
'임베디드 스케치'의 3번째 요약 및 정리는 ARM프로세서와 연관된 내용을 담았으며 원본 교제의 다음 부분을 포함합니다.
- Chapter 5. ARM Processor Analyse
[※] 표시와 함께 존댓말로 적힌 문장은 책에는 없으나 부가설명이 필요한 경우 구글링을 통해 제가 추가 학습한 내용입니다!
1. ARM Processor가 많이 사용되는 이유
- RISC 아키텍처는 임베디드 시스템에 적합하기 때문이다.
- 명령어와 내부 레지스터가 모두 32-bit로 같은 length를 1개 WORD로 사용하기 때문에 CPU 입장에서는 Fetch 및 Decode 과정이 상대적으로 간단하다.
- CISC 대비 명령어 구조가 간단하고 명령어 개수가 적어 효율적이며 저전력 동작에 용이하다.
- THUMB(THUMB-2)의 도입 때문이다.
- THUMB는 ARM 명령어와 거의 비슷한 기능을 제공하면서 16-bit로 크기가 작은 instruction set을 의미한다.
- 임베디드 시스템에 탑재되는 메모리는 16-bit인 경우가 많다. CPU가 32-bit 인터페이스인 반면 메모리가 16-bit 인터페이스를 갖고 있다면, CPU는 한 번 메모리에 접근 할 때마다 16-bit 밖에 읽을 수 없어서 32-bit 데이터가 필요한 명령어를 수행할 때마다 2번씩 메모리에 접근해야 한다.
- 이런 임베디드 시스템에서는 THUMB를 사용하면, 성능 증가와 효율적인 자원관리 그리고 코드 사이즈를 감소할 수 있다.
- [※] 따라서 THUMB의 도입은 임베디드 개발자에게 더욱 융통성 있는 선택지를 제공합니다.
- Endian 사용이 자유롭기 때문이다.
- 컴파일 할 때 개발자가 입력하는 parameter에 따라 little endian, big endian을 자유자재로 설정할 수 있다.
0x12345678이라는 데이터가 있을 때- Big endian은
[0] = 0x12, [1] = 0x34, [2] = 0x56, [3] = 0x78로 저장한다.
([※] 높은 비트부터 차례대로 저장하는 방식입니다.) - Little endian은
[0] = 0x78, [1] = 0x56, [2] = 34, [3] = 0x12로 저장한다.
([※] 낮은 비트부터 차례대로 저장하는 방식입니다.)
- Big endian은
- FIQ가 존재하기 때문이다.
- ARM 프로세서는 인터럽트를 IRQ와 FIQ로 분류한다.
- IRQ는 레지스터가 3개 있는 반면, FIQ는 레지스터가 8개 있다.
- 따라서, 레지스터가 더 많은 FIQ는 더 빠르게 인터럽트를 처리할 수 있다.
- [※] 사용자는 추가로 입력하는 peripheral의 특성에 따라 IRQ 또는 FIQ에 설정할 수 있습니다.
2. ARM의 instruction
2.1. THUMB 명령어
- [※] 앞서 1절에서는 THUMB의 장점에 대해서 다뤘다면, 이번에는 한계점에 대해서 다뤄보겠습니다.
- THUMB instruction set은 16-bit로 구성돼있다.
- ARM 명령어처럼 data processing 명령어(ADD, SUM, MOV 등), Load/Store 명령어(LDR, STR, PUSH, POP 등), Branch 명령어(B, BX, BLX) 등 다양한 명령어가 제공된다.
- THUMB로 컴파일 한 바이너리 사이즈는 기존 ARM보다 약 65% 감소하기 때문에 메모리 공간을 적게 사용할 수 있다는 장점이 있다.
- 하지만, 뭐든지 장점이 있다면 단점이 있듯, THUMB 명령어의 단점들은 다음과 같다.
- 분기 명령어를 제외하고는 조건부 실행이 안 된다.
- R0~R7 레지스터만 사용할 수 있다.
- 상수값(immediate) 사용 범위가 상대적으로 제한적이다.
- Inline barrel shifter([※] Shift나 rotate 명령어를 수행하는 곳)의 사용이 제한적이다.
