ABSTRACT
생성적 적대 네트워크(GAN)는 지난 몇 년 동안 광범위하게 연구되었다. 거의 틀림없이 그들의 가장 중요한 영향은 그럴듯한 이미지 생성, 이미지 대 이미지 변환, 얼굴 속성 조작 및 유사한 영역과 같은 도전에서 큰 발전이 이루어진 컴퓨터 비전 영역에 있었다. 현재까지 달성된 상당한 성공에도 불구하고, GAN을 실제 문제에 적용하는 것은 여전히 중요한 과제를 제기하며, 그 중 세 가지는 우리가 여기서 초점을 맞추고 있는것은 다음과 같다.(1) 고품질 이미지 생성, (2) 이미지 생성의 다양성, (3) 안정화 훈련 인기 있는 GAN 기술이 이러한 도전에 대해 진전을 이룬 정도에 초점을 맞추어, 우리는 출판된 과학 문헌에서 GAN 관련 연구의 최신 기술에 대한 상세한 검토를 제공한다. 우리는 GAN 아키텍처와 손실 기능의 변화를 기반으로 채택한 편리한 분류법을 통해 이 검토를 추가로 구성한다. 지금까지 GAN에 대한 몇 가지 검토가 제시되었지만, 컴퓨터 비전과 관련된 실질적인 과제를 해결하기 위한 진전을 바탕으로 이 분야의 상태를 고려한 것은 없다. 따라서, 우리는 이러한 과제를 해결하기 위해 가장 인기 있는 아키텍처 변형 및 손실 변동 GAN을 검토하고 비판적으로 논의한다. 우리의 목표는 중요한 컴퓨터 비전 응용 요구 사항에 대한 관련 진행 측면에서 GAN 연구의 상태에 대한 개요와 비판적인 분석을 제공하는 것이다. 이를 통해 우리는 향후 연구 방향에 대한 몇 가지 제안과 함께 GAN이 상당한 성공을 입증한 컴퓨터 비전에서 가장 설득력 있는 응용 프로그램에 대해서도 논의한다.
1 INTRODUCTION
생성적 적대 네트워크(GAN)는 딥 러닝 커뮤니티에서 점점 더 많은 관심을 끌고 있다[45, 83, 107, 117, 128, 136]. GAN은 컴퓨터 비전 [38, 72, 79, 89, 106, 130, 139, 152], 자연어 처리 [28, 40, 59, 141], 시계열 합성 [15, 34, 39, 48, 75], 의미 분할 [37, 86, 112, 155] 등과 같은 다양한 영역에 적용되어 왔다. GAN은 기계 학습에서 생성 모델군에 속한다. variant autoencoder와 같은 다른 생성 모델에 비해, GAN은 날카로운 추정 밀도 함수를 처리할 수 있는 능력, 원하는 샘플을 효율적으로 생성할 수 있는 능력, 결정론적 편향의 제거 및 내부 신경 아키텍처와의 양호한 호환성과 같은 이점을 제공한다[44]. 이러한 특성은 GAN이 특히 컴퓨터 비전 분야에서 큰 성공을 누릴 수 있도록 해주었다.
그러나 GAN에 문제가 없는 것은 아니다. 가장 중요한 두 가지는 그들이 훈련하기 어렵다는 것과 그들이 평가하기 어렵다는 것이다. 훈련하기 어렵다는 측면에서 판별기와 생성기가 훈련 중에 내쉬 평형을 달성하는 것은 사소하지 않으며 생성기가 데이터 세트의 전체 분포를 잘 학습하지 못하는 것이 일반적이다. 이것은 잘 알려진 모드 축소 문제입니다. 이 지역에서 많은 작업이 수행되었습니다 [27, 68, 69, 78]. 평가의 측면에서, 주요 쟁점은 목표 pr의 실제 분포와 생성된 분포 pθ 사이의 차이를 어떻게 가장 잘 측정할 것인가이다. 안타깝게도 pr의 정확한 추정은 불가능하다. 따라서, pr과 pθ 사이의 대응성에 대한 좋은 추정치를 도출하는 것은 어렵다. 이전 연구에서는 GAN[10, 12, 46, 47, 49, 124, 134, 135, 138]에 대한 다양한 평가 지표를 제안했으며, 이는 활발한 연구 분야이다. 그러나, 그것은 훈련과 관련된 문제들, 특히 이미지 품질, 이미지 다양성 및 안정성에 관한 문제들의 첫 번째 세트이다. 이 연구에서, 우리는 컴퓨터 비전 영역에서 이러한 측면을 다루는 기존의 GAN 변형을 연구할 것이다. 평가 과제에 관심이 있는 독자는 참조할 수 있습니다 [12, 124].
현재 GAN 연구의 대부분은 (1) 훈련의 개선과 (2) 실제 응용을 위한 GAN의 배치라는 두 가지 목표 측면에서 고려될 수 있다. 전자는 GANs 성능을 향상시키려 하므로 후자, 즉 응용 프로그램의 기반이 된다. GAN 훈련 개선을 다루는 많은 발표된 결과를 고려하여, 이 글에서 이러한 측면에 초점을 맞춘 가장 중요한 GAN 변형에 대한 간결한 검토를 제시한다. 훈련 프로세스의 개선은 (1) 생성된 이미지 다양성(모드 다양성이라고도 함)의 개선, (2) 생성된 이미지 품질의 증가, (3) 생성기의 그레이디언트 소실 문제를 해결하는 것과 같은 훈련을 안정화시키는 GANs 성능 측면에서 다음과 같은 이점을 제공한다. 위에서 언급한 바와 같은 성능을 향상시키기 위해, GAN에 대한 수정은 구조적 측면 또는 손실 관점에서 수행될 수 있다. 우리는 이러한 GAN 변형을 성능을 향상시키는 방법의 관점에서 각 관점에 따라 연구할 것이다.
article의 나머지 부분은 다음과 같이 구성된다. (1) 우리는 GAN에 관련한 이전의 검토 작업을 소개하고 이러한 검토와 이 작업의 차이를 설명한다. (2) 우리는 GAN에 대해 간략하게 소개하고, (3) 우리는 문헌에서 아키텍처에 따른 GAN을 검토한다. (5) 우리는 문헌에서 손실 변형 GAN을 검토한다. 주로 컴퓨터 비전 분야에서 사용되는 SED 애플리케이션은 (6) 본 연구의 GAN-변형을 요약하고 차이점과 관계를 설명하고 GAN에 관한 향후 연구를 위한 몇 가지 방법을 논의하며 (7) 이 검토를 마무리하고 해당 분야에서 가능한 미래 연구 작업을 미리 살펴본다.
성능을 향상시키기 위해 많은 GAN 변형이 문헌에서 제안되었다. 이 두 가지 유형으로 나눌 수 있습니다. (1) 아키텍처-변형. 처음 제안된 GAN은 완전히 연결된 신경망을 사용했기 때문에 [45] 특정 유형의 아키텍처가 특정 응용 프로그램에 유용할 수 있다. 예를 들어 이미지에 대한 컨볼루션 신경망(CNN)과 시계열 데이터에 대한 반복 신경망(RNN) 및 (2) 손실 변동. 여기서 G의 보다 안정적인 학습을 가능하게 하기 위해 손실 함수의 다양한 변형(식 (1))을 탐구한다.
