
8.1. Pipeline 개요
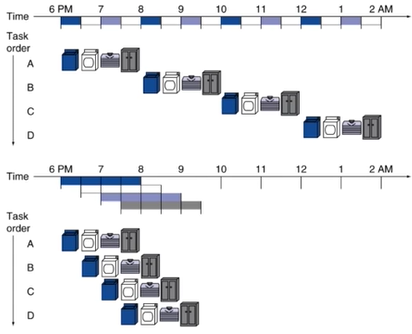
- Pipelining은 여러 작업들을 병렬(pallerism)성을 이용해서 빠르게 작업하는 방법을 말한다.
- 위 그림에서, 4가지 소작업으로 구성된 4개 작업을 순차적으로 실행한다면 총 8시간이 소요된다.
- 하지만, pipelining을 사용해서, 각 작업의 소작업이 끝날 때마다 다른 작업을 수행한다면 3.5시간이 소요된다.
- 속도는 2.3배 증가하고, 만일 작업이 4개가 아니라 n개로 늘어난다면, 속도는 최대 4배까지 늘어난다.
- 즉, 작업 4개를 1개 수행할 시간에 마칠 수 있다.
8.2. RISC-V Pipeline
8.2.1. Background
RISC-V의 pipelining을 배우기 앞서, instruction이 수행되는 과정을 단계별로 나눠보면 아래 다섯 가지로 나눌 수 있다.
IF: Instruction Fertch from memory
Instruction memory에서 instruction을 fetch하는 cycle을 의미한다.ID: Instruction decode & register read
Instruction을 decode해서 operand register를 읽는 cycle을 의미한다.EX: Execute operation or calculate address
Operation을 수행하고 address를 계산한다. (PC 계산이라던지…)MEM: Access memory operand
Operand 또는 destination에 address가 있을 때 memory에 access하는 cycle을 의미한다.WB: Write result back to register
register에 연산 결과를 기록하는 cycle을 의미한다.
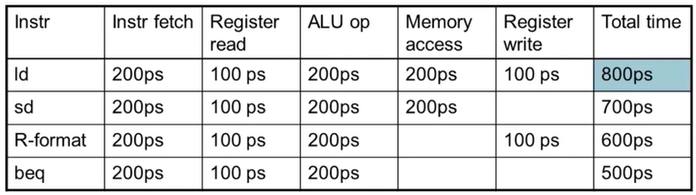
Datasheet에 따르면, pipeline을 사용하지 않을 경우 대표적인 4가지 연산에 소요되는 시간은 위와 같다.
ld는 모든 과정을 전부 거치게된다. (그래서 최대한ld를 줄이기 위해 register에서 연산하려고 하는거다.)sd는rd같이 destination register에 data를 기록하지 않기 때문에Register Write이 빠진다.R-format은rs1,rs2사이의 연산이기 때문에 memory에 load하는 과정이 생략된다. 바로 이게 load & store 아키텍처의 장점이다!beq와 같은 branch 연관 연산 역시 memory access가 불필요하고 register에 write하는 과정이 필요없으며 ALU의 sub 연산 결과로zero핀이high인지 여부만 확인하므로 빠르다.
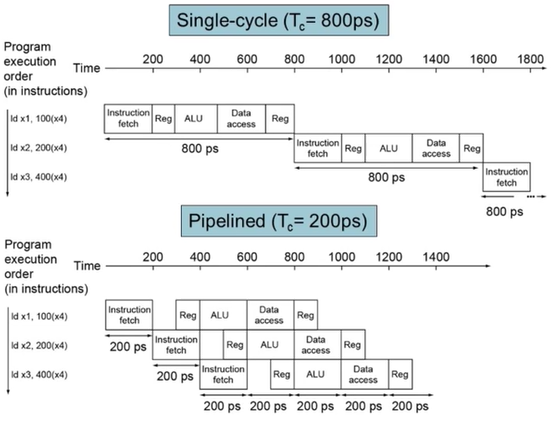
- Throughtput : 단위시간동안에 몇 개의 instruction을 처리했는지를 나타내는 지표.
- Delay(=latency) : Instruction이 queue에 들어와서 기다리다가 처리되기까지의 시간.
8.2.2. RISC-V는 Pipelining 하기 좋다!
이유는 아래와 같이 3가지 있다.
- 모든 instruction이 32-bit로 고정돼있다.
- Instruction의 fetch-decode-execute-store을 1-cycle에 수행하기 좋다.
