2. Data transfer instructions(DTI)
- 하나의 레지스터를 load and store 가능
- byte, half-word, word 단위로 메모리와 레지스터 간의 정보 이동 가능 - 여러개의 레지스터 load and store 가능
- less flexible but 많은 양의 데이터를 옮길 수 있음
- 함수 실행 시 data를 저장, load할 때 유용
- data의 blocks를 복사할 때도 사용 - 레지스터와 메모리의 data를 동시에 교환하는 swap instruction도 있음(단일 레지스터에 한 함)
➔ data가 접근하는 순서에 따라서 결과가 달라지는 조건일 때 사용
DTI : Register-indirect addressing
- base register : 메모리 주소값이 저장된 레지스터
LDR r0, [r1]
STR r0, [r1]- 여기서 r1이 base address → word address이므로 2LSBs가 0이어야 함.
LDRB r0, [r1] ;r0[7:0] = mem8[r1]- byte address이므로 r1에 어떤 제한도 없음
- r0[31:8]은 0으로 채워짐.(byte 단위로 읽어온 것이므로)
DTI : Initializeing an address pointer
Pseudo-instruction
- assembly codes의 정상적인 명령어
- but ARM 명령어로는 변환되지 않음
➔ 컴파일러나 어셈블러가 달라지면 pseudo-instruction도 달라짐. - Assembler가 Pseudo명령어를 처리하기 위해 적절한 ARM 명령어의 set을 만듦
- ADR : register를 초기화하는 pseudo 명령어
- Label : assembly code의 특정 point를 구체화해주는 것
- table1을 table2에 복사하는 코드
COPY ADR r1 TABLE1 ;r1에는 TABLE1의 주소가 들어감
ADR r2 TABLE2 ;r2에는 TABLE2의 주소가 들어감
LOOP LDR r0, [r1] ;r1이 가리키는 값이 r0로 들어감
STR r0, [r2] ;r0의 값이 r2가 가리키는 메모리로 들어감
TABLE1 ... ;data의 source