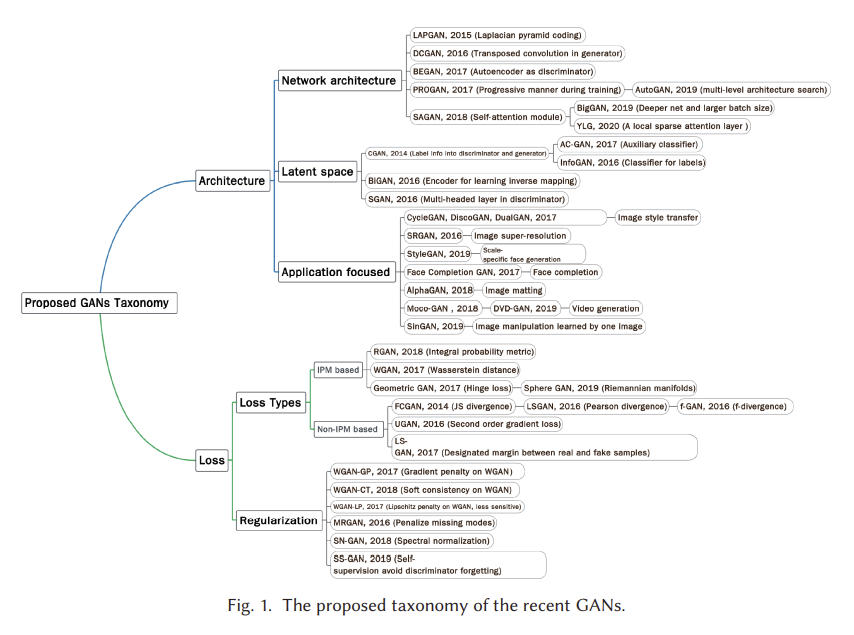
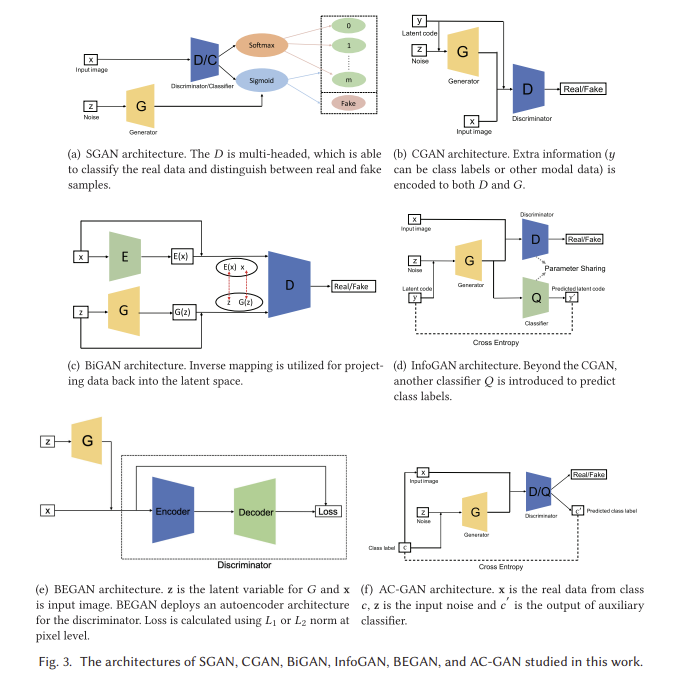
그림 1은 2014년부터 2020년까지 문헌에 제시된 대표적인 GAN에 대해 제안된 분류법을 보여준다. 우리는 현재의 GAN을 두 가지 주요 변형, 즉 아키텍처 변형과 손실 변형으로 나눈다. 아키텍처 변형에서, 우리는 네트워크 아키텍처, 잠재 공간 및 애플리케이션 포커스라는 세 가지 범주를 요약한다. 네트워크 아키텍처 범주는 전체 GAN 아키텍처(예: 프로그레시브 GAN(PROGAN)에 배치된 점진적 메커니즘)에 대해 이루어진 개선 또는 수정을 의미합니다 [64]. 잠재 공간 범주는 잠재 공간의 다른 표현을 기반으로 아키텍처 수정이 이루어졌음을 나타낸다. 예를 들어 조건부 GAN(CGAN) [99]은 생성자와 판별기 모두에 레이블 정보를 제공하는 것을 포함한다. 마지막 범주인 응용 프로그램 중심은 서로 다른 응용 프로그램에 따라 이루어진 수정을 나타냅니다. 예를 들어 CycleGAN [153]은 이미지 스타일 전송을 다루는 특정 아키텍처를 가지고 있습니다. 손실 변동의 관점에서, 우리는 이것을 손실 유형과 정규화의 두 가지 범주로 나눈다. 손실 유형은 GAN에 대해 최적화될 수 있는 다양한 손실 함수를 의미하며 정규화는 손실 함수 또는 네트워크에 대해 수행되는 모든 유형의 정규화 작업에 대해 설계된 추가 불이익을 의미한다. 보다 구체적으로, 우리는 손실 함수를 적분 확률 메트릭(IPM) [101] 기반과 비 IPM 기반으로 나눈다. IPM 기반 GAN에서 판별기는 특정 등급의 함수로 제한된다[60]. 예를 들어, WGAN(Wasserstein GAN)의 판별기는 1-립시츠로 제한된다. 비 IPM 기반 GAN에서 판별자는 그러한 제약을 가지고 있지 않다.
2 RELATED REVIEWS
예를 들어, GANs 성과 검토와 관련하여 이전 GANs 검토 문서가 있었다[71]. 이 작업은 대규모 장면 이해(LSUN)-BEDROOM [145], CELEBA-HQ 128 [84] 및 CIFAR10 [70] 이미지 데이터 세트에서 벤치마킹하는 다양한 유형의 GAN에 걸친 실험 검증에 중점을 둔다. 결과는 스펙트럼 정규화[144]가 있는 원래 GAN[45]이 새로운 데이터 세트에 GAN을 적용할 때 좋은 시작 선택임을 시사한다. 그 검토의 한계는 벤치마크 데이터 세트가 다양성을 유의미한 방식으로 고려하지 않는다는 것이다. 따라서 벤치마크 결과는 이미지 품질 평가에 더 집중하는 경향이 있으며, 이는 다양한 이미지를 생성하는 GANs 효율성을 무시할 수 있다. 다른 연구[51]는 다양한 GAN 아키텍처와 평가 메트릭을 조사한다. 서로 다른 아키텍처 변형의 성능, 애플리케이션, 복잡성 등에 대한 추가적인 비교가 검토되어야 한다. 다른 논문[26, 52, 131]은 최신 개발 단계와 GAN의 적용에 대한 조사에 초점을 맞추고 있다. 그들은 다른 적용 대상의 렌즈를 통해 GAN 변형을 비교한다.
우리의 리뷰를 다른 기존 리뷰 기사와 비교하여 고품질 및 다양한 이미지를 생성하는 능력, 훈련의 안정성, 그레이디언트 소실 문제를 처리하는 능력을 포함한 성능을 기반으로 GAN-변종에 대한 소개를 강조한다. 우리는 아키텍처와 손실 기능 고려사항에 기반한 관점을 취함으로써 이 박람회에 접근한다. 이 관점은 GAN의 근본적인 과제를 다루고 GAN 요구사항과 특정 애플리케이션에 대한 아키텍처 및 손실 기능을 가장 잘 선택하는 방법 에 대해 연구자에게 도움이 되기 때문에 중요하다. 그것은 또한 지금까지 연구자들이 어떻게 그러한 문제들을 다루었는지에 대한 스냅숏을 제공하며, 따라서 새로운 연구자들에게 그들 자신의 연구를 위한 출발점을 제공할 것이다. 우리의 문헌 검색 전략과 이 검색 결과는 보충 자료에 제시되어 있다.
요약하면, 이 검토의 기여는 세 가지이다.
• 우리는 다음 세 가지 중요한 문제를 해결함으로써 GAN에 초점을 맞춘다. : (1) 고품질 이미지 생성, (2) 다양한 이미지 생성, (3) 안정화 훈련.
• (1) 생성기 및 판별기의 아키텍처(예: 네트워크 아키텍처, 잠재 공간 및 애플리케이션 중심 설계)와 (2) 훈련을 위한 목적 기능(예: IPM 기반 및 비 IPM 기반 방법, 정규화 접근법)의 변화를 통해 유용한 GAN 분류법을 제안하고 최근의 GAN을 맥락화한다. GAN에 대한 다른 검토와 비교하여, 이 검토는 다양한 GAN 변형에 대한 고유한 관점을 제공한다.
• 우리는 또한 이 기사에 제시된 GAN 변형의 장단점 측면에서 비교와 분석을 제공한다.
3 GENERATIVE ADVERSARIAL NETWORKS
일반적인 GAN은 두 가지 구성 요소로 구성되는데, 하나는 실제 이미지와 생성된 이미지를 구별하는 판별기(D)이고, 다른 하나는 판별기를 속이기 위해 이미지를 생성하는 생성기(G)이다. 분포 z ~ pz가 주어졌을 때, G는 확률 분포 pθ를 표본 G(z)의 분포로 정의한다. GAN의 목적은 실제 데이터 분포 pr에 근사한 생성기의 분포 pθ를 학습하는 것이다. GAN의 최적화는 D와 G의 공동 손실 함수와 관련하여 수행된다.
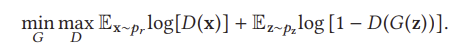
GAN은 딥 생성 모델(DGM) 제품군의 일원으로서 기존 DGM에 비해 몇 가지 이점 때문에 딥 러닝 커뮤니티에 기하급수적으로 많은 관심을 끌었다. (1) GAN은 다른 DGM보다 더 나은 출력을 생성할 수 있다. 가장 잘 알려진 DGM과 비교하여 가변 자동 인코더(VAE)는 생성할 수 있다.VAE가 선명한 이미지를 생성할 수 없는 동안 모든 유형의 확률 밀도[44] GAN 프레임워크는 모든 유형의 발전기 네트워크를 훈련시킬 수 있다. 다른 DGM에는 발전기에 대한 사전 요구 사항이 있을 수 있습니다. 예를 들어 발전기의 출력 계층은 가우스 [32, 44, 67]입니다. (3) 잠재 변수의 크기에는 제한이 없습니다. 이러한 이점은 GAN이 특히 이미지 데이터에 대한 합성 데이터를 생성하는 데 있어 최첨단 성능을 달성하도록 이끌었다.
4 ARCHITECTURE-VARIANT GANS

문헌에서 제안된 아키텍처 변형에는 많은 유형이 있습니다(그림 2 참조). [11, 64, 113, 150, 153]. 아키텍처에 따라 다양한 GAN은 주로 이미지 간 전송[153], 이미지 초해상도[74], 이미지 완성[55] 및 텍스트-이미지 생성[114]과 같은 다양한 응용 프로그램의 목적으로 제안된다. 이 섹션에서는 앞에서 언급한 세 가지 측면, 즉 이미지 다양성 향상, 이미지 품질 향상 및 훈련 안정화에 따라 GAN의 성능을 향상시키는 데 도움이 되는 아키텍처 변형에 대한 검토를 제공한다. 다양한 응용 프로그램의 관점에서 아키텍처에 대한 검토는 여기에서 확인할 수 있습니다 [26, 51].