- 다음에 올 instruction의 길이를 확정적으로 알고 있으므로 어디서 부터 어디까지 읽어야 하는지 매번 알아봐야 할 필요가 없다.
- Instruction의 개수가 적으로 format이 일반화돼있다.
- 단일 step으로 decode할 수 있다.
- 사람도 읽기 편하고 컴파일러도 효율적으로 컴파일 할 수 있다.
- Load-store architecture을 선택했다.
- memory access에 address를 ALU로 계산하게 된다.
- 따라서 계산 후 접근하는 구조가 만들어져서 pipelining이 용이하다.
- 왜냐하면, 한쪽에서 memory에 접근하는 동안 한쪽에서는 계산하고 한쪽에서는 decode하고 한쪽에서는 fetch하고 있으면 되기 때문이다.
즉, ISA를 설계할 때 pipelining을 고려했기 때문에 RISC-V가 이런 특징을 가질 수 있었던 것이다.
8.3. Hazards
8.3.1. Hazards 정의
Pipelining은 instruction을 쉬지않고 매 cycle마다 pipe에 넣어줘야 한다. 이게 불가능할 때 우리는 ‘Hazard가 발생했다.’고 표현한다. Hazard는 resource confilict situation 이라고도 부르며, 시스템의 throughput을 떨어트린다.
8.3.2. Hazards의 종류
-
Structure Hazard
-
동시의 두 하드웨어가 같은 address의 data에 access 하려는 hazard다.
-
Fetch-decode-execute-store 구조에서 Fetch와 store은 memory에 access 하게 된다.
1, 2, 3, 4로 끝나면 문제없지만,1, 2, 3, 4, 1, 2, 3 ...이라면,4와1이 연속하게 된다.
-
즉, memory access가 store에서, fetch에서 연속적으로 발생한다.
-
이번 instruction의 store은 다음 instruction의 fetch를 stall 시킬 가능성이 있다.
-
그러므로, pipelined datapath는 서로 독립적인 instruction, data memory(or cache)에 접근해야 한다.
-
-
Data Hazard
- 이번 instruction을 수행하기 위해 이전 instruction의 결과가 필요한 경우다. 의존성이 있다고 말한다.
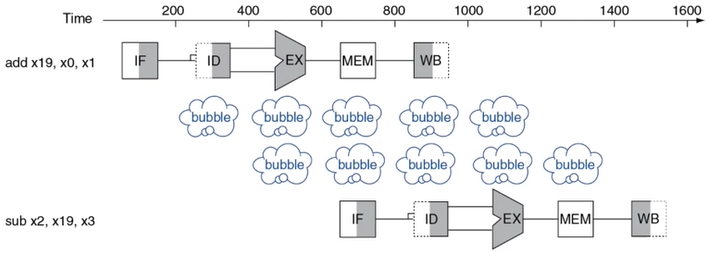 + `x19`를 계산해야만 아래 명령어의 operand로 사용할 수 있는 전형적인 data hazard다.
+ `EX` 단계에서 `x19`가 계산되고 나서야 다음 instruction의 `IF`가 시작된다.
+ **Fowarding (=Bypassing)**을 사용하면 이 문제를 해결할 수 있다.
+
+ `x19`를 계산해야만 아래 명령어의 operand로 사용할 수 있는 전형적인 data hazard다.
+ `EX` 단계에서 `x19`가 계산되고 나서야 다음 instruction의 `IF`가 시작된다.
+ **Fowarding (=Bypassing)**을 사용하면 이 문제를 해결할 수 있다.
+ 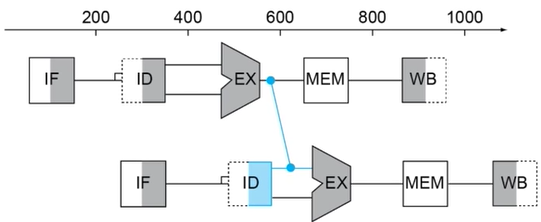 + 다음 instruction의 `EX`가 시작되기 전에 이전 instruction의 `EX` 결과를 받아올 방법이 있다면 data hazard를 극복할 수 있다.
+ 비록 이번 instruction의 `ID`는 의미없는 쓰레기값을 갖겠지만 `EX` 실행 전에 제대로 된 값을 갖게 될 테니까 문제없다.
+
+ 다음 instruction의 `EX`가 시작되기 전에 이전 instruction의 `EX` 결과를 받아올 방법이 있다면 data hazard를 극복할 수 있다.
+ 비록 이번 instruction의 `ID`는 의미없는 쓰레기값을 갖겠지만 `EX` 실행 전에 제대로 된 값을 갖게 될 테니까 문제없다.
