
'임베디드 스케치'의 2번째 요약 및 정리는 개발된 SW가 임베디드 시스템에서 동작하기 까지의 설명이 포함되며 원본 교제의 다음 부분을 포함합니다.
- 책의 Chapter 2 : 206 ‘인터럽트가 뭐죠?’
- 책의 Chapter 3
- 책의 Chapter 4
- 400 ‘Monolithic kernel과 micro kernel 차이점은?’
- 401 ‘임베디드 OS의 용어 정의’
[※] 표시와 함께 존댓말로 적힌 문장은 책에는 없으나 부가설명이 필요한 경우 구글링을 통해 제가 추가 학습한 내용입니다!
1. 인터럽트 (Interrupt)
- ARM Core는 인터럽트를 두 가지로 분류해 처리한다.
- IRQ (Interrupt ReQuest)
- FIQ (Fast Interrupt reQuest)
- 부팅할 때 각 peripheral은 interrupt controller의 ‘Interrupt Mode Register’에 자신이 내보내는 인터럽트가 IRQ로 분류될지 FIQ로 분류될지 설정한다.
- ARM에서 IVT(Interrupt Vector Table)는 ‘startup.s’에 정의돼있으며 고정된 주소를 갖고 있다. IRQ/FIQ 발생 시 IVT로 PC값이 jump한 뒤 대응하는 ISR(Interrupt Service Routain) 시작주소로 또 jump한다.
- [※] 즉, 인터럽트가 발생하면 IVT를 주욱 보면서 이 인터럽트를 처리할 함수(ISR)의 시작주소를 찾아서 실행한다는 뜻입니다.
- IVT에서도
0x8번지는 SWI(SW Interrupt)로 고정돼있다. SWI란, 시스템콜(system call)이 요청될 때 발생하는 인터럽트를 말한다. 유저 영역의 애플리케이션이 시스템콜을 사용하면 SWI가 발생해 커널영역의 ISR을 수행한다.
2. 크로스 컴파일러 (Cross Compiler)
- 우리가 일반적으로 사용하는 host PC에 탑재된 CPU와 임베디드용 CPU는 종류가 다르므로 실행할 수 있는 바이너리도 다르다. (x86 바이너리 / ARM 바이너리)
- Host CPU는 64-bit인 경우가 대부분이지만, 타겟 CPU는 8, 16, 32, 64-bit 등 다양하다. CPU의 bit가 다르다는 의미는 CPU가 1개 명령을 수행할 때 메모리 속 바이너리에서 읽어오는 bit 수가 다르다는 뜻이다.
- [※] 그러므로 우리가 host PC에서 만들고 컴파일한 바이너리가 타겟 MCU에서 동작하기 위해서는 해당 CPU가 사용할 수 있는 형태의 바이너리로 바꾸는 과정이 필요합니다. (x86 → ARM) 이 작업을 크로스 컴파일이라고 합니다.

- 우리가 만든 C언어 소스파일은 C컴파일러 또는 assembly 컴파일러를 이용하면 object file(
*.o)이 생성된다. - 여러 object file을 만들면 링커가 링커 스크립트에 따라 실행 가능한 ELF(Executable and Linkable Format)파일을 만든다.
- ELF에는 타겟의 메모리 주소, 개발자의 프로그램 소스 등 여러 가지 정보가 들어있다.
- ELF는 헤더, 바이너리, 심볼 3개의 파트로 나뉘어 있다.
- 헤더: 파일의 구성을 나타내는 로드맵과 같은 역할을 한다.
- 바이너리: 순수하게 실행할 수 있는 코드이며 타겟 메모리에 올라가는 그 바이너리다.
- 심볼: 디버깅을 위한 정보로, 개발자가 정의한 함수나 변수를 실제 메모리 주소와 매핑시켜 보여준다.
- 마지막으로 컴파일러 유틸리티인 ‘Object copy’를 사용하면 바이너리 파일(
*.bin)이 만들어진다.
3. 컴파일러 과정 중 만나는 파일들
3.1. ‘startup.s’ 파일
- ‘startup.s’ 어셈블리 파일은 부팅 과정에서 가장 첫 번째 단계를 담당하는 파일을 말한다.
- Q. ‘startup.s’는 왜 C언어가 아니라 어셈블리어로 개발해야 할까?
- A1) 인터럽트를 처리해야 하기 때문이다. IRQ/FIQ는 빈번하게 발생하므로 빠르게 처리해줘야 하며 실행되는 코드 수를 최소화, 최적화하기 위해서는 어셈블리어가 유리하다.
