
6.1. RISC-V Encoding
RISC-V의 모든 instruction은 32-bit, 1 WORD 길이로 일반화돼있다. 아래를 보면 모든 Instruction이 우리가 읽기에 친숙한 구조가 아닌데, 왜냐하면 RISC-V가 Little endian이기 때문이다.
6.1.1. R-format instructions
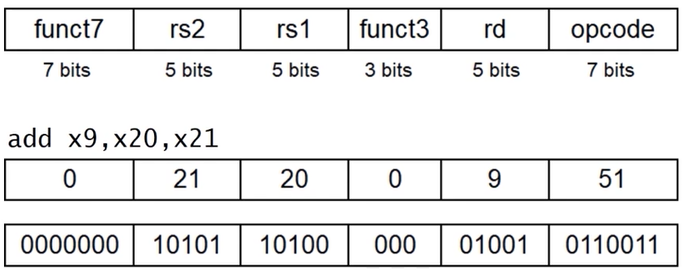
opcode: Instruction operation coderd: 연산결과가 저장될 레지스터 번호 (Destination register number)funct3: 3-bit 짜리 function coders1: 연산에 사용될 operand register number 1rs2: 연산에 사용될 operand register number 2funct7: 7-bit 짜리 function code,funct3과 합친 10-bit가 operation의 세부적인 기능을 결정한다.
6.1.2. I-format instructions

- Immediate instruction은 memory access가 불필요하다.
- R-format의 opcode~rs1 까지는 동일한 형식이고, rs2가 불필요하므로 rs2 + funct7 영역을 합친 12-bit로 상수를 표현한다.
- 만일 12-bit 보다 큰 값을 상수로 사용하고 싶다면, 지금 형식으로는 불가능하다. (후술함)
6.1.3. S-format instruction

- Store 명령에는 destination이 필요없기 때문에
rd영역을 상수를 표현하기 위한 추가 5-bit 영역으로 활용한다. - 상수를 저장하는 것이 아니라면
rs2에 있는 데이터를rs1에 저장한다.
6.1.4. Shift Operation