- Exception 처리가 불가능하다! ARM은 모든 exception 처리를 ARM 명령어 상태에서 하도록 돼있다.
- PSR(CPSR, SPSR)을 바꿀 수 없다. 즉, 인터럽트나 모드 비트를 전환할 수 없다.
- MMU와 cache 제어를 할 수 없다.
- ARM7 이후부터 완벽하게 지원하게 된 개선버전 THUMB-2 instruction set은 16-bit는 물론이고 32-bit 명령어도 포함하여 ARM 명령어와 거의 비슷한 기능을 제공하고 성능도 유사하지만 코드 사이즈는 적은 고밀도 코드를 만들 수 있다.
- 또한, THUMB-2는 별도의 TI 명령어로 조건부 실행이 가능하고 exception 처리가 가능하며 Co-processor에 접근하는 명령어도 제공돼 MMU와 cache도 제어할 수 있다.
2.2. Co-processor 명령어
- ARM에서 제공하는 Co-processor 관련 명령어는 2가지가 있다.
- MCR: Move from CPU Register to Co-processor register
- MRC Move from Co-processor register to CPU Register
2.3. VFP와 NEON 명령어
- VFP(Vector Floating Point)는 부동 소수점 연산 기능을 제공하는 보조 연산장치로 SIMD 명령어를 처리한다. ([※] SIMD는 3.2.4절에 간략히 설명돼있습니다.)
- ARM10때 VFPv1이, ARM11때 VFPv2가, ARM Cortex-A8때 VFPv3가 적용됐다.
- VFPv3을 NEON이라고 부른다.
- NEON은 VFPv2보다 2배 이상 성능과 코드 효율을 보여 저전력 구현이 가능하다.
- NEON은 주로 3D 그래픽, 오디오, 비디오, 이미지, 음성 처리 등을 수행할 때 사용하곤 한다.
- NEON은 부동 소수점 연산 뿐만 아니라 단수, 단정도 부동소수점도 처리할 수 있고 배열 형태도 저장된 데이터도 지원한다.
2.4. LDR/STR 명령어
- ARM Core에서 사용하는 명령어 중 가장 중요하다고 말해도 과언이 아닌 것이 LDR, STR 명령어다.
- LDR은 Core ← SDRAM으로 read 하는 명령어
- STR은 Core → SDRAM으로 write 하는 명령어
- C 프로그램을 분석해보니 LDR/STR 명령어 개수가 약 50%를 차지하고 있었다.
- C프로그램의 핵심은 바로 메모리를 어떻게 잘 다루느냐에 따라 성능이 많이 좌우된다는 것을 알 수 있다.
- 사용사례
LDR R2, 0x036C=0x036C번지 데이터를 R2로 가져온다.LDR R3, [R2]= R2 값을 주소로 하는 곳에 있는 데이터를 R3로 가져온다.LDR R3, [R11, #-0x10]= R11 값 -0x10한 값을 주소로 하는 곳에 있는 데이터를 R3로 가져온다.- C언어는 포인터를 많이 사용하는데, 포인터를 쓰면 필연적으로 LDR, STR을 사용하게 된다.
3. Mode와 PSR
3.1. ARM Mode
- ARM Core는 6개의 모드 중 한 가지 상태로 동작한다.
- USR, FIQ, SVC, IRQ, UND, ABT 모드가 있다.
- 각 모드마다 서로 다른 레지스터를 가지고 동작한다.
