이번 알고리즘 문제는 문제 자체 설명도 복잡하고 그림으로 이해해야 하는 부분이 많아서 깃헙 커밋 대신 블로깅으로 대체한다.
문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
- 0ms 시점에 3ms가 소요되는 A작업 요청
- 1ms 시점에 9ms가 소요되는 B작업 요청
- 2ms 시점에 6ms가 소요되는 C작업 요청와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.
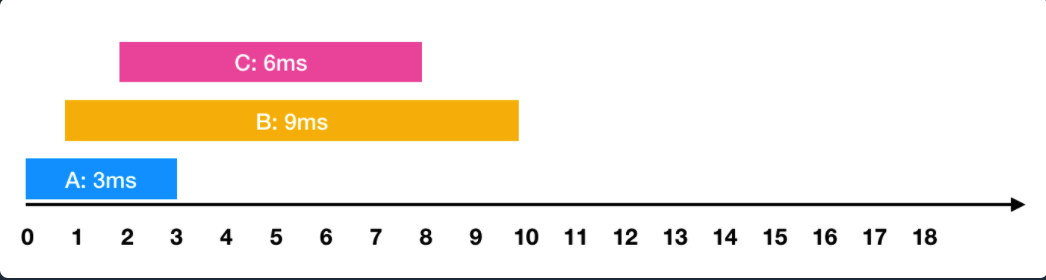
한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.
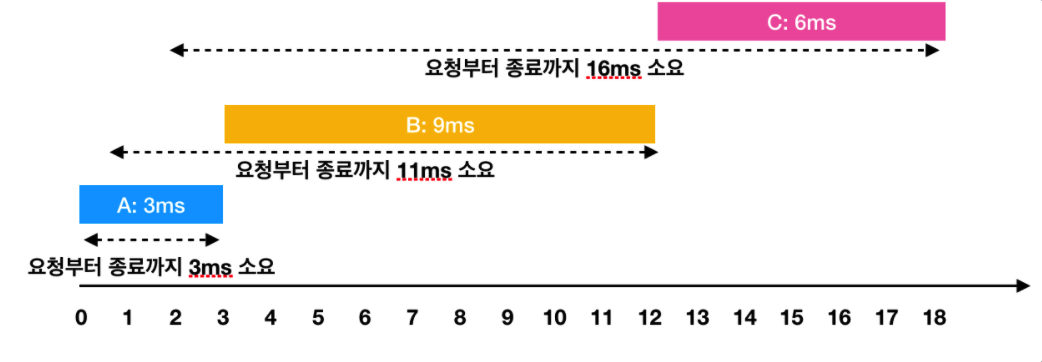
- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms)
- B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms)
- C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면
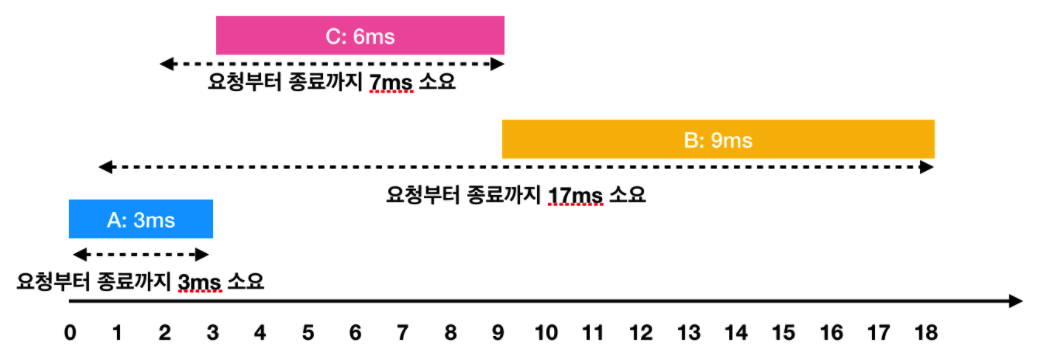
- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms)
- C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms)
- B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항
- jobs의 길이는 1 이상 500 이하입니다.
- jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
- 각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
- 각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
입출력 예
| jobs | return |
|---|---|
| [[0, 3], [1, 9], [2, 6]] | 9 |
입출력 예 설명
문제에 주어진 예와 같습니다.
- 0ms 시점에 3ms 걸리는 작업 요청이 들어옵니다.
- 1ms 시점에 9ms 걸리는 작업 요청이 들어옵니다.
- 2ms 시점에 6ms 걸리는 작업 요청이 들어옵니다.
문제 풀이
우선 로직은 내 자력으로 도저히 생각해낼 수 없어서 다른 블로그 풀이를 보고 이해했다.
(출처 : https://kyun2da.github.io/2020/07/21/diskController/)
간단히 요약하자면 다음과 같다.
1. 요청이 들어온 순서대로 우선 정렬 한다.
2. 태스크를 수행하는 중에 들어온 요청들 중에서는 수행 시간이 짧은 태스크부터 먼저 수행한다.해당 문제는 우선순위 큐로 접근하는 문제인데, 일반적인 큐는 선입선출(먼저 들어간 큐가 먼저 나옴)의 규칙을 따르지만 우선순위 큐는 들어간 순서와 상관없이 우선순위가 높은 큐가 먼저 나오는 구조이다.
위 요약에서 2번 요약이 처음에는 이해가 가지 않았다. 그래서 좀 더 자세히 예를 들어 설명해보자면 다음과 같다.