4.1 Fully connected GAN
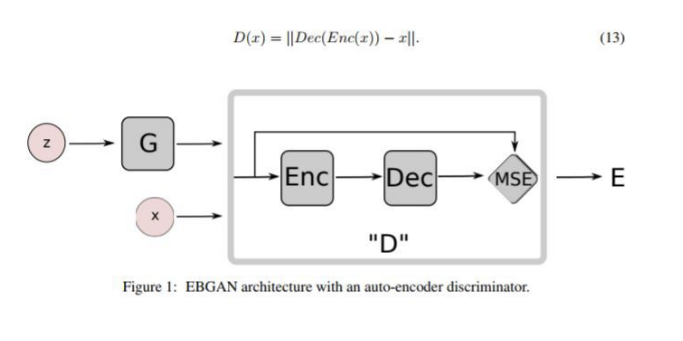
원본 에너지 기반 GAN(EBGAN) 논문 [45]은 생성기와 판별기 모두에 완전히 연결된 신경망을 사용한다. 이 아키텍처 변형은 MNIST [73], CIFAR-10 [70] 및 토론토 얼굴 데이터 세트와 같은 일부 간단한 이미지 데이터 세트에 적용되었다. 저자들은 훈련의 내부 루프에서 최적화의 완료가 이루어질 경우 D를 최적화하는 k단계와 판별기의 과적합으로 인한 G를 최적화하는 1단계를 제안한다. 실제로, 방정식 (1)은 생성기를 최적화하기 위해 사라지는 그레이디언트 문제를 유도할 수 있고, 대신 저자들은 G 훈련을 위해 로그 D(G(z))를 최대화할 수 있다. 이 수정은 G에 대해 pθ와 pr 사이의 역 쿨백-라이블러(KL) 발산을 동등하게 최적화하며, 이는 또한 비대칭 문제를 야기한다. 이에 대해서는 섹션 5에서 자세히 살펴보겠습니다. 아키텍처 설정의 경우, 판별기에 대해 maxout [41]이 배치되었고, 발전기에 ReLU와 Sigmoid 활성화의 혼합이 사용되었다. 더 복잡한 이미지 유형에 대해 좋은 일반화 성능을 보여주지 못한다.
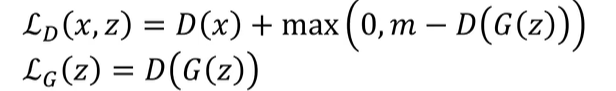
다음 손실함수 (maxout)은 학습초기에 생성기의 수준이 낮을 때 도움을 주고,
에너지기반 아키텍처 ==(오토인코더)를 사용하였다.
4.2 Semi-supervised GAN
준지도 GAN(SGAN)은 준지도 학습의 맥락에서 제안된다[105]. 준지도 학습은 지도 학습과 비지도 학습 사이의 유망한 연구 분야이다. 모든 샘플에 대한 레이블이 필요한 지도 학습과 레이블이 제공되지 않는 비지도 학습과는 달리, 준지도 학습은 예제의 작은 하위 집합에 대한 레이블을 가지고 있다. 완전히 연결된 GAN(FCGAN)과 비교하여 SGAN의 판별기는 다중 헤드 입니다. 즉, 각각 실제 데이터를 분류하고 실제 샘플과 가짜 샘플을 구별하기 위한 소프트맥스와 시그모이드를 가지고 있습니다. 저자들은 MNIST 데이터 세트에 대해 SGAN을 훈련시켰다. 결과는 SGAN의 판별기와 생성기 모두 원래 GAN에 비해 개선되었음을 보여준다. 우리는 다중 헤드 판별기의 구조가 모델의 다양성을 제한하는 비교적 단순하다고 생각한다. 즉, 실험은 MNIST 데이터 세트에서만 수행된다. 판별기를 위한 더 복잡한 아키텍처는 모델의 성능을 향상시킬 수 있다.
4.3 Bidirectional GAN
전통적인 GAN은 역 매핑, 즉 잠재 공간에 데이터를 다시 투영하는 방법을 학습할 수 없다. 양방향 GAN(BiGAN)은 이러한 목적을 위해 설계되었다[35]. 그림 3(c)에서 보는 바와 같이, 전체 아키텍처는 인코더(E), 제너레이터(G), 판별기(D)로 구성된다. E는 실제 샘플 데이터를 E(x)로 인코딩하고 G는 z를 G(z)로 디코딩한다. 결과적으로 D는 (E(x), x)와 (G(z), z)의 각 쌍 간의 차이를 평가하는 것을 목표로 합니다. E와 G는 직접 통신하지 않기 때문에, 즉, E는 G(z)를 보지 못하고 G는 E(x)를 보지 못한다. 저자들은 인코더와 디코더가 원본 논문에서 판별자를 속이기 위해 서로를 뒤집는 법을 배워야 한다는 것을 증명한다. 그러한 모델이 향후 연구에서 적대적 사례를 다룰 수 있는지 보는 것은 흥미로울 것이다. BiGAN은 MNIST 및 ImageNet 데이터 세트에 대해 교육을 받았다. 최적화에 β1 = 0.5 및 β2 = 0.999인 Adam optimizer가 사용된다. 배치 크기는 128이며 모든 파라미터에 2.5 × 10-5의 중량 감쇠가 적용됩니다. 배치 정규화도 배포됩니다.
4.4 Conditional GAN
CGAN은 각각 등급 라벨을 공급함으로써 판별기와 발전기 모두에 대한 조절의 혁신을 가지고 있다[99]. 그림 3(b)에서 볼 수 있듯이 CGAN은 추가 정보 y(클래스 라벨 또는 기타 모달 데이터일 수 있음)를 판별기와 생성기 모두에 공급한다. 일반적으로 y는 인코딩된 z 및 인코딩된 x와 연결되기 전에 생성기 및 판별기 내부에서 인코딩된다는 점에 유의해야 한다. 예를 들어, 원본 작업의 MNIST 실험에서, z와 y는 생성기에서 서로 결합되기 전에 각각 레이어 크기가 200과 1,000인 숨겨진 레이어에 매핑된다(결합 레이어 치수는 200 + 1000 = 1200). 이를 통해 CGAN은 판별자의 판별력을 향상시킨다. CGAN의 손실 함수는 x와 y를 z로 조건화한 식 (2)에서 보는 바와 같이 FCGAN과 약간 다르다. 추가 인코딩 정보의 혜택을 받은 CGAN은 단일 모드 이미지 데이터 세트뿐만 아니라 연관된 사용자 생성 메타데이터, 특히 사용자 태그와 함께 레이블링된 이미지 데이터를 포함하는 Flickr과 같은 멀티모달 데이터 세트도 처리할 수 있으며, 이는 GAN을 멀티모달 데이터 생성 영역으로 가져올 수 있다. 저자들은 MNIST와 Yahoo Flickr Creative Common 100M(YFCC 100M)에서 CGAN을 실험했다. MNIST 데이터 세트의 경우, 모델은 미니 배치 크기가 100이고 초기 학습률이 0.1인 확률적 그레이디언트 강하(SGD)를 사용하여 훈련되었으며 붕괴 계수는 1.00004로 설정된 상태에서 1 × 10-6으로 기하급수적으로 감소했다. 드롭아웃은 발생기와 판별기 모두에 대해 0.5의 확률로 사용되었습니다. 모멘텀은 초기값 0.5로 사용되었고 최종적으로 0.7까지 증가하였다. 클래스 라벨은 원핫 벡터로 인코딩되어 G와 D에 모두 공급되었다. YFCC 100M 실험의 관점에서, 훈련 초 매개 변수는 MNIST 실험의 설정과 동일하다. CGAN이 인코딩된 레이블을 도입하여 판별기의 식별 능력을 향상시키지만, 인코딩된 레이블 중 일부는 여전히 이미지
와의 연결이 느슨하다.
4.5 InfoGAN
InfoGAN은 조건부 변수와 생성 데이터 사이의 상호 정보를 최대화하여 비지도 방식으로 해석 가능한 표현을 학습하는 CGAN[20]을 넘어서는 단계로 제안된다. 이를 달성하기 위해 InfoGAN은 G(z|y)에 의해 주어진 분류를 예측하기 위해 다른 분류기 Q(그림 3(d) 참조)를 도입한다. 여기서 G와 Q의 조합은 오토인코더로 이해될 수 있으며, 여기서 우리는 y와 y' 사이의 교차 엔트로피를 최소화하는 임베딩(G(z|y))을 찾는 것을 목표로 한다. 그러나 D는 FCGAN과 동일한 작업을 수행하여 G에서 생성된 샘플 또는 실제 데이터를 구별한다. 계산 비용을 줄이기 위해 Q와 D는 마지막으로 완전히 연결된 레이어를 제외한 모든 컨볼루션 레이어를 공유하므로 판별기는 실제 샘플과 가짜 샘플을 구별하고 정보를 복구할 수 있다. 이는 원래 GAN 아키텍처에 비해 InfoGAN에 대한 차별적 능력을 향상시킬 수 있다. InfoGAN에서 사용된 손실은 판별기가 y를 입력으로 받아들이지 않고 I(·)가 상호 정보라는 점을 제외하고 V(D,G)가 CGAN의 목표인 CGAN 손실의 정규화이다.
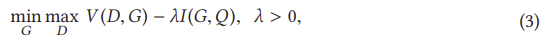
저자들은 MNIST, 3차원(3D) 얼굴 이미지[109], 3D 의자 이미지[6], SVHN 및 CelebA를 사용하여 InfoGAN을 실험했다. 모든 데이터 세트는 Adam 옵티마이저를 사용하고 배치 정규화가 적용된 동일한 교육 설정을 공유했다. Reky rate가 0.1인 Leaky ReLU를 판별기에 적용하였으며, ReLU를 발전기에 사용하였다. D는 2 × 10-4의 학습률을, G는 1 × 10-3의 학습률을 설정하였으며, λ은 1로 설정하였다. 여기서 우리는 마지막 레이어를 제외하고 D와 Q에 대한 매개 변수가 서로 공유되기 때문에 모델의 다양성이 매우 제한적이라고 생각한다. Q에 대한 보다 복잡한 설정을 유용하게 조사할 수 있다.