- A2) Memory controller의 레지스터 설정 및 stack 주소 할당 때문이다. C프로그램이 작동하려면 지역변수나 return address가 저장될 stack 영역이 무조건 할당돼야 한다. Stack 영역을 할당하기 위해서는 CPU가 SDRAM에 접근할 수 있어야 하고 그러기 위해선 이전 챕터에서 배웠듯 memory controller 레지스터 설정이 선행돼야 한다. 따라서 startup.s는 어셈블리어로 개발해야 한다.
- ‘startup.s’는 다음과 같은 순서로 구성돼있다.
- IVT (Interrupt Vector Table)
- Disable interrupt: 부팅 중에 인터럽트를 받지 않도록 잠시 비활성화하는 부분
- PLL (Phase Looked Loop) 설정: 시스템 및 peripheral의 동작 클럭을 설정하는 부분
- Memory controller 설정: CPU가 SDRAM 및 Flash memory에 접근할 수 있도록 설정하는 부분
- 메모리 영역 설정: Stack 영역을 포함해 각 메모리 영역(
.text, .data, .bss, stack, heap 등) 설정하는 부분 - 변수 초기화:
.bss영역에 있는 global 변수들을 초기화하는 부분 main()함수 호출
3.2. Makefile 파일
- 개발 과정에서 코드를 조금 수정할 때마다 컴파일 - 링크 - objcopy 등을 반복하는 것은 굉장히 귀찮은 일이다. 또한, 한동안 컴파일 안 하고 개발만 하다가 다시 컴파일 할 때 컴파일 명령어나 옵션이 기억 나지 않으면 또 찾아봐야 하므로 여러모로 손해다.
- 바이너리를 조금이나마 편하게 얻기 위해서 일련의 과정을 자동화하는 스크립트를 Makefile이라고 하며 이를 가능하게 해주는 유틸리티를 Make라고 부른다.
- Makefile은 다음과 같은 구조로 돼있다.
- Source file name
- Compiler name
- Assembly compiler(Assembler) option
- C compiler option
- Compile command
3.3. 링크 스크립트 (Linker Script) 파일
링커 스크립트란?
- 컴파일이 끝나 만들어지는 object 파일은 4가지 독립된 영역인 코드/ 데이터/ 힙/ 스택 영역으로 나눠진다.
#include <stdio.h>
int a, b = 15; // 1
int main() {
int c; // 2
char *d; // 3
a = 10; // 4
b++; // 5
c = c + 5; // 6
d = malloc(10); // 7
return 0;
}- 위와 같은 C프로그램이 있다고 가정해보자.
- 코드영역은 위 C 프로그램이 ARM Core가 이해하는 기계어 명령으로 바뀌었을 때의 코드가 들어간다.
- 데이터영역은 글로벌 변수를 포함하며 초기화 여부에 따라 서로 다른 영역에 저장된다.
int a는 초기화 되지 않았으므로 SDRAM의.bss영역에 저장된다.int b = 15는 초기화 됐으므로 플래시메모리의.data영역에 저장된다.
- 힙 영역은
malloc()함수 등을 사용했을 때 동적메모리가 할당되는 영역이며char d[10]은 여기 저장된다. - 스택영역은
int c같은 지역변수나 서브루틴 복귀주소 등이 저장된다. - 스택영역은 높은 주소에서 낮은 주소로, 힙 영역은 낮은 주소에서 높은 주소로 서로 반대방향으로 할당된다.
- 링커 스크립트는 각 영역의 start 주소와 end주소를 지정해 기록하는 곳이다.
- 두 개 이상의 object 파일을 하나의 바이너리로 만들 때(링크 할 때) 링커는 각 오브젝트에서
.text와.data를 따로 분리해 한 곳으로 합쳐서 바이너리를 생성한다.
링커 스크립트 만들기 (예시)
- MCU 데이터시트를 보고 memory map을 찾는다.
- SDRAM 시작주소, 크기, Flash memory 시작주소, 크기를 파악한다.
- Flash memory는 HW를 찾은 뒤 component 이름을 구글에 검색하면 추가정보를 얻을 수 있다.
- 여기서는
NOR Flash 시작주소:0x0000_0000, 마지막주소:0x003F_FFFF(크기: 4MB)
SDRAM 시작주소:0x3000_0000, 마지막주소:0x31FF_FFFF(크기: 32MB) 라고 가정한다.
- 메모리 영역을 어떻게 나눌 것인지 결정한다.