TABLE2 ... ;data의 목적지- 값을 여러 개 읽어올 때는 ADR + LDR
- 값 조금 읽어올 때는 LDR
DTI : Single register load and store instructions
COPY LDR r1 VALUE1 ;r1에는 VALUE1가 가리키는 값이 들어감(r1 = &0000a000 )
LDR r2 VALUE2 ;r2에는 VALUE2가 가리키는 값이 들어감(r2 = &0000a008 )
MOV r3, #7 ;r3에 7을 넣음
STR r3, [r1] ;mem32[&0000a000] = r3 = 7
LDR r0, [r1] ;r0 = mem32[&0000a000] = 7
STR r0, [r2] ;mem32[&0000a008] = r0 = 7
VALUE1 DCD &0000a000 ;VALUE1 = &0000a000
VALUE2 DCD &0000a008 ;VALUE2 = &0000a008 - DCD : memory에 word를 할당 ⇒ 메모리 할당
➜assembler/linker가 address를 결정
data1 DCD 1,5,20 ;memory에 3words 할당 그 안에 1,5,20을 넣어
data2 DCD mem06 ;memory에 1word 할당 그 안에 label인 mem06의 주소를 넣어
data3 DCD glb + 4 ;memory에 1word 할당 그 안에 4 + glb의 값을 넣어COPY LDR r1 VALUE1 ;r1에는 VALUE1가 가리키는 값이 들어감(r1 = &0000a000 )
LDR r2 VALUE2 ;r2에는 VALUE2가 가리키는 값이 들어감(r2 = &0000a008 )
MOV r3, #7 ;r3에 7을 넣음
STR r3, [r1] ;mem32[&0000a000] = r3 = 7
LDR r0, [r1] ;r0 = mem32[&0000a000] = 7
STR r0, [r2] ;mem32[&0000a008] = r0 = 7
;주소 변환(다음 word로)
ADD r1, r1, #4 ; r1 = r1(&a000) + 4 = &a004
ADD r2, r2, #4 ; r2 = r2(&a008) + 4 = &a00c
;다음 주소에 r0값을 넣음
LDR r0, [r1] ;r0 = mem32[&0000a004] = 7
