
머신러닝에 관심을 가지게 된 계기
기술의 발전으로 인해 개발 언어는 쉬워지고 개발의 편리성을 높여주는 툴이 발전함에 따라 진입장벽이 낮아지고 있다. 기술 변화 속도는 가속화되고 있다. 이런 상황 속에서 깊어지는 고민, 어떤 개발자로 살아야 할 것인가. 현재 기술에 집중하는 것도 좋지만, 기술의 근간이 되는 과거의 지식들과 앞으로 변화할 미래에 대비하는 것도 중요하다는 생각이 들었다. 컴퓨터 기초 이론들과 ai 관련 공부 필요성을 느꼈다.
우선 머신러닝 공부부터 시작해보려한다. 커뮤니티에서 우연히 머신러닝 야학 2기 소식을 접한 게 가장 큰 이유이다. 또 다른 이유로는, 예전에 참석했던 강연에 대한 기억 때문이다. 공유 오피스 입주사 중 ai 관련 회사에서 주최한 머신러닝 강연에 참석했는데, 월요일 퇴근 이후 시간이라 야근 때문에 못 가는 날도 있었고 여러모로 미련이 남았다. 이번 기회를 통해 아쉬움을 달래보려한다.
머신러닝1 강의를 듣고
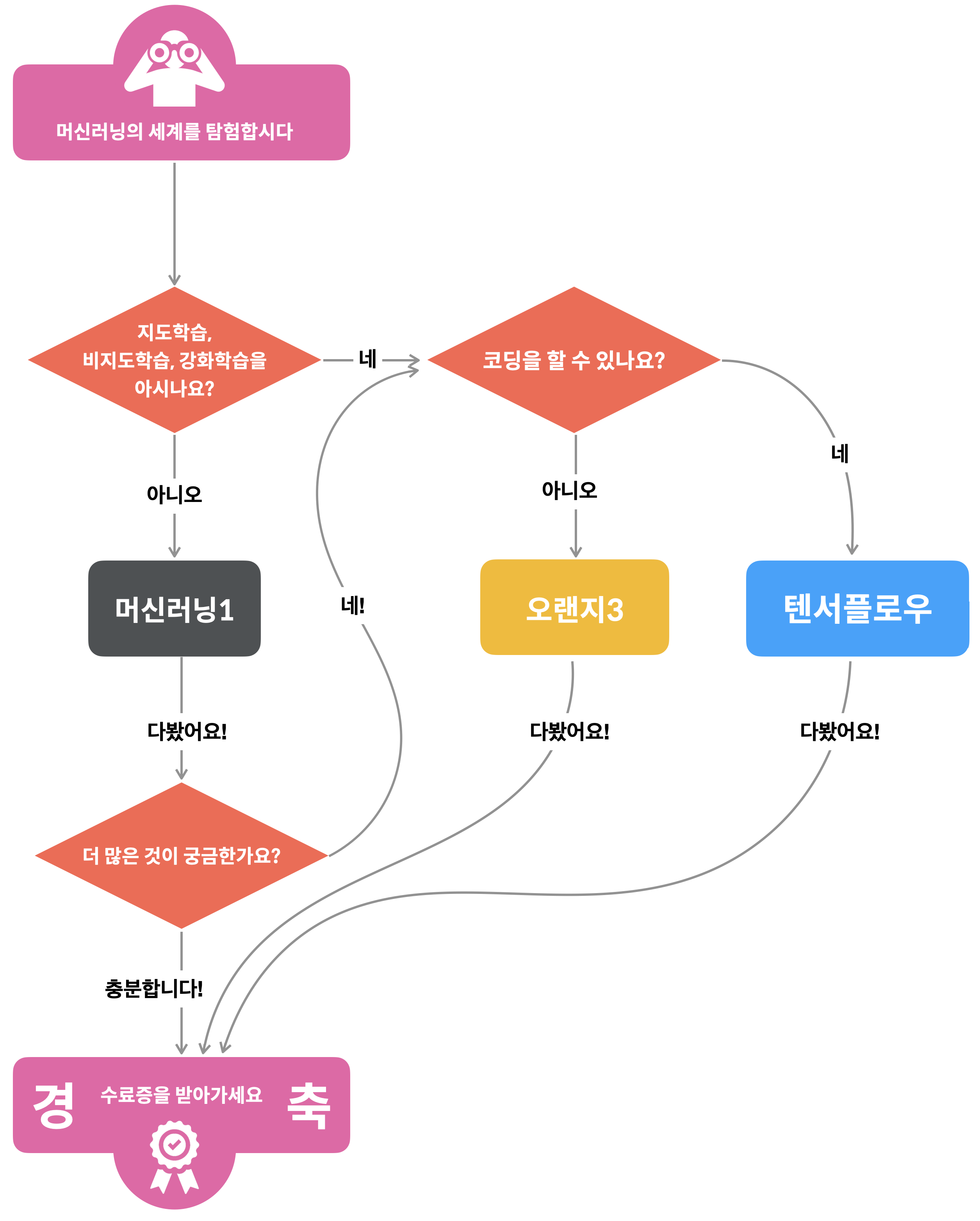
머신러닝 야학 수업 소개 플로우 차트에 따라 우선 머신러닝1 강의부터 시작했다. 크게 교양, 직업 두 파트로 나눠져있다. 교양 부분은 머신러닝에 관심이 있는 사람이라면 누가 들어도 쉽게 이해할 수 있다. 초반에는 이렇게 파트가 나눠있는지 모른채로 들어서 강의 내용이 아쉽게 느껴졌다. 괜한 걱정이었던 게, 직업 파트로 넘어가니 머신러닝 용어도 나오기 시작했다. 설명이 친절해서 처음 입문하는 사람도 쉽게 이해할 수 있다. 전체 강의를 하루에 몰아들어도 부담없을 정도이다.
완강 후 놀랐던 점은 순수한 공공재로 강의를 만들었기에, 저작권 걱정없이 자유롭게 사용하고자 하는 곳에 사용해도 좋다는 마지막 글 때문이었다. 이런 마음 가짐 덕분에 좋은 내용의 강의를 들을 수 있게되어 감사하다. 머신러닝의 기반이 되는 굵직한 키워드들을 잘 정리한 기회였다.
강의 내용 정리
올해는 될 수 있으면, 보고 들은 것의 내용과 느낀 점을 모두 정리하기로 마음 먹었기에 이번 강의를 들으면서 인상깊었던 부분과 오래 기억하고 싶은 내용들을 정리했다.
교양편
오리엔테이션

머신러닝은 기계를 학습시켜 인간의 판단을 위임하기 위해서 고안된 기술입니다.
머신러닝이란?
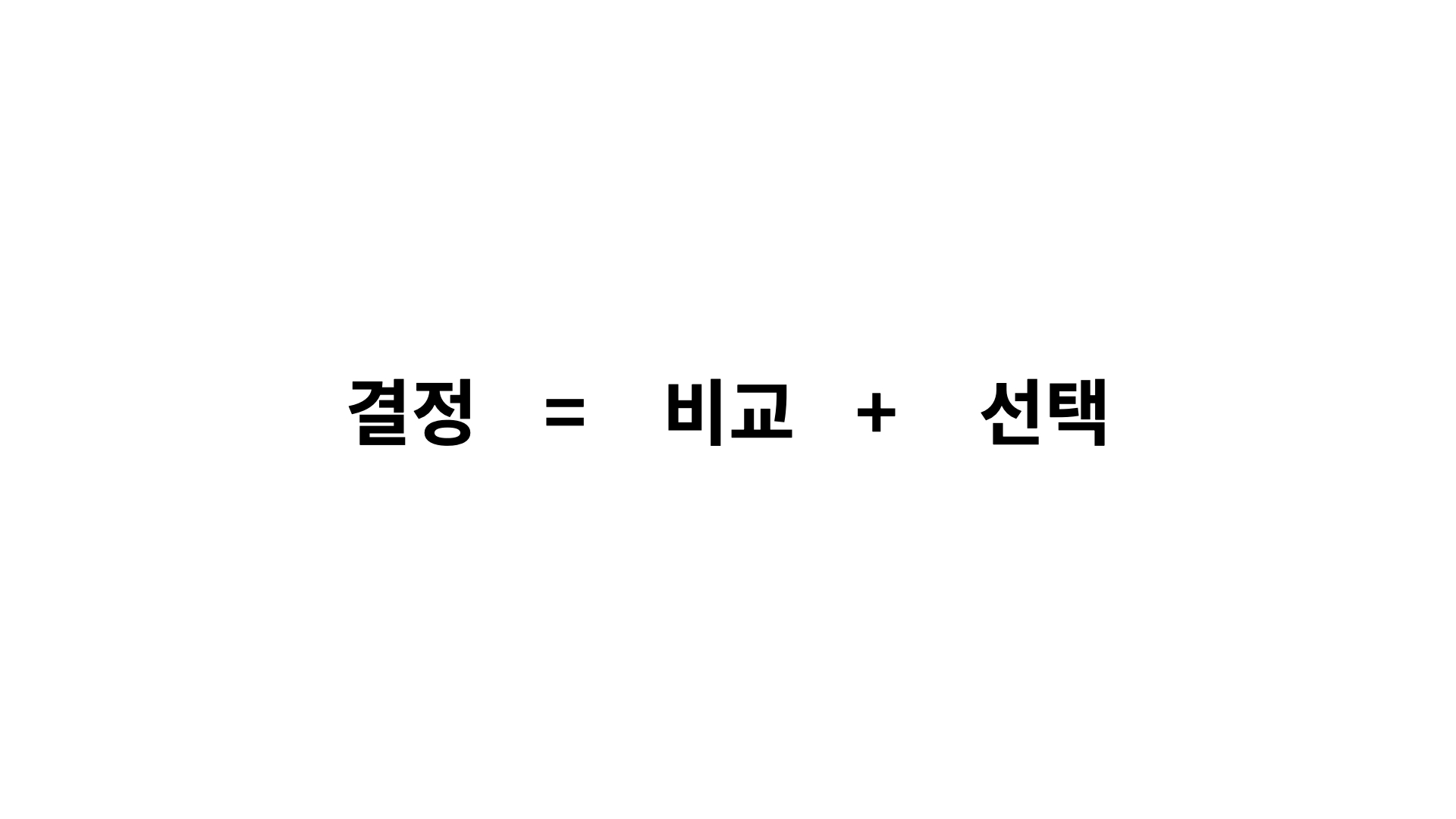
컴퓨터가 등장하면서 인류는 단순한 계산으로부터 해방됩니다.