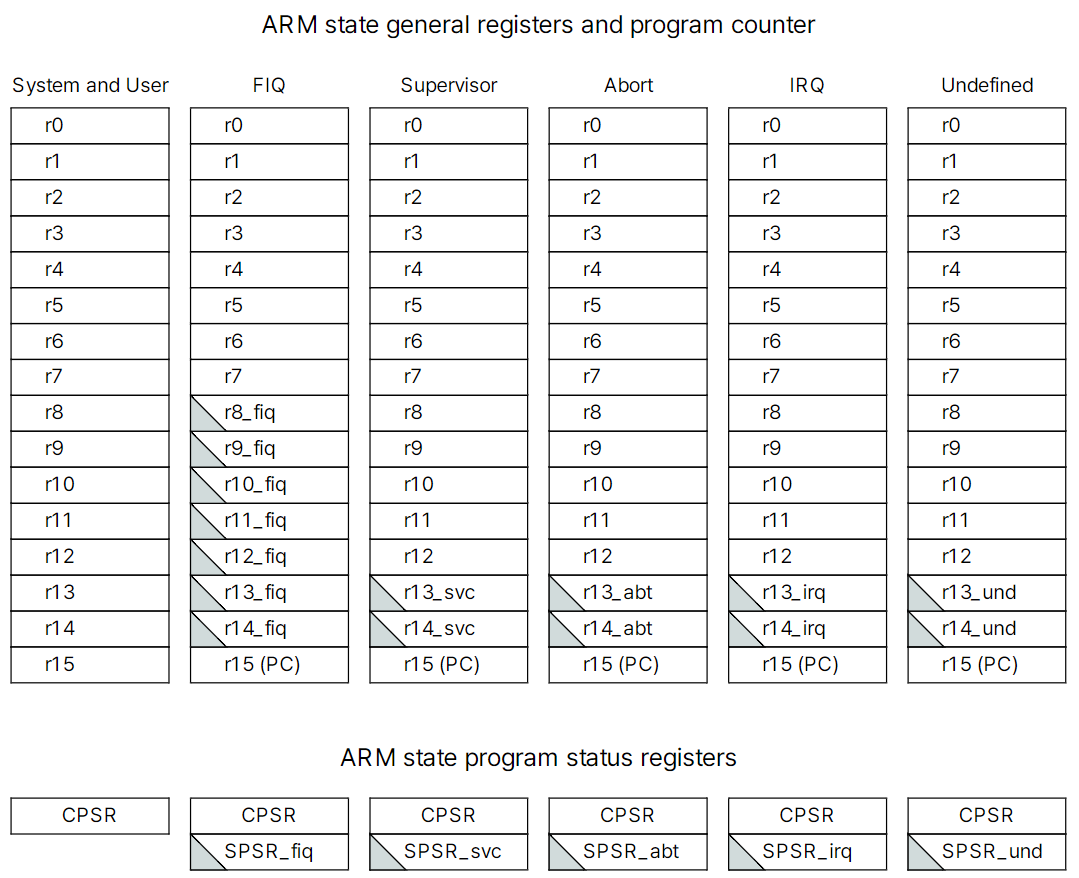
- USR(유저): R0~R14 = 15개
- FIQ: R8~R14 + SPSR_FIQ = 8개
- IRQ, SVC, ABT, UND: R13, R14, SPSR 각 3개씩 × 4 = 12개
- 15 + 8 + 12 + PC(R15) + CPSR = 37개. ARM Core는 37개의 레지스터를 가지고 있다.
3.2. PSR (Program Status Register)
- 2.1.절에서 우리는 각 모드에 따라 서로 다른 레지스터를 사용함을 배웠다.
- 하지만, PC, CPSR 처럼 공통적으로 사용하는 레지스터도 있었다.
- PSR은 현재 ARM core의 상태 및 수행중인 instruction의 정보등을 알려주는 특수한 레지스터다.
- PSR은 CPSR, SPSR로 나뉜다.
3.2.1. ARM9의 CPSR (Current PSR)
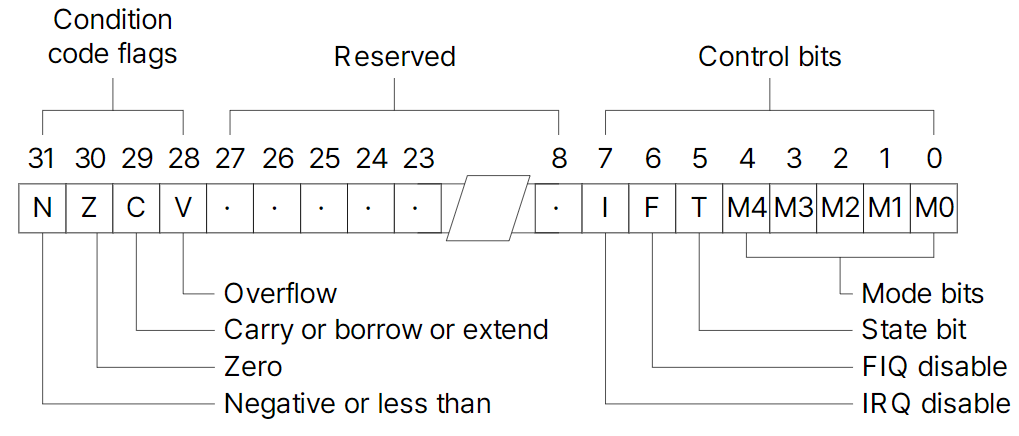
- Condition Flags: 현재 수행한 instruction에 대한 정보를 알려주는 부분이다.