4.6 Auxiliary Classifier GAN
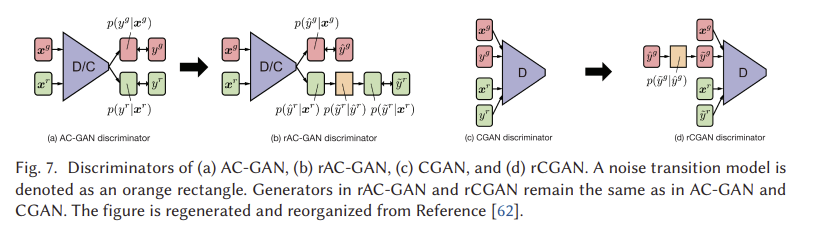
보조 분류기 GAN (AC-GAN) [106]은 CGAN 및 InfoGAN과 매우 유사합니다. 그림 3(f)에서 보는 바와 같이 아키텍처에 보조 분류기가 포함되어 있습니다. AC-GAN에서 생성된 각 표본에는 z 외에도 해당 클래스 레이블 c가 있습니다. AC-GAN과 이전 두 아키텍처 변형(CGAN 및 InfoGAN)의 차이는 여기서 추가 정보이며, 이전 두 가지는 다른 도메인 데이터가 될 수 있는 반면 클래스 레이블만 언급한다. 따라서 AC-GAN에서 c와 c를 사용하여 이전 두 변형과의 차이를 명시적으로 플래그 지정한다. AC-GAN의 판별기는 판별기 D(실제 샘플과 가짜 샘플을 구별)와 분류기 Q(실제 샘플과 가짜 샘플을 분류)로 구성된다. InfoGAN과 마찬가지로 판별기와 분류기는 마지막 레이어를 제외한 모든 가중치를 공유한다. AC-GAN의 손실 함수는 판별기와 분류기를 고려하여 구성할 수 있으며,
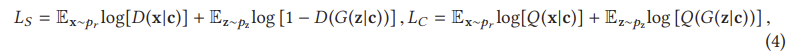
D는 LS + LC를 최대화하여 훈련되고 G는 LC - LS를 최대화하는 것으로 훈련된다. 저자들은 모든 1,000개 클래스에 대해 CIFAR-10 및 ImageNet 데이터 세트에 대해 AC-GAN을 훈련시켰다. CIFAR-10과 ImageNet 모두에 대해, 모델은 D, G, Q에 대해 α = 2 × 10-4, β1 = 0.5, β2 = 0.999인 Adam을 사용하여 훈련되었다. 미니 배치 크기가 100으로 설정되었습니다. 모델 성능 및 관련 실험에 대한 자세한 내용은 원본 논문에서 확인할 수 있습니다 [106]. AC-GAN은 생성된 이미지에 대한 시각적 품질이 향상되었으며 모델 다양성이 높다. 그러나 이러한 개선은 대규모 레이블링된 데이터 세트에 따라 달라지며, 이는 일부 실제 애플리케이션에서 문제를 일으킬 수 있다. AC-GAN과 비지도 또는 자체 지도 접근법의 조합은 더 조사되어야 한다. 우리는 또한 4.13절에서 노이즈가 많은 레이블 문제를 다루는 레이블 잡음 강력한 GAN(rGAN)의 유형을 도입했다.
4.7 Laplacian Pyramid of Adversarial Networks
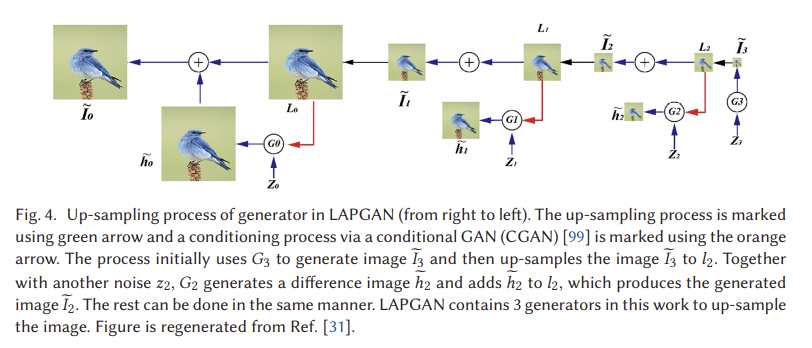
LAPGAN(Laplacian Pyramid of Adversarial Networks)은 저해상도 입력 GAN에서 고해상도 이미지를 생성하기 위해 제안된다[31]. 라플라시안 피라미드[16]는 이미지 코딩 접근법으로서, 많은 스케일이지만 동일한 모양의 로컬 연산자를 기본 함수로 사용한다. LAPGAN은 그림 4(오른쪽에서 왼쪽으로)에 표시된 고품질 이미지를 생성하기 위해 라플라스 피라미드 프레임워크 [16] 내에서 CNN의 캐스케이드를 활용한다. LAPGAN은 이전 계층의 커널 출력을 업샘플링하기 위해 디콘볼루션 프로세스(즉, DCGAN에서 사용)를 사용하는 대신 라플라시안 피라미드를 사용하여 이미지를 업샘플링한다. 먼저, LAPGAN은 첫 번째 생성기를 사용하여 매우 작은 이미지를 생성하며, 이는 생성기의 불안정성 문제를 완화할 수 있으며, 그 다음 이 이미지는 라플라시안 피라미드를 사용하여 업샘플링된다. 그런 다음 업샘플링된 이미지는 이미지 차이와 이미지 차이의 합계를 생성하기 위해 다음 생성기로 공급됩니다. 입력 이미지는 생성된 이미지일 것이다. 그림 4의 G3만이 이미지 생성에 사용되고 있으나 치수가 매우 작아 안정화 훈련을 장려함을 알 수 있다. 더 큰 이미지의 경우 생성기를 사용하여 이미지 차이를 생성하는데, 이는 동일한 크기의 원시 이미지보다 훨씬 덜 복잡합니다. 이 구조는 안정화 훈련과 고해상도 모델링을 용이하게 한다. CIFAR10(28 × 28 픽셀), STL(96 × 96 픽셀), LSUN(64 × 64 픽셀)이 생성에 사용되었다. 각 데이터 세트에 대한 라플라시안 피라미드 상향 조정 프로세스는 8 → 14 → 28 (CIFAR10), 8 → 16 → 32 → 64 → 96 (STL), 4 → 8 → 16 → 32 → 64 (LSUN)이다. 판별기는 3개의 숨겨진 레이어와 시그모이드 출력을 사용했고, 생성기는 ReLU와 배치 정규화를 포함한 5개의 레이어 CNN을 사용했다. 선형 출력 레이어가 사용되었습니다. 초기 학습률이 0.02인 SGD는 매 시대마다 (4 × 10-5)의 배수로 감소하여 실험에 배치되었다. 모멘텀은 0.5에서 시작하여 각 에폭에서 최대 0.8까지 0.0008씩 증가했습니다. 현재 구조에는 이미지 생성을 위한 여러 제너레이터가 포함되어 있으며 이러한 제너레이터 간의 연결은 설정되지 않았습니다. 섹션 4.10에서, 우리는 점진적인 방식으로 모델을 훈련시키는 더 진보된 전략, 즉 PROGAN을 소개한다.
4.8 Deep Convolutional GAN
DCGAN은 G[113]를 위한 디콘볼루션 신경망 아키텍처를 적용한 첫 번째 작업이다. 디콘볼루션(Deconvolution)은 CNN의 기능을 시각화하기 위해 제안되었으며 CNN 시각화에서 좋은 성능을 보여주었다[148]. DCGAN은 GAN을 사용하여 고해상도 이미지를 생성할 수 있는 G에 대한 디콘볼루션 연산의 공간 업샘플링 기능을 배포한다. 원래 FCGAN과 비교하여 DCGAN의 아키텍처에는 몇 가지 중요한 수정 사항이 있으며, 이는 고해상도 모델링 및 안정화 교육에 도움이 된다. 첫째, DCGAN은 모든 풀링 계층을 판별기를 위한 스트라이드 컨볼루션과 생성기를 위한 분수 스트라이드 컨볼루션으로 대체한다. 둘째, 배치 정규화는 판별기와 생성기 모두에 대해 사용되며, 이는 생성된 샘플과 실제 샘플, 즉 생성된 샘플과 실제 샘플에 대한 유사한 통계를 0을 중심으로 찾는 데 도움이 된다. 셋째, ReLU 활성화는 Tanh를 사용하는 출력을 제외한 모든 레이어에 대해 생성기에서 사용되는 반면, Leaky ReLU 활성화는 모든 레이어에 대해 판별기에서 사용된다. 이 경우, Leaky ReLU 활성화는 발전기가 판별기로부터 그레이디언트를 수신함에 따라 "다잉 상태" 상황(예: ReLU 레이어에서 0보다 작은 입력)에서 네트워크가 정체되는 것을 방지할 것이다. DCGAN은 LSUN [145], ImageNet [30] 및 맞춤형 조립 얼굴 데이터 세트에 대해 교육된다. 모든 모델은 128의 미니 배치 크기로 SGD를 사용하여 훈련되었다. 모든 가중치는 표준 편차가 0.02인 0 중심 정규 분포에서 초기화되었습니다. Adam 옵티마이저는 학습 속도 0.0002와 운동량 항 0.5로 사용되었다. Leaky ReLU의 기울기는 모든 모델에서 0.2로 설정되었습니다. 모델은 64 × 64 픽셀 이미지를 사용하여 훈련되었다. DCGAN은 GAN의 역사에서 매우 중요한 이정표이며 디콘볼루션 아이디어는 GAN 발전기에 사용되는 주요 아키텍처의 주체가 된다. 모델 용량의 한계와 DCGAN에 사용되는 최적화로 인해 저해상도 및 덜 다양한 이미지에서만 성공한다.