그리고 더 인간적인 영역인 "결정하기"에 전념할 수 있게 되었습니다.
이런 과정을 통해서 인류의 결정능력은 비약적으로 향상됩니다.
(...)
하지만 사람의 욕심은 끝이 없죠?
인류는 인간의 고유한 영역으로 남아있던 결정을 기계에 맡기고 싶어 합니다.
머신러닝은 우리의 두뇌가 가진 중요한 기능인 판단능력을 확장해서 우리의 두뇌가 더욱 빠르고 정확하게 결정할 수 있게 돕는 기가 막힌 도구입니다.
나의 두뇌를 더욱 두뇌답게 만들어봅시다.
궁리하는 습관

무엇인가를 궁리하는 것이 과거에는 지금만큼 값지지 않았습니다.
궁리를 해봐야 실현하기 어려운 것이 많았거든요.
하지만, 이제 우리는 자신의 궁리가 단지 몽상이 아니라 혁명이 될 수 있는
놀라운 시대에 우리는 살고 있습니다.
이런 시대에 궁리하지 않는다는 것이 얼마나 손해인가요?
모델 Model
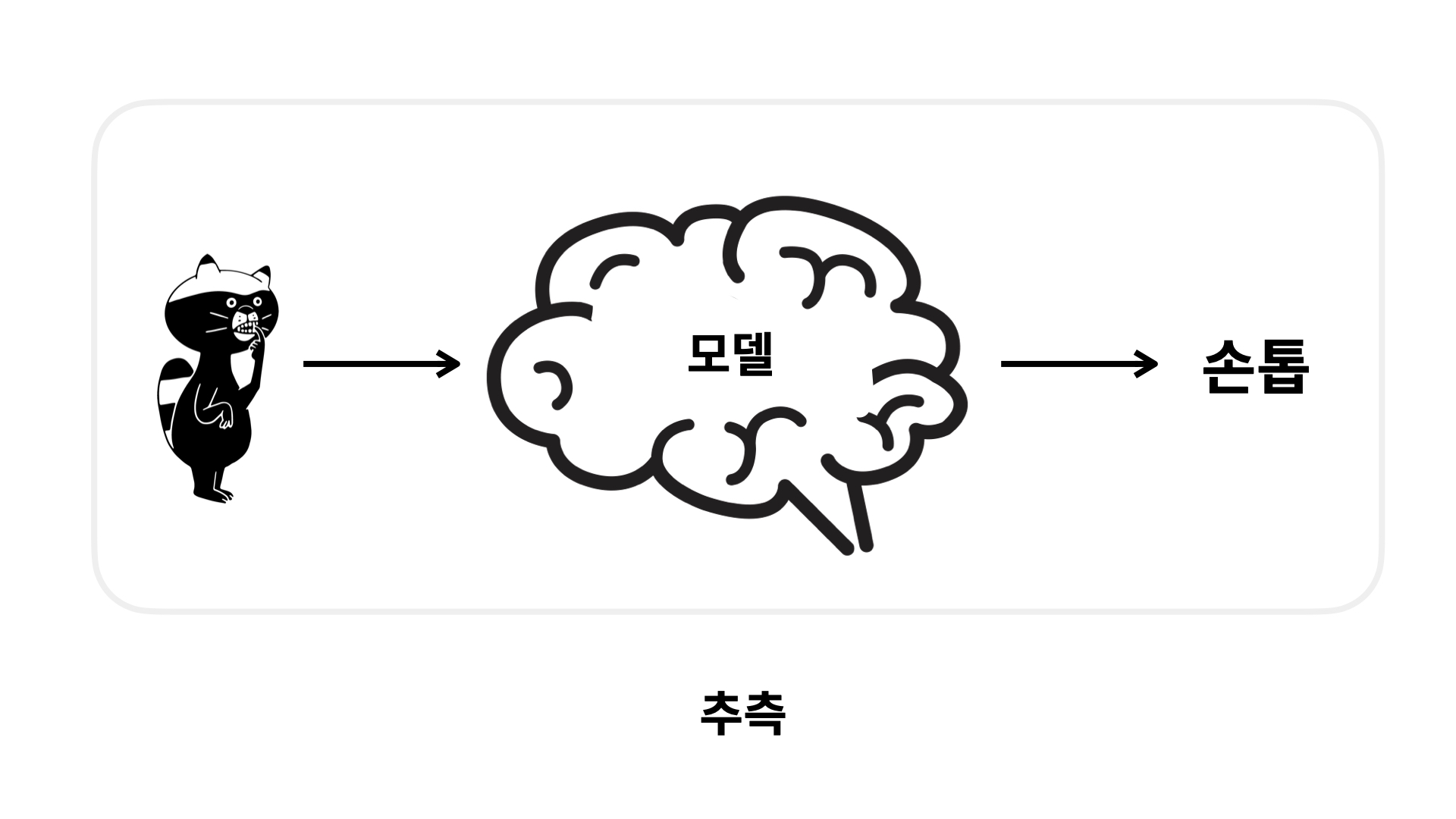
학습이 잘 되어야 좋은 모델을 만들 수 있고, 모델이 좋아야 더 좋은 추측을 할 수 있습니다.
추측이 정확해야 좋은 결정을 할 수 있는 것은 말할 것도 없습니다.
모르면 마법, 알면 기술
'머신러닝으로 해결할 수 있을 것 같은 문제가 무엇일까요?'가 질문이었다. 다른 분들의 답변을 보니, 평소에 만들어보고 싶다 생각했던 서비스도 있었고, 전혀 예상하지 못했던 분야에 머신러닝을 접목시킨 답변도 있었다. 집단 지성의 힘이란... 세상에는 정말 다양한 필요들이 존재한다.
직업편
직업의 시작
데이터 과학은 데이터를 만들고, 만들어진 데이터를 이용하는 일을 합니다.
데이터 공학은 데이터를 다루는 도구를 만들고, 도구를 관리하는 일을 합니다.
