
[※] 이번 chapter에서는 지금까지 여러 차례 언급했던 각 device 및 HW를 어떻게 제어할 수 있는지에 대해 배워봅시다.
1. Device control
[※] 작은 것부터 큰 것까지 순서대로 register → memory → memory controller —> LCD(peripheral device)를 제어하는 방법에 대해 알아봅시다.
Device는 MCU 외부에 달려있는 IP를 의미하며, 대략 아래와 같은 구성과 흐름으로 이뤄진다.
- CS핀 (Chip select) : 이 device를 사용하겠다고 활성화시키는 역할을 하는 핀으로 CE(Chip Enable)핀이라고 표기되기도 한다.
CS/로 표기되는데, 슬래시는 ‘low active’라는 뜻이다. 따라서 이 device를 사용할 때는0을 입력해야 한다. - Data핀 : 양방향 핀으로 명령어 또는 데이터를 주고받는 용도로 사용하는 핀이다. 여러 개의 핀으로 구성될수도 있고, I2C/ SPI 등으로 한두가닥의 bus로 구현될 수도 있다.
- CS를 low로 만들어서 ‘널 쓸거야’ 라고 알려준다.
- Data핀으로 slave에게 command sequence를 보내서 명령한다.
- Data핀으로 device는 제대로 수신했고 ready 상태임을 master에게 알려준다.
- Data핀으로 데이터를 쓰거나 읽는다.
- CE를 high로 만들어서 사용을 종료한다.
1.1. Register
레지스터 설정은 1) 레지스터의 주소에 접근, 2) 값을 쓰거나 읽음 2가지로 구성돼있다.
- SW적으로는 굉장히 간단하지만, 내부 과정에는 복잡한 HW 과정이 포함돼있다.
- SW 개발자 입장에서는 내부 latch 제어 과정까지는 자세히 알지 못해도 괜찮다.
- 하지만, 주의할 점은 레지스터는 부분 접근이 불가하다는 점이다.
- 예를 들어,
0x12345678에 있는 32-bit 레지스터 A가 있다고 가정하자. - A의 12번째 bit인 A[11]에 접근하기 위해 1-byte 뒤인
0x12345678 + 0x1에 접근해서는 안 된다.
- 예를 들어,
- 왜냐하면, ‘memory mapped I/O’라는 개념에 의해 레지스터든, 메모리든, 외부 peripheral이든 모두 메모리에 접근하듯 align된 주소를 통해 접근 및 제어가 가능하기 때문이다. Memory mapped I/O란, 레지스터와 외부 I/O controller 등을 특정하는 주소를 메모리의 일부 영역에 할당해서 별다른 조치를 취하지 않고도 메모리를 제어하듯 레지스터와 외부 장치를 제어하는 기능을 말한다. 따라서 레지스터, 메모리, I/O peripheral 모두 특정 address에 접근하는 것으로 제어할 수 있다.
1.2. Memory & Memory controller
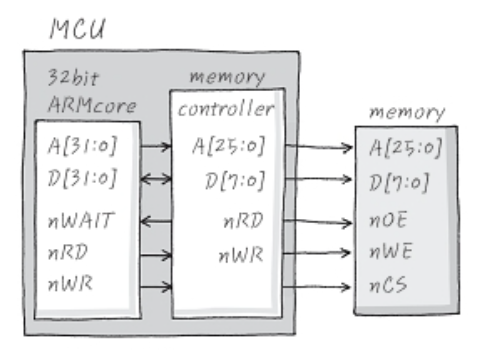
- ARM core와 memory 사이에는 양방향 데이터 흐름을 제어하는 controller가 있다.
- 메모리도 위에서 배운 device 동작과정과 거의 동일한 과정을 거쳐서 제어할 수 있다.
- CS를 low로 만들어 enable 한다.
- OE(Output Enable)을 low(read) 또는 high(write)로 만든다.
- Address line에 읽거나 쓰기를 원하는 주소를 지정한다.
- ([※] 보통 여기에 ALE (Address Latch Enable) 이라는 핀이 있어서, OE와 address가 준비되면 권총 트리거를 당겨서 쏘듯 slave에게 정보를 보내는 역할을 하는 핀이 추가로 있습니다.)
- Data line에 read할 데이터가 뜨거나, write할 데이터를 보낸다.
- CS를 high로 만들어 종료한다.
- 위 그림의 메모리는 address line이 26개이므로 2^24 == 64MB이고 data line은 8개이므로 주소당 1-byte를 저장할 수 있는 메모리다.
- 하지만, ARM core는 address line은 32개, data line도 32개를 가지고 있기 때문에 이런 메모리를 사용하기 위해서는 address line을 24개로, data line은 8개로 바꿔주는 회로가 필요하다.
- 바로 이 역할을 memory controller가 해준다.
- Memory controller는 ARM core의 address line의 LSB 24-bit만 사용하고, data line의 LSB 8-bit만 사용해서 메모리에 접근할 수 있도록 도와준다.
- 만일 메모리를 하나 더 추가하거나 기존 메모리를 변경해서 128MB 구성이 된다면, controller 속의 bus sizer 레지스터를 제어해서 address line의 bit를 1개만 더 사용하도록 만들면 된다.
1.3. LCD
- 지금까지 배운 내용을 토대로 LCD 인터페이스를 제어하는 방법에 응용해보자.
- 어떤 MCP의 datasheet 속 memory map을 확인해보니 address
0x2000_0000부터 3MB 크기가LCD_CS_N이라는 이름으로 선언돼있었다._N이라는 접미사가 붙은 것으로 보아 이 device의 CS핀은 low active임을 예측할 수 있다.- 3MB이므로
0x2000_0000 ~ 0x202F_FFFF영역이 LCD를 위한 영역임을 알 수 있다.