.text영역의 시작.text_start는 Flash 시작주소 이후로 결정한다. →.text_start = 0x0000_0000.data영역의 시작은.text영역의 끝인.text_end이후+0x4로 결정한다. 하지만, 개발자 입장에서는 현재 개발중인 프로그램 소스코드의 마지막 주소를 알 수 없기 때문에 컴파일러가 알아서 결정해준다. →.data_start = .text_end + 0x4.bss영역의 시작.bss_start는 SDRAM 시작주소 이후 조금 여유공간을 둔 뒤 결정한다. 여기서는 128KB를 띄웠다고 가정한다. →.bss_start = 0x3002_0000- 힙 영역과 스택 영역은 링커 스크립트에서 따로 지정하지 않는다.
malloc()함수가 자동으로.bss_end주소+0x4이후 주소를 동적할당 해주기 때문이다. 그리고 스택은 SDRAM의 마지막 주소부터 위에서 아래로 내려오며 할당하므로 스택의 마지막 주소를 따로 지정할 필요가 없다. 또한, 스택은 링커 스크립트가 아니라 ‘startup.s’에서 영역 할당을 해주던 점을 다시 상기하자.
- 결정한 내용에 따라 링커 스크립트를 작성한다.
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
OUTPUT_ARCH(arm)
ENTRY(_start)
__TEXT_START__ = 0x00000000;
__BSS_START__ = 0x30020000;
...4. 코딩하기 전 알아야 할 사항들
4.1. C언어에서 변수는 어디에 저장되는가?
- [※] 위 3.3절과 중복되는 내용입니다.
- C언어에서 변수를 저장하는 ‘기억클래스’는 다음 4가지가 있다.
- Register (레지스터 변수) : CPU 내 레지스터에 저장하는 변수를 말한다. 보다 빠르게 입출력 할 수 있지만, 레지스터 개수 제한 때문에 선언한다고 모두 레지스터에 저장되진 않고 스택에 저장되기도 한다.
- Auto (자동변수, 지역변수) : 기억장소를 따로 지정하지 않은 모든 변수는 auto로 스택에 저장된다. 함수 또는 블록이 유효할 때만 존재할 수 있으며 대표적으로 ‘지역변수’가 여기에 포함된다. 초기화하지 않으면 이전에 스택에 저장됐던 값(쓰레기값)이 들어가므로 초기화를 권장한다.
- 단, 초기화를 권장하지만, ‘초기화를 한다는 것’이 어떤 결과를 초래하는지 머릿속에 염두해야 한다.
- CPU는 초기화를 하기 위한 명령어를 SDRAM으로부터 가져오기 위해 메모리 접근을 최소 1번 더 하게 되므로 바이너리 크기와 전력소모량이 증가한다.
- Static (정적변수, 전역변수) :
static키워드를 사용하거나 전역변수로 선언했다면 함수나 블록을 벗어나도 그 값을 유지한다. 초기화 여부에 따라.data영역 또는.bss영역에 저장된다. 만일 초기화 하지 않았다면, startup.s에서.bss영역을 초기화 할 때0으로 초기화 한다. - Extern (외부변수) : 외부변수도 초기화하지 않으면 정적변수처럼 0으로 초기화 된다. 스택에 저장하기에 너무 큰 데이터의 경우
extern선언으로 지정해.data또는.bss에 저장되게끔 만들어야 한다.