- N(=Negative): 연산 결과가 마이너스일 때
1로 set. - Z(=Zero): 연산 결과가
0일 때1로 set. - C(=Carry): 연산 결과에서 자리 올림이 발생한 경우
1로 set. - V(=Overflow): 연산 결과가 32-bit를 넘어 sign-bit가 상실된 경우
1로 set.
- N(=Negative): 연산 결과가 마이너스일 때
- Control bits(Mask bits)
- I(=IRQ): IRQ 활성화/ 비활성화
- F(=FIQ): FIQ 활성화/ 비활성화
- T(=Thumb): THUMB 모드 활성화/ 비활성화
- Critical section 진입 시 인터럽트를 비활성화 해야 하는데 이때
MRS, MSR명령어를 사용해서 CPSR의 이쪽 bit를 수정해서 잠시 IRQ/FIQ를 비활성화 한다. Critical section에서 나올 때 다시 활성화 해준다.
([※] <Summary 2. SW Analyse>의 6절 RTOS에서 ‘critical section’에 대해 다뤘습니다. )
- Mode bits
3.2.2. SPSR (Saved PSR)
- 이름에서 유추할 수 있다시피 A 모드에서 B 모드로 전환할 때 이전 CPSR 값을 저장하는 백업 저장소다.
- 어떤 외부 이벤트(인터럽트, 시스템콜 등)로 인해 모드가 바뀔 때 이전 CPSR 값을 SPSR에 백업해둔 뒤 다시 돌아올 때 SPSR 값을 토대로 복구한다.
3.2.3. ARM11의 CPSR
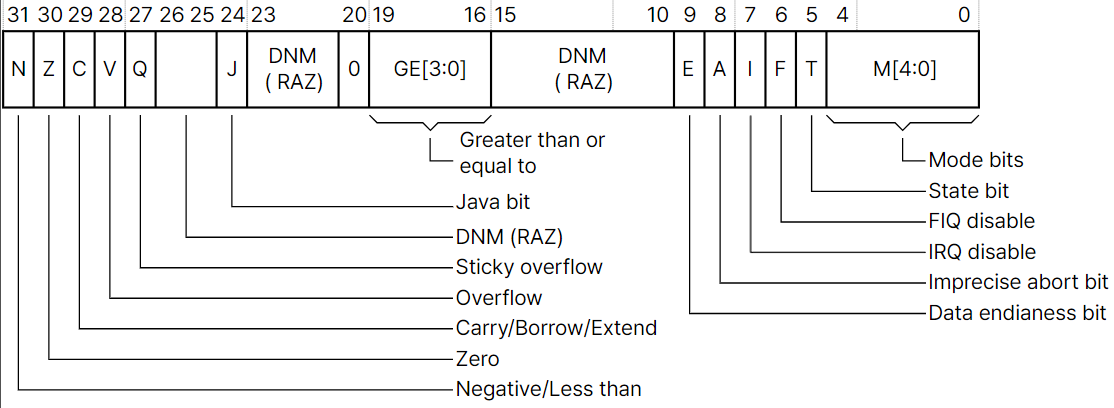
- ARM11로 발전하면서 표현해야 할 시스템의 상태도 다양해지면서 CPSR도 더 많은 정보를 담게 됐다.
- CPSR[27] = Q(Sticky Overflow) flag
- V(Overflow) flag와 유사한 역할을 하나 특정 명령어(QADD, QSUB 등)를 수행할 때 양의 최댓값 또는 음의 최솟값을 넘어가는지 (Saturation) 확인하는 역할을 한다.