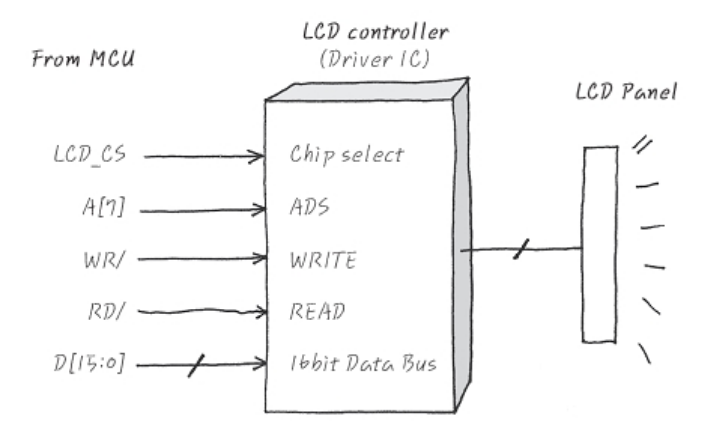
- 이제 datasheet를 넘겨서 LCD controller에 대한 회로를 설명하는 부분으로 넘어가보자.
- 이 controller는 특이하게도 address line의 7번 bit를 통해 command/ data 여부를 결정한다.
- CS와 WD 그리고 RD는 모두 low active이고, 16개의 data line을 주고받는다.
- 위 정보들을 습득했으면 이제 SW개발자는 LCD를 제어할 수 있는 최소한의 정보를 얻은 것이다.
; Command Issue
LDR R0, #0x20000080 ; A[7] = HIGH
LDR R1, #0xABCD ; 명령을 보냄
STR R1, [R0]
; Data Issue
; Command Issue
LDR R0, #0x20000000 ; A[7] = LOW
LDR R1, #0x1234 ; 데이터를 보냄
STR R1, [R0]- 어셈블리로 작성하면 위와 같다.
- Address line의 7번 bit를 통해 command를 보낼지, data를 보낼지 결정한다.
- 위 어셈블리를 C언어로 작성하면 아래와 같다. ([※] #define 문 MACRO 테크닉은 3.2절에서 다룹니다.)
#define Main_LCD_Write_cmd (cmd) (*(volatile word *)(0x200000080) = cmd
#define Main_LCD_Write_data (data) (*(volatile word *)(0x200000000) = data
Main_LCD_Write_cmd (0xABCD);
Main_LCD_Write_data (0x1234);2. HW control
2.1. PLL(Phase Locked Loop)
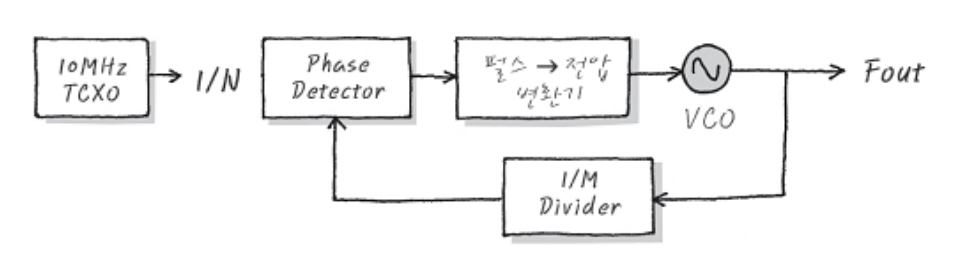
- 앞서 우리는 reset handler 및 bootloader가 하는 일 중 PLL setting이 있음을 배웠다.
- PLL(Phase Locked Loop)는 feedback을 통해 전압을 보정하며 일정한 주파수를 생성해주는 회로를 말한다.
- VCO(Voltage Controlled Oscillator)는 인가되는 전압에 따라 주파수를 생성하는 HW다.
- 10MHz 주파수를 입력하면 펄스-전압 변환기와 VCO를 거쳐서 증폭된 주파수
F_out이 출력된다. 하지만, 증폭된 주파수다보니 외부 환경(온도, 습도, 회로 길이 등)에 취약하다는 단점이 있다.- 예를 들어, 100MHz로 증폭된
F_out을 기대했는데 99MHz 또는 101MHz가 나온다면 시스템의 안정성에 악영향을 끼치게 된다.
- 예를 들어, 100MHz로 증폭된
- 따라서, 증폭된 출력신호
F_out을 1/M divider를 이용해 다시 입력 주파수TCXO수준으로 다운샘플링 한 뒤 phase detector를 통해TCXO와 비교해 VCO에 입력되는 전압을 수정한다. - 이런 feedback 과정을 통해 보정하며 일정한 주파수를 생성하게 된다.
- 이때 ‘증폭’과 ‘다운샘플링’ 이라는 단어로부터 유추할 수 있다시피, M/N:D Counter를 이용하면 입력 주파수를 M배 증폭, N배 다운샘플링해서 원하는 출력값을 만들 수 있다. D는 duty cycle을 의미하며, clock의 high/ low 비율을 의미한다. D가 크면 high일 때가 길어지고 작아지면 짧아진다.
- 정수 N과 M 그리고 D는 CPU 내부의 clock controller 레지스터를 설정해 변경할 수 있는데, 적당한 값을 찾는것도 임베디드 SW 개발자의 몫이다.
2.2. GPIO(Tristate buffer)
- GPIO(General Perpose I/O) pin들은 사용자가 원하는 대로 I/O 용도로 사용할 수 있는 핀을 의미한다.
- ARM core가 탑재된 MCU 입장에서 GPIO는 AMBA bus에 연결된 peripheral이며 memory mapped I/O에 의해 GPIO register도 특정 주소를 통해 control 가능하다.
- 우선 CPU는 GPIO를 사용하기 위해 GPIO 레지스터의 3가지를 설정해야 한다.
- GPIO pin의 mode 설정: GPIO로 쓸 것인지, 특별한 다른 용도로 사용할 것인지 결정.
- GPIO pin의 방향 설정: Input으로 쓸 것인지, output으로 쓸 것인지 결정.
- GPIO pin에게 command 입력: Read 또는 write 명령을 입력.
- 위 3가지를 설정하면 GPIO를 사용할 준비는 완료된 것이다.
- GPIO 핀 자체는 HW적으로 tristate buffer(3상버퍼)로 구현되는데,
0, 1, Z3가지 상태를 가진다.- Tristate buffer는 input, output 말고도 switch라는 입력을 받는다.