표
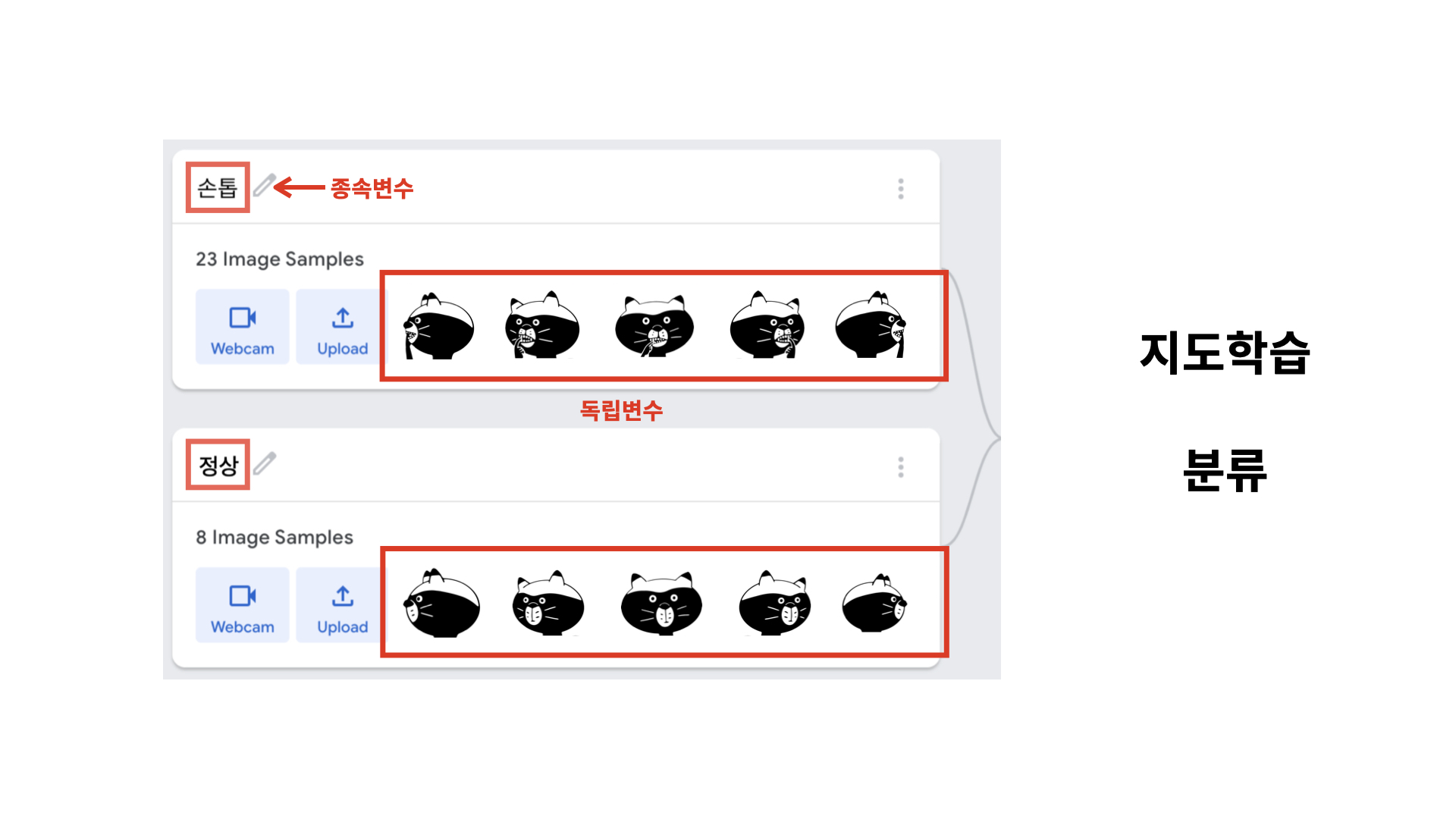
독립변수와 종속변수

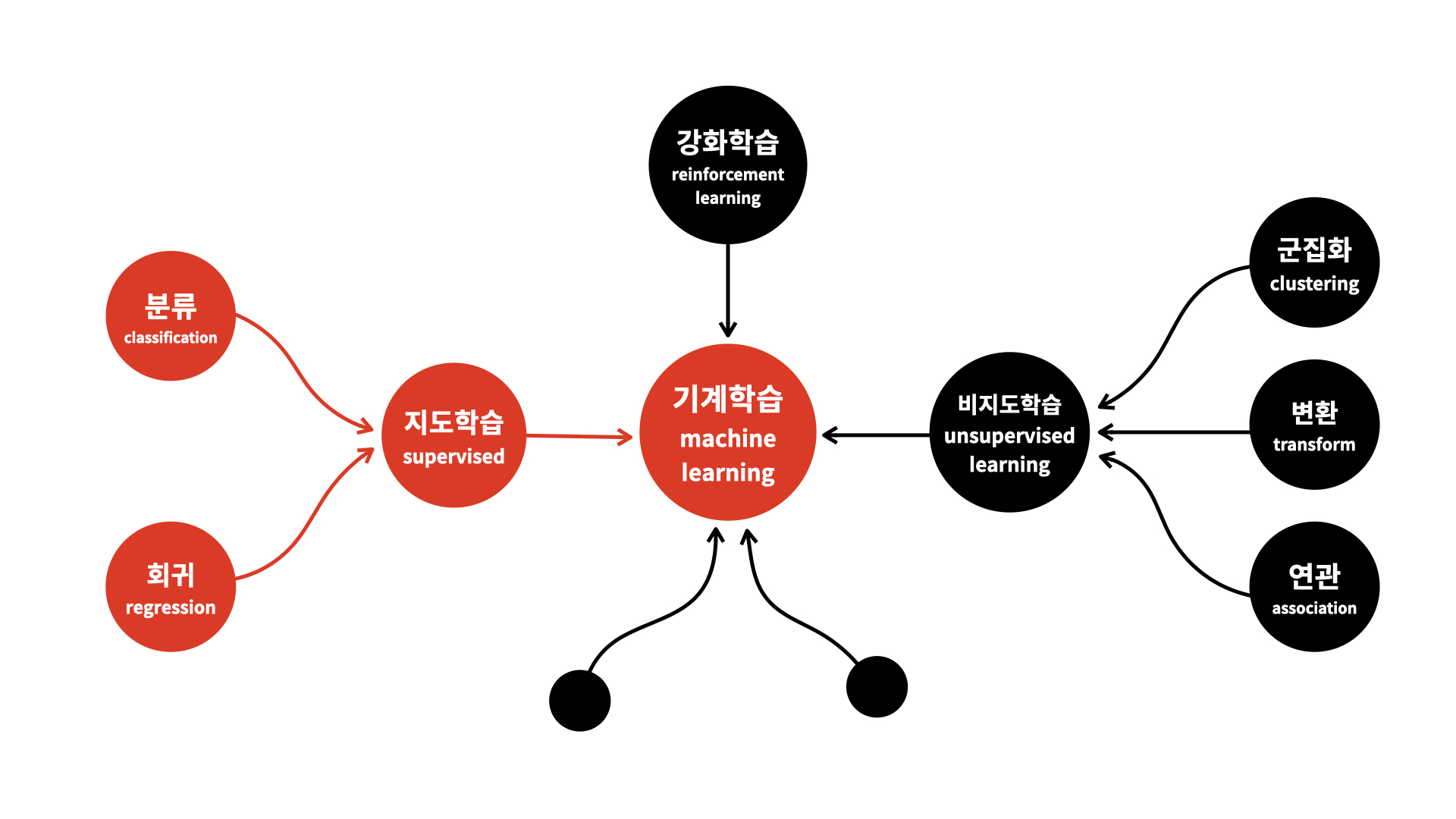
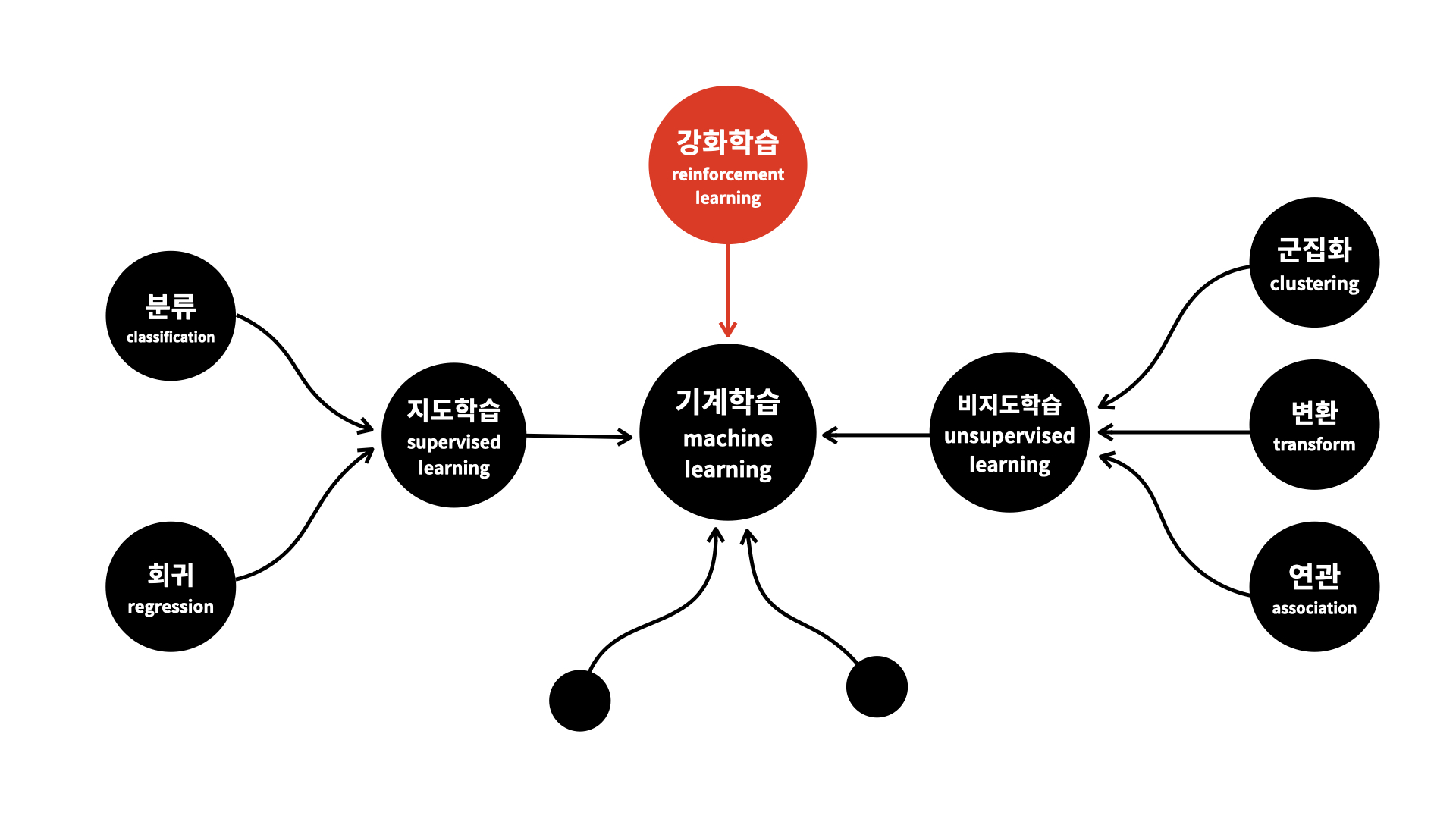
머신러닝의 분류
