
타겟 모듈의 메모리 구조를 어떻게 정의하느냐에 따라서 성능에 큰 영향을 미치게 되므로 중요하다.
10.1. Introduction
모든 개발자는 무한한 메모리를 거의 none latency로 access하길 원한다. 하지만, 빠른 메모리는 비용(cost)이 비싸다.
메모리 구조를 계층(hierarchical) 구조로 만들면 문제를 해결할 수 있다.
- 느리지만 대용량인 메모리에 모든 데이터를 저장한다.
- 용량은 더 적지만 속도는 빠른 메모리를 연결해서 바로바로 가지고 올 수 있도록 한다.
계층구조를 사용하면 속도 향상을 얻을 수 있는건 locality 덕분이다. Locality란, 어떤 주소의 데이터에 access 했다면, 가까운 시간(for, while loop)에 또는 인접한 주소(array)에 access할 가능성이 높음을 의미한다.
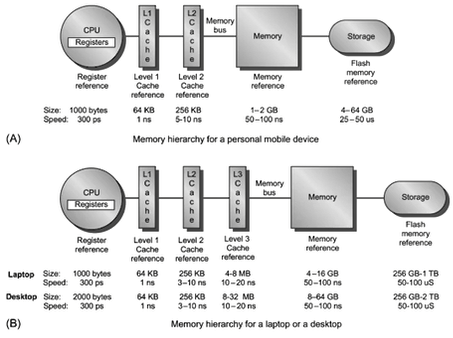
계층 구조를 구현하는 방법은 다양하지만, 일반적으로 핸드폰 같은 모바일 디바이스는 (a), 랩탑이나 데스크탑같은 pc는 (b)와 같은 계층 구조를 가지고 있다. CPU가 요구하는 정보를 L1 Cache에 빠르게 넣어서 즉시 사용하도록 하는 것이 성능 향상에 가장 중요하다.
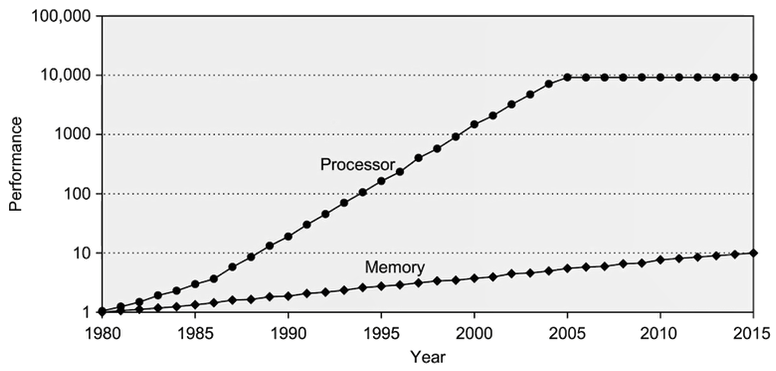
지난 40년간, CPU 프로세서의 성능은 기하급수적으로 증가했으나 메모리는 그 속도를 따라잡지 못해 bottleneck으로 작용하는 현상이 많이 발견되고 있다. 물리적인 속도차이를 극복하기 위한 방법으로 가장 유력한 후보가 바로 ‘계층구조’다.
- 계층구조에서는 memory 사이의 data의 이동이 block 단위로 이뤄진다. 1 block은 여러 개의 line(word)로 구성돼있다.
- 접근한 데이터가 상위계층에 이미 존재한다면, hit이라고 표현하며 hit에 성공하는 비율인 hit ratio이 메모리 계층구조의 성능을 결정하는 중요한 지표로 사용된다.
- 만일 miss가 발생한다면, 하위 계층에서 우리가 원하는 데이터를 찾게 되기 때문에 그만큼 시간이 더 소요된다. 이때 데이터를 찾았다면, 해당 데이터만 가지고 오는 것이 아니라 block 단위로 인접한 데이터들도 같이 가져와서 spatial locality를 충분히 활용한다.
- 결과적으로 메모리의 성능을 결정하는 것은 다음과 같다.
- 우리가 원하는 data를 얼마나 빠르게 상위 계층에서 찾을 수 있는가?
- Miss가 나지 않도록 (Hit ratio가 높도록) 가지고 올 수 있는가?
- Miss가 발생했을 때 얼마나 빠르게 새로운 block을 copying할 수 있는가?
