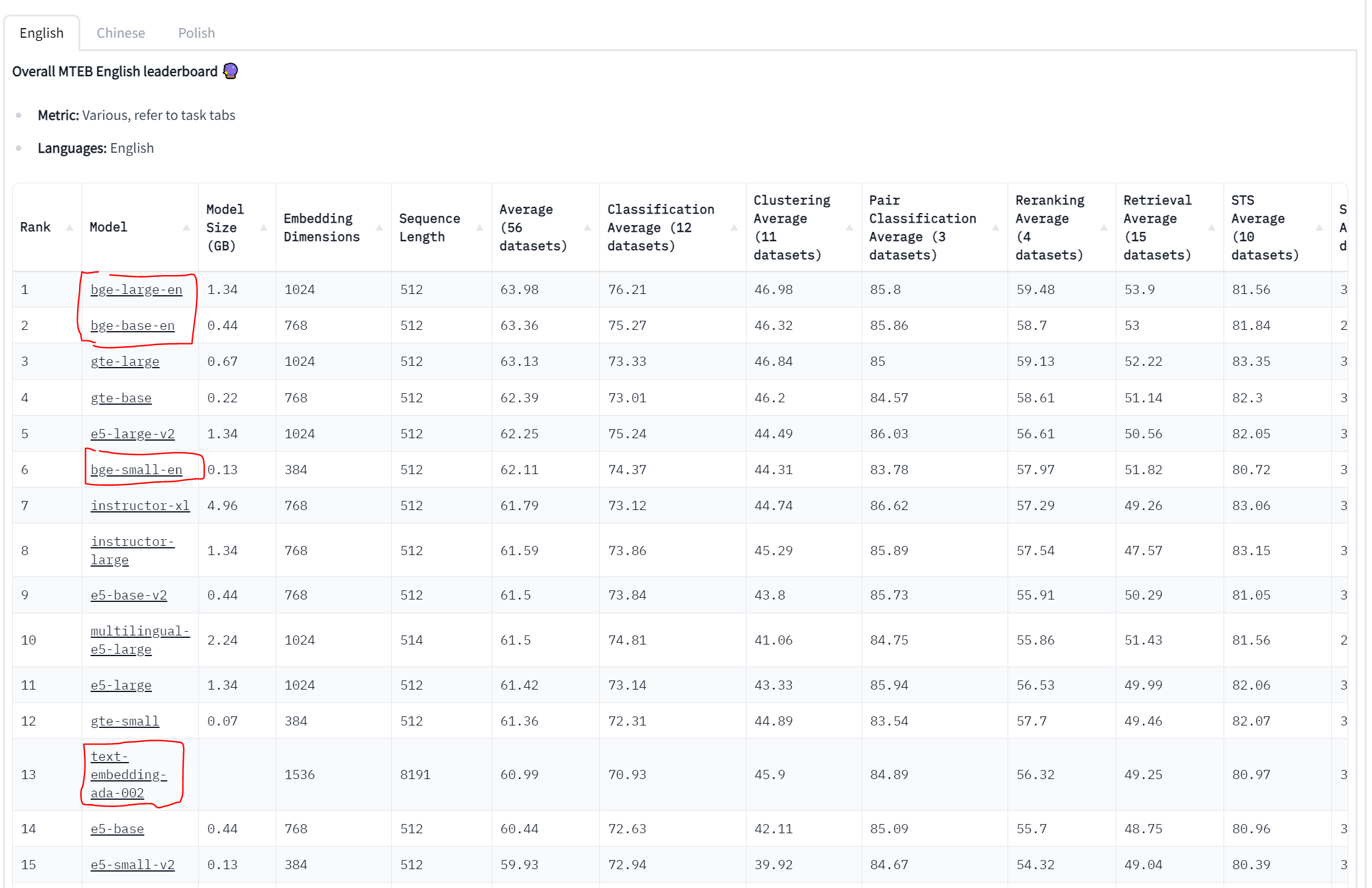
Massive Text Embedding Benchmark (MTEB)에 관한 순위표로, 직역하자면 큰 대용량 텍스트 임베딩에 관한 벤치마크 순위표로 볼 수 있다.
나의 경우 아래의 조건을 충족하면 되었는데,
- 영어 문서에 대한 좋은 성능 (한글 x)
- 사용 비용이 무료
- 대용량 처리에 적합
음... 위 조건에서는 bge 모델이 상당히 이에 적합한 것 같다.