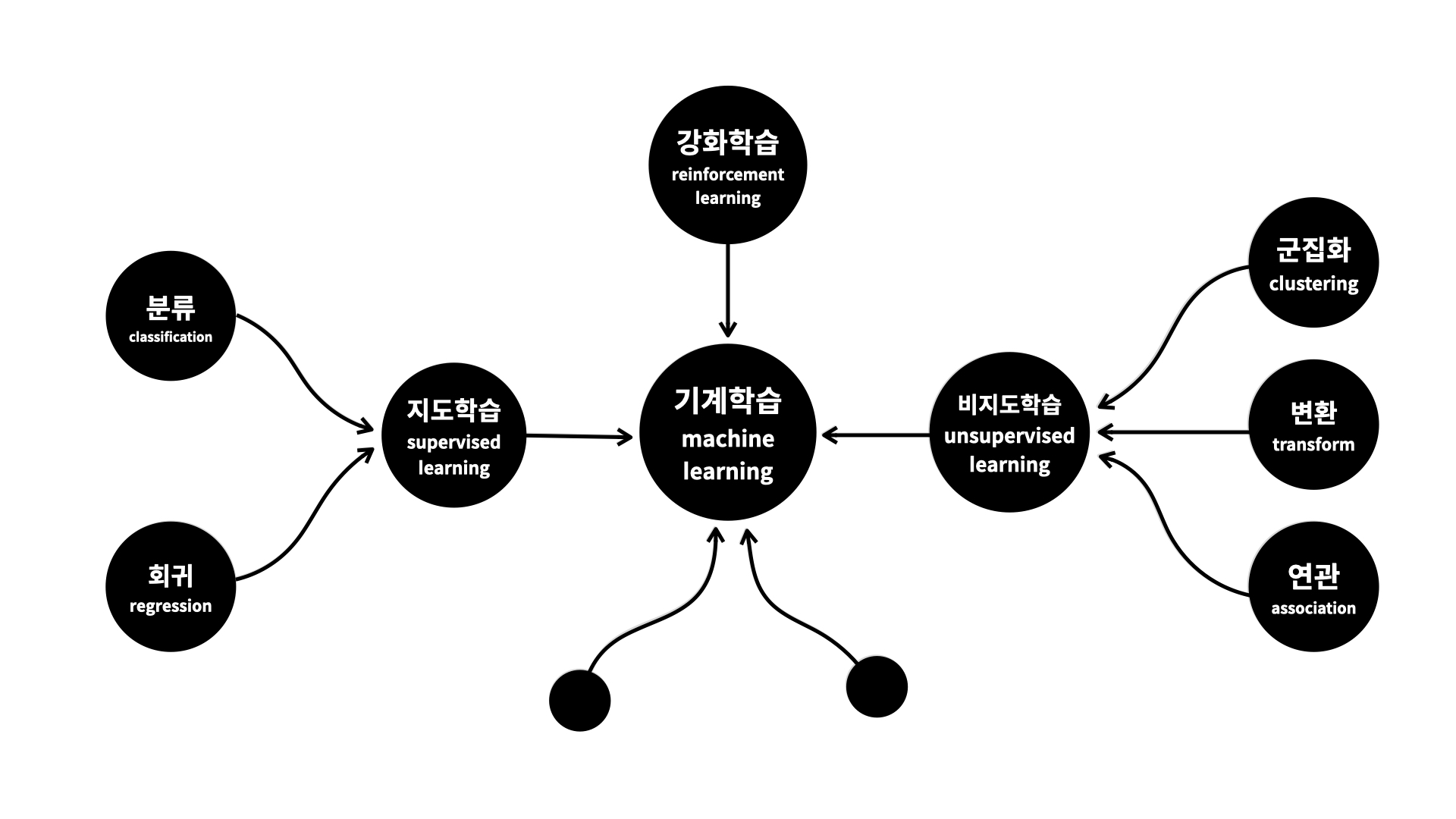
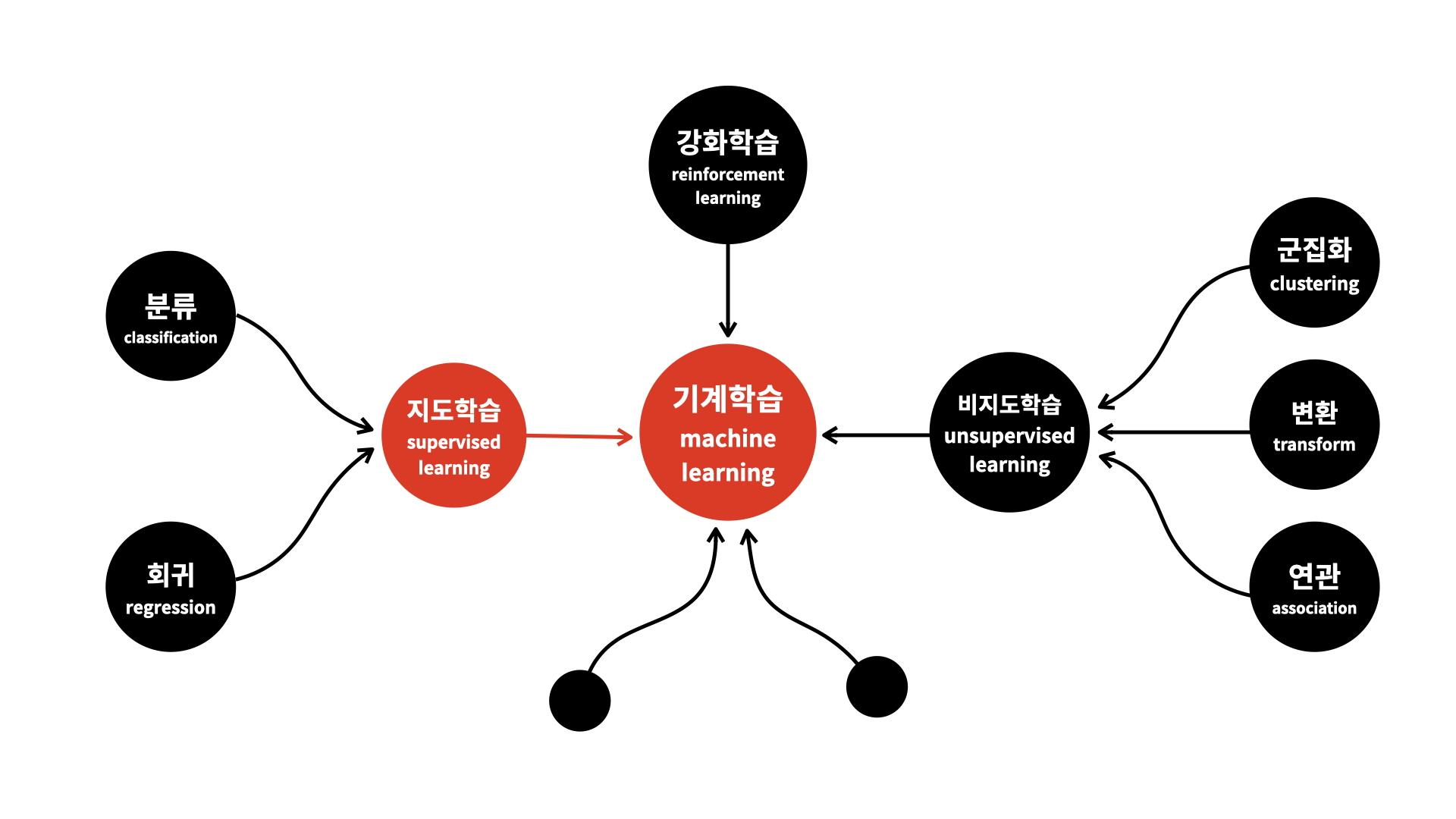
지도학습 Supervised Learning
머신러닝의 지도학습을 이용하기 위해서는 우선 충분히 많은 데이터를 수집해야 합니다. 데이터는 독립변수와 종속변수로 이루어져 있어야 합니다.