4.9 Boundary Equilibrium GAN
4.10 PROGAN
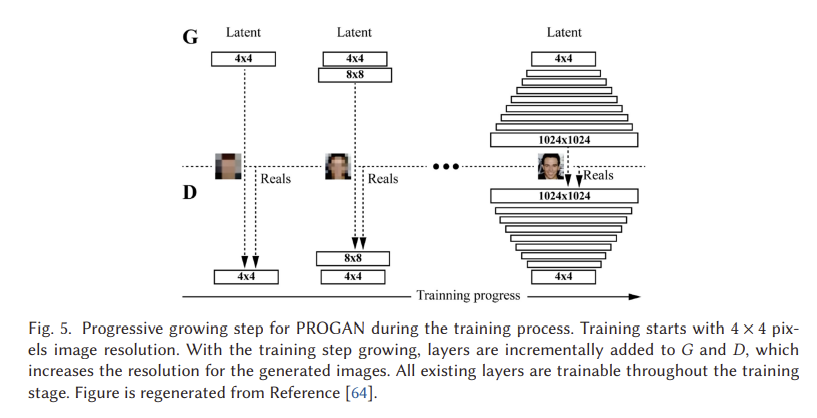
PROGAN은 네트워크 아키텍처의 확장을 위한 점진적인 단계를 포함한다[64]. 이 아키텍처는 참조 [116]에서 처음 제안된 점진적 신경망의 개념을 사용한다. 이 기술은 잊는 데 어려움을 겪지 않으며 이전에 학습한 기능에 대한 측면 연결을 통해 사전 지식을 배포할 수 있습니다. 결과적으로 복잡한 작업 시퀀스를 학습하는 데 널리 적용된다. 그림 5는 PROGAN의 교육 과정을 보여줍니다. 교육은 저해상도 4 x 4 픽셀 이미지로 시작됩니다. G와 D 모두 훈련이 진행됨에 따라 성장하기 시작한다. 중요한 것은 모든 변수가 이러한 성장 과정 동안 훈련될 수 있다는 것입니다. 이 점진적 훈련 전략은 두 네트워크 모두에 대해 훨씬 더 안정적인 학습을 가능하게 한다. 해상도를 조금씩 높임으로써, 네트워크는 잠재 벡터로부터 매핑을 발견한다는 최종 목표에 비해 훨씬 간단한 질문을 지속적으로 받는다. 현재의 모든 최첨단 GAN은 이러한 유형의 훈련 전략을 채택하고 있으며 인상적이고 그럴듯한 이미지를 만들어냈다.
4.11 Self-attention GAN
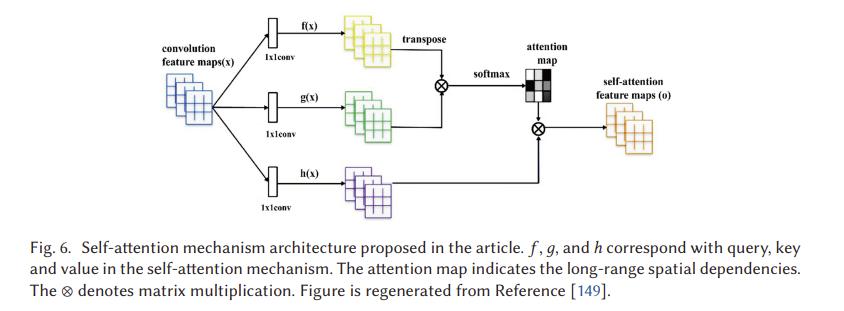
기존 CNN은 로컬 공간 정보만 캡처할 수 있고 수용 필드는 충분한 구조를 포함하지 않을 수 있으며, 이로 인해 CNN 기반 GAN은 다중 클래스 이미지 데이터 세트(예: ImageNet)를 학습하는 데 어려움을 겪고 생성된 이미지의 핵심 구성 요소가 이동될 수 있으며, 예를 들어 얼굴 생성 이미지의 코가 올바른 위치에 나타나지 않을 수 있다.on. CNN의 계산 효율성을 희생하지 않고 큰 수용 영역을 보장하기 위한 자기 주의 메커니즘이 제안되었다[129]. 자기 주의 GAN(SAGAN)은 GAN을 위한 판별기 및 발전기 아키텍처 설계에 자기 주의 메커니즘을 배치한다[149]. (그림 6 참조) 자기 주의 메커니즘의 이점을 활용하여 SAGAN은 이미지 생성을 위한 전역적이고 장기적인 의존성을 배울 수 있다. ImageNet 데이터 세트를 기반으로 한 다중 클래스 이미지 생성에서 뛰어난 성능을 달성했다. 저자들은 ImageNet 데이터 세트(128 x 128 픽셀 이미지)에 대해 SAGAN을 훈련시켰다. 스펙트럼 정규화[100]는 D와 G 모두에 적용되었다. 조건부 배치 정규화는 생성기에서 사용되었고 배치 투영은 판별기에서 사용되었다.
4.12 BigGAN
BigGAN [13]은 또한 ImageNet 데이터 세트에서 최첨단 성능을 달성했다. 그것의 설계는 SAGAN을 기반으로 하며 성능이 GAN 훈련의 스케일업, 즉 각 레이어에 대한 채널 수의 증가와 배치 크기의 증가를 산출할 수 있음을 입증했다. 저자들은 128 × 128, 256 × 256 및 512 × 512 해상도로 ImageNet에서 모델을 훈련시킨다. 이 작업의 훈련 설정은 학습률이 절반으로 줄고 G 단계당 두 개의 D 단계를 훈련하는 SAGAN을 따른다. 잠재 변수 z의 다양한 선택이 탐구되고 저자들은 베르누이 {0,1}과 관측 중단 정상 최대값(N(0, I), 0)이 절단 없이 가장 잘 작동한다고 진술한다. 잘라내기 트릭은 추론 또는 이미지 합성 시와는 달리 훈련 중에 생성기에 대한 다른 분포를 잠재 공간으로 사용하는 것을 포함한다. BigGAN에서는 훈련 중에 가우스 분포를 사용하고 추론 중에 잘린 가우스 분포를 사용한다. 이 잘라내기 트릭은 이미지 품질 또는 충실도와 이미지 다양성 간의 균형을 제공합니다. 샘플링 범위가 좁을수록 품질이 향상되는 반면 샘플링 범위가 클수록 샘플링된 이미지의 다양성이 증가합니다. 우리는 BigGAN이 아키텍처를 확장하도록 만드는 BigGAN에 대한 다음 작업을 요약한다. (1) 자기 주의 모듈 및 힌지 손실: BigGAN은 SAGAN의 어텐션 모듈과 함께 모델 아키텍처를 사용하며, 자체 어텐션이 모델 다양성에 기여하고 힌지 손실이 훈련의 안정성을 가능하게 하는 힌지 손실을 통해 훈련된다. (2) 클래스 조건부 정보: 클래스 정보는 클래스 조건부 배치 정규화를 통해 제너레이터 모델에 제공됩니다. (3) 제너레이터보다 업데이트 식별자: BigGAN은 각 훈련 반복에서 생성기 모델을 업데이트하기 전에 이를 약간 수정하고 판별기 모델을 두 번 업데이트합니다. (4) 모델 가중치의 이동 평균: 평가를 위해 이미지가 생성되기 전에 이전 훈련 반복에서 모델 가중치를 이동 평균을 사용하여 평균화합니다. (5) 네트워크상의 일부 작업: 또는호곤 가중치 초기화, 더 큰 배치 크기, 스킵-z 연결(잠재 레이어에서 여러 레이어로 연결 가능) 및 공유 임베딩, 즉, 저자는 이러한 작업이 모두 성능을 향상시키는 데 도움이 될 수 있음을 보여준다. 저자들은 또한 그러한 대규모에 특유한 불안정성의 분석을 특징짓는다. 더 자세한 내용은 원본 논문에서 확인할 수 있습니다.