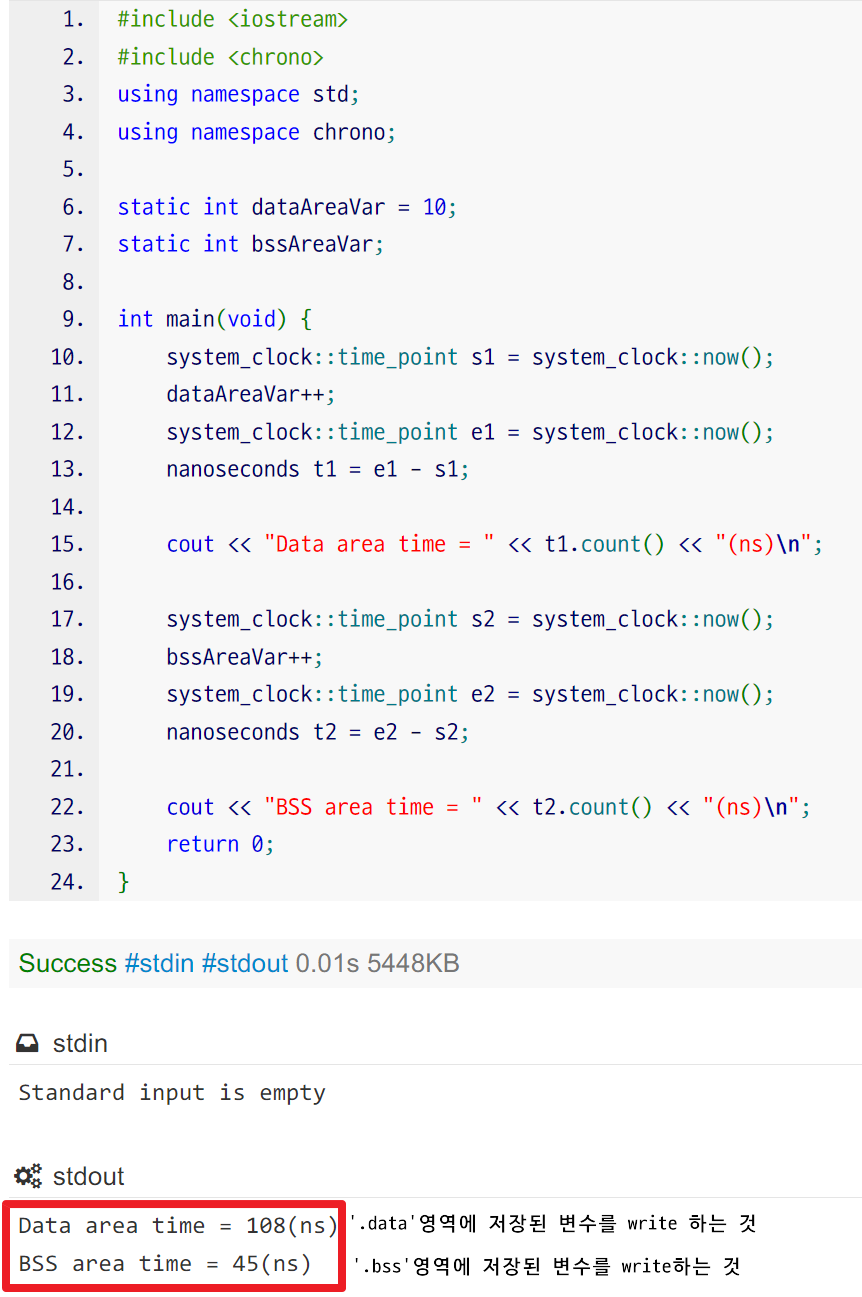
- [※] 중요한 점은 Static 변수의 초기화 여부에 따른 속도 차이입니다. Static 변수는 초기화를 하면 플래시메모리에, 초기화를 하지 않으면 SDRAM에 저장된다고 배웠습니다. 즉, 초기화를 하지 않는 쪽이 CPU 입장에서는 더 빠르게 read/write 할 수 있습니다.
4.2. C언어에서 C++ 함수는 어떻게 call 하는가?
- [※] Extern 선언과 Makefile의 parameter를 이용해서 C 파일에서 C++ 함수를 call, 어셈블리에서 어셈블리함수 call, C++에서 C함수 call하는 방법을 소개하고 있습니다…만 솔직히 잘 이해가 안 가서 원본 주소(링크)를 올리고 스킵하겠습니다 ㅎㅎㅎ…
4.3. 인라인 어셈블리 (inline assembly)는 왜 사용하는가?
#include <stdio.h>
int result;
void func(int lhs, int rhs) {
result = lhs + rhs;
}
int main() {
int i, a, b;
a = 1, b = 2;
// [Step 1] C언어 함수
for(i = 0; i < 5; i++)
func(a, b);
// [Step 2] 인라인 어셈블리
for(i = 0; i < 5; i++) {
_asm__volatile_(
"add %0, %1, %2 \n\t"
:" =r" (result)
:"r" (a), "r" (b)
:"memory"
);
}
return 0;
}- 위 C코드는 a = 1과 b = 2를 5번 더하는 간단한 프로그램을 C함수와 인라인 어셈블리로 구현한 것이다.
- 컴파일 한 결과를 덤프해서 확인한 결과, step 1은
0x0000_03AC ~ 0x0000_03E8까지 총 64B를 사용했고, step 2는0x0000_0450 ~ 0x0000_0470까지 총 36B를 사용했다. - Step 1과 2는 같은 결과를 만드는 소스코드지만, 메모리 사용량과 성능에서 차이가 있음을 알 수 있다.
5. MMU & Cache Enable 하기
5.1. MMU Enable 하기
-
앞서 Co-processor를 제어해 MMU를 활성화하고 MMU를 활성화 해야만 cache를 사용할 수 있음을 배웠다.
-
ARM Core가 Co-processor를 제어하는 표준 명령어는 단 2개다.
- MCR (Move from Register to Co-processor)
- MRC (Move from Co-processor to Register)
- [※] M●◆ 형태인데 ◆에서 ●로(뒤에서 앞으로) 데이터가 옮겨진다고 외우면 편합니다.
MCR/MRC P15, 0x0, R0, C1, C0, 0x0형태로 명령어를 사용한다. Core의 0번 레지스터와 15번 Co-processor(CP15)의 1번 레지스터(C1 = CR = Control Register)와 데이터를 옮기겠다는 뜻이다.
-
MRC 명령어를 사용해 CP15의 CR 레지스터를 수정해 MMU를 활성화 할 수 있다.