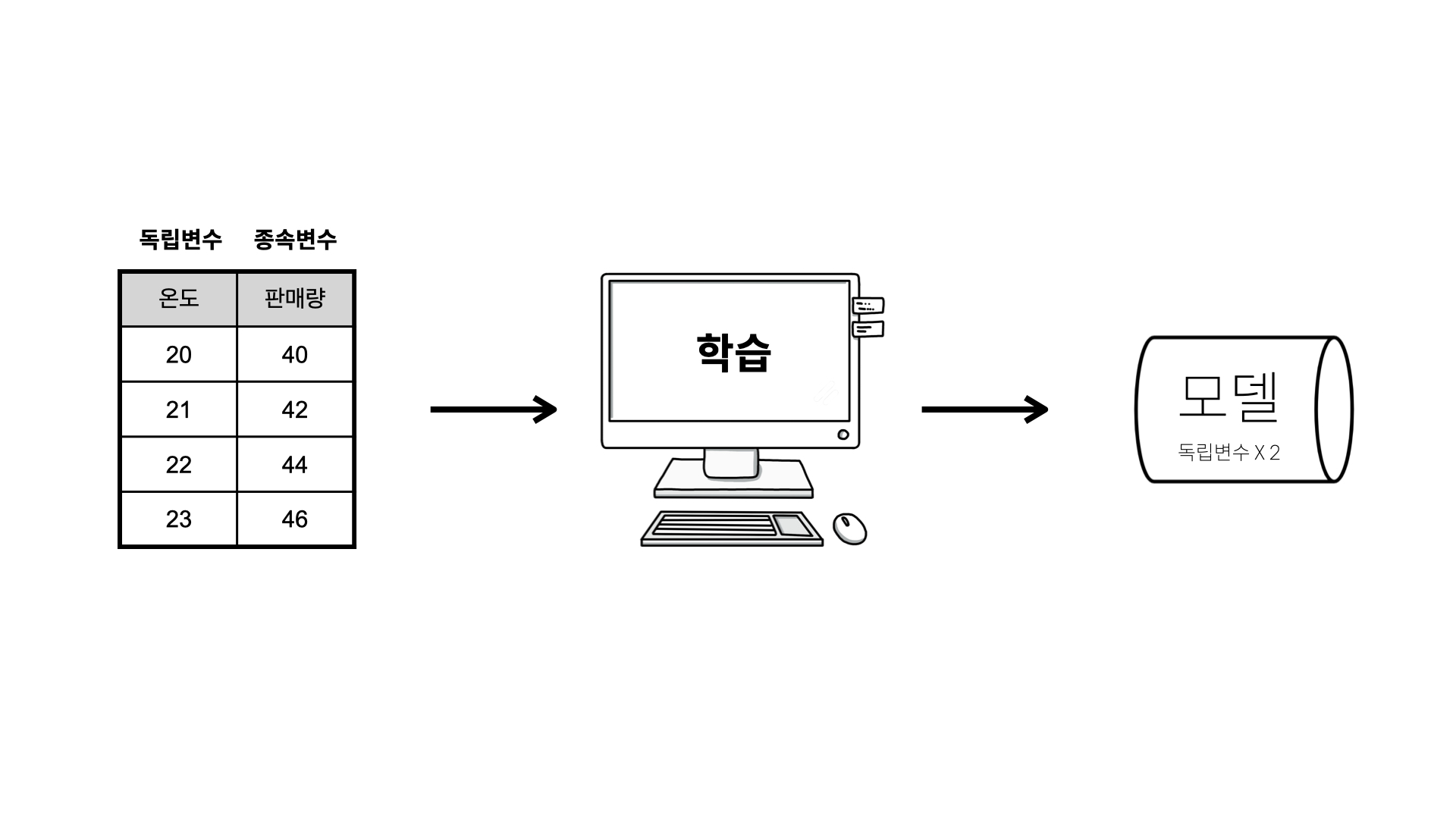
좋은 모델이 되려면 데이터가 많을수록, 정확할수록 좋습니다.
회귀 VS 분류
예측하고 싶은 종속변수가 숫자일 때, 보통 회귀라는 머신러닝의 방법을 사용합니다. (...) 앞으로 여러분이 어떤 문제를 만났는데 그 문제에서 추측하고 싶은 결과가 이름 혹은 문자라면, 지도학습의 분류로 해결하면 됩니다.

양적 데이터와 범주형 데이터
즉, 얼마나 큰지, 얼마나 많은지, 어느 정도인지를 의미하는 데이터라는 뜻에서 ‘양적(量的, Quantitative)'이라고 합니다. 또 산업에서는 ‘이름'이라는 표현 대신에 ‘범주(範疇, Categorical)'라는 말을 씁니다.
(...)
종속변수가 양적 데이터라면 회귀를 사용하면 됩니다.
종속변수가 범주형 데이터라면 분류를 사용하면 됩니다.
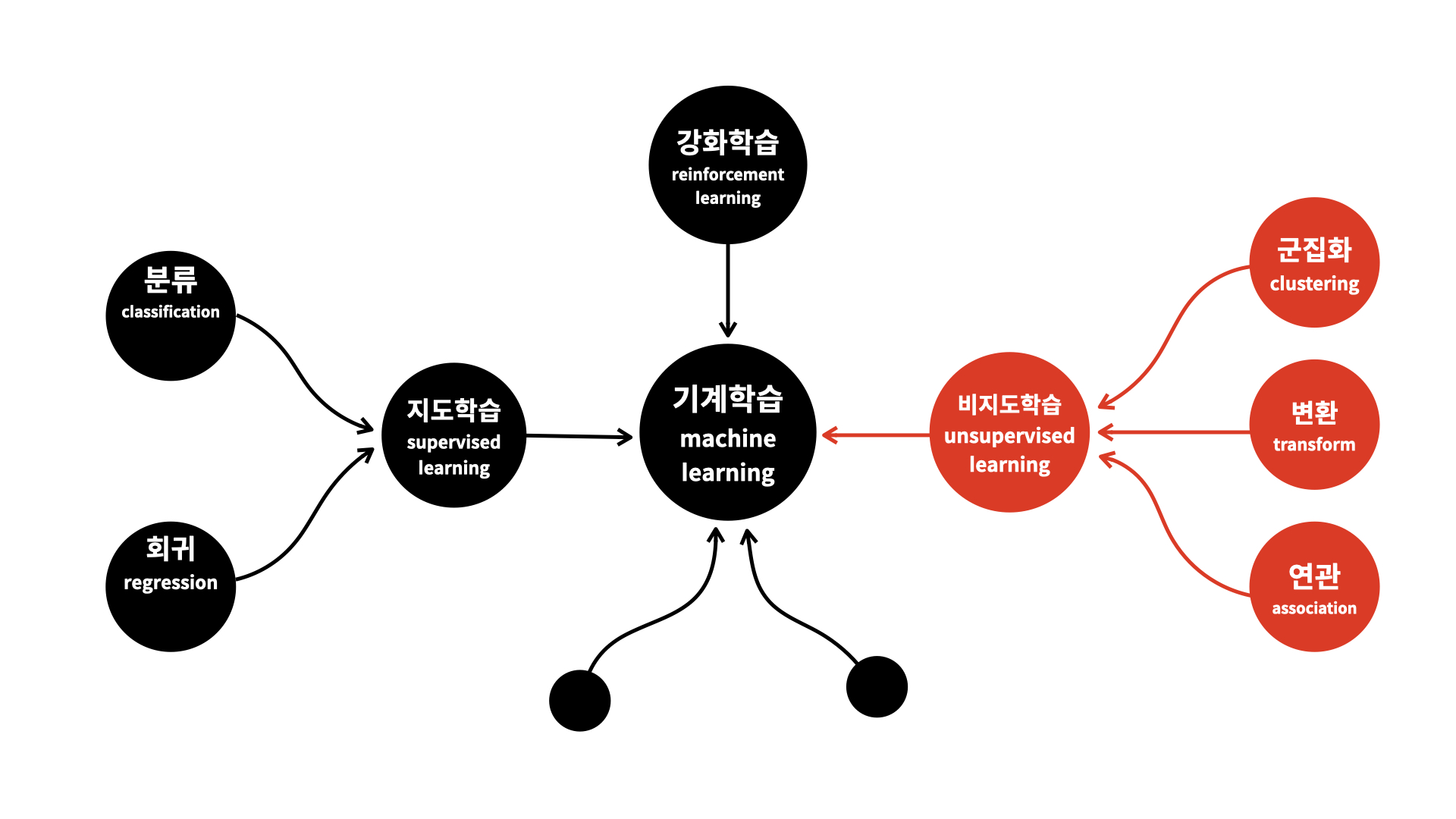
비지도 학습
변환
강의에서 까치밥으로 남겨두었던 내용. 정의를 찾아보니 '데이터를 새롭게 표현하여 사람이나 다른 머신러닝 알고리즘이 원래 데이터보다 쉽게 해석할 수 있도록 만드는 알고리즘'이라고 나온다. 변환 과정 중 데이터를 구성하는 단위나 성분을 찾기도 하는데, 대표적인 예로는 많은 텍스트 문서에서 주제를 추출하는 것이라고 한다.