4.13 Label-noise rGANs
4.14 Your Local GAN
이 작업[29]은 2차원 지오메트리 및 지역성을 보존하는 새로운 로컬 희소 주의 계층을 소개한다. 아이디어의 적용 가능성을 보여주기 위해 SAGAN [129]의 고밀도 주의 계층을 새로운 구성으로 교체한다. 주요 혁신은 (1) 주의 패턴이 정보 흐름 그래프의 정보 이론적 프레임워크에 의해 잘 지원된다는 것이다. (2) 로컬 GAN(YLG)-SAGAN이 도입되어 훈련 시간을 약 40% 단축하면서 우수한 성능을 달성한다. (3) 그들은 그레이디언트 내림차순을 수행하는 자연스러운 반전 프로세스를 만들었다.작은 GAN에 대한 이전 작업보다 더 큰 모델의 손실 작업에 대해 설명합니다. 저자가 사용하는 한 가지 구체적인 속임수는 열거, 이동, 적용(ESA)이다. 그들은 (0, 0) 위치에서 픽셀로부터의 맨해튼 거리를 기준으로 이미지의 픽셀을 열거함으로써 2차원 지역성을 인식하도록 1차원 희소화를 수정한다. (행 우선 순위를 사용하여 넥타이를 끊는다음 대신 주어진 1차원 희소화의 인덱스를 맨해튼 거리 열거와 일치하도록 이동한다. 재형상 열거, 그리고 2차원 인접성을 존중하는 이 새로운 1차원 희소화 패턴을 이미지의 1차원 재형상 버전에 적용합니다. 그러나 이 작업에는 두 가지 상반된 목표가 존재한다고 생각한다. 이 방법은 한편으로는 계산 및 통계 효율성을 위해 네트워크를 가능한 한 희박하게 만들고, 다른 한편으로는 여전히 양호하고 완전한 정보 흐름을 지원해야 한다.
4.15 AutoGAN
4.16 MSG-GAN
GAN은 서로 다른 데이터 세트에 적응하기 매우 어렵다는 것은 잘 알려져 있다. 카네와르 등은 이에 대한 이유 중 하나는 실제 분포와 가짜 분포의 지지에서 충분히 겹치지 않을 때 판별기에서 생성기로 전달되는 기울기가 정보를 제공하지 못하기 때문이라고 주장한다. 그들은 그러한 문제를 다루기 위한 수단으로 MSG-GAN[63]을 제안한다. 그림 8에서 보는 바와 같이 발전기와 판별기의 잠재 공간은 발전기와 판별기 사이에 더 많은 정보를 공유할 수 있도록 연결되어 있다. 보다 구체적으로, G의 각 전치 컨볼루션 단계(그림 8의 3단계)에서의 활성화는 연산 r에 의해 서로 다른 스케일의 영상에 매핑된다. 즉, 이 경우 1 × 1 컨볼루션이다. 마찬가지로, 매핑된 이미지는 r에 의해 활성화로 인코딩되며, 이는 실제 이미지로 인코딩된 활성화와 연결된다. 이 연결은 D와 G 사이의 더 많은 정보 공유를 가능하게 하고 실험 결과는 이점을 보여준다.
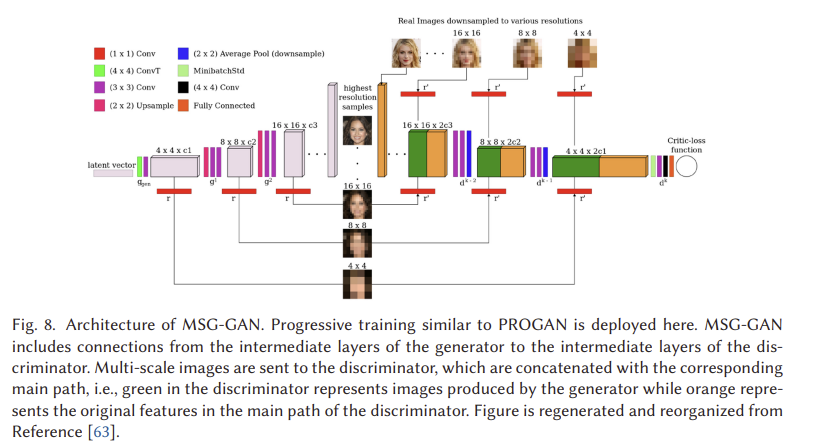
4.17 Summary
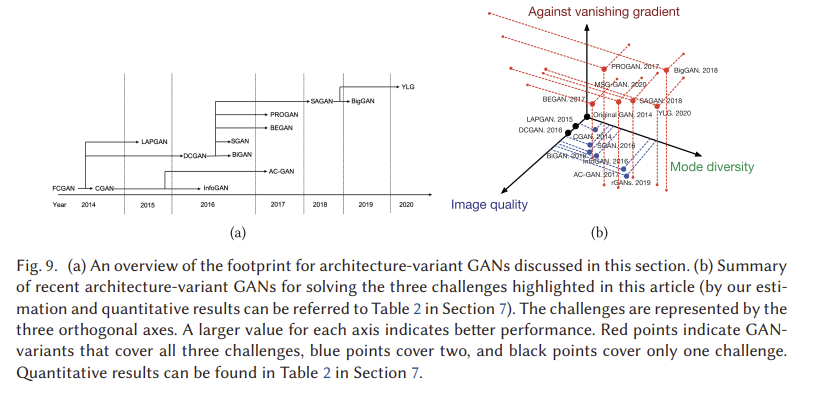
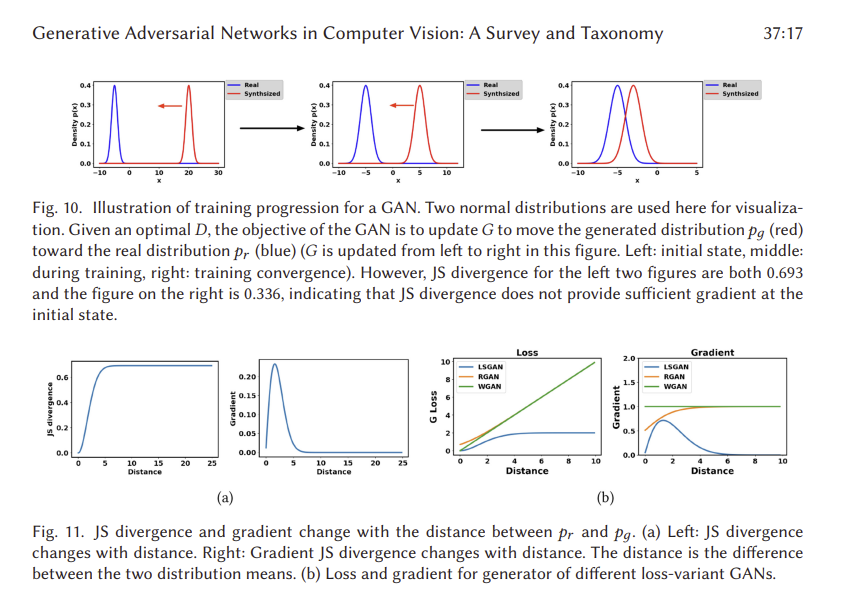
우리는 이미지 품질, 모드 다양성 및 불안정한 훈련 문제의 세 가지 핵심 과제와 관련하여 성능을 잠재적으로 향상시킬 수 있는 방법에 중점을 둔 아키텍처 가변 GAN의 개요를 제공했다. 그림 9(a)는 이 절에서 논의한 2014년부터 2020년까지의 아키텍처 가변 GAN의 풋프린트를 보여준다. 다양한 GAN 변종에서 많은 상호 연결이 있음을 알 수 있다. 그림 9(b)는 세 가지 과제에 대한 상대적 성과를 보여줍니다. 우리는 관심 있는 독자들이 각 GAN 변형의 이론과 성능에 대한 더 깊은 통찰력을 얻기 위해 원본 기사를 참조해야 한다고 제안한다. 여기서는 아키텍처에 따른 GANs 해결 방법이 어떻게 과제를 식별하는지 간략히 요약한다(정량적 결과는 섹션 7의 표 2에 요약되어 있다).
Image Quality
GAN의 기본 목표 중 하나는 높은 이미지 품질로 사실적인 이미지를 생성하는 것이다. 원래 GAN(FCGAN)은 아키텍처의 제한된 용량 때문에 MNIST, 토론토 페이스 및 CIFAR-10 데이터 세트에만 적용되었다. DCGAN과 LAPGAN은 디콘볼루션과 업샘플링 프로세스를 설계에 도입했다. 두 가지 모두 모델이 더 높은 해상도의 이미지를 생성할 수 있도록 합니다. 나머지 아키텍처 변형(예: BEGIN, PROGAN, SAGAN 및 BigGAN)은 모두 손실 함수에 대한 몇 가지 수정 사항을 가지고 있으며, 이는 더 나은 이미지 품질을 생성하는 데에도 도움이 된다. 아키텍처 구성 요소에서만 BEARD는 식별자를 위해 자동 인코더 아키텍처를 사용하며, 이는 생성된 이미지와 픽셀 수준에서 실제 이미지를 비교한다. 이를 통해 생성기가 재구성하기 쉬운 데이터를 생성할 수 있습니다. PROGAN은 더 깊은 아키텍처를 활용하고 모델은 교육이 진행됨에 따라 확장된다. 이 점진적 훈련 전략은 판별기와 생성기의 학습 안정성을 향상시켜 모델이 고해상도 이미지를 생성하는 방법을 더 쉽게 학습할 수 있도록 한다. SAGAN은 주로 다음 섹션에서 다루는 스펙트럼 정규화의 혜택을 받는다. BigGAN은 고해상도 이미지 생성은 배치 크기가 더 큰 심층 모델의 이점을 얻을 수 있음을 보여준다.
Vanishing Gradient
손실 함수를 변경하는 것만이 현재 이러한 문제를 해결할 수 있는 유일한 방법입니다. 여기서 일부 아키텍처 변형은 서로 다른 손실 함수를 사용하기 때문에 사라지는 그레이디언트 문제를 피한다. 이에 대해서는 다음 섹션에서 살펴보겠습니다.