STR r0, [r2] ;mem32[&0000a00c] = r0 = 7 (copy)
VALUE1 DCD &a000, &a004 ;source of data
VALUE2 DCD &a008, &a00c ;destination- &a004, &a00c로 메모리 할당 → 이 메모리 read/write 가능
DTI : Base plus offset addressing
- address 계산
- base address에 offset을 더함
- offset은 4Kbytes까지 (12bit에 해당하는 addr offset)
- Pre-indexed addressing mode
- 주소 연산 먼저
- LDR r0, [r1,#4] ; r0 := mem32[r1+4]
- Pre-indexed addressing with auto-indexing
- 주소 연산 먼저
- 연산한 주소로 base address 변경(추가적인 cycle 없이)
- !가 있어야 해
- LDR r0, [r1,#4]! ; r0 := mem32[r1+4] ;r1 := r1 + 4
- Post-indexed addressing
- 먼저 명령어 수행
- 그 다음에 주소 연산
- LDR r0, [r1], #4 ; r0 := mem32[r1] ;r1 := r1 + 4
✮ Ex. Pre-indexed addressing
- 코드가 차지하는 메모리 감소
- 실행 cycle 수 감소
- ADD 명령 안 써도 돼
COPY LDR r1 VALUE1 ;r1에는 VALUE1가 가리키는 값이 들어감(r1 = &0000a000 )
LDR r2 VALUE2 ;r2에는 VALUE2가 가리키는 값이 들어감(r2 = &0000a008 )
MOV r3, #7 ;r3에 7을 넣음
STR r3, [r1] ;mem32[&0000a000] = r3 = 7
LDR r0, [r1] ;r0 = mem32[&0000a000] = 7
STR r0, [r2] ;mem32[&0000a008] = r0 = 7
;다음 주소에 r0값을 넣음
LDR r0, [r1, #4] ;r0 = mem32[&0000a004] = 7
STR r0, [r2, #4] ;mem32[&0000a00c] = r0 = 7 (copy)
VALUE1 DCD &a000, &a004 ;source of data