- ‘Sticky’라는 수식어가 붙은 이유는 이 flag는 한 번
1로 set 되면 후속 연산에 상관없이 값을 계속 유지하기 때문이다. ([※] 방금 계산하다가 saturation이 발생했어요! 나중에라도 알아차려주세요! 라는 의미입니다.) - 개발자는 MRS 명령어로 Q flag를 확인해서 이전 연산에서 saturation이 발생했는지 검사한 뒤 MSR 명령어로 Q flag를 초기화시켜준다.
- CPSR[19:16] = GE(Greater than or Equat to) flags
- SIMD(Single Instruction Multiple Data) 명령어들의 도입과 함께 생긴 flag 들이다.
- SIMD 명령어에 따라 연산을 8-bit 또는 16-bit로 나눠서 계산한다.
- 각 부분의 연산결과 부호를 4개 bit에 각각 저장한다.
- 예)
SADD16 R0, R1, R2명령어 수행 결과가0x9000_9001이라면 16-bit씩 나눈0x9000과0x9001의 부호를 GE flags에 저장한다.
- CPSR[9] = E(Endianess) flag
- 메모리에 있는 데이터를 읽어올 때, ARM은 big endian과 little endian을 모두 지원한다.
- 개발자는 SETEND 명령어를 사용해 CPSR을 수정해서 endianess를 변경할 수 있다.
0이면 little endian,1이면 big endian으로 설정된다.
- CPSR[8] = A(Imprecise Data Abort mask) flag
- Exception 중 하나인 data abort를 어떻게 처리할지 결정하는 bit다.
0이면 data abort를 발생시키고,1이면 발생시키지 않는다.
- CPSR[27] = Q(Sticky Overflow) flag
4. R13 & R14
- ARM의 6가지 모드는 모두 R13, R14, R15(PC) 레지스터를 사용하는 걸 알 수 있다.
- 즉, 위 3가지 레지스터는 특수한 기능을 하는 레지스터임을 유추할 수 있다.
이중 R13과 R14 레지스터에 대해 알아보자.
4.1. R13 - 스택 포인터(Stack Pointer)
- 개발자는 알게 모르게 스택을 정말 많이 사용하고 있다. (i.e. 함수 call 및 return)
- ARM에서 제공하는 스택 관련 명령어는 다음과 같다.
- ARM: push -
STMDB, pop -LDMIA - THUMB: push -
PUSH, pop -POP
- ARM: push -
- R13은 스택 포인터로 사용되며 다음과 같은 과정을 거쳐 동작한다.
- 스택 포인터를
-0x4이동시킨다. (스택은 방향이 높은 주소에서 낮은 주소로 내려오기 때문이다.) - 데이터를 저장(push)한다.
- 스택포인터는 스택에서 가장 상위 데이터 주소를 가리킨 상태가 된다.
- 스택 포인터를
- 실제 사례를 보며 R13의 용도에 대해 더 자세히 알아보자.
- Push의 경우 -
STMDB R13!, {R3- R4, R14}- 서브루틴을 call 하는 요청이 들어오자
STMDM명령어가 사용된다. - 현재 R15(PC)값은
0x0288을 가리키고 있고, R13은0x30FF_D7E8을 가리키고 있다. - 명령어가 실행되면 R13을
-0x4주소로 옮긴 뒤 operand의 뒤에서부터 순서대로 R14, R4, R3 값을 push해 저장한다. - R13은
0x30FF_D7DC주소를 가리키며 연산이 종료된다.
- 서브루틴을 call 하는 요청이 들어오자
- Pop의 경우 -
LDMIA R13!, {R3-R4, PC}- 서브루틴이 끝나 return 하는 요청이 들어오자
LDMIA명령어가 사용된다. - 현재 R15(PC)값은
0x02C4를 가리키고 있고, R13은0x30FF_D7DC주소를 가리키고 있다. - 명령어가 실행되면 operand의 앞에서부터 순서대로 R3, R4, PC값으로 pop해 저장한다.