Mode Diversity
이것은 GAN들에게 가장 어려운 문제이다. GAN이 자연 이미지와 같은 사실적인 다양한 이미지를 생성하는 것은 매우 어렵다. 아키텍처 가변 GAN의 관점에서 SAGAN과 BigGAN만이 이 문제를 명시적으로 다룬다. 자기 주의 메커니즘의 이점을 활용하여 SAGAN과 BigGAN의 CNN은 생성된 이미지의 구성 요소 이동 문제를 극복하는 큰 수용 필드를 처리할 수 있다. 이는 이러한 유형의 GAN이 다양한 이미지를 생성할 수 있게 한다.
5 LOSS-VARIANT GANS
성능에 상당한 영향을 미치는 GAN의 또 다른 설계 결정은 식 (1)의 손실 함수의 선택이다. 원래의 GAN 작업[45]은 이미 전역 최적성과 GAN 훈련의 수렴을 입증했지만, 여전히 GAN을 훈련시킬 때 발생할 수 있는 불안정성 문제를 강조한다. 이 문제는 참조 [45]에 명시된 글로벌 최적성 기준에 의해 발생합니다. 전역 최적성은 임의의 G에 대해 최적의 D에 도달했을 때 달성된다. 따라서 최적 D는 식 (1)의 손실에 대한 D의 도함수가 0일 때 달성된다.
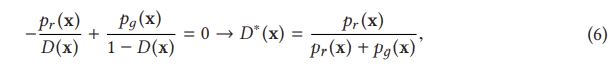
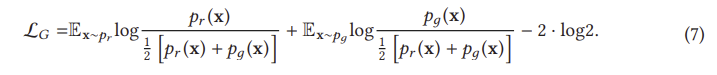
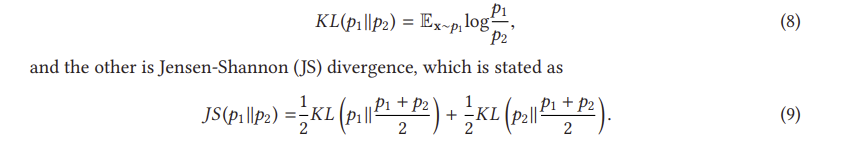

이는 G에 대한 손실이 동일하게 pr과 pθ 사이의 JS 발산을 최소화한다는 것을 나타낸다. D를 단계별로 훈련하면 G의 최적화는 pr과 pд 사이의 JS 발산을 최소화하는 데 더 가까워질 것이다. 우리는 이제 D가 종종 G를 쉽게 이기는 훈련의 불안정성 문제를 설명 하기 시작할 수 있다. 이러한 불안정한 훈련 문제는 실제로 방정식 (9)의 JS 발산에 의해 발생한다. 최적 D가 주어졌을 때, 방정식(10)에 대한 최적화 목표는 pθ를 pr 쪽으로 이동하는 것이다(그림 10 참조). 왼쪽에서 오른쪽으로의 세 그래프에 대한 JS 발산은 0.693, 0.693 및 0.336이며, 이는 pr과 pθ 사이에 겹침이 없는 경우 JS 발산이 일정하게 유지됨을 나타냅니다(log2 = 0.693). 그림 11(a)은 pr과 pθ 사이의 거리에 해당하는 JS 발산 및 그 기울기의 변화를 보여준다. 거리가 5보다 클 때 JS 발산이 일정하고 그 기울기가 거의 0에 가깝다는 것을 알 수 있는데, 이는 훈련 과정이 G에 아무런 영향을 미치지 않음을 나타낸다. G를 훈련하기 위한 JS 발산 기울기는 pθ와 pr이 상당한 중첩을 가질 때만 0이 아니다. 즉, D가 최적에 가까울 때 G에 대해 소멸 기울기가 발생할 것이다. 실제로, p와 p p가 겹치지 않거나 무시할 수 있는 겹침을 가질 가능성은 매우 높다[3].
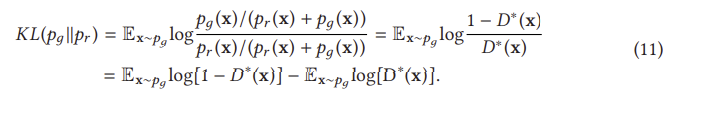
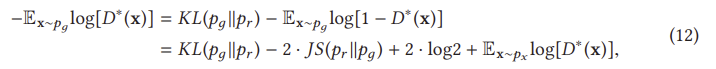
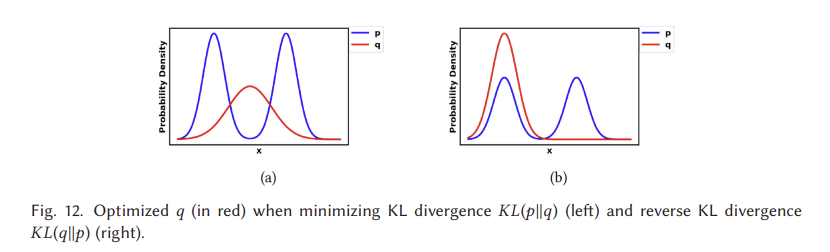
식 (12)에서 G에 대한 대체 손실은 처음 두 항 (마지막 두 항은 상수)에 의해서만 영향을 받지만, JS (pr p θ)는 왼쪽 그림 11(a)에 표시된 것처럼 [0, log 2]에서 제한되기 때문에 이 손실 함수는 KL(p θ pr)에 의해 지배됩니다. 식 (12)의 첫 번째 항은 역 KL 발산임을 알 수 있는데, 역 KL 발산에 의해 최적화된 pθ는 역 KL 발산에 의해 최적화된 pθ와 완전히 다른 것을 알 수 있다. 그림 12는 p에 대해 두 개의 가우시안(Gaussian)과 q에 대해 하나의 가우시안(Gaussian)의 혼합물을 사용하여 이러한 차이를 보여준다. p에 여러 모드가 있을 때, q는 그림 12(a)에서 보는 바와 같이 모든 모드에 높은 확률의 질량을 가하기 위해 모든 모드를 함께 흐리게 하려고 한다. 그러나 그림 12(b)는 q가 두 가우시안 중심에 있는 낮은 확률 영역에 확률 질량을 두지 않기 위해 단일 가우시안 복구를 선택한다는 것을 보여준다. 따라서 역 KL 발산에 대한 최적화는 GAN 훈련 중에 모드 붕괴를 일으킬 것이다. 아래에 강조 표시되어 있습니다.
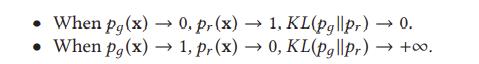
G의 두 가지 실적 부진 사례에 대한 처벌은 완전히 다르다. 성능이 좋지 않은 첫 번째 예는 G가 합리적인 범위의 샘플을 생산하지 않고 있지만 매우 적은 불이익을 초래한다는 것이다. 성능 저하의 두 번째 예는 G가 신뢰할 수 없는 샘플을 생산하는 것과 관련이 있지만 매우 큰 벌칙을 가지고 있다. 첫 번째 예는 생성된 샘플이 다양성이 부족하다는 사실에 관한 것이고, 두 번째 예는 생성된 샘플이 정확하지 않다는 사실에 관한 것이다. 이러한 첫 번째 사례를 고려할 때, G는 다양하고 "안전하지 않은" 샘플을 생성하기 위해 위험을 감수하는 대신 반복적이지만 "안전한" 샘플을 생성하며, 이는 모드 붕괴 문제로 이어진다. 요약하면, 식 (1)의 원래 손실을 사용하면 G 훈련의 기울기가 사라지고 식 (12)의 대체 손실을 사용하면 모드 붕괴 문제가 발생한다. 이러한 종류의 문제들은 단순히 구조를 바꾸는 것만으로 해결될 수 없다. 따라서 GAN의 궁극적인 문제는 손실 함수의 설계에서 비롯되며 이러한 손실 함수의 재설계에 대한 혁신적인 아이디어가 문제를 해결할 수 있다고 주장할 수 있다. 손실 변동 GAN은 훈련 GAN의 안정성을 향상시키기 위해 광범위하게 연구되어 왔으며 우리는 이를 다음으로 고려한다.
5.1 Wasserstein GAN
WGAN [4]은 최적화를 위한 손실 척도로 Earth mover (EM) 또는 Wasserstein-1 [115] 거리를 사용하여 원래 GAN에 대한 두 가지 문제를 성공적으로 해결했습니다.
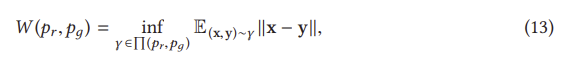
또한 연속적이며, 따라서 발전기를 훈련시키기 위한 의미 있는 구배를 제공할 수 있다. 그림 11(b)은 원래 GAN과 비교한 WGAN 기울기를 보여준다. WGAN은 전체 공간에 걸쳐 발전기를 훈련하기 위한 부드러운 기울기를 가지고 있다는 것이 눈에 띈다. 그러나 식 (13)의 무한값은 다루기 어렵지만, 생성자들은 와세르슈타인 거리를 다음과 같이 대신 추정할 수 있음을 입증한다.
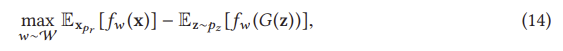
여기서 fw는 D에 의해 실현될 수 있지만 일부 제약 조건이 있다(자세한 내용은 관심 있는 독자가 원본 [4]를 참조할 수 있다). z는 G에 대한 입력 노이즈이다. 여기서 D의 매개 변수는 와세르슈타인 거리와 동등한 최적화 거리를 만들기 위해 방정식(14)을 최대화하는 것을 목표로 한다. D가 최적화되면 방정식(13)은 와세르슈타인 거리가 되며 G는 이를 최소화하는 것을 목표로 한다.