군집화
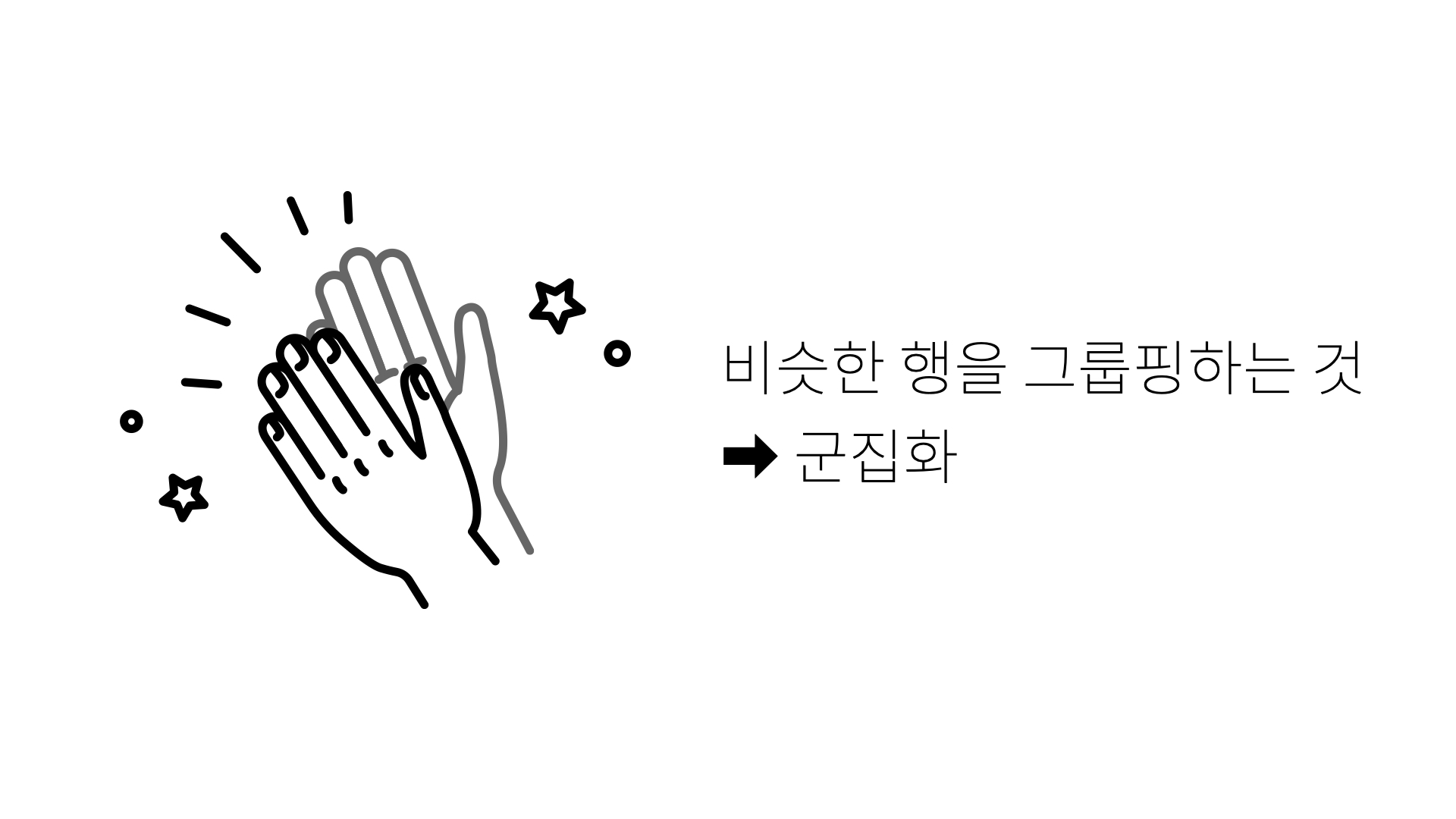
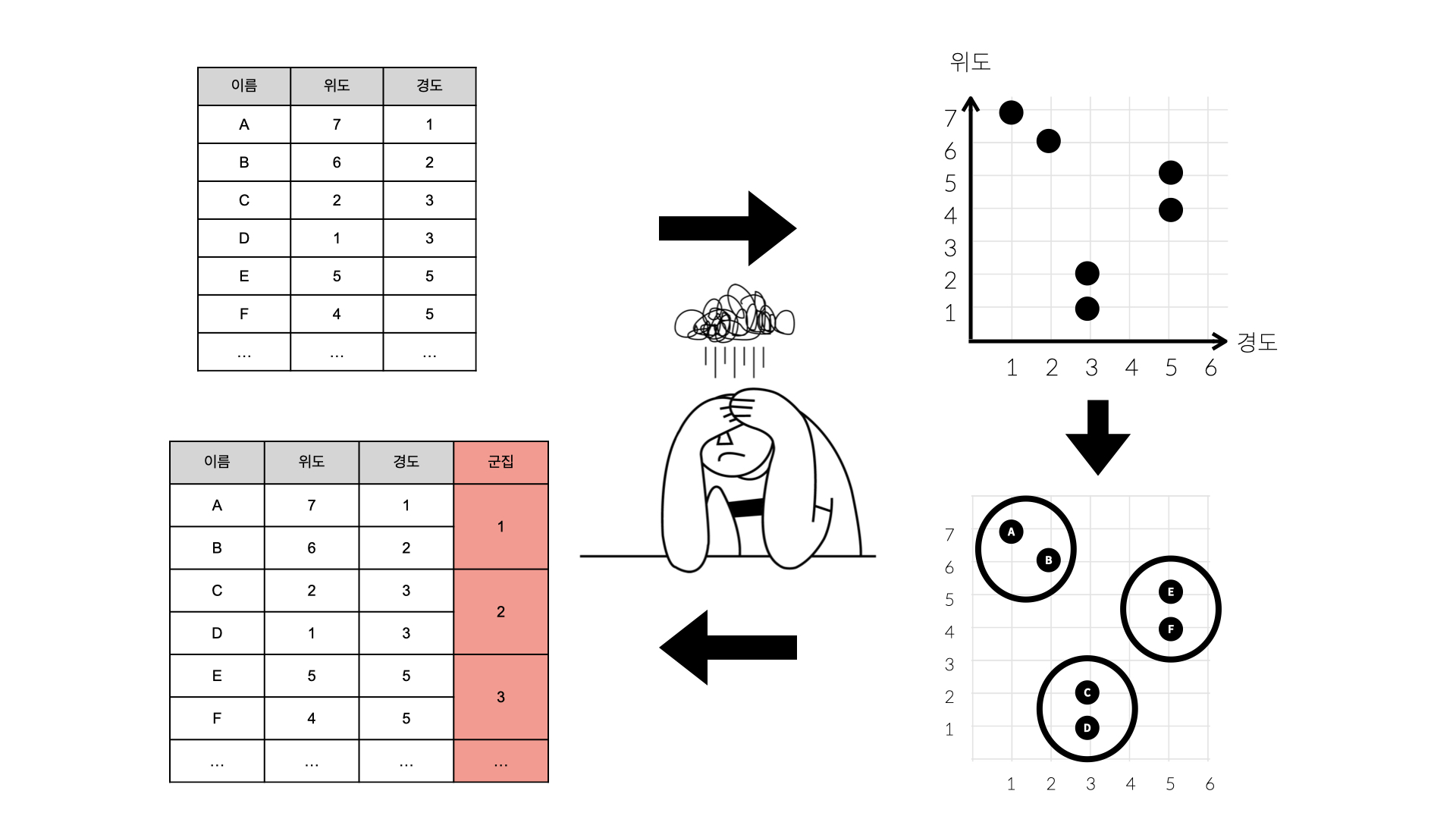
어떤 대상들을 구분해서 그룹을 만드는 것이 군집화라면,
분류는 어떤 대상이 어떤 그룹에 속하는지를 판단하는 것
연관 규칙 학습
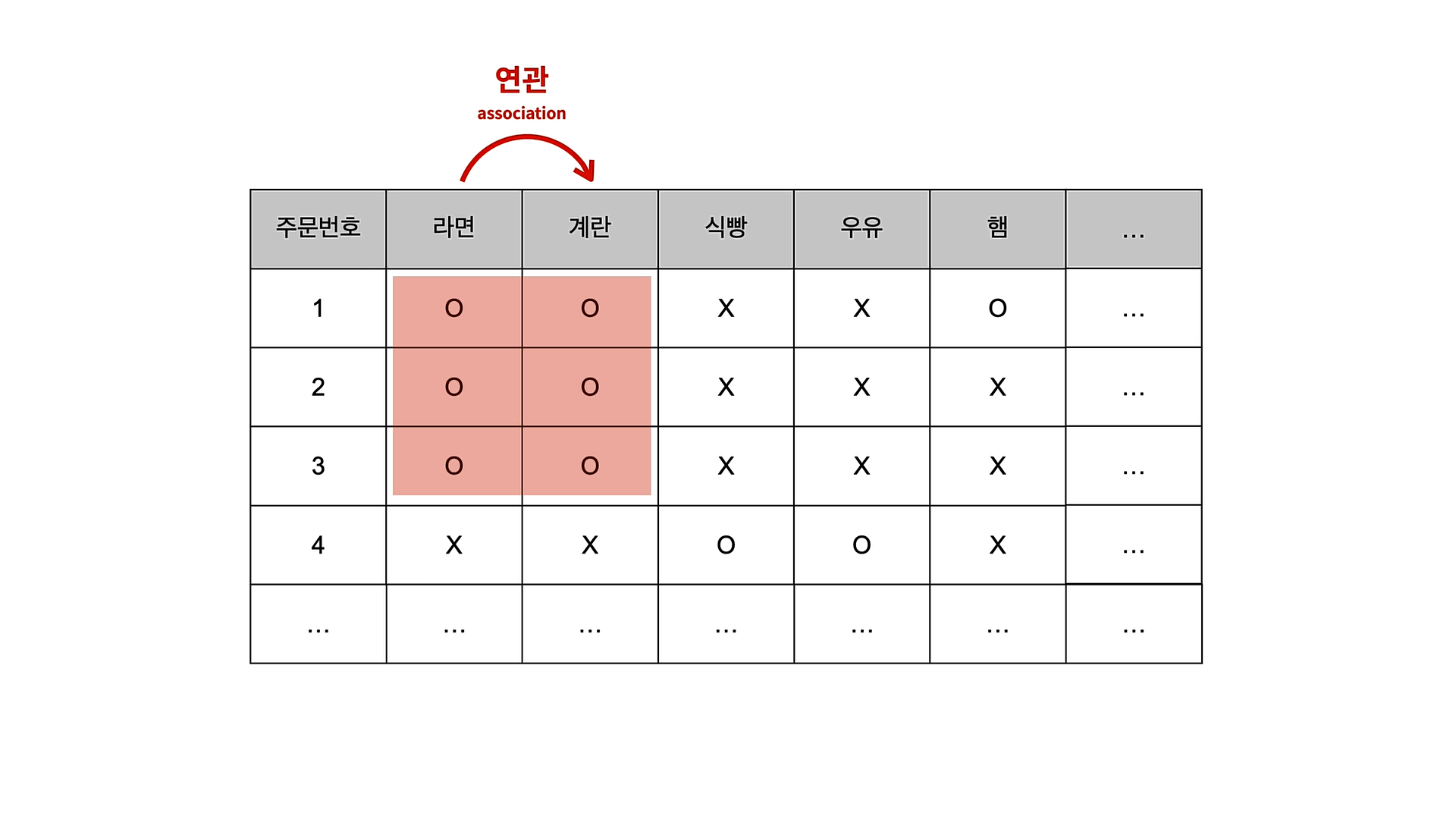
연관규칙학습은 서로 연관된 특징을 찾아내는 것입니다.