VALUE2 DCD &a008, &a00c ;destination✮ Ex. Post-indexed addressing
COPY LDR r1 VALUE1 ;r1에는 VALUE1가 가리키는 값이 들어감(r1 = &0000a000 )
LDR r2 VALUE2 ;r2에는 VALUE2가 가리키는 값이 들어감(r2 = &0000a008 )
MOV r3, #7 ;r3에 7을 넣음
STR r3, [r1] ;mem32[&0000a000] = r3 = 7
LDR r0, [r1], #4 ;r0 = mem32[&0000a000] = 7 ;r1 := r1 + 4
STR r0, [r2], #4 ;mem32[&0000a008] = r0 = 7 ;r2 := r2 + 4
;다음 주소에 r0값을 넣음
LDR r0, [r1] ;r0 = mem32[&0000a004] = 7
STR r0, [r2] ;mem32[&0000a00c] = r0 = 7 (copy)
VALUE1 DCD &a000, &a004 ;source of data
VALUE2 DCD &a008, &a00c ;destinationDTI : Multiple register data transfers
- LDM/STM : load multiple/ store multiple
⇒ processor의 state를 save하고, data의 block들을 메모리에 옮김 - 장점 : code space를 줄일 수 있음.(그냥 single 명령어의 냐열보다 4배 빨라)
⇒ 순수한 RISC와는 달라 (single cycle 명령어랑은 다름)
LDMIA r1 {r0, r2, r5} ;r0 := mem32[r1]
;r2 := mem32[r1 + 4]
;r5 := mem32[r1 + 8]
;r1에 mem주소가 있음
;r1에 ! 안 붙이면 r1이 변하지 않음(!는 auto-indexing 표시) ✮ 뽀인트
- 하나의 명령어로 레지스터들의 부분 집합들이 load/store
- 레지스터들의 순서는 중요하지 않아(reg 뒤 번호 순으로 data transfer 진행됨)
- r15가 레지스터 리스트 안에 있으면 control flow가 바뀔 수 있음
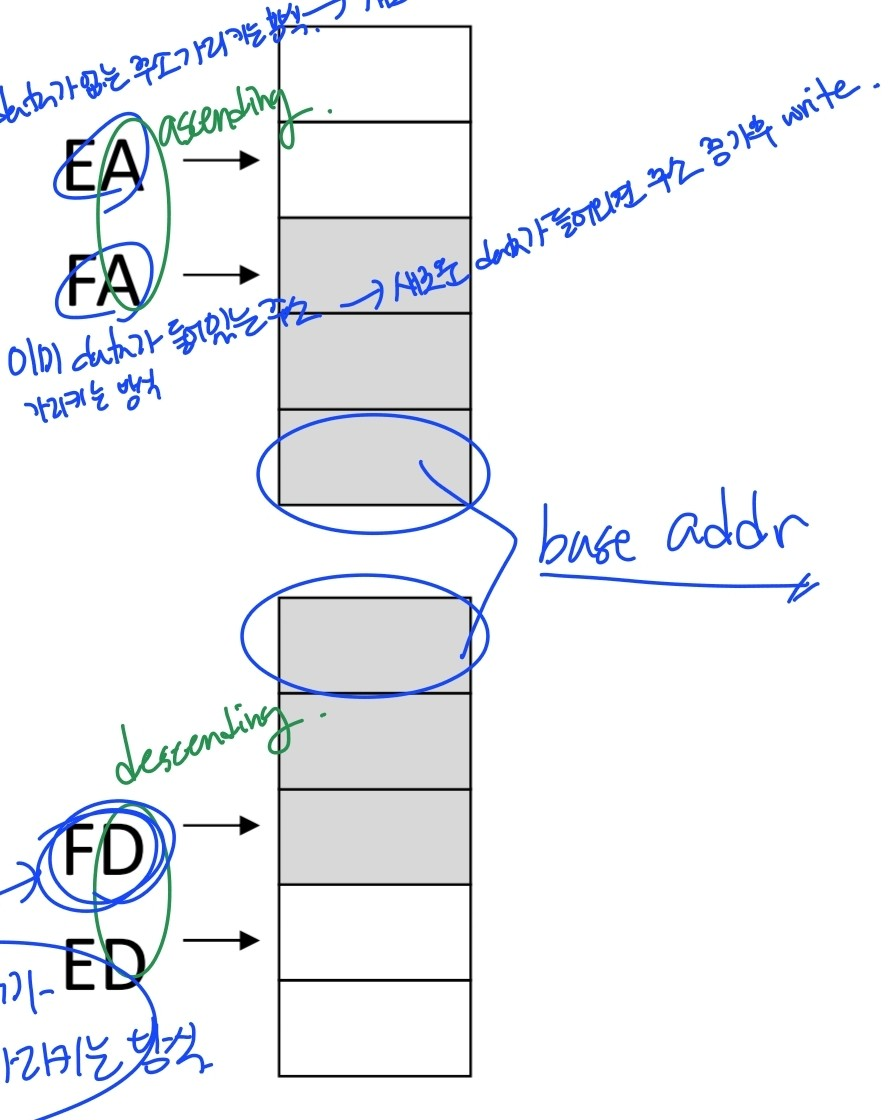
DTI : Stack and block copy addressing