- Switch가
0이면 마치 buffer 내부 회로가 막힌 것처럼 input과 output은 회로적으로 open이 돼 연관성이 사라진다. - Switch가
1이면 일반 buffer처럼 입력값이 그대로 출력값으로 나온다.
- Tristate buffer로 구현되는 이유는 GPIO 핀이 input으로도, output으로도 사용되기 때문이다.
- 예를들어 output으로 사용된다고 생각해보자. MCU가 내보내려고 하는 데이터가 GPIO 핀의 input으로 들어와 그대로 output으로 출력돼야 하므로 switch는
1이어야 한다. - 이번엔 input으로 사용된다고 생각해보자. GPIO핀의 input으로 외부로부터 들어오는 신호를 읽어야 하는데, 회로가 연결돼있으면 output 쪽 값이 계속 input으로 읽혀질 것이므로 원하는 값을 읽지 못하는 문제가 발생한다.
- 따라서, switch를
0으로 만들어 input과 output을 회로적으로 연결을 끊어버려 외부 신호를 input으로 잘 받을 수 있도록 만든 것이다.
- 예를들어 output으로 사용된다고 생각해보자. MCU가 내보내려고 하는 데이터가 GPIO 핀의 input으로 들어와 그대로 output으로 출력돼야 하므로 switch는
- GPIO는 MCU에 따라 그리고 핀에 따라 pull-up/ pull-down을 설정해줘야 하는 경우도 있다.
- GPIO를 통해 외부로부터 interrupt를 걸어줄 수도 있다.
2.3. DMA(Direct Memory Access)
- DMA는 CPU 대신 데이터를 송수신하는 HW를 말하며 CPU time을 최적화하기 위한 용도로 사용한다.
- CPU는 DMA controller(DMAC)에게 source와 destination 그리고 전송할 바이트수만 알려주면 DMA가 알아서 데이터를 송수신하며 전송이 완료되면 CPU에게 interrupt를 걸어 알려주기 때문에 CPU는 그동안 전혀 신경쓸 필요가 없다.
- DMA는 두 가지 전송모드가 있다.
- Single address mode: BR(Bus Request), BG(Bus Grant)신호로 매 cycle마다 bus 사용권을 얻어서 1-byte를 전송한 뒤 사용권을 반환한다. 따라서 전송속도는 느리지만, CPU나 peripheral이 언제든지 arbiter에 의해 언제든지 bus 사용권을 휙득할 수 있다는 점에서 시스템 안정성은 높다.
- Burst address mode: Block transfer이라고도 불리며, CPU로부터 요청된 데이터 전송이 끝날 때까지 멈추지않고 계속해서 bus를 사용해서 전송한다. 따라서 전송속도는 빠르지만, 다른 IP들은 bus를 사용할 수 없어 CPU가 기다리는 경우가 생길 수도 있다.
- DMA는 조심해서 사용해야 한다. 왜냐하면, cache와 밀접한 연관이 있기 때문에 언제든지 cache invalid 또는 cache incoherence를 발생시킬 수 있기 때문이다. 이에 대해서는 바로 밑에서 조금 더 자세히 다뤄보자.
2.4. Cache
- Cache는 CPU 성능을 향상시키기 위해 temporal/ spartial locality에 따라 자주 사용할 가능성이 높은 데이터를 wait state가 0인 TCM 같은 비싼 메모리에 저장하는 것 또는 그런 메모리 자체를 가리킨다.
- Cache는 보통 cache controller + cache memory를 통칭하는 용어다.
- Cache 중에는 N-way associative mapping이라는 개념이 있다.
- 예를 들어 16KB cache memory가 있다고 가정하자.
- 2-way는 8KB씩 2개의 block으로 나눠서, 4-way는 4KB씩 4개, 8-way는 2KB씩 8개, 16-way는 1KB씩 16개의 block으로 나눠서 cache를 사용한다는 의미다.
- 이를 위해 index, offset, tag 등 용어가 쓰이는데 기초 CS의 OS에 잘 설명돼있으니 생략한다.
- Cache와 memory 사이의 일관성(coherence)을 유지하기 위해 대표적인 2가지 write policy가 있다.
- Write through: Cache가 갱신되면, memory도 똑같이 갱신해준다. 일관성을 아주 잘 유지해주지만, 어쨋든 메모리에 접근하기 때문에 cache를 사용하는 의미가 줄어든다는 단점이 있다.
- Write back: Cache에만 갱신하고, cache가 가득차 일부 block의 내용을 버려야 할 때 갱신표시(dirty bit)가 돼있는 block이라면 memory에 갱신해준다. 일관성을 다소 포기하고 성능을 얻었다고 생각하면 된다.
- Cache에 갱신된 내용을 메모리에 write하는 과정을 조금이나마 빠르게 하고자 마치 DMA처럼 데이터를 보관했다가 CPU 대신에 메모리에 전송하는 FIFO buffer를 도입했다.
- Write buffer: Write through에 대한 FIFO buffer.
- Write Back PA TAG RAM: Write back에 대한 FIFO buffer.
- Cache는 DMA와 함께 사용할 때 굉장히 조심해서 사용해야 한다. 왜냐하면, DMA가 메모리의 어느 주소에 어떻게 갱신하는지에 대해서는 cache가 알 수 없기 때문에 incoherence를 유발할 가능성이 있기 때문이다.
- 이를 해결하기 위해 대표적으로 cache invalidate + cache flush 또는 cache clean을 사용한다.
- Cache flush: 이름 그대로 incoherence가 발생했다고 가정하고 그냥 cache를 싹 비우는 방법이다.
- Cache clean: Dirty bit가 set 된 cache line 또는 block을 메모리에 갱신해준다.
- Cache가 가득차서 버려야 할 block을 선택하는 방법을 replacement policy라고 말한다.
- Replacement policy는 random, round-robin 등 여러가지 방법이 있다.
- Replacement policy는 CP15의 CR 레지스터의 14번 bit를 MCR, MRC 명령어로 바꿔서 설정할 수 있다.