일명 장바구니 분석이라고 불립니다.
(...)
쇼핑 추천, 음악 추천, 영화 추천, 검색어 추천, 동영상 추천…..
추천이 이름 뒤에 붙은 것들은 거의 다 연관규칙을 이용한 것이라고 보면 됩니다.
군집화와 연관 규칙 비교
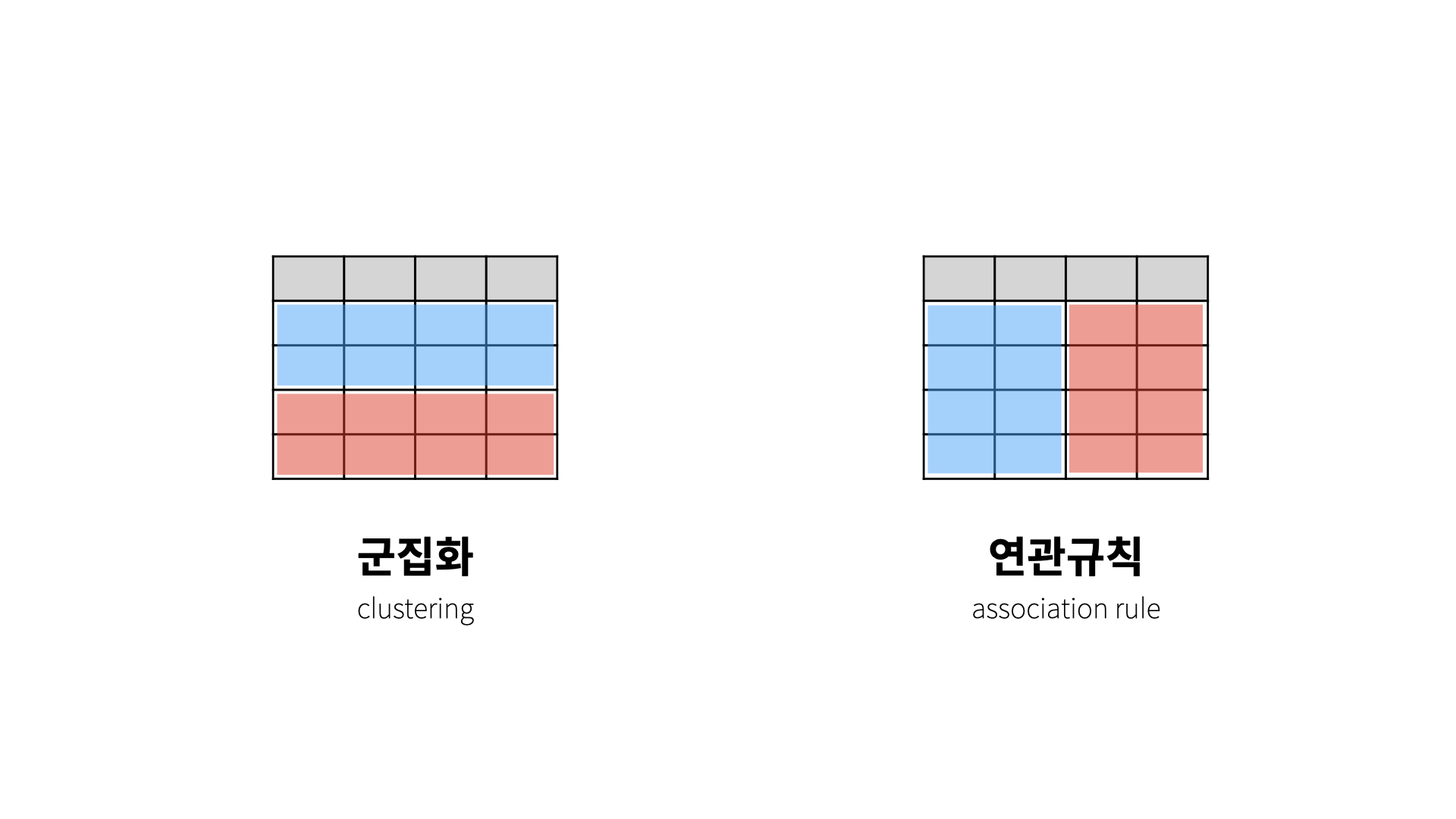
관측치(행)를 그룹핑 해주는 것 → 군집화
특성(열)을 그룹핑 해주는 것 → 연관규칙
