4.1. Stored Program Concept
메모리에 데이터와 프로그램을 저장하고 CPU는 그것을 읽어서 연산만 수행하는 개념.
-
Fetch → Decode → Execute → Store :: 반드시 이 cycle은 머릿속에 넣어두자!
-
메모리로부터 정의된 instruction을 가져와서 수행하고, 다음 instruction을 가져와서 수행하고…
4.2. Instruction set을 design 할 때 고려할 사항
- Operands를 어디에 저장할 것인가? - register, memory, stack, acc …
- Operands 몇 개까지 허용할 것인가? - 0, 1, 2 or 3
- Operands의 위치를 어떻게 나타낼 것인가? - Direct, Immediate, Indirect …
- Operands의 종류와 크기를 어디까지 지원할 것인가? - byte, int, float, double …
- 어떤 operation을 지원할 것인가? - add, sub, mul, div, mov, comp …
4.3. ISA 구조
add r0, r1, r3 라는 명령줄이 있다고 가정하자.
- Operation (Op code) :
add같은 수행할 연산을 의미 - Operands :
r1, r3같은 피연산자를 의미. register, memory 또는 외부에 있을 수 있다. - Place to stroe result :
r0, 연산결과를 저장할 위치 지정 - Location of next instruction : 순차적으로 실행되지 않을 때, 다음 분기가 시작되는 지점을 명시해줄 수 있다.
4.4. ISA의 Operantion 범주
-
Data movement
데이터를 source에서 destination으로 옮기거나 복사하는 것을 목표로 하는 operation이다.
- Load : src는 memory, dst는 register, 데이터 가져오는 명령어
- Store : src는 register, dst는 memory, 데이터 저장하는 명령어
- Move : src는 register, dst도 register, 데이터 위치를 이동하는 명령어
-
Arithmetic and Logic (ALU)
Operands 사이에서 특정 연산을 수행하고 destination에 저장하는 것을 목표로 하는 operation이다.
- ADD
- SUB
- Shift
- …
-
Branch (or Control flow)
순차적인 흐름에서 벗어나서 다른 곳으로 분기할 때 사용하는 operation이다.
- BEQ
- …
4.5. Address Instrunctions
-
4-address instrunction
- 4-address instruction은 연산 결과를 register에 저장하지 않고 memory에 저장한다.
- CPU에 어떤 정보도 저장하지 않고, 오로지 연산만 수행한다.
- 일반형은
OPCode Res, Op1, Op2, NextInst이다.Op1과Op2사이에서OPCode연산을 수행한 뒤 결과를Res에 저장한다.Res와Op1,Op2는 모두 memory의 주소를 가리킨다.- Register를 일절 사용하지 않으므로 당연히 다음에 수행할 instruction의 주소값을 담고있는
PCregister도 없다.
따라서 연산이 종료된 다음 번에 실행할 instruction의 주소를NextInst에 명시해줘야 한다.
- Instruction의 크기가 커진다는 단점이 있다.
-
3-Address Instruction
- CPU 내부에
PCregister가 있는 상황을 가정하면 위 instrunction에서NextInst가 불필요하다. - RISC를 사용하는 ISA에서는 가장 일반적으로 많이 사용하는 instruction format이다.
- 일반형은
OPCode Res, Op1, Op2이다. - Branch 하는 경우에는
PC의 값을 바꾸는 명령어(branch,jump)를 사용한다. - 한 번의 명령을 수행할 때 메모리 접근 횟수가 여전히 많다는 단점이 있다.
- Operation fetch 1번, 2번의 operand fetch, destination에 저장 1번.
- 즉, 최소 4회의 memory access가 발생한다. (Memory traffic 증가)
- Memory는 CPU보다 훨씬 느리기 때문에 최대한 memory access를 줄이기 위해 register를 적극 활용한다.
- CPU와 ISA가 발전하면서 조금이라도 CPU 내부에 register를 확보하려는 방향으로 노력하고 있다.
- CPU 내부에
-
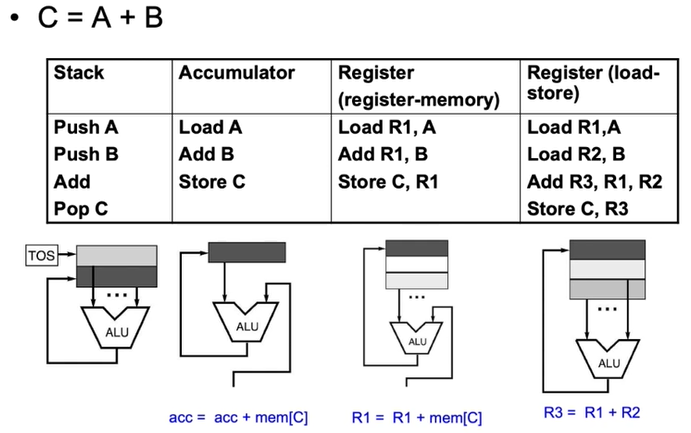
2-Address Instruction
-
일반형은
OPCode Op2, Op1d이다. -
연산 결과를 따로 저장하지 않고, operand 중 하나인
Op2에 덮어쓴다. -
하지만,
A + B = C를C = C + A,C = C + B이렇게 두 번에 나눠서 진행해야하므로 같은 연산을 하더라도 3-address instruction보다 많은 instruction이 필요하다.
