
11.1. Cache 성능 평가 방법
11.1.1. CPU time
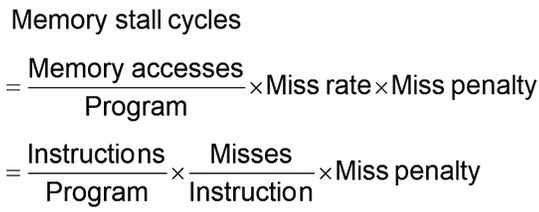
CPU가 동작하는 cpu time은 아래와 같은 두 가지 종류의 time으로 구성돼있다.
- Instruction execution cycles - 명령어가 수행되는 시간 (Cache hit 포함)
- Memory stall cycle - CPU가 멈춰있어야 하는 시간
- Cache miss로 인한 memory access 포함, 이를 miss penalty라고 한다.
11.1.2. 예제
I-cache miss rate = 2%, D-cache miss rate = 4%,
Miss penalty = 100cycles, Base CPI = 2, Load & Store are 36% of instructions.일 때 수행되는 시간을 구하시오.
- I-cache가 miss일 확률이 2%이므로 I-cache에서는 평균적으로 instruction마다 2-cycle이 소요된다.
- D-cache가 miss일 확률이 4%이므로 D-cache에서는 평균적으로 instruction 마다 4-cycle이 소요된다.
그러나Load & Store명령이 전체 instrunction의 36%이므로 4 * 0.36 = 1.44-cycle이 소요된다고 볼 수 있다. - 결과적으로, CPI는 2 + 2 + 1.44 = 5.44다.
- Base CPI가 2인 반면, 계산한 CPU는 5.44이므로 miss가 날 때 성능 저하가 얼마나 심한지 알 수 있다.
- I-cache는 매번 참조하는 반면, D-cache는 pipeline 생각해보면 사실 access 할 기회가 많지는 않기 때문에 D-cache의 panelty가 커도 실제로는 I-Cache의 panelty가 더 크게 작용하는 것도 확인할 수 있다. = I-cache의 hit ratio를 늘리는 것이 성능 개선에 크게 도움이 된다!
11.1.3. AMAT (Average Memory Access Time)
- Memory에 access할 때 소요되는 평균 시간은 다음과 같다.
- 로 계산할 수 있다.
- Cache hit일 경우 memory access가 불필요하므로 hit time을,
Cache miss일 경우 memory access가 필요하므로 miss에 대한 time 계산을 더해준다.
- Cache의 성능을 늘리기 위해서는 AMAT를 줄여야 하며 다음과 같은 방법을 사용한다.
- Hit time을 줄인다. 최대한 cache에서 빠르게 데이터를 가져올 수 있도록 만든다.
- Miss rate를 줄인다. 즉, Hit ratio를 높혀서 최대한 miss가 덜 발생하도록 한다.
- Miss panelty를 줄인다. 메모리의 주파수가 DDR3, 4, 5로 높아지면서 점점 동작주파수가 높아지는데, 이러면 panelty도 줄어든다.
11.2. Cache 성능 개선 방법
11.2.1. 기본 방법들
- Larger block size
- Block size를 늘리는 것이 compulsory miss를 줄이는 데 도움을 준다.
- 왜냐하면, block size가 늘어나면 cache에 공간이 줄어들게 되고 (물리적인 공간은 그대로지만, 데이터를 넣을 칸막이가 늘어나니까 칸막이 개수는 줄어드는 것, 서울 지하철 5호선 좌석과 2호선 좌석을 생각하면 됨), 그럼 compulsory miss 확률이 줄어든다.
- 하지만, block size가 커진다는 것은 miss panelty가 증가한다는 것과 같다. 왜냐하면, memory에서 가져올 block의 크기가 커졌기 때문이다.
- 근데 이게 의미가 있나…? 어차피 현대 DRAM의 block size는 거의 고정돼있는데
- Larger total cache capcity to reduce miss rate
- Miss rate를 줄이기 위해 cache 용량을 큼지막하게 만든다.
- Cache에 담긴 데이터 양이 많아지니 당연히 hit ratio는 오르겠지만, hit time과 전력 소모도 같이 오른다.