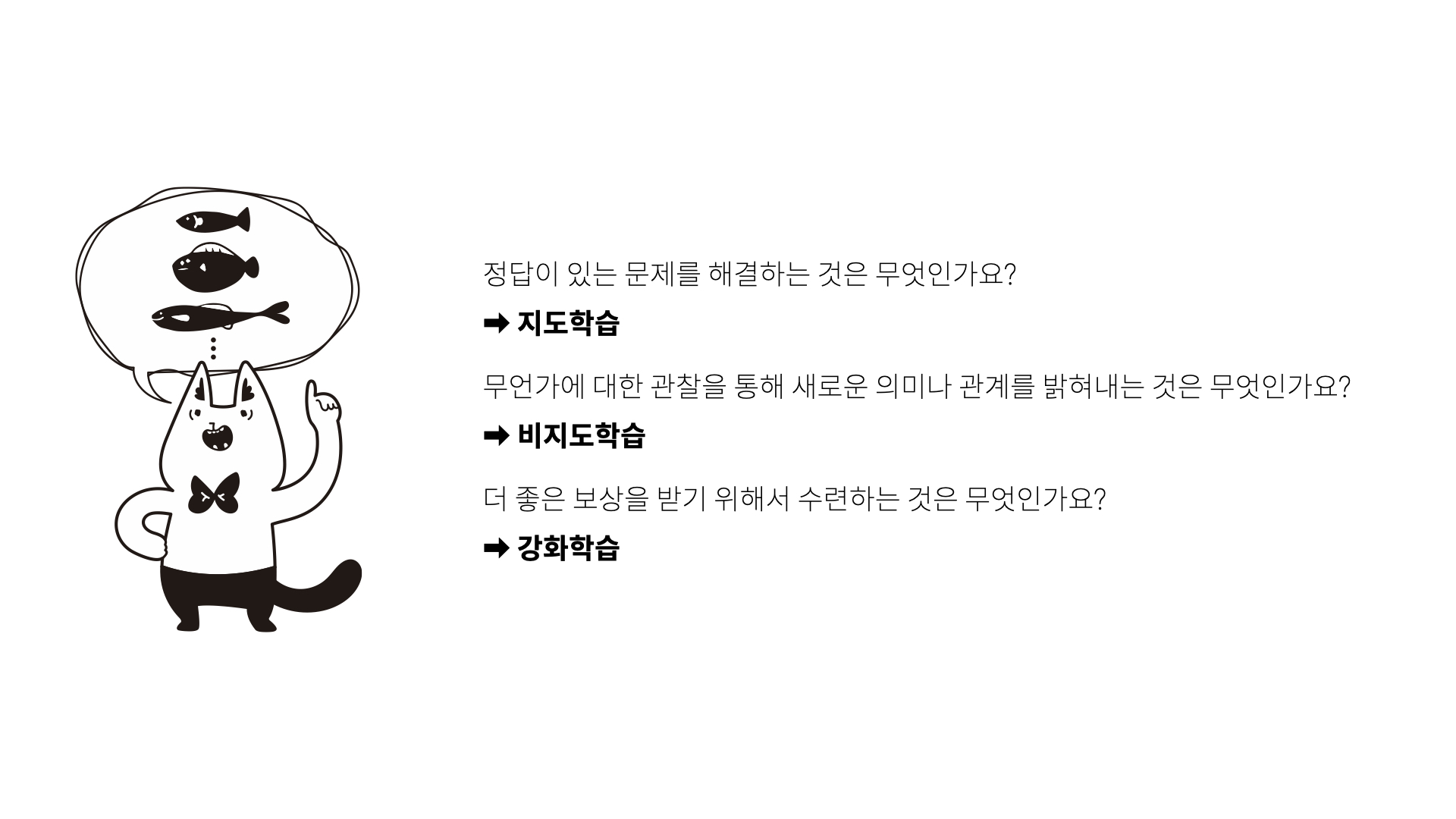
비지도 학습과 지도 학습의 차이점

강화학습

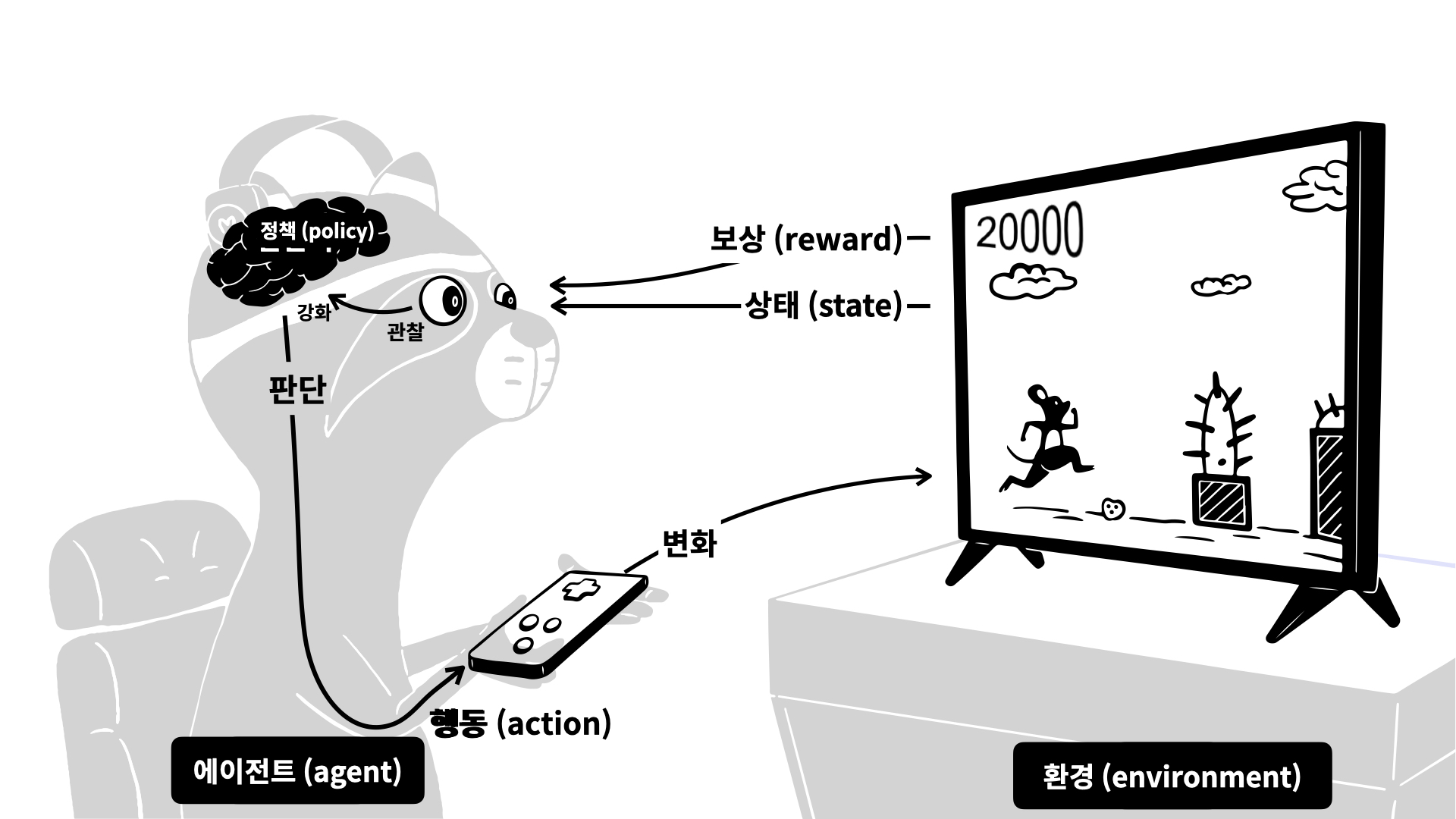
강화학습에서는 더 많은 보상을 받을 수 있는
정책을 만드는 것이 핵심입니다.
강화학습 강의를 다 듣고 나서는, 하단의 동영상 시청을 꼭 추천한다. 강화학습을 적용한 예제 동영상 링크인데, 컴퓨터를 학습시키는 과정을 볼 수 있어 신기하고 재밌다.