2.5. MMU(Memory Management Unit)
- MMU는 가상주소(virtual address, VA)를 실제주소(physical address, PA)로 바꿔주는 HW다.
- MMU를 사용하면 다음과 같은 3가지 장점을 얻을 수 있다.
- 서로 다른 task/ program이 똑같은 주소를 사용해도 실행하는 데 전혀 상관없게 된다. (어차피 실제주소는 다르니까)
- 메모리상으로 실제로는 흩어져있는 메모리 영역(fragment)이 마치 이어져 연결돼있는 것처럼 사용할 수 있게 된다.
- 특정 메모리 영역에 특성을 부여할 수 있게 된다.
- Cache 가능 영역/ 불가능 영역
- Wrtie bufferable 영역/ non bufferable 영역
- Readonly 영역 등
- 특정 user 또는 domain만 접근 가능하도록 설정
- VA를 PA로 mapping하기 위해서는 변환 테이블이 있어야 하는데, 이를 MMU page table이라고 부른다.
- MMU page table은 TCM 또는 SDRAM에 저장되며 실제 주소는 TTB(Translation Table Base address) 레지스터에 기록된다.
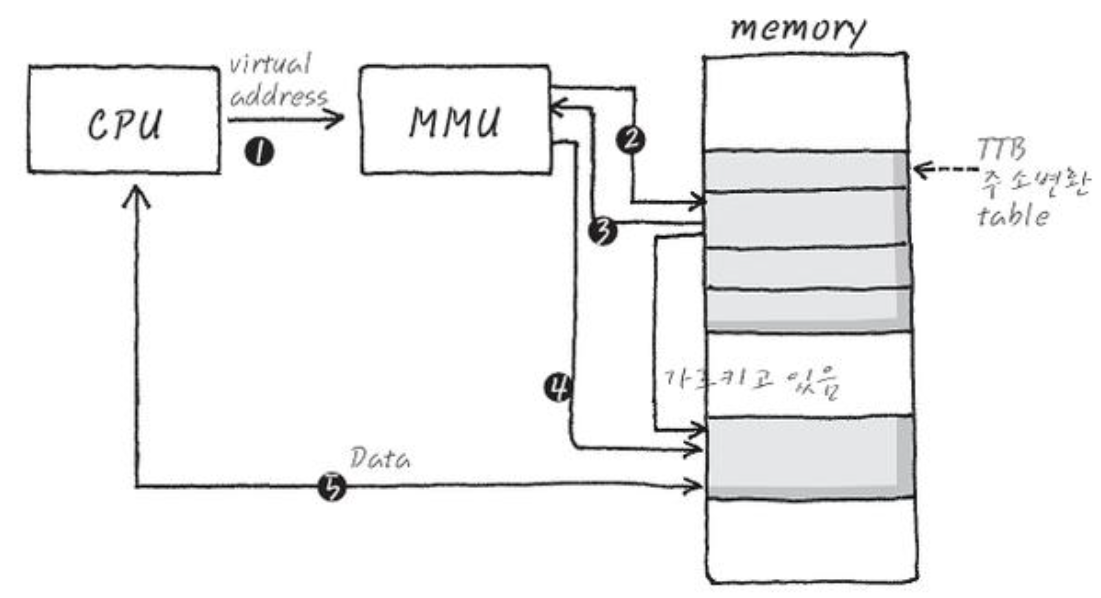
-
위는 MMU가 VA를 PA로 변환하는 과정을 간략하게 도식화한 그림이다.
- CPU가 접근하고 싶은 메모리의 주소(VA)를 발생시킨다.
- MMU는 TTB를 통해 page table을 탐색하며 대응하는 PA를 찾아 발생시킨다.
- 메모리는 해당 PA 속 데이터를 CPU에게 data bus로 전달한다.
-
ARM core는 32-bits 시스템이므로 address bus가 2^32 = 4GB를 나타낼 수 있다.
- 따라서 MMU page table도 4GB를 나타낼 수 있어야 한다. Table의 각 entry(line)은 1MB를 나타낼 수 있고 그러한 entry가 4,096개 있어서 총 4GB를 나타낼 수 있다.
- 한 개 entry는 32-bit 크기이고 4,096개 있으니 MMU page table의 기본 크기는 16KB다!
-
하지만, mapping하는 VA 단위가 1MB이면 굉장히 답답할 것이다. 따라서 ARM은 더 작은 단위로 나눌 수 있도록 아래와 같이 옵션을 나눠 분류해놨다.
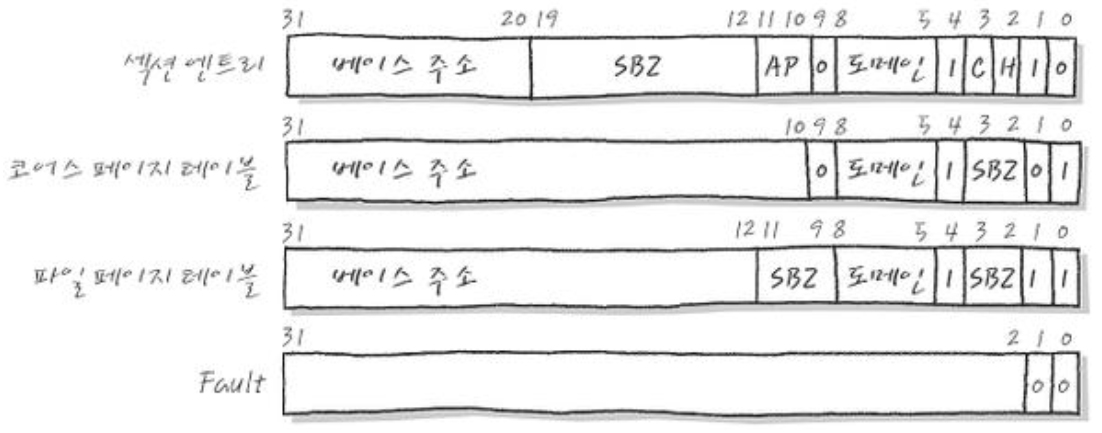
-
Section entry: 위에서 설명한 1MB 크기의 entry를 말한다. 베이스 주소 12-bits와 다른 곳의 8-bits를 합쳐서 PA를 mapping 한다. 이렇게 1MB 단위로 mapping 하는 table을 ‘Level 1 Page Table’이라고 부른다.