-
Shift 연산은 operand가 2개일 필요가 없으므로
rs2가immed로 대체됐다. -
immed는 몇 bit shift 할 지 나타내는 상수이며rs2가 5-bit 였던 것에 비해immed는 6-bit다.- 기존의 32-bit 아키텍처는 5-bit (2^5 = 32)로 다룰 수 있었다.
- 64-bit 아키텍처로 바뀌면서
immed가 1bit 더 필요하게 됐다.
-
남은 칸은 6-bit 이므로
funct6라는 이름의 칸이 있다. -
왼쪽 shift는
slli라고 표현하고i-bit 만큼 왼쪽으로 이동한다. -
오른쪽 shift는
srli라고 표현하고i-bit 만큼 오른쪽으로 이동한다.
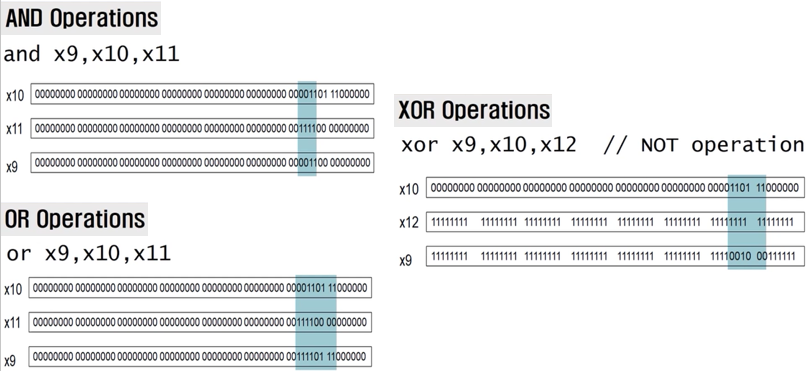
6.1.5. Logic Operations
6.1.6. Conditional operations
- if-else 문 처럼 분기를 형성할 때 사용하는 operation이다.
- 여러 명령어가 있고, 대표적으로
beq(= Branch if equal, ==)과bne(=Branch if not equal, !=)이 있다. blt(= Branch less than),bgt(= Branch greater than)도 있다.
ble(= Branch less than or equal),bge(= Branch greater than or equal)도 있다.- Signed number는 위 명령어들을 사용하면 되고, unsigned number는 끝에
u를 붙힌 명령어를 사용하면 된다.
if (i == j) f = g + h;
else f = g - h;위와 같은 C언어 코드에서 f부터 차례대로 x19에 저장돼있다고 가정하면,
bne x22, x23, Else
add x19, x20, x21
beq x0, x0, Exit ;;; 무조건 진입한다.
Else: sub x19, x20, 21
Exit: ...- 반드시 이렇게 컴파일 되는 건 아니고 한 가지 예시일 뿐이다.
x22(=i)와x23(=j)를 비교하고, 같지 않다면Else라는 이름의 분기문으로 진입한다.
Else에서는x19(=f)에x20(=g)에서x21(=h)를 뺀 결과를 저장한 뒤Exit로 진입한다.- 같다면 순차적으로 진행한다.
x19(=f)에x20(=g)에서x21(=h)를 더한 결과를 저장한다.
beq x0, x0는 무조건 참이다. 따라서Else라벨을 지나서 바로Exit로 넘어간다.
while (A[i] == k) i++;위와 같은 C언어 코드에서 i는 x22에, k는 x24에, A는 x25에 저장돼있다고 가정하면,
Loop: slli x10, x22, 3
add x10, x10, x25
ld x9, 0(x10)
bne x9, x24, Exit
addi x22, x22, 1
beq x0, x0, Loop
Exit: ...i를1증가시켜주는 이유는A의 다음 인덱스를 가리키기 위해서다.
따라서 address로는 8-bit 증가해야 하므로i를 2³만큼, 3-bit만큼 shift left 해줘야 한다.i를8증가시켜준 값을x10이라는 temporary register에 저장한다.x25(=A = A[0])에x10을 더해주면 다음 인덱스의 주소가 되고 이를 다시x10에 저장한다.- Displacement addressing을 사용해서
x10으로 부터 0bit 떨어진 곳의 값을x9에 저장한다.
즉,x10에 저장된 주소 안의 값 (=A[i])을x9에 저장한다. - 만일
x9 != x24라면, while문을 그만해야 하므로Exit:로 넘어가서 반복문을 종료한다. - 만일 같다면, immediate instruction으로 상수
1을i에 더한다. beq x0, x0은 무조건 진입하는 unconditional statement이므로 다시Loop:로 돌아가서 위 과정을 반복한다.
6.1.7. Procedure call Operations
함수같은 프로시저를 호출할 때 발생하는 operation을 의미하고 과정은 다음과 같다.
x10 ~ x17register에 input parameter들을 저장한다.- 실행 흐름을 프로시저로 넘긴다.
- 프로시저에서 사용할 공간을 확보한다.
- 프로시저를 수행한다.
- 프로시저 결과값(= return value)을 register에 저장한다.
x1에는 프로시저를 호출한 (= 돌아갈) 주소가 저장돼있으므로 그쪽으로 return 한다.
위 과정을 컴파일하면 다음과 같다.
jal x1, label로x1에PC + 1값을 저장해서 돌아갈 주소를 확보하고label로 branch한다.jalr x0, 0(x1)으로x1에 저장된 돌아갈 주소로 branch 한다.
이때x0는rd역할을 하므로 경우에 따라 상수값을 넣어서 다른 곳으로 이동할 수도 있다.
long long procedure (long long g, long long h,long long i, long long j) {
long long f = (g + h) - (i + j);
return f;
}위 코드를 컴파일하면 아래와 같다.
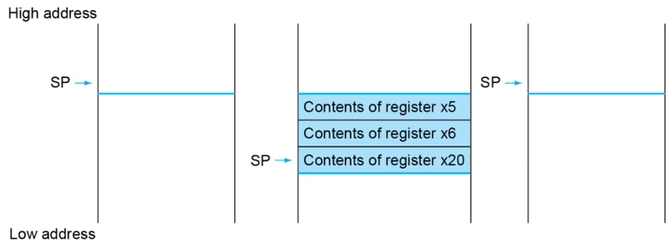
;;; g부터 x10에 저장된다. f는 x20에 저장된다. x5, 6은 임시공간.
procedure: addi sp, sp, -24 ;;; Stack pointer를 3-Byte 확보.
sd x5, 16(sp) ;;; 임시공간 x5 공간확보
sd x6, 8(sp) ;;; 임시공간 x6 공간확보
sd x20, 0(sp) ;;; local variable f를 위한 공간확보
add x5, x10, x11 ;;; g + h
add x6, x12, x13 ;;; i + j
sub x20, x5, x6 ;;; f 구함
addi x10, x20, 0 ;;; x10에 return value 저장
ld x20, 0(sp) ;;; 저장해뒀던 x20값 백업
ld x6, 8(sp) ;;; 저장해뒀던 x6값 백업
ld x5, 16(sp) ;;; 저장해뒀던 x5값 백업
addi sp, sp, 24 ;;; Stack pointer 복구
jalr x0, 0(x1) ;;; 돌아갈 주소로 RETURN- 주석에 상세한 설명을 적었으므로 따로 긴 부가설명은 생략함.
- 하나 더 알아둘 점은, 앞서 RISC-V의 register는 사용처가 정해져있다고 했는데, 일부 register (
x8, x9, x18~x27)는 사용 후 다시 원래 값으로 복원시켜줘야 함. 이때 위와 같이 stack을 사용할 수 있음.
마이크로 아키텍처를 설계할 때 어떤 부분에 대해 초점을 맞췄고, 설계된 ISA가 어떤 목적에 따라 만들어졌는지 위주로 공부하자.

임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.