- R3 → R3, R4 → R4, R14 → PC
- PC값이 R14값으로 변경됐으므로 jump하고 R13은
0x30FF_D7E8을 가리키며 연산이 종료된다.
- 서브루틴이 끝나 return 하는 요청이 들어오자
- Push의 경우 -
- 각 모드별로 R13을 가지고 있기 때문에 서로 다른 R13 레지스터들은 각기 다른 주소를 가리킨다.
STACK_BASEADDR EQU 0x31000000 USER_STACK EQU (STACK_BASEADDR-0x3800) SVC_STACK EQU (STACK_BASEADDR-0x2800) UNDEF_STACK EQU (STACK_BASEADDR-0x2400) ABT_STACK EQU (STACK_BASEADDR-0x2000) IRQ_STACK EQU (STACK_BASEADDR-0x1000) FIQ_STACK EQU (STACK_BASEADDR-0x0) - 우리가 꼭 사용하는
main()함수도 startup.s의 마지막 부분에서STMDB명령어를 사용해서 main 함수로 이동한다. 즉, C언어는 반드시 스택을 사용해야 하는 이유다.
4.2. R14 - 링크 레지스터 (Link Register)
- R14는 링크 레지스터라고 부르며 복귀해야 할 주소를 저장하는 역할을 한다.
- 4.1.절에서 서브루틴 call 할 때
STMDB명령어를 사용해서 R14를 저장하고, return 할 때LDMIA명령어로 R14값을 PC에 저장하는 모습을 볼 수 있었다. R14가 복귀해야 할 주소를 담고 있었기 때문이다. - 또한, 항상 서브루틴으로 이동한다고 해서 스택에 복귀할 주소를 저장하는 건 아니다. 이럴 때는 R14값을 참고해서 복귀할 주소를 알 수 있다.
- 예시
func()함수를 호출하는 코드를 실행해 서브루틴으로 진입했으나 이번에는STMDB명령어가 없어 스택에 복귀 주소를 push하지 않는 모습을 볼 수 있다.- ARM core는 서브루틴에 진입할 때, R14에 서브루틴 호출 다음의 주소 값을 저장한다.
- 이것이 가능한 이유는 서브루틴에 진입할 때
BL명령어를 사용했기 때문이다. - BL 명령어는 Branch with Link(immediate)의 약자로 현재 PC값 +
0x4번지를 R14에 복귀주소로 저장한 뒤 지정된 operand 주소로 분기하는 명령어다.
- 이것이 가능한 이유는 서브루틴에 진입할 때
- 그리고
func()함수가 끝날 때MOV R14, PC명령어로 R14 값을 PC에 전달하는 모습을 확인할 수 있다.
5. 파이프라인
- CPU는 플래시메모리에서 메모리로 코드를 복사해온 뒤 메모리에서 읽어와서(Fetch) 해석하고(Decode) 실행하고(Execute) 연산 결과를 저장하는(Stroe) 과정을 거친다.
- 일련의 과정은 Fetch → Decode → Execute → Store로 요약할 수 있다.
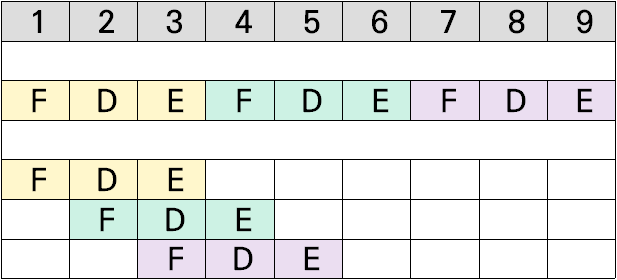
- 파이프라인은 각 단계마다 사용되는 자원이 다르기 때문에 서로 다른 명령어들을 중첩해서 성능을 높이는 방법이다.
- 위 그림을 보면 3개 명령어를 수행할 때 파이프라인을 사용하지 않았을 때는 9-cycle이 소요됐지만, 파이프라인을 사용하면 5-cycle밖에 소요되지 않아 성능이 증가함을 확인할 수 있다.