-
이때 MMU를 활성화하기 전에 반드시 3가지 작업을 선행해야 한다.
-
MMU Page Table 주소 지정하기
- 코어가 사용하는 가상주소(VA)를 SDRAM의 물리주소(PA)로 변경헤주는 MMU Page Table이 위치할 주소는 개발자가 수동으로 지정한다.
- CP15의 2번 레지스터인 TTBA(Translation Table Base Address)레지스터에 MMU Page Table의 물리주소를 설정하면 된다.
- [※] TTBA는 TTB 또는 TTBR라고 부르기도 합니다.
MCR P15, 0x0, R0, C2, C0, 0x0을 사용하면 TTBA 레지스터를 설정할 수 있다. 이때 주소는 SDRAM의 물리주소 중에.text와.data를 제외한 곳으로 지정하면 된다.
-
물리주소(PA)와 가상주소(VA) 설정하기
- [※] ★ ****주의 ★****
- [※] 이 부분이 원본 책에서 설명이 애매모호하게 돼있습니다. 추가로 검색하고 조사해서 채워넣어 보려고 했지만, 의문을 완전히 해소하지 못했습니다. (참고링크: 링크1, 링크2, 링크3)
- [※] 의문점 1.
MMU_SetMTT명령 후 ‘어디에’ ‘어떤 방법으로’0x0000_0C1A라는 값이 저장되는지 모르겠습니다. ARMv9 문서에 따르면, TTB의 상위 18-bit와 FCSE에 의해 변조된 MVA의 상위 12-bit가 합쳐져서 만들어진 결과물 1st-level descriptor가0x000_0C1A인 것 같은데…책에서 TTBA를 지금0x30F0_0000으로 선언했는데 어떻게0x0000_0C1A가 나온건지 모르겠네용 - [※] 의문점 2. 책에 TLB가 MMU page table을 ‘만든다고’ 설명돼있는데 이게 정말 맞는 설명인지…? 원래 알고있던 TLB랑 하는 역할이 너무 다릅니다.
- [※] 의문점 1.
- [※] 이 부분은 흐름 정도만 파악하시기 바랍니다. 추후 공부한 뒤 꼭 수정해서 채워넣도록 하겠습니다.
- [※] 이 부분이 원본 책에서 설명이 애매모호하게 돼있습니다. 추가로 검색하고 조사해서 채워넣어 보려고 했지만, 의문을 완전히 해소하지 못했습니다. (참고링크: 링크1, 링크2, 링크3)
MMU_SetMTT(0x0000_0000, 0x000F_0000, 0x0000_0000 RW_CNB);라는 C언어 매크로를 사용하면 MMU page table에 새로운 entry를 삽입할 수 있다.- Parameter 설명: 1st = VA 시작주소, 2nd = VA 끝 주소, 3rd = PA 시작주소, 4th = 이 영역의 VA에 대해 부여할 권한 및 캐시 정책 설정. ([※]
RW_CNB는 Read/Write Cache Write Through)
- Parameter 설명: 1st = VA 시작주소, 2nd = VA 끝 주소, 3rd = PA 시작주소, 4th = 이 영역의 VA에 대해 부여할 권한 및 캐시 정책 설정. ([※]
- MMU는 instruction MMU와 data MMU로 나뉘는데, 각각 TLB(Translation Lookup Buffer)가 있다. TLB가 MMU page table에 새로운 entry를 넣는 역할을 한다. (?)
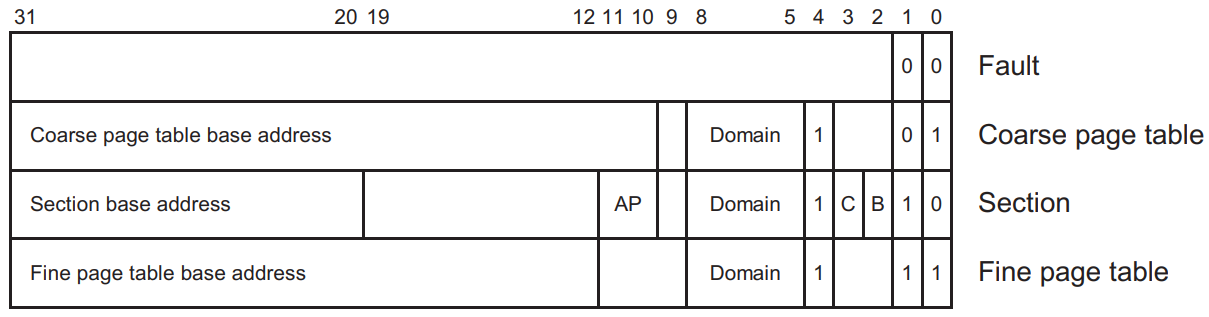
- [※] 책에서 다루는 ARMv9는 2-level translating page table을 사용합니다. 여기서 MMU는 메모리에 접근하는 물리주소(PA)를 나눌 크기 단위를 지정하는 여러 방식 중 하나를 선택할 수 있습니다. (솔직히 맞는 설명인지 확신이 없습니다.)