+ 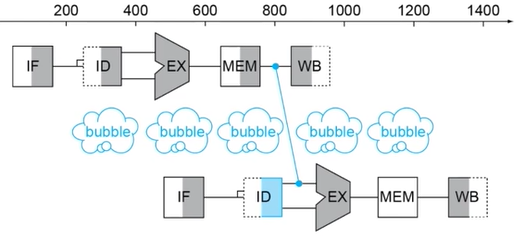 + 하지만, 제한시간 내에도 이전 instruction의 `EX`가 계산되지 않았을 경우에는 forwarding을 사용하더라도 어쩔 수 없이 bubble이 생기게 된다. (그래도 사용 안하는 것보다는 빠르다.)
+ 하지만, 제한시간 내에도 이전 instruction의 `EX`가 계산되지 않았을 경우에는 forwarding을 사용하더라도 어쩔 수 없이 bubble이 생기게 된다. (그래도 사용 안하는 것보다는 빠르다.)
-
Control Hazard
- Branch나 Jump 같이 실행흐름을 변경하는 명령어를 수행할 땐 target address를 계산한 뒤 PC에 저장하게 되는데, 이전 instruction에 의해 PC값이 변경되는 경우 원치 않는 곳으로 실행흐름이 변경될 수 있다.
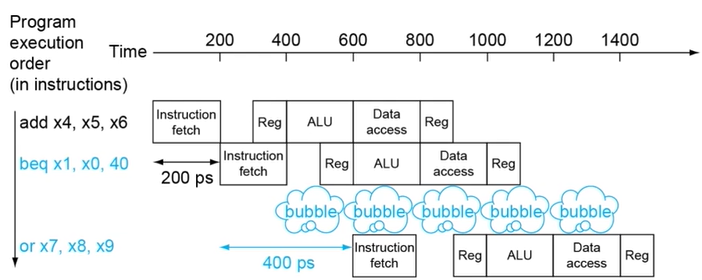
- 따라서 RISC-V에서는 다음 instruction의 decode 단계를 의도적으로 한 번 쉬어준 다음 (bubble 하나 추가), 안정적으로 target address가 ALU에 의해 계산됐을 때 비로소