[[24, 10], [18, 39], [34, 20], [37, 5], [47, 22]]
이런 배열이 입력되었다고 가정해보자. 그러면 우선 요청이 들어온 순서대로 정렬을 하게 될 것이다. 정렬을 하고 나면
[[18, 39],[24, 10],[34, 20],[37, 5],[47, 22]]
위와 같이 정렬이 될 것이다. 여기서 가장 먼저 들어온 요청은 18ms에 들어온 39ms짜리 태스크가 될 것이다.
이 태스크를 수행하는 동안의 시간은 18ms~57ms가 될 것이고, 그렇다면 해당 요청이 끝나기 전에 들어온 태스크는 처음 태스크를 제외한 나머지 태스크 전부가 될 것이다.(제일 나중에 들어온 태스크도 57ms 전인 47ms에 들어왔기 때문)
그렇다면 이제 남은 태스크들을 수행 시간 순으로 오름차순 정렬을 다시 해준다.
[[37, 5],[24, 10],[34, 20],[47, 22]]
다시 정렬한 배열은 위와 같을 것이고, 이제 이 순서로 태스크를 수행했을 시에 구할 수 있는 각각의 요청부터 종료까지의 시간을 구할 수 있다.
해당 예제로 문제의 해를 도출해내는 과정을 계속 설명해보자면,
첫 번째 요청이 종료된 시점부터 정렬한 배열의 첫 요소 태스크를 수행하게 되면 우선 첫 번째 요청([18, 39])의 요청 종료까지 걸리는 시간은 39ms가 될 것이고 두 번째 요청([37, 5])는 57ms~62ms사이에 수행될 것이기 때문에 요청 종료까지 총 시간은 57 + 5 - 37 = 25ms가 된다. 이런 식으로 끝까지 태스크를 수행했을 때의 표를 그려보면 다음과 같다.
| jobs | 수행 기간 | 수행 종료까지 걸린 시간 |
|---|---|---|
| [18, 39] | 18ms ~ 57ms | 39ms |
| [37, 5] | 57ms ~ 62ms | 57 + 5 - 37 = 25ms |
| [24, 10] | 62ms ~ 72ms | 62 + 10 - 24 = 48ms |
| [34, 20] | 72ms ~ 92ms | 72 + 20 - 34 = 58ms |
| [47, 22] | 92ms ~ 114ms | 92 + 22 - 47 = 67ms |
레퍼런스 코드
이 로직을 코드로 표현하면 다음과 같다.
function solution(jobs) {
let answer = 0, // 수행 종료까지 걸리는 시간들의 합
j = 0, // jobs 배열의 index
time = 0; // 수행 시간
jobs.sort((a, b) => {
return a[0] - b[0];
}); // 1. 요청이 들어온 순서대로 정렬
const priorityQueue = []; // 우선순위 큐 선언
while (j < jobs.length || priorityQueue.length !== 0) { // 큐가 완전히 비게 되면 순회 종료 || j가 jobs의 길이를 넘지 않는 조건 하에 while loop
if (jobs.length > j && time >= jobs[j][0]) { // 만약 jobs[j]요청이 들어온 시점이 태스크를 수행 중인 런타임보다 이를 때(태스크 수행 중에 요청이 들어온 경우)
priorityQueue.push(jobs[j++]); // jobs[j]를 큐에 넣고 j의 인덱스를 1 증가 시킨다.
priorityQueue.sort((a, b) => { // 큐의 요소를 작업의 소요시간이 짧은 순으로 오름차순 정렬을 다시 한다.
return a[1] - b[1];
});
continue;
}
if (priorityQueue.length !== 0) { // 큐가 비지 않았다면
time += priorityQueue[0][1]; // 큐에 정렬한 순서대로 수행 시간을 늘려준다.
answer += time - priorityQueue[0][0]; // 각 요청부터 종료시까지 걸린 시간을 차례로 answer 변수에 더해준다.
priorityQueue.shift(); // 수행이 끝난 작업은 큐에서 삭제한다.
} else {
time = jobs[j][0]; // 맨 처음 수행 시작 시 기준 time 설정
}
}
return parseInt(answer / jobs.length); // 평균값 도출
}이 문제에서 주의해야할 점은, 첫 요청부터 종료시까지 걸린 시간을 계산할 때 기준 시간을 0ms가 아닌 맨 처음 요청이 들어온 시점으로 계산해야한다는 점이다. 위의 예제의 경우 18ms에 첫 요청이 들어왔기 때문에 0ms~18ms까지는 대기시간으로 포함시키지 않는다. 그렇기 때문에 첫 번째 요청 처리를 할 때 대기 시간은 없는 것으로 계산하는 것이 맞다. 이 부분이 헷갈리지 않는 사람도 많겠지만 나는 처음에 너무 헷갈렸다. 입출력 예시는 시작점이 0ms인 예시뿐이었기 때문에 시작점이 0ms 이상인 경우에 첫 요청 처리를 어떻게 해야 할 지부터 고민해야 했다.
결론
정렬 기준이 중간에 한 번 바뀌어 총 두 개의 기준으로 정렬을 새로 해주어야 하는 점이 신선했다. 처음에는 요청이 들어온 순서가 기준이었고, 첫 요청을 수행 중에 들어온 요청들은 수행 시간이 짧은 순서가 기준이 되어야 하는 접근 방법을 전혀 생각해내지 못했다는 점에서 아쉬웠지만, 우선순위 큐를 사용하는 유형의 문제를 이번에 처음 접해봤으니 다음 번에 비슷한 유형이 나오면 응용할 수 있도록 복습을 철저히 해야겠다.