- [※] Section(섹션) 단위 : 1MB 크기 block 단위로 translation 합니다.
- [※] Page(페이지) 단위
- [※] Coarse 단위: 64KB(Large), 4KB(Small) 단위 page translation 합니다.
- [※] Fine 단위: 64KB(Large), 4KB(Small), 1KB(Tiny) 단위 page translation 합니다.
- TTB 하위 2-bit로 구별 →
00= Fault,01= Coarse page table,10= Section,11= Fine page table
- [※] 책은 TTB가 현재
0x0000_0C1A인 상황을 가정했습니다. 이를 펼쳐보면 다음과 같습니다.0000_0000_0000_0000_0000_1100_0001_1010- [※] 하위 2-bit가
10이므로 translation 단위는 섹션(section)인 1MB입니다. - [※] 교제의 MMU Page table을 보니 ‘physical’ 부분에
0x0000_0000 ~ 0x000F_FFFF로 표현되는게 보입니다. 정말로 section인 1MB 단위로 translation을 하네요.
- [※] ★ ****주의 ★****
-
도메인 및 권한(Permission) 지정하기
- CP15의 3번째 레지스터인 DACR(Domain Access Control Register)은 2-bit씩 해석해 총 16개의 도메인에 대해 4개의 상황을 표현한다.
00= No Access = 모든 접근에 대해 ‘domain fault’ 예외 발생01= Client = TLB entry의 AP 비트 정보를 따른다10= Reserved = 사용하지 않는 상황 / 이런 경우는 발생하지 않음11= Manager = TLB entry의 AP 비트 정보를 무시하고 무조건 접근 허용
- TTB[8:5]는
0x0000으로 현재 domain은D0번을 지정하고 있고
DACR이0x5555_5551이므로D0번 domain은 client이다. - TTB[11:10] 2-bit는 AP(Access Point)라고 부르며 CP15의 CR 레지스터 속 R, S bit 2개와 합쳐서 총 4개 bit로 16가지 퍼미션(권한) 상황을 지정한다.
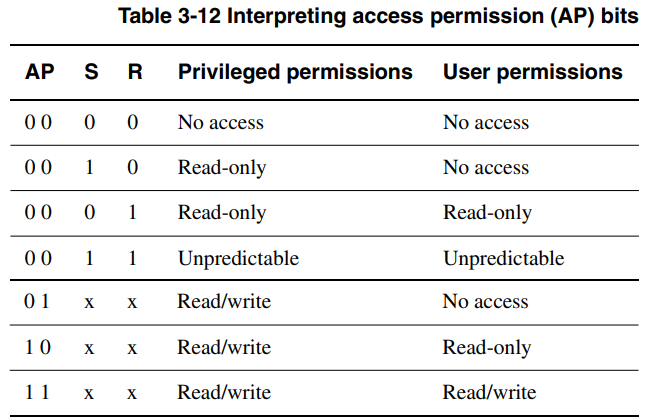
- CP15의 3번째 레지스터인 DACR(Domain Access Control Register)은 2-bit씩 해석해 총 16개의 도메인에 대해 4개의 상황을 표현한다.
-
5.2. Cache Enable 하기
5.2.1. Cache 식별하기
- Cache를 사용하는 가장 큰 이유는 temporal/spartial locality에 의한 높은 재사용성으로 시스템의 성능을 비약적으로 높이기 위해서다.
- Co-processor → MMU → Cache 순서로 설정해야 함을 여러차례 반복하고 있으니 꼭 다시 상기하자.
- Co-processor에는 cache의 정보가 들어있는데, 이를 HW 디버거를 사용해서 확인하면 다음과 같다.

- MIDR 레지스터는 cache의 ID 코드를 의미하며 오른쪽은 각 숫자의 설명을 의미한다.
- CTR 레지스터는 cahce의 type을 설명하는 레지스터다.
H yes는 cache가 instruction과 data가 나뉘어있는 Harvard 아키텍처인지 여부를 알려준다.DSIZE, ISIZE는 cache의 크기를 말한다.DASS, IASS는 cache의 주소 매핑 way 수를 말한다.DLENGTH, ILENGTH는 cache의 한 line의 WORD 수를 말한다.- 정리하면, 현재 ARM920T에 장착된 cache는 1개 line이 8WORD(=32Bytes)이고 64way를 포함하는 2KB 짜리 segment를 8개 가진 16KB 크기의 하버드 아키텍처 cache다.