-
LSB 2-bits가
01또는11인 경우를 각각 coarse page table, file page table이라고 부르며 더 작은 단위를 세밀하게 mapping 하고 싶을 때 사용하는 level 2 page table이다. -
Level 2 Page Table
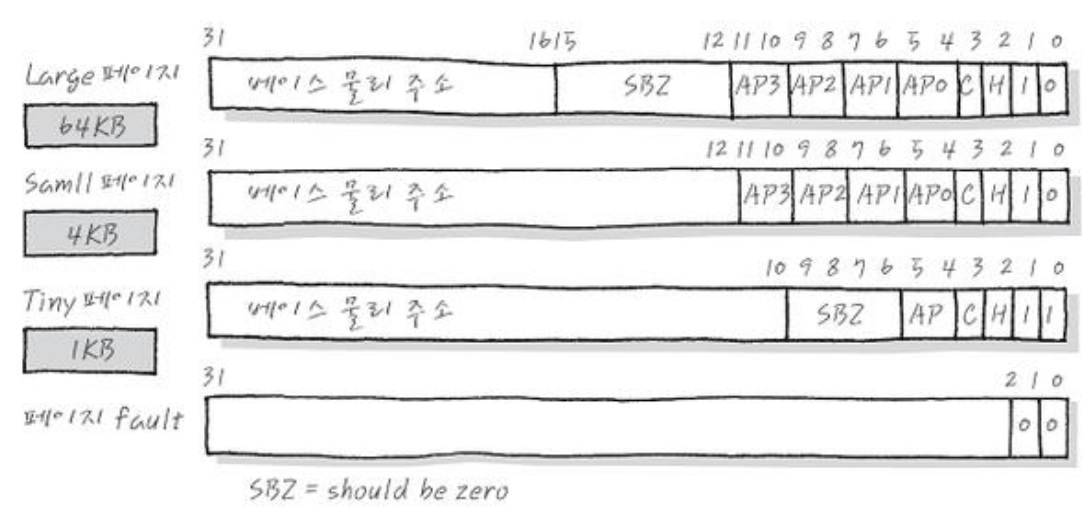
- Coarse page table: LSB 2-bits가
01이면 coarse page table로 이동하는데, 여기에는 256개의 entry가 있고 각 entry는 64KB를 가지는 Large page, 4KB를 가지는 Small page로 구성된다. - Fine page table: LSB 2-bits가
11이면 fine page table로 이동하며, 여기는 1,024개의 entry가 있고 각 entry는 large(64KB), small(4KB), 1KB를 가지는 tiny page로 구성된다.
- Coarse page table: LSB 2-bits가
-
-
위 내용을 정리해서 VA가 PA로 변환되는 과정을 전체적인 그림으로 보면 다음과 같다.
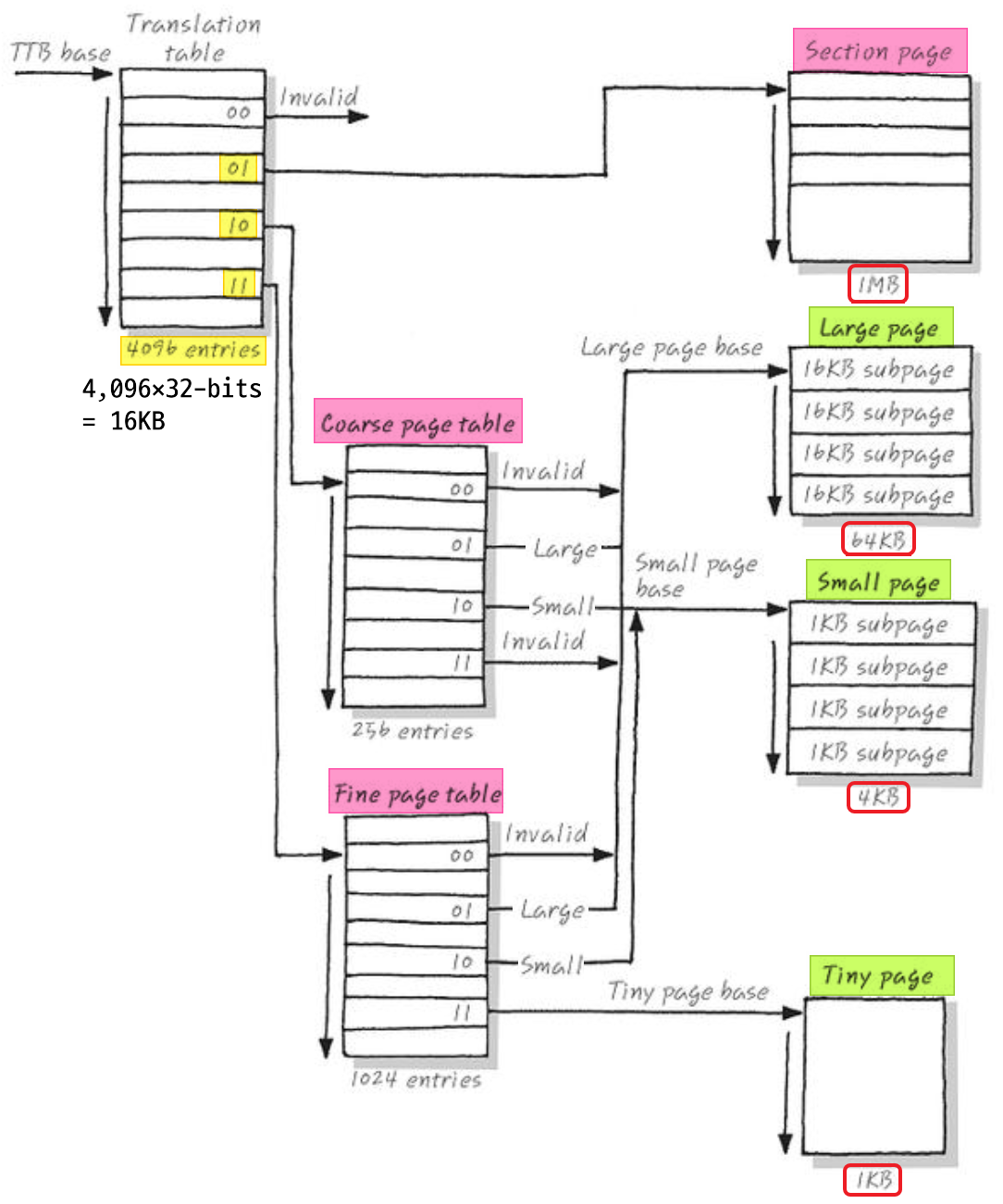
이제 예시를 보면서 MMU의 address mapping을 확실하게 이해해보자.