- Higher associativity
- Way 수를 늘리면, 하나의 set에 많은 데이터를 저장하므로 conflict miss 확률이 줄어든다.
- 하지만, 탐색해야 하는 cache line 개수가 많아지므로 hit time과 전력 소모도 함께 오른다.
- Higher number of cache levels
- Cache를 조금 더 계층적으로 세분화한다면, memory access time을 조금 더 줄일 수 있다.
- 하지만 전체 system의 복잡도와 전력 소모가 함께 증가한다.
- Giving priority to read misses over wrties
- 같은 miss여도 write miss와 read miss는 panelty가 다르다.
- Write miss는 inconsistency 문제를 제외하면, memory access에 조금 유연하게 대처할 수 있다. (우리는 앞서 access 회피를 위해 write-through, write-back, write-buffer 같은 전략을 배웠다.)
- 반면에 read miss는 CPU가 stall 돼버리므로 신속하게 처리해줘야 한다.
따라서 write miss와 read miss가 연속해서 발생한 경우라면, read miss를 우선 처리해주는 것이 좋다.
- Read miss에 더 높은 우선순위를 부여해서 write miss를 조금 뒤에 처리하도록 한다.
- 같은 miss여도 write miss와 read miss는 panelty가 다르다.
- Avoiding address translation in cache indexing
- Physical addr과 Virtual addr 사이의 translation을 제거한다.
- 즉, virtual address를 사용하지 않고 physical address만 사용하므로 조금 더 성능이 좋아진다.
- 근데 이 방법도 거의 안 쓸 것 같기는 하다…OS를 사용하는 이상 거의 무조건 PA와 VA를 구분할테니까…
OS를 사용하지 않는 임베디드 디바이스라면 유효한 방법일지도 모르겠다.
11.2.2. 심화 방법들
- Reduce Hit time - Way prediction
- Set associativity에서는 하나의 set의 모든 tag를 비교해야한다는 단점 아닌 단점이 있었다.
- 내가 찾으려는 data가 해당 set 내에서도 어느 way에 위치할 확률이 더 높은지를 미리 계산할 수 있다면 cache hit time을 조금 더 줄일 수 있다.
- 2-way에서는 예측 정확도가 90% 이상, 4-way에서는 80% 이상이어야 효과가 있다고 알려져있다.
- 90년대 중반부터 MIPS R10000에서 이미 사용된 기술이며 현재 ARM Cortex-A8에도 사용되고 있다.
- Increase bandwidth - pipelined cache, multibanked cache, non-blocking cache
- Reduce miss panelty - critical word first, write buffer
- Read miss가 발생했을 때, memory에서 block을 모두 옮겨야 한다.
- Block을 모두 copying하는 시간을 기다리지 말고, CPU가 요구하는 word만 우선적으로 넘겨준 뒤 나머지를 차근차근 옮기는 방법을 critical word first 라고 한다.
- 위에서 배웠던 write buffer 방법을 사용한다.
- Reduce miss rate - compiler optimization
- Parallelization - HW or compiler prefetching
11.2.3. 성능지표 (참고용)
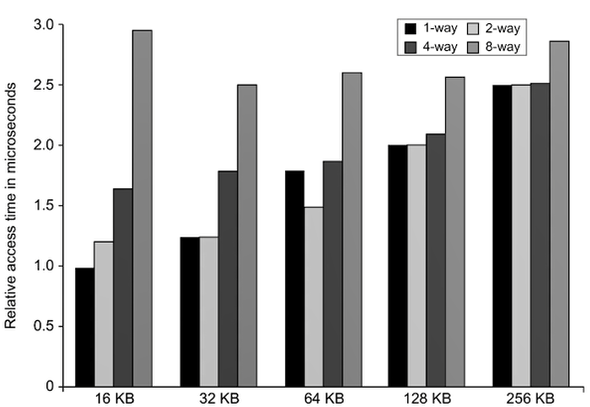
- Cache의 size가 증가할수록 hit time이 증가하기 때문에 way 사이의 성능 차이가 적어진다.
- Way가 증가할수록 1회 cache 접근 시 탐색해야 하는 line 개수가 늘어나므로 hit time이 증가한다.
- 2-way 또는 4-way를 쓰는 것이 좋은 것을 확인할 수 있다.

임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.