물론 무작정 위 모델을 사용하기에는, text-embedding-ada-002는 한글 임베딩 분야에서는 거의 유일무의한 성능을 보여주기 때문에, 영어 문서만을 임베딩 하고자 하는 것이 아니라면 한번 더 고려하는 것을 추천한다.
BGE-small-en
https://huggingface.co/BAAI/bge-small-en
좀 더 빠르고 로컬에서 돌릴 수 있게 (노트북 환경) 필자의 경우는 bge-small-en를 활용할 것이다.
물론 더 큰 모델을 사용하고 싶다면, BAAI/(원하는 bge 모델)을 model_name의 변수에 넣으면 된다.
참고로, bge models를 사용하고 싶다면, 아래의 라이브러리를 먼저 깔아야 한다.
pip install sentence-transformers
또한, langchain이나 faiss도 깔려있어야 하는데, 만약 깔려있지 않다면 아래의 명령어를 먼저 실행해주도록 하자. (이미 깔려있다면 패스)
pip install faiss-cpu
pip install langchain
내가 개발중인 주력 툴이 langchain인데, 다행히 위의 링크에서 BGE모델을 사용할 수 있도록 langchain에 업데이트 되어있다면서 아래의 기본 예제를 주고 있었다.
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-small-en"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model_norm = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)근데, 사실 이를 처음 실행할 때 오류를 내뿜으며 동작하지 않았는데,
HuggingFaceBgeEmbeddings가 langchain.embeddings 모듈에 존재하지 않다는 것이 그 이유에서였다.
실제로 확인해보니, 진짜로 없었다.
다행히, HuggingFaceEmbeddings을 통해 bge 모델을 불러올 수 있으므로, 나처럼 langchain에서 바로 불러오지 못하는 사람은 아래의 코드를 활용하도록 하자.
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "BAAI/bge-small-en"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model_norm = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)FAISS에 활용하기(저장& 로드)
모델 로드하는 법만 들고오면 정없으니, 이를 저장하고 불러오는 과정도 해보도록 하자
def Embedder(dir_path, store_name="FAISS_INDEX"):
print("try to Loading " + dir_path + "...")
model_name = "BAAI/bge-small-en"
model_kwargs = {'device': 'cuda'} # 안되면 cpu를 사용해보도록 합시다.
# '\n' 문장 단위로 embedding vector로 전환하여 faiss Vector store에 저장합니다.
result = open(
dir_path, "r", encoding="utf-8").read().split('\n')
# [txt for txt in tqdm(result, desc="Running...")]
store = FAISS.from_texts([txt for txt in result], HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs
# encode_kwargs=encode_kwargs
))
store.save_local(store_name)
print(f"Success to save FAISS index from ./{store_name}")위 함수는 특정 텍스트 파일을 들고온 뒤, '\n'(줄바꿈) 단위로 나뉜 문장을 임베딩하여 저장한다.
저장 과정을 progress bar로 확인하고 싶다면, 리스트 부분을 tqdm주석처리한 부분으로 치환하면 된다.
이제, 위의 함수를 사용해서 저장한다면, 해당 경로에 FAISS_INDEX라는 폴더가 나올 것이고, 안의 폴더 내부에 위 두 파일이 있다면 성공한 것이다.

짝짝스
이를 불러오는 건 더 간단하다.
store_name = (folder_name, FAISS_INDEX)
embeddings = HuggingFaceEmbeddings(
model_name = "BAAI/bge-small-en",
model_kwargs = {'device': 'cuda'}
)
new_db = FAISS.load_local(store_name, embeddings)
docs = new_db.similarity_search("신라면의 제조 일자는?", k=5)
# print(len(docs))
print(docs)이렇게 임베딩 모델만 맞춰주면, 내가 사용하고픈 모든 임베딩 모델을 간단하게 활용해볼 수 있으니, 많은 활용을 해보도록 하자!
특히, TEXT 줄 별로 임베딩 하는 것은 langchain의 langchain.text_splitter와 사용이 용이하니, 이를 잘 합쳐서 활용해보는 것도 추천한다.

좋은글 감사합니다. 코드를 자세히 볼수있는 방법은 없을까요?