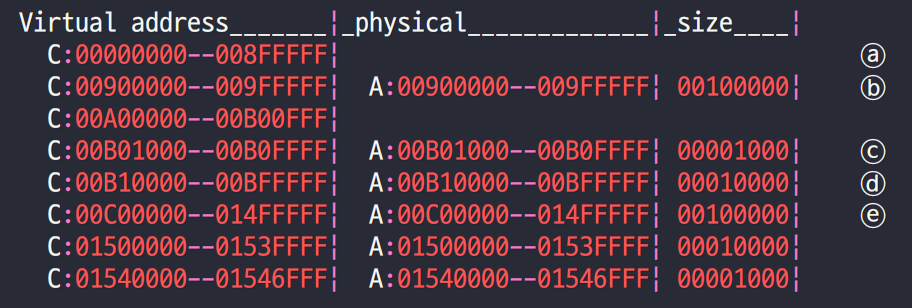
- TTB를 통해 MMU page table의 실제주소(
0x00A2_4000)를 알아냈고, 해당 영역을 덤프한 결과 위와 같은 결과를 얻을 수 있었다. - 두 번째 entry ⓑ를 보니 크기가
100000 = 16^5 = 1MB로 section entry인 level 1 page table임을 확인할 수 있다. - 위 결과는 개발자가 읽기 편하게끔 편의기능을 통해 깔끔하게 덤프된 결과이므로 실제
0x00A2_4000번지는 어떤 모습을 하고 있는지 덤프해서 확인해보자.
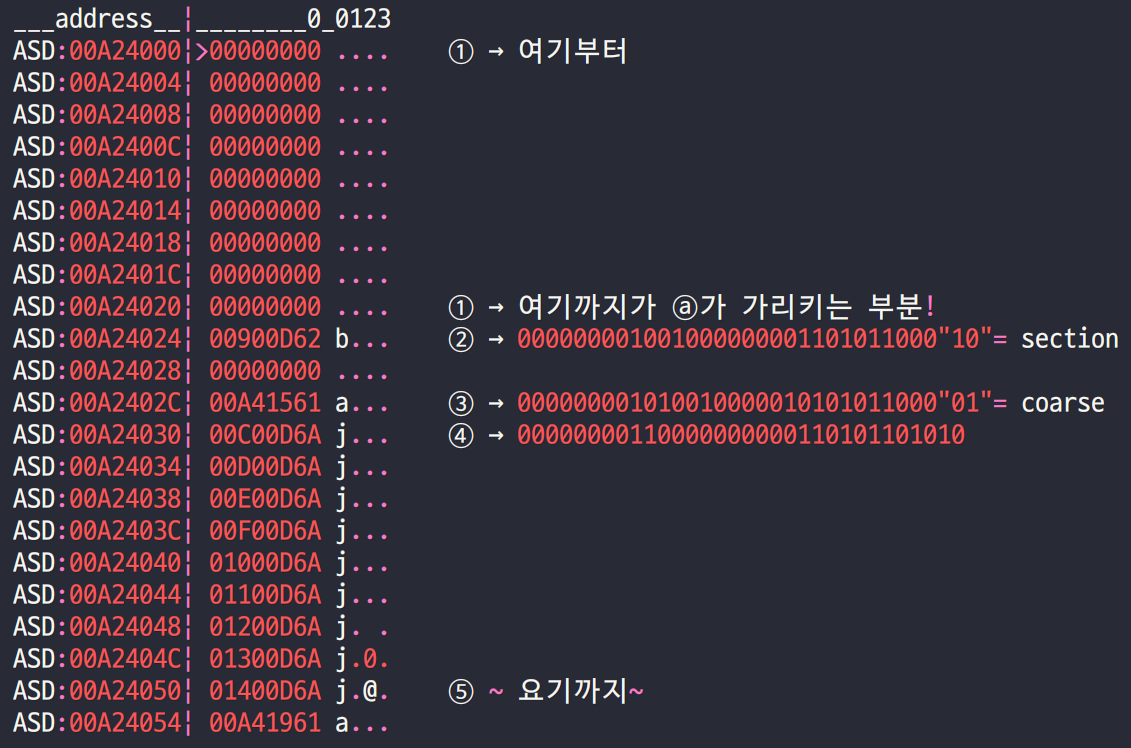
- 첫 entry인 ⓐ에서 9MB가 아무것도 mapping되지 않았었는데 실제로 ①을 보니 9칸이 0으로 초기화된 채로 있다. ([※] 사실 9칸이 아니라 8칸이어야 하는데 오타인 것 같네요.) 이렇게 아무것도 mapping 되지 않은 page를 fault page라고 부르며 CPU가 접근하려고 하면 abort가 발생한다.
- ②를 보니
0x0090_0D62로 2진수로 표현하면 위 사진과 같은데, LSB 2-bits가10으로 끝나는 것을 보니 section page를 의미하며 MSB 12-bits를 제외한 나머지 bits를 0으로 초기화 시킨 값이 PA의 base 주소가 된다.0000_0000_1001_0000_0000_0000_0000 = 0x900_000이므로 PA 9MB~10MB를 가리킬 것을 예상할 수 있다.- 실제로 ⓑ를 보니 해당 entry가 PA의
0x0090_0000 ~ 0x009F_FFFF에 매칭되는 것도 확인할 수 있다.