10.2. Cache 방법
10.2.1. Direct Mapped Cache
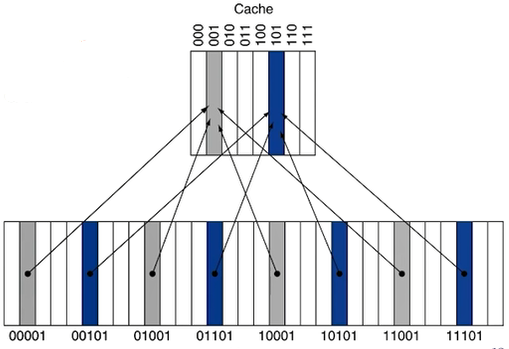
- 하위계층의 block마다 상위계층의 block에 mapping을 시켜서 저장될 장소를 지정해버리는 방법이다.
- 이때 찾은 데이터가 내가 원하는 주소인지는 아직 알 수 없다. 왜냐하면, cache의 해당 주소를 참조하고 있는 하위 계층의 block이 여러 개이기 때문이다. 따라서 cache에 저장할 때, data 뿐만 아니라 source의 주소도 함께 저장한다.
- Cache에 저장된 source의 주소와 mapping된 주소를 비교해서 같다면 hit, 다르다면 miss로 판단한다.
이때, 주소의 모든 bit를 비교하지 않고 상위 n-bit만 비교하는데 (그래도 되게끔 조합해서 mapping한다.) 이 n-bit를 tag라고 부른다. - 웃기는 건 tag로도 cache에 저장된 데이터가 유효한지 아닌지를 알 수 없다. 왜냐하면, 계층구조의 한계 때문이다. Cache는 memory에서 어떤 일이 벌어지는 지에 대해서는 모른다. Memory에 있는 데이터가 변경되서 cache에 저장된 데이터가 구닥다리 정보가 되버릴 가능성이 있다. 이를 해결하기 위해 Valid bit라는 1-bit 정보를 cache에 만들어서 메모리와 cache의 정보가 같아서 cache의 정보가 유효함을 알린다.
10.2.2. Associative Cache
저장될 위치가 정해져있던 direct mapped cache와는 달리, cache에 빈자리가 있다면 data를 넣는 방식이다.이때 모든 block을 검사하는 것은 cache라고 할 수 없기 때문에, 찾을 구역을 set로 나눠서 정한다.
글로 설명하면 너무 어려우니, 예제를 통해 과정을 알아보자.
0, 8, 0, 6, 8번 block에 access 한다고 생각해보자.
- Direct Mapped
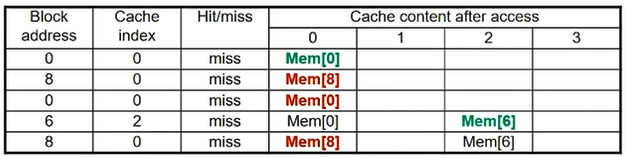
- Direct Mapped 방식에서는 정해진 공간에 원하는 데이터가 없을 경우에는 바로 그 자리를 다른 데이터로 교체하기 때문에 위 그림의 빨간색 처럼 불필요한 교체가 발생하게 된다. 왜냐하면 바로 다음에 방금 버린 데이터에 접근하기 때문이다.
- 2-way Set Associative
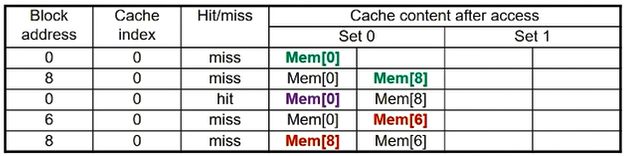
- 2-way set이므로 cache의 임의의 set에는 2개의 데이터를 저장할 수 있는 공간이 있다.
- 원래라면 교체가 발생했어야 하는
8번 block에 대한 access도set 0의 빈공간에 저장된다. - 하지만 안타깝게도
6번 block에 대한 access에서set 0의Mem[8]이 교체된다. 왜냐하면Mem[0]은 직전 cycle에 참조됐기 때문에 상대적으로 오래된 데이터인Mem[8]이 교체되는 것이다.
- Fully Associative
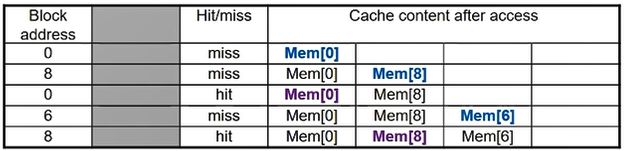
- Fully associative에서는 이제 cache의 모든 공간에 block을 임의로 저장할 수 있기 때문에 hit ratio가 상당히 높아진 것을 확인할 수 있다.