Stack addressing
- memory에 stack처럼 선형적으로 주소가 증/감하며 data가 저장됨.
- stack pointer : address pointing current top of the stack
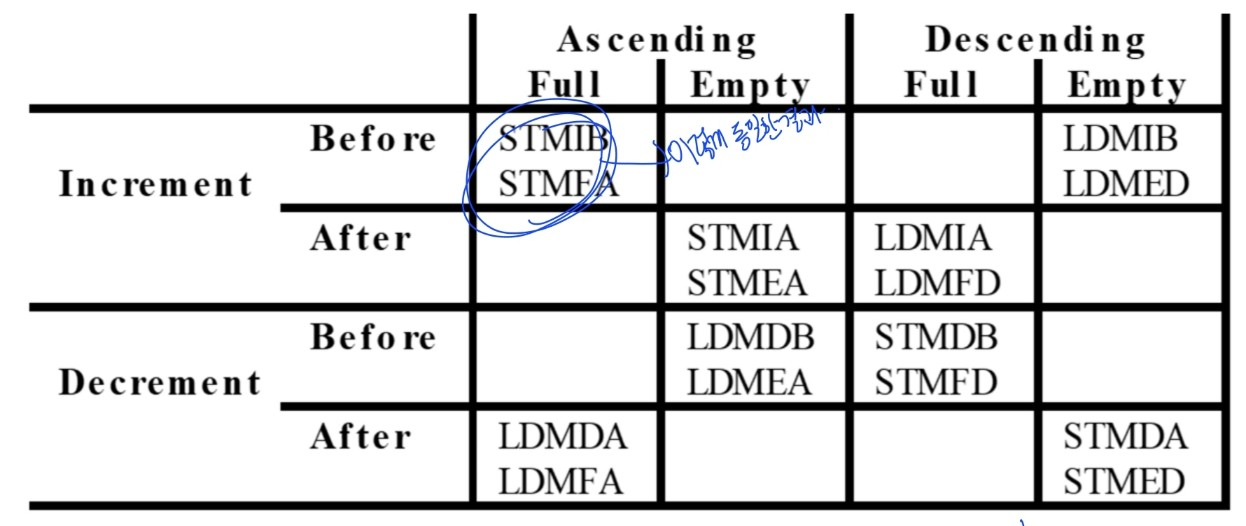
- Stack organizations(stack을 구현하면서 주소값을 어떻게 변화시킬건지, stack pointer가 어디를 가리킬건지를 나타냄)
- FA : full ascending
- EA : empty ascending- FD : full descending
- ED : empty descending
- full 방식 : pointer가 가리키는 주소에 이미 data가 들어있음 → 새로운 data가 들어오면 주소 증가 후 write
- empty 방식 : pointer가 가리키는 주소에 data 없음 → 새로운 data가 write 후 주소 증가
Block copy addressing
- data의 block을 메모리에 copy하는 방식
- base register가 가리키는 주소의 위 혹은 아래에 저장
- 주소를 바꾸는 방법에 따라 IA, IB, DA, DB 방식이 있음
- 높은 주소에 높은 번호의 register가 저장됨
- Ex. r9(start addr.) → r9' (final addr. auto indexing)
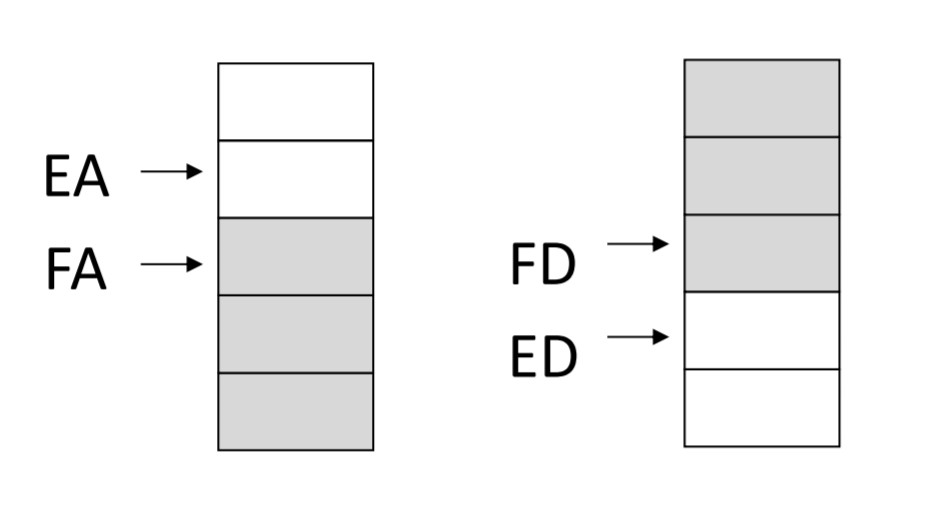
Mapping between the stack and block copy views
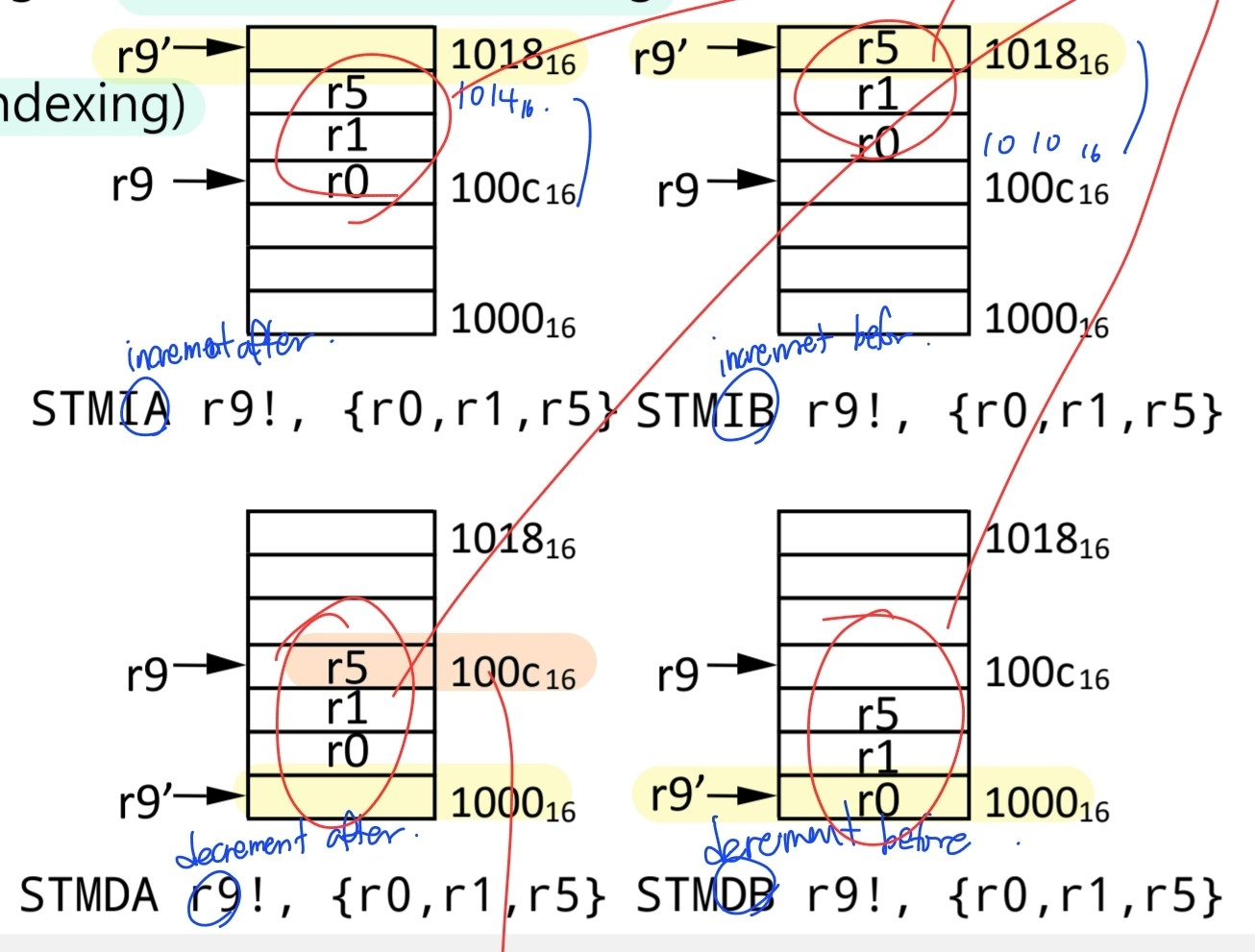
Examples
LDMIA r0! {r2 - r9} ;r0는 명령이 끝난 후 32만큼 증가
STMIA r1 {r2 - r9} ;auto-indexing X -> r1은 변하지 않음STMFD r13! {r2 - r9} ;STMFD = STMDB ;regs를 stack에 저장 (r13 := r13 - 32)
STMIA r0! {r2 - r9} ;STMIA = STMEA ;regs의 block을 복사 (r0 := r0 + 32)
LDMDB r1, {r2 - r9} ;LDMDB = LDMEA ;block of data를 memory에서 restore(auto-indexing X)