5.2 WGAN-GP
5.3 Least Square GAN (LSGAN)
5.4 f-GAN
5.5 Unrolled GAN
~~## 5.6 Loss Sensitive GAN (LS-GAN)
~~
~~## 5.7 Mode Regularized GAN
~~
~~## 5.8 Geometric GAN
~~
~~## 5.9 Relativistic GAN
~~
5.10 SN-GAN
5.11 RealnessGAN
5.13 Self-supervised GAN (SS-GAN)
5.14 Summary

우리는 원래의 GAN 설계에 존재하는 훈련 문제(모드 붕괴 및 G의 소멸 그레이디언트)를 설명하고 주로 세 가지 주요 측면의 관점에서 GANs 성능을 개선하기 위해 제안된 문헌에서 손실 변동 GAN을 도입했다. 그림 19(a)는 이 섹션에서 설명하는 손실 변동의 발자국을 보여준다. 그림 19(b)는 이러한 과제에 대한 손실 변동 GAN의 효과를 요약한다. 정량적 결과에 대한 자세한 내용은 섹션 7에 나와 있다. LSGAN, RGAN 및 WGAN의 손실은 원래 GAN 손실과 매우 유사합니다. 우리는 그림 11(b)의 실제 데이터 분포와 생성된 데이터 분포 사이의 거리에 관한 G 손실을 보여주기 위해 장난감 예(즉, 그림 10에 사용된 두 가지 분포)를 사용한다.
판별기가 최적화되었을 때 RGAN과 WGAN은 발전기에 대한 사라지는 그레이디언트 문제를 본질적으로 해결할 수 있음을 알 수 있다. 대조적으로 LSGAN은 여전히 발전기에 대한 기울기가 사라지지만 실제 데이터 분포와 생성된 데이터 분포 사이의 거리가 상대적으로 작을 때 그림 11(a)의 원래 GAN에 비해 더 나은 기울기를 제공할 수 있다. 이것은 LSGAN이 생성된 샘플을 판별기에 의해 설정된 경계로 더 쉽게 밀어내는 것으로 보여지는 원본 논문[94]에서 입증된다.
손실 변동 GAN은 아키텍처 변동에 적용될 수 있다. 그러나 SN-GAN과 RGAN은 다른 유형의 손실 변인에 의해 이 두 손실 변인이 배치될 수 있는 다른 손실 변인에 비해 더 강한 일반화 능력을 보여준다. 스펙트럼 정규화는 모든 GAN 변형 [100]에 적용될 수 있으며, RGAN 개념은 모든 IPM 기반 GAN [60]에 적용될 수 있다. 여기에 설명된 대로 모든 GAN 애플리케이션에 대해 스펙트럼 정규화를 사용할 것을 강력히 권장합니다. 이 기사에서 언급된 손실 변동 GAN은 모드 붕괴 및 훈련 안정성 문제를 해결할 수 있다.
6 APPLICATIONS
6.1 Image Synthesis
6.2 Video Generation
6.3 Feature Generation
7 DISCUSSION
우리는 원래 GAN 설계에 존재하는 가장 중요한 문제, 즉 G를 업데이트할 때 모드 붕괴와 소멸 그레이디언트를 소개했다. 우리는 (1) 아키텍처 변형이라는 두 가지 설계 고려 사항을 통해 이러한 문제를 해결하는 중요한 GAN 변형을 조사했다. 이 측면은 GAN을 위한 아키텍처 옵션에 초점을 맞춘다. 이 접근 방식을 통해 GAN을 다른 애플리케이션에 성공적으로 적용할 수 있지만, 위에서 언급한 문제를 완전히 해결할 수는 없다. (2) 손실 변동 우리는 이러한 문제가 원래 GAN에서 발생하는 이유에 대해 자세한 설명을 제공했습니다. 이러한 문제는 본질적으로 원래 GAN의 손실 함수에 의해 발생한다. 결과적으로, 이 손실 함수를 수정하면 이 문제를 해결할 수 있다. 그러나 일부 구조변동에서는 손실함수가 변경될 수 있으며, 많은 경우에 구조특이적 손실이라는 점에 유의해야 한다. 따라서 다른 아키텍처로 일반화할 수 없다. 표 2는 문헌에 제시된 바와 같이 Inception Score와 FID를 사용하여 본 연구에서 제시된 GAN의 성능에 대한 요약을 보여준다. 요약에서는 가장 널리 사용되는 벤치마크 데이터 세트인 CIFAR10, ImageNet, LSUN 및 CelebA의 네 가지 이미지 데이터 세트를 고려한다.
Interconnections between Architecture and Loss
이 기사에서는 원래 GAN 설계에 내재된 문제를 강조한다. 후속 연구자들이 이러한 문제를 어떻게 해결했는지 강조하면서, 우리는 GAN 설계의 아키텍처 변형과 손실 변형에 대해 별도로 탐구했다. 그러나 이 두 가지 유형의 GAN 변형 사이에는 상호 연결이 있다는 점에 유의해야 한다. 앞에서 언급했듯이, 손실 기능은 다른 아키텍처에 쉽게 통합됩니다. 아키텍처 변형은 재설계된 손실 함수를 통해 향상된 수렴 및 안정화의 혜택을 받으며 더 나은 성능을 달성하고 더 어려운 문제에 대한 솔루션을 달성할 수 있다. 예를 들어, BEGIN과 PROGAN은 JS 발산 대신 Wasserstein 거리를 사용한다. SAGAN과 BigGAN은 스펙트럼 정규화를 배포하여 멀티 클래스 이미지 생성을 기반으로 좋은 성능을 달성한다. 이 두 가지 변형 유형은 GANs 진행에 동등하게 기여한다.
Future Directions
GAN은 원래 그럴듯한 합성 이미지를 생성하기 위해 제안되었으며 컴퓨터 비전 영역에서 흥미로운 성능을 달성했다. GAN은 일부 다른 분야(예: 시계열 생성 [15, 39, 48, 87] 및 자연어 처리 [8, 40, 76, 147])에도 적용되었지만 어느 정도 성공을 거두었다. 컴퓨터 비전에 비해 다른 분야의 GANs 연구는 여전히 다소 제한적이다. 이러한 제한은 이미지 대 비이미지 데이터에 내재된 서로 다른 속성으로 인해 발생합니다. 예를 들어, GAN은 연속적인 값 데이터를 생성하기 위해 작업하지만 자연어는 단어, 문자 및 바이트와 같은 이산 값을 기반으로 하기 때문에 이러한 데이터에 GAN을 성공적으로 적용하는 것은 어렵다. 이 분야 역시 매우 유망한 분야인 만큼, 이 분야에서 성공을 거두면 라이브 스트리밍에 대한 자막과 댓글 생성 등 많은 응용 프로그램으로 이어질 것이다. 보건과 같은 연구 영역은 특히 개인 정보 보호 문제에 민감하며 성공적인 데이터 증강은 이러한 영역에 상당한 영향을 미칠 것이다. 그러나 시계열 데이터와 같은 응용 분야와 관련된 다른 데이터 모달리티의 생성은 제한된 방법으로만 탐구되었다. 여기서 주목할 만한 과제는 그러한 영역에서 GAN의 성능을 평가하기 위한 효율적인 메트릭의 부족을 포함한다. 이 분야에서는 더 많은 연구가 필요하다.
8 CONCLUSION
이 기사에서는 더 높은 이미지 품질, 더 다양한 이미지 및 훈련의 안정성 측면에서 제공되는 성능 개선을 기반으로 한 GAN 변형을 검토했다. 아키텍처와 손실 기반 모두에서 GAN 관련 연구의 현재 상태를 검토했다. 배치 크기가 더 큰 더 복잡한 아키텍처는 이미지 품질과 이미지 다양성, 즉 BigGAN의 증가와 관련이 있다. 그러나 제한된 GPU 메모리는 많은 이미지 배치를 처리하는 데 문제가 될 수 있다. 대안으로 PROGAN에 사용된 점진적 훈련 전략은 매우 큰 이미지 배치 없이 이미지 품질을 높일 수 있다. 이미지 다양성의 측면에서, 생성기와 판별기 모두에 자기 주의 메커니즘을 추가하는 것은 ImageNet 데이터 세트를 사용하여 강력한 성능을 입증하는 SAGAN으로 흥미로운 결과를 달성했다. 훈련 안정성 측면에서 손실 함수는 여기서 중요한 역할을 하며 이 과제를 해결하기 위해 다양한 유형의 손실 함수가 제안되었다. 다양한 유형의 손실 함수를 검토한 결과, 스펙트럼 정규화는 모든 GAN에 적용할 수 있고 구현이 용이하며 계산 비용이 매우 낮다는 것을 발견했다. BigGAN 및 PROGAN과 같은 현재 최첨단 GAN 모델은 컴퓨터 비전 분야에서 고품질 이미지와 다양한 이미지를 생성할 수 있다. 그러나 비디오의 더 어려운 시나리오에 GAN을 적용한 연구는 제한적이다. 또한 시계열 생성 및 자연어 처리와 같은 다른 분야의 GAN 관련 연구는 성능과 능력 면에서 컴퓨터 비전에 비해 뒤처진다. 우리는 특히 이러한 분야에서 향후 연구와 적용의 기회가 분명히 있다고 결론짓는다.