ID를 수행한다.
8.3.3. 결론
- Pipelining은 throughput을 올리기 위한 아주 좋은 방법이다.
- 여러 instruction은 병렬로 수행한다.
- 하지만, latency는 그대로라는 점을 잊지말자.
- “Pipelining을 사용하면 언제나 성능향상이 가능하다”라는 말을 함부로 할 수 없다.
- Hazard가 있기 때문이다 - Structure, Data, Control
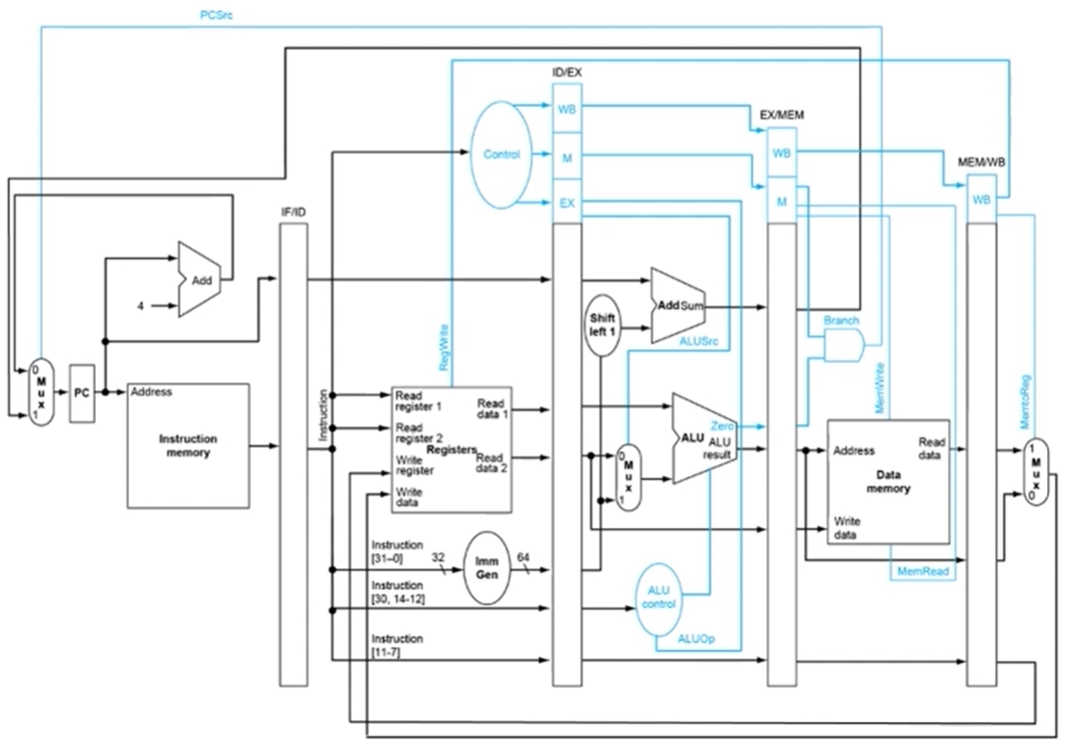
8.4. RISC-V Pipelined Datapath and Controlpath
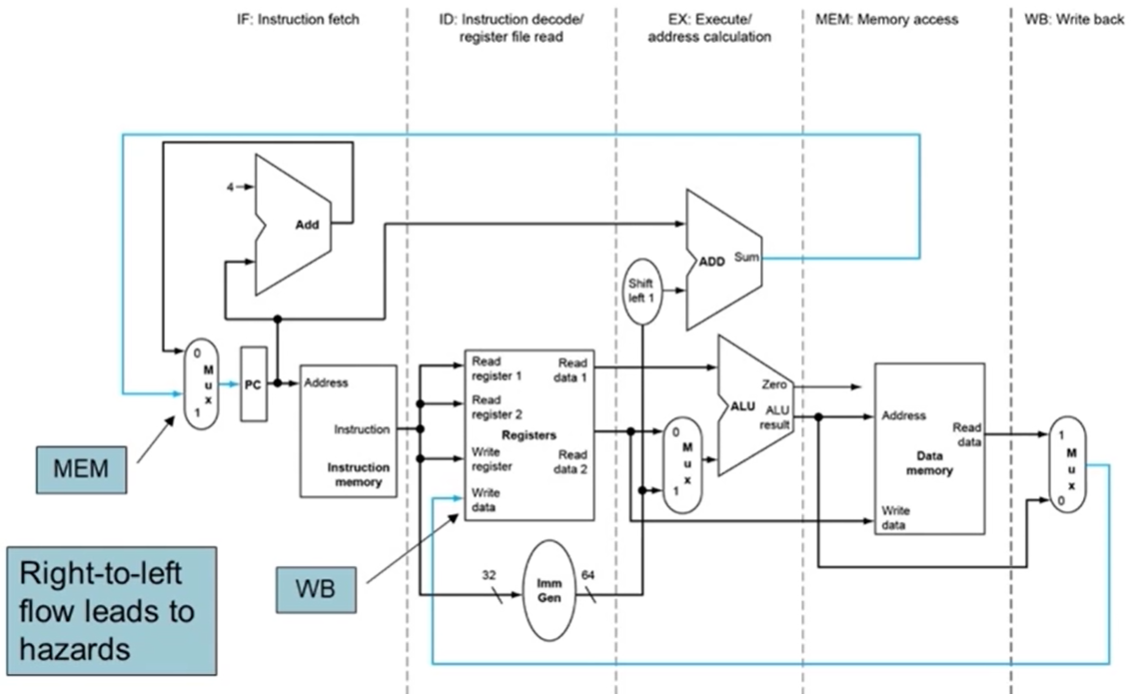
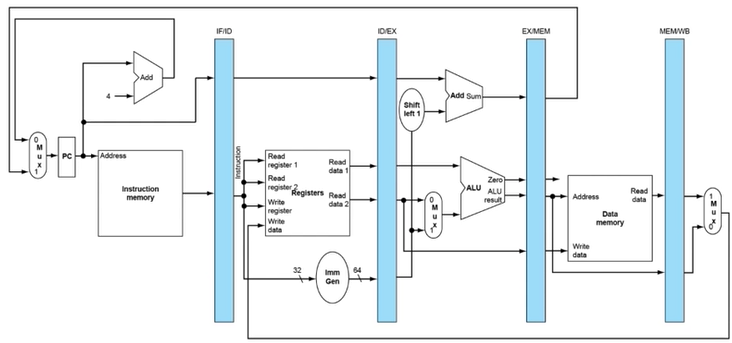
- Pipelining을 구현하기 위해서는 당연히 각 단계의 combinational circuit 사이에 flip flop같은 sequential circuit이 들어가야하고 hardware의 complexity가 증가하는 것은 불가피하다.

임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.