- ③을 보니
0x00A4_1561로 2진수로 표현하면 위 사진과 같은데, LSB 2-bits가01로 끝나므로 coarse page table을 의미한다. MSB 22-bits를 제외한 나머지를 0으로 초기화 시킨 값이 coarse page table의 base 주소가 된다.- Base 주소를 다시 16진수로 만들면
0x00A4_1400을 가리키므로 이제 그 주소를 덤프하면 level 2 page table을 확인할 수 있다.
- Base 주소를 다시 16진수로 만들면

- Level 2 Page Table의 내용물을 확인할 수 있다.
- ⑵를 확인하니 끝이
10으로 끝나는 것을 보아 4KB짜리 small page임을 알 수 있다.- LSB 12-bits를 0으로 날려버린 뒤 16진수로 표현하면
0x00B0_1000이므로 - 그 주소로부터 4KB인
0x00B0_1000~0x00B0_FFFF를 mapping하고 있음을 알 수 있다. - ⓒ를 보니 정말로 4KB만큼 영역을 차지하고 있음을 나타내고 있다.
- LSB 12-bits를 0으로 날려버린 뒤 16진수로 표현하면
- ⑶은 끝이
01로 끝나는 64KB짜리 large page다.- LSB 16-bits를 0으로 날려버린 뒤 16진수로 표현하면
0x00B1_0000이다. - 즉 방금 small page의 영역에 이어서 mapping 되고 있는 것이다.
- 그 주소로부터 64KB인
0x00B1_0000~0xBF_FFFF를 차지하고 있음을 ⓓ를 통해 재확인 할 수 있다.
- LSB 16-bits를 0으로 날려버린 뒤 16진수로 표현하면
지금까지 MMU가 어떻게 VA를 PA로 mapping 시키는지 알아봤으니, 이제 나머지를 알아보자.

- MMU page table 전체 내용을 덤프하면 permission 및 access 속성에 대한 정보도 확인할 수 있다.
- ⓐ와 ⓑ는 모두 크기가 1MB인 section entry다. (위에 ①, ②, ③, ④가 적힌 사진에서 ①은 ⓐ를, ④는 ⓑ를 가리킨다.)

- ⓐ는
0000_0000_1001_0000_0000_1101_0110_0010이었는데, 하나하나 자세히 살펴보자.- Base address는 MSB 12-bits로
0x0090_0000을 가리키고 있음을 위에서 확인했다. - SBZ는 should be zero의 줄임말로 베이스 주소에 이어 8-bits가 0으로 돼있음을 확인할 수 있다.
- AP(Access Permission)는
11로 ‘readwrite’이라는 뜻이다. 이 영역은 읽고 쓰기가 모두 가능하다. - Domain은
1011이므로 11번째 domain에 속해있다는 정보를 담고 있다.- DACR(Domain Access Control Register)는 2-bits씩 총 16개의 domain에 대한 정보를 나타낸다.
- DACR이
0x0040_0001이라면, 2-bits씩 자르면00/00_/00/00_/01/00_/00/00_/00/00_/00/00_/00/00_/00/01이다. - 따라서 0번째 domain과 11번째 domain이
01로 설정돼있음을 알 수 있다.00은 no access/01은 client/10은 reserved/11은 manager 라는 뜻이다.- 따라서 D0과 D11에 포함되는 메모리 영역은 client 유저가 접근할 수 있도록 설정됐다는 뜻이다.
- 결과적으로 ⓐ는 client 유저가 readwrite 할 수 있다.
- [4]는
1로 고정돼있고 - [3]인 C-bit는
0이므로 uncached, cache에 넣는 것이 불가능한 영역이라는 뜻이다. - [2]인 B-bit([※] 책의 H-bit는 오타입니다.)는 write buffer 사용 여부인데
0이니까 사용 안 한다는 뜻이다. - [1:0]은 section entry임을 나타내는 것이라고 위에서 배웠다.
- Base address는 MSB 12-bits로
- ⓑ는
0000_0000_1100_0000_0000_1101_0110_1010인데, 위에서 배운 내용에 따라 정리해보자.- Base address는
0x00C0_0000이고 - AP는
11이니까 readwrite 이고 Domain은1011이니까 D11에 포함되는 client 영역이고 - C-bit는
1이고 B-bit는0이니까 Cache On (write through) Write buffer On이다.
- Base address는
- 이제 우리는 MMU page table을 보고 유틸리티의 도움이 없더라도 의미를 확실하게 이해할 수 있게 됐다.
2.6. TLB (Translation Lookaside Buffer)
- TLB는 MMU의 address mapping 속도를 증가시키기 위한 entry에 대한 cache를 말한다.
- MMU page table은 어쨌든 레지스터가 아니라 잘해야 TCM, 일반적으로는 메모리에 있기 때문에 translation도 메모리 접근이 필요하다. 메모리 접근 횟수를 최소한으로 만들기 위해 translation의 cache를 만든 것이다.
- CPU가 VA를 발생하면 → TLB에서 해당 VA의 entry가 들어있는지 확인하고 → hit이면 바로 PA 반환, miss면 MMU page table로 가서 translation 한 뒤 → 나중에 쓸 수도 있으니 TLB에 저장한다.
- 최악의 시나리오는 TLB miss + cache miss로 instruction 1회 실행에 메모리를 2, 3회 접근하는 경우다.
3. 기타 내용
3.1. Bit operation
- Q. Shadow란?
- Back-up의 유의어로 보통 레지스터를 가리킬 때 자주 사용한다.
- 레지스터 중에 write만 가능하고 read가 불가능한 레지스터가 있다.
- 그런 레지스터의 값을 읽어보기 위해 전역변수에 백업하는 방법을 말한다.
- 우리는 1.1절에서 레지스터는 address align을 위해 부분접근이 불가능하다고 배웠다.