-
-
1-Address Instruction (Accumulator Machine)
-
CPU 내부에
ACC(Accumulator) register가 포함된다. 연산 중간 결과가 이곳에 저장된다. -
일반형은
OPCode Op1이다. -
Op1과ACC사이의OPCode연산을 수행한 결과를 다시ACC에 덮어씌워 저장한다. -
Accumulator에 접근하기 위한 명령어 (
LDA,STA)가 필요하다. -
같은 결과를 만들기위한 instruction의 개수가 더욱 늘어난다는 단점이 있다.
-
ACC에 너무 자주 접근하기 때문에 접근하는 행위 자체가 하나의 bottleneck이 된다. CPU 성능을 올리기 병렬화나 파이프라이닝을 이용하는데,ACC의 구조적 특징으로 인해 이 수혜를 받을 수 없다. -
하나의 operand를 memory에서 가져와야 하기 때문에 여전히 memory traffic이 있다.
-
-
0-Address Instrunction (Stack Machine)
- Stack에 push와 pop을 하면서 연산하는 방법이다.
A * B - (A + C * B)를 구현한다고 가정하면 다음과 같다.push A→push B→mulpush A→push C→push B→mul→add→sub
- 명령어가 compact 해지므로 density가 증가한다.
- 병렬성과 파이프라이닝을 전혀 이용할 수 없는 구조가 된다.
- 원하는 데이터가 stack의 아랫부분에 있을 때 비효율적인 상황이 발생한다.
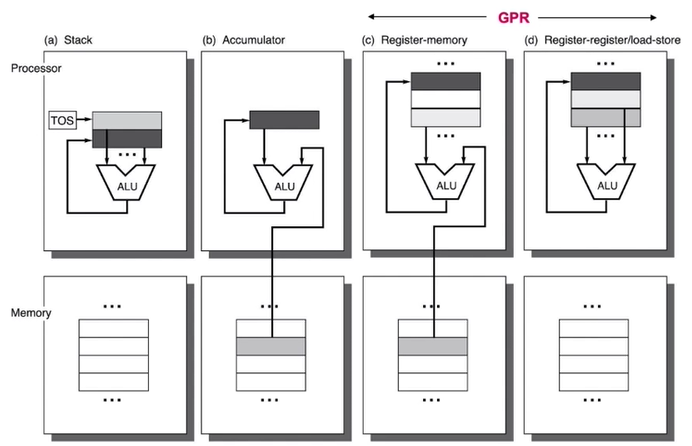
4.6. General Perpose Register (GPR) Machine
CPU 내부에 여러 개의 register를 둬서 저장공간을 확보하는 방법으로 요즘은 전부 이거 사용한다. Register와 memory 사이의 data를 이동시키는 명령어가 추가로 필요하다.
Operand 2개를 사용할 때, 하나는 register에 있고 다른 하나는 memory에 있으면 두 operand를 load 하는 데 소요되는 시간이 서로 달라서 같은 instruction을 수행해도 소요되는 시간이 달라질 여지가 있다. 이는 당장에는 문제가 되지 않지만, CPU를 최적화하는 여러 기법을 적용할 때 방해요소로 작용한다. 물론 이를 해결하는 수많은 방법이 연구돼 적용됐다.
4.7. Load-store Architecture
- 모든 연산을 최대한 register에서 해결하는 아키텍처를 말한다.
장점
- 가장 간단하고 고정된 길이의 instruction을 사용한다.
- 따라서 구조가 일반화돼 간단해지고, 대부분의 연산이 비슷한 시간(clock)이 소요된다고 예상할 수 있다.
- 파이프라이닝이라 superscalar 같은 CPU 성능 최적화 기법을 비교적 자유롭게 적용할 수 있다.
단점
- 같은 결과에 필요한 연산의 개수가 많다.
- 제한적인 register의 개수로 인해 각 레지스터 마다 내용물을 memory로 빼거나 저장하는 연산이 필요하다.
결론 (정리 그림)