5.2.2. Cache hit & miss
- ARM Core가 요청한 데이터가 cache에 있을 때 ‘hit’, 없을 때 ‘miss’라고 부른다.
- Cache miss가 났을 때 메모리로부터 block 단위로 데이터를 가져와 cache에 저장하고 core가 요청한 WORD 크기의 데이터만 전달한다.
- 이때 cache가 이미 가득 찼다면 교체 정책(replace policy)에 따라 cache에서 제거할 block을 선택해야 한다.
- Round-Robin(RR) 방식: 별도의 카운터를 두고 교체할 때마다 block마다 순서대로 한 번씩 돌아가면서 교체하는 방식.
- Random 방식: 무작위로 아무 block이나 제거하고 교체한다.
- CP15의 CR레지스터를 확인하면 ‘RR’ bit가 있는데 여기서 현재 어떤 정책을 사용하는지 확인할 수 있다.
5.2.3. Cache write 정책
- Core가 메모리에 write을 요청할 때 쓰기 정책(write policy)에 따라 변경사항을 cache에만 적용하거나, 메모리에도 적용해야 한다.
- Write through: Cache와 함께 메모리도 변경사항을 저장하는 방식으로 일관성을 유지할 수 있으나 성능은 좋지 않으며 심한 경우 cache가 무용지물이 되기도 함.
- Write back: 우선 cache에만 변경사항을 저장하고 표시(Dirty-bit)해둔 뒤 나중에 변경사항을 메모리에 적용한다. 보통 dirty-bit가 표시된 block이 교체될 block(victim)으로 선택될 때 메모리에 적용한다.
- Write through를 사용하던 write back을 사용하던 메모리 접근 또는 cache replace를 피할 수 없기 때문에 cache의 장점을 완전하게 이용할 수 없다.
- 따라서, write buffer 및 write back PA TAG RAM 이라는 별도의 버퍼 장치를 도입해 cache 변동 사항을 메모리에 전달하는 기능을 대신 수행하도록 맡긴다면, cache는 본연의 업무에만 집중할 수 있고, 일관성(consistency)도 확보할 수 있게 된다. ([※] Write through면 write buffer를 사용하고, write back이면 PA TAG RAM을 사용합니다. 변동사항이 있는 cache line을 버퍼에 넣어두면 얘가 알아서 SDRAM에 write 합니다.)
5.2.4. Cache 활성화
- 5.1절의 MMU 때와 마찬가지로 cache도 활성화 하기 전에 3가지 작업을 선행해야 한다.
- Cache clean :
MCR P15, 0x0, R0, C7, C14, 0x2 - Cache flush :
MCR P15, 0x0, R0, C7, C5, 0x0 - TLB 비활성화 :
MCR P15, 0x0, R0, C8, C7, 0x0
- Cache clean :
- 이후 CP15의 CR 레지스터 값을 변경에 cache를 활성화 한다.
MCR P15, 0x0, R0, C1, C0, 0x0 - Cache 관련 용어 설명
- Cache clean 이란?
- Dirty-bit가 set 된 cache line을 강제로 메모리에 write한 뒤 dirty-bit를 0으로 reset하는 행위를 말한다.
- Write back을 사용할 때 cache와 메모리 사이의 일관성을 유지하기 위해 사용한다.
- Cache flush 란?
- Cache invalidate 란?
Cache line의 valid-bit를 set해 ‘invalid(유효하지 않음)’로 표시하는 행위를 말한다. - Cache flush는 cache invalidate 후 cache line의 data를
0으로 초기화 한 뒤 메모리에서 다시 로드해서 저장해 일관성을 유지하는 행위를 말한다. - Core의 bus 제어권을 훔칠 수 있는 DMA 같은 경우 cache를 지나쳐서 바로 메모리에 read/write을 하기 때문에 core 입장에서는 현재 cache 데이터가 메모리의 데이터와 일치하는지 알 수 없게 된다. 따라서 ([※] DMA로 인해 불일치가 발생한 cache가 어떤 line, block에 있는지 어떻게 아는지는 모르겠지만) cache invalidate 후 flush 해버리고 다시 메모리에서 load 해와야 한다.
- Cache invalidate 란?
- [※] 주의해야 합니다. Cache clean과 cache flush는 아키텍처마다 의미가 혼용돼있습니다. 구글링 해보면 아시겠지만 저마다 하는 말이 다 다릅니다 ㄷㄷ…따라서 용어 자체에 신경쓰기보다는 저런 용어를 사용하게 된 배경(일관성, DMA 등)과 과정에 집중하면 될 것 같습니다.
- Cache clean 이란?