- 하지만, 레지스터는 latch(flip flop)의 집합이기 때문에 사실 bit 연산을 통해 bit 단위 제어가 가능하다.
- AND(&): 특정 bits를 보기 위한 용도로 사용한다.
if (reg_data & 0x20)은0x20 = 100_000이므로reg_data의 6번째 bit가1인지 아닌지 확인이 가능하다.- 또는
if (reg_data & (1 << 5))으로 표현이 가능하다. 이게 더 편하다.
- OR (|): 특정 bits를
1로 set 하기 위한 용도로 사용한다.reg_data |= (1 << 3)은reg_data의 4번째 bit를1로 set 한다.
- AND NOT (~&): 특정 bits를
0으로 reset하기 위한 용도로 사용한다.reg_data &= ~(1 << 4)는reg_data의 5번째 bit를0으로 reset 한다.
- XOR(^): 특정 bits를 toggle(뒤집기)하는 용도로 사용한다. (
0 → 1, 1 → 0)
- AND(&): 특정 bits를 보기 위한 용도로 사용한다.
3.2. MACRO 테크닉
C언어의 Macro는 사용하기에 따라 굉장히 편리하므로 여기서 4가지 테크닉에 대해 알아보자.
-
여러 줄을 Macro로 만들기
// 역슬래시 '\'로 여러 줄을 Macro로 만들 수 있다. #define CRITICAL_IO_IN \ critical_section_in();\ ret = io_read();\ critical_section_out();- 위와 같이 역슬래시를 사용해서 여러 줄을 가진 macro를 만들 수 있다.
- 이제 어디서든
CRITICAL_IO_IN이라고 입력하면 위 3줄이 한 번에 들어간다.
-
Macro에 매개변수 받기
#define CRITICAL_IO_IN(curr, io_num, prev) \ critical_section_in(curr);\ ret = io_read(io_num);\ critical_section_out(prev);- 소괄호를 이용해서 마치 함수처럼 macro도 arguments를 받을 수 있다.
- 위와 같이 받아온 arguments를 각 함수에 따로따로 넘겨줄 수도 있다.
-
##으로 매개변수명 치환하기#define DEVICE_BOOTUP_BUFFER 1 #define DEVICE_STARTUP_BUFFER 3 #define IO_USB 2 #define CRITICAL_IO_IN(CURR, IO, PREV) \ critical_section_in(DEVICE_CURR##_BUFFER);\ ret = io_read(IO_IO##);\ critical_section_out(DEVICE_PREV##_BUFFER); ... CRITICAL_IO_IN(BOOTUP, USB, STARTUP) /* critical_section_in(DEVICE_BOOTUP_BUFFER);\ ret = io_read(IO_USB);\ critical_section_out(DEVICE_STARTUP_BUFFER); 직접 해보니까 책처럼 ##CURR## 이렇게 ##으로 감싸는게 아니라 뒤에 ##을 붙혀야 동작하더라구요. 오타인가봐요. */##을 사용하면 위와 같이 엄청난 일이 가능해진다.
-
do while(0)으로 블록으로 묶인 Macro 만들기- 위 1~3번은 보통 arguments를 받아 직접 써먹기 위한 용도로 사용한다.
- 하지만, 반복문에서 사용하기에는 부적절한 경우가 많다.
// 예를 들어, #define INPUT_AND_OUTPUT(x)\ scanf("%d", &x);\ printf("%d", x); if (x > 10) INPUT_AND_OUTPUT(x) else exit(0);- 위와 같은 경우, if문은
scanf()에만 적용될 것이며 컴파일러는 에러를 낼 것이다. - 따라서 block으로 묶어줄 필요가 생기는데, 이때
do-while(0)을 사용한다.
#define INPUT_AND_OUTPUT(x)\ do {\ scanf("%d", &x);\ printf("%d", x);\ } while (0) if (x > 10) INPUT_AND_OUTPUT(x); else exit(0); /* if (x > 10) { scanf("%d", &x); printf("%d", x); } else exit(0); */- 위와 같이 정의하면 하단 주석과 같이 block으로 씌워진 것 같은 효과를 낼 수 있다.
3.3. Wait state
- MCU는 자신보다 느린 장치를 다룰 때 wait state를 사용한다.
- Wait state란, MCU가 device로부터 값을 읽거나 쓰기 위해 특정 주소에 접근한 뒤 제대로 된 값을 받거나 줄 수 있을거라 기대하는 시간을 의미한다.
- Wait state를 너무 크거나 적으면 CPU가 쓰레기값을 읽을 수 있으며 적정값보다 높으면 성능이 감소하므로 적정 수준에서 가장 최소한의 wait state를 설정해야 최대 성능을 낼 수 있다.
- [※] 본문 p.550의 그림이 원문 티스토리 블로그에서 없어졌네요…ㅠㅠ
- 어느 NOR flash의 datasheet를 보니 read operation의 타이밍도에서
tCE(Chip Enable Access Time)이 최소 80ns라는 것을 확인할 수 있다. 즉, 유효한 output data를 얻기까지 CE가 low로 활성화 된 뒤 최소 80ns 소요된다는 뜻이다. - 이번에는 MCU의 datasheet를 보자. CS가 low로 내려간 뒤 data를 읽을 때까지의 시간
tACSDV(Address and Chip Select active to Data Valid)가 최소 (T-21)+W×T라고 명시돼있다. - 이 MCU의 core frequency는 40Mhz이므로 시간으로 환산하면 25ns다.
- 따라서 (25 - 21) + 25W ≤ 80 이므로 W는 3.xxx이므로 대략 wait state는 4-clock임을 알 수 있다.
- 만일 다른 NOR flash 제품의 tCE가 75ns이면, W는 3.0이므로 wait state는 3-clock이다. 단지 5ns의 차이만 있을 뿐인데 wait state는 25%가 좋아졌으니 성능이 대폭 좋아졌다고 볼 수 있다.
- 이 경우는 tCE와 tACSDV만 따져봤지만, read, write, reset 등에 대한 다양한 경우의 수를 모두 고려한 뒤 적절한 wait state를 결정해야 한다.