LDMFD r13!, {r2 - r9} ;LDMFD = LDMIA ;stack restore(auto-indexing)3. Control Flow Instructions(CFI)
- 다음 명령어를 결정해주는 명령어
- Branch(B) 명령어
- Conditional branches
MOV r0, #0 ;counter 초기화
LOOP ADD r0, #1 ;loop counter 증가
CMP r0, #10 ;r0가 10이 아니면
BNE LOOP ;LOOP로 branchCFI : Branch conditions
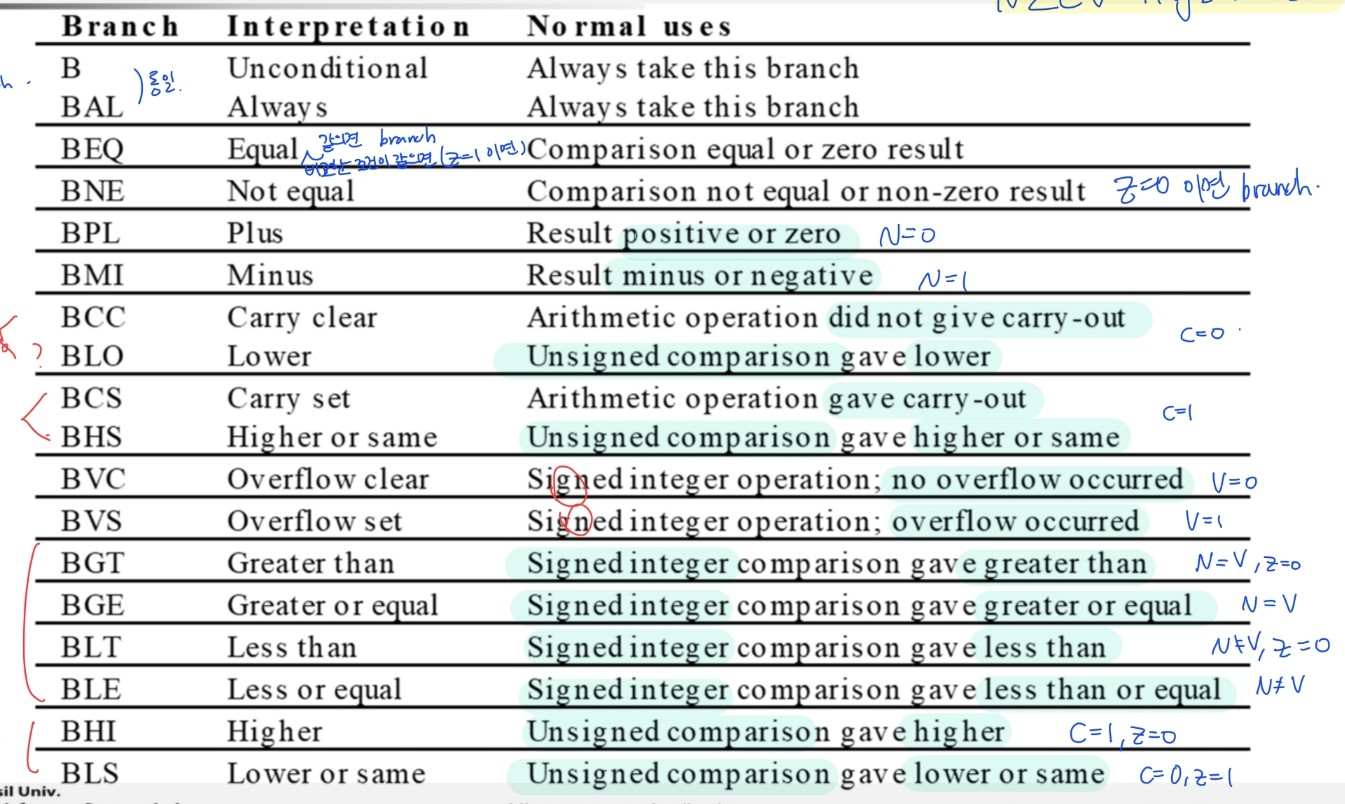
CFI : Conditional execution
- 모든 ARM 명령어는 conditional execution 가능
-EX1
CMP r0, #5 ;r0와 5 비교
BEQ BYPASS ;if(r0 != 5){
ADD r1, r1, r0 ;r1 := r1 + r0 - r2
SUB r1, r1, r2 ;}
BYPASS -EX2
- branch 명령어 → 실행 사이클이 긺
- conditional execution을 통해 branch 명령을 줄일 수 있음
- 조건을 따져야 하는 명령어가 많지 않으면 conditional execution이 좋음
CMP r0, #5 ;r0와 5 비교
;if(r0 != 5){
ADDNE r1, r1, r0 ;r1 := r1 + r0 - r2
SUBNE r1, r1, r2 ;} -EX3
- compact code using conditionals
CMP r0, r1 ;a==b인지 확인
CMPEQ r2, r3 ;a==b이면 c==d인지 확인
ADDEQ r4, r4, #1 ;a==b & c==d이면 e++ CFI : Branch and link instructions
- subroutine으로 branch할 때 사용하는 명령어 (c코드의 경우 func)
- 실행하던 PC를 저장해둬야 나중에 subroutine을 빠져나와 원래 실행하던 PC를 다시 실행할 수 있음
- 이 PC를 r14에 저장해둠 (link register)
BL SUBR ;SUBR로 branch
...
SUBR ...
MOV pc, r14 