6. RTOS 배경지식
6.1. Monolithic Kernel vs Micro Kernel
- RTOS는 시간에 따라 기능이 정확하게 동작하도록 관리할 수 있고,
각 task마다 사용하는 독립적인 시스템 자원을 관리할 수 있으며,
보다 편리하게 애플리케이션을 개발할 수 있는 기반을 제공하는 일종의 시스템 SW다. - 주요특성: 신뢰성, 확장성(필요에 따라 기능 추가, 제거), 예측가능성, 간결성(자원을 효율적으로 사용하고 프로그램을 간결하게 설계함), 고성능
- 임베디드 OS를 선택할 때는 kernel이 어떤 구조를 가졌는지 파악해야 한다.
- Monolithic kernel: OS가 관리할 수 있는 모든 서비스를 갖춘 kernel이다. 시스템을 보다 효율적으로 관리하기 위해 시스템 운영에 필요한 많은 서비스 루틴을 포함하고 있다. 대표적으로 임베디드 리눅스(Linux)가 있다.
- Micro kernel: Kernel의 가장 핵심적인 기능만 갖춘 최소화된 kernel이다. 실시간성에 강하고 크기가 작아 낮은 성능의 임베디드 시스템에도 로드할 수 있다.
- 하이퍼바이저 (HyperVIsor)
- Host PC에서 ‘VM Ware’나 ‘Virtual Box’처럼 기본 OS위에 다른 OS를 동시에 실행하기 위한 가상플랫폼 프로그램이 있는 것처럼, 임베디드 시스템에도 여러 OS를 실행하려는 시도가 있다.
- 하이퍼바이저는 다수의 OS를 동시에 실행하기 위한 가상플랫폼 기술을 의미한다.
- 대표적으로 Open Kernel Labs의 ‘OKL4’ OS가 있다. 임베디드 시스템 CPU에 OKL4 micro kernel을 올리고 그 위에 다른 monolithic kernel을 올릴 수 있다.
- Micro kernel의 최소 기능만을 포함해 실시간성을 보장하고, 작은 서버 모듈로 구성된 서비스 프로세스도 포함하고, 유저영역과 커널영역으로 나뉜 구조는 monolithic kernel과 유사하다.
6.2. 임베디드 OS 용어 정리
- Task (태스크)
- 실행할 수 있는 프로그램 또는 함수를 의미하며 CPU 스케줄링의 최소단위를 말한다.
- RTOS는 보통 ‘고정 우선순위 기반 스케줄링’을 지원한다. 동일 우선순위 task 사이에서는 round-robin을 사용해서 순서대로 번갈아가면서 CPU time을 가진다.
- ‘가변 우선순위 기반 스케줄링’은 task의 deadline을 기반으로 우선순위가 바뀌어 실시간성이 높아 RTOS에 이상적이지만, 계속해서 우선순위를 재계산 해야하므로 CPU 자원을 많이 소모한다.
- Context switching
- 인터럽트가 발생했거나, 특정 함수의 사용으로 task의 상태가 바뀌거나 (running → waiting), 우선순위가 더 높은 task의 등장 등의 이유로 현재 CPU가 작업중인 task가 전환되는 상황을 의미한다.
- 인터럽트가 발생한 상황을 가정할 때 context switching 과정은 다음과 같다.
- Task A 수행 중 인터럽트 발생
- Task A 관련 context(Stack + TCB(Task Control Block))를 저장한다.
- IVT로 jump 한다. (IVT 주소는 고정돼있고 약속돼있다.)
- 해당 인터럽트 식별 후 대응하는 ISR 시작 주소로 jump 한다.
- ISR 및 연관 task (Deferred interrupt handler) 수행 및 종료
- 2번에서 외부에 저장해둔 task A context 복구
- Task A 이어서 실행
- 공유자원 취급
- Global 변수나 static 변수같은 Task끼리 공유할 수 있는 자원에 접근할 때는 critical section을 선언해서 mutual exclution을 보장해야 한다.
- RTOS에서 critical section은 보통 다음 3가지 요소를 포함한다.
- IRQ/FIQ 비활성화 (Critical section에서 인터럽트 걸리면 안 되니까)
- 스케줄러 비활성화 (Critical section에서 작업 중에 context swtiching 되면 안 되니까)
- Mutex(Binary semaphore) 또는 count semaphore를 이용해 critical section에 들어간다.
- 공유자원 및 critical section은 관리가 까다로우므로,
- RTOS의 기능인 mailbox나 message queue를 이용해서 값을 주고 받으며 동기화 할 수도 있다. (값 요청 → waiting → 수신 이벤트 → ready → 수신 완료 후 running)
- Event group 또는 signal을 사용해서 SWI를 걸어 특정 작업(Handler)을 수행하도록 만들어 동기화 하는 방법도 있다.

임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.