- 하지만, 하나의 데이터에 접근하기 위해 결국에는 앞에서부터 cache를 끝까지 전역검색해야 하므로 비효율적이다.
정리하자면, n-way를 증가시키면 hit ratio가 증가하지만 속도는 떨어지는 관계를 가진다.
- 수학적으로, 64KB cache를 기준으로 4-way, 8-way를 사용하는 것이 가장 효율적이라고 알려져있다.
- 여전히 임베디드 디바이스에서는 direct mapped cache를 사용하는 경우도 많다. (KB급 메모리를 가지고 있기 때문이다.)
10.3. Cache Miss 종류
- Compulsory miss: 어떤 메모리를 처음 첩근할 때는 무조건 miss가 난다. Initial miss라고도 부른다.
- Capacity miss: Cache의 양적 제한 때문에 어떤 데이터를 지웠는데 바로 다음에 그 데이터를 찾는 경우의 miss다.
- Confilct miss: Cache의 같은 주소를 참조하는 서로 다른 memory block을 계속 반복해서 참조하는 miss다.
10.4. Write Hit
CPU가 memory에 어떤 주소에 데이터를 write하겠다는 명령을 내렸고 hit 했을 때 어떻게 처리해야 할까?
10.4.1. Only Write
- Target 주소에 해당하는 cache만 update한다.
- Memory access를 하지 않으므로 속도가 빠르다
- 하지만, memory와 cache 사이에서 inconsistency가 발생한다는 치명적인 단점이 있다.
10.4.2. Write-Through
- Cache와 원본인 memory를 동시에 update해 동시성(consistency)을 보장한다.
- 하지만, memory에 access를 해야하므로 속도가 느려진다는 단점이 있다.
- Write buffer 방법을 사용하면 보완 가능하다!
- Cache와 memory와 독립적으로 운용되는 buffer를 외부에 둔다.
- Cache를 update한 뒤, memory에 access 하지 말고 buffer에 주소와 데이터를 저장해둔다.
- CPU는 그 이후로는 전혀 신경쓰지않고 계속 연산을 수행한다. Buffer는 독자적으로 움직이며 느린 속도로 memory를 update해서 consistency를 보장한다.
- 하지만 Write buffer 방법도 연속해서 같은 주소를 참조하는 연산이 있는 경우에는 consistency를 보장할 수 없다는 단점이 있다.
10.4.3. Write-Back
- Cache를 update하고, valid (dirty) bit를
1로 만들어서 “이 데이터는 memory랑 다름”을 표시한다. - 이후, 해당 cache 영역을 다른 데이터로 교체할 때 해당 bit를 확인해서 enable 여부에 따라 memory를 update 해준다.
10.5. Write Miss
이번에는 write할 때 cache에서 miss가 발생했다면 어떻게 처리해야 할까?
10.5.1. Write miss 대처 방법 종류
- Write allocation: Memory에 access해서 update를 한 뒤 cache로 가져오는 과정까지 수행한다.
- Write-Through에서는 hit 하든 안하든 memory에 access 하므로 상관없다.
- Write-Back은 일반적으로 allocation을 수행한다.
- Write around: Allocation을 수행하지 않는 경우다.
10.5.2. Replacement Policy in Conflict Situation
넣으려는 cache의 자리에 이미 다른 데이터가 존재하는 경우, 어떻게 replace를 할 것인지 정책을 결정해야 한다.
- Direct Mapped: Cache가 이 종류라면, 고민할 필요 없이 바로 교체하면 된다.
- n-Set Associative: 해당 set 중 valid bit가 disable한 데이터를 교체한다. 만일 없다면 임의로 하나를 고른다.
- Least-Recently Used (LRU): 가장 오랫동안 사용되지 않은 데이터를 교체한다. 다만, N이 너무 커진다면 tracking 자체가 너무 overhead가 되므로 2-way 또는 4-way에서 사용하는 것이 좋다. 가장 일반적으로 사용하는 정책이다.
- Random: 그냥 임의로 하나를 골라서 채워넣는 방법이다. 놀랍게도 N이 클 때는 LRU 만큼의 성능을 보인다.