- Fetch → Decode → Execute는 가장 기초적인 단계이며 ARM 버전의 발전에 따라 3단계(ARM7) → 5단계(ARM9) → 8단계(ARM11) → 13단계(ARM Cortex-A)로 점점 많아지고 있다.
5.1. ARM7 Core의 파이프라인 (3단계)
- ARM7 Core는 위에서 말한 Fetch → Decode → Execute 3단계로 이뤄져 있다.
- 구체적으로는 다음과 같다.
- Fetch 단계: Instruction을 fetch 한다.
- Decode 단계: THUMB → ARM 압축해제, 해석(Decode), 사용할 레지스터 선택
- Execute 단계: 레지스터 읽기 + Shift + ALU + 레지스터 쓰기
- 하지만, ARM7 Core의 파이프라인에는 치명적인 단점이 있는데, 바로 메모리 접근에 대한 대책이 없다는 것이다.
- ARM 명령어는 ⓐ 레지스터-레지스터 명령어와 ⓑ 레지스터-메모리 명령어로 나뉘는데, 이 파이프라인은 ⓐ에만 초점이 맞춰져 있어서 ⓑ처럼 메모리에 접근해야 하는 경우 ‘읽어온 뒤 쓰는 작업’이 추가로 필요하다.
- 따라서 ⓑ 명령어들은 ‘Memory stage(읽어오기 단계)’와 ‘Write stage(쓰기 단계)’가 추가로 필요하다.
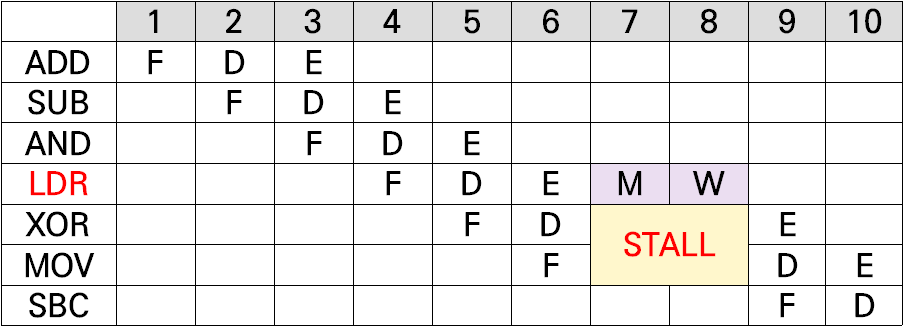
- 위 두 단계는 ARM7 Core 파이프라인에 포함되지 않는 단계이므로 ⓑ 명령어를 수행할 때마다 파이프라인이 멈춘다(Stall).
5.2. ARM9 Core의 파이프라인 (5단계)
- ARM7의 한계를 보완하기 위해 레지스터-메모리 명령어를 위한 ‘Memory stage’와 ‘Write stage’를 파이프라인에 추가해 총 5단계가 됐다.
5.3. ARM11 Core의 파이프라인 (8단계)
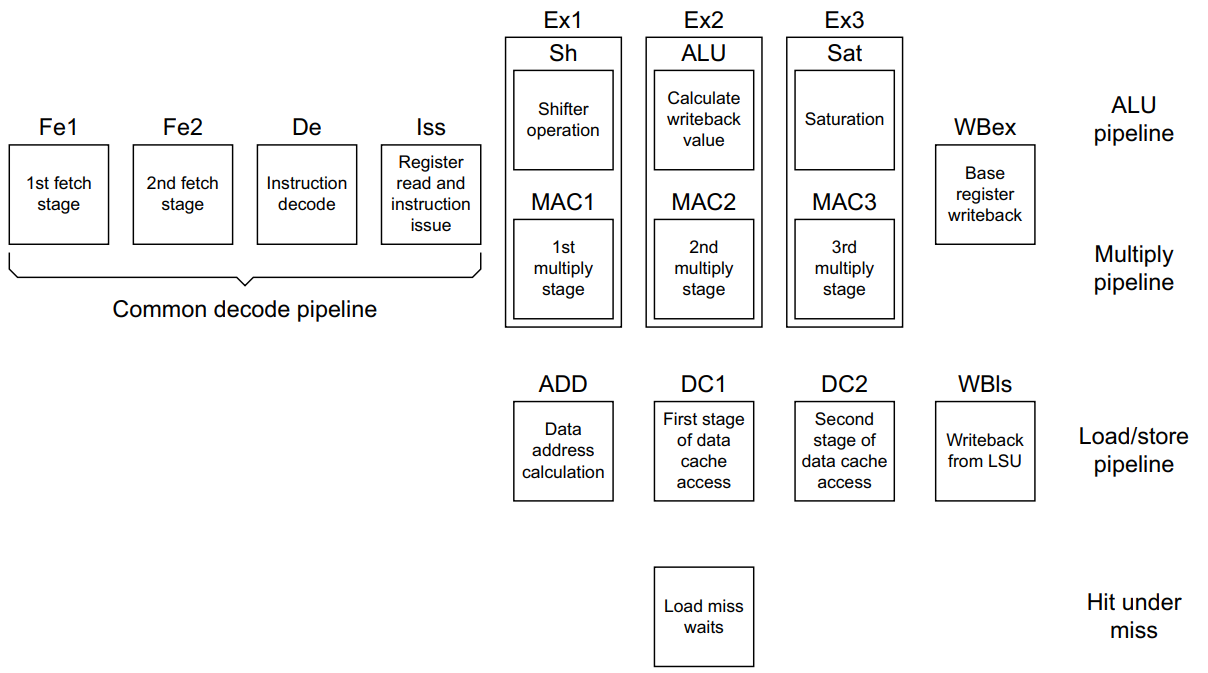
- Fetch가 2단계, Decode, Issue, Excute 4단계로 총 8단계로 구성된 파이프라인이다.
- [※] Fetch 1단계 (Fe1): 특정 주소(PC)에서 instruction을 가져오는 단계입니다.
- [※] Fetch 2단계 (Fe2): Branch prediction를 수행한 결과를 fetch 해오는 단계입니다.
- [※] Issue 단계 (Iss): 연산에 필요한 레지스터 값을 읽은 뒤 후속 단계(execute)를 위해 instruction을 알리는(issue) 단계입니다.
- Execute 단계가 4단계로 구성돼있는 이유는 각 명령어의 유형에 따라 파이프라인을 분리했기 때문이다.
- 산술 연산 명령어는 ALU pipeline에서 처리하고,
- 곱셈 연산 명령어는 MAC pipeline에서 처리하고,
- 메모리에 접근하는 LDR, STR 같은 명령어는 Load/store pipeline에서 처리한다.
- [※] D-Cache miss가 발생하면 메모리로부터 데이터를 가져와야 합니다. 이때 파이프라인이 stall 되서는 안 되므로 이러한 상황 자체를 파이프라인에 포함시킨 것이 Hit under miss 입니다. 메모리로부터 데이터를 load하는 동안 파이프라인 후속 단계는 이어서 진행됩니다. 하지만, 만일 이어진 instruction에서 요구하는 데이터가 지금 load 중인 데이터와 dependant(의존) 관계거나 또 cache miss가 발생한다면 그때는 stall이 발생합니다.
- 하지만, 이렇게 파이프라인 단계가 많아지고 길어지면 1개 명령어를 처리할 때 발생하는 delay 및 latency가 늘어나 시스템의 throughput에 큰 악영향이 발생한다.
- 문제를 해결하기 위해 ARM11부터 ‘Program Flow Prediction’방법을 도입해 기존 delay를 유지하면서 throughput은 향상시키는 데 성공했다.
- Dynamic/Static Branch prediction, Branch folding, Return stack, Forwarding 등 다양한 방법을 사용해서 분기를 예측하고 앞으로 진행될 instruction을 효율적으로 처리할 방법을 모색한다.
- BTAC(Branch Target Address Cache)의 기록을 살펴보며 현재 만난 branch의 결과가 과거에 있었는지, 실행되는 횟수가 많을지 적을지 등을 조사한 뒤 판단하는 것을 branch prediction 이라고 부른다.
- CP15의 CR의 Z-bit로 기능을 on/off 할 수 있다. On일 때 ACR(Auxiliary Control Register)에 의해 다양한 branch prediction 기능을 세부 설정할 수 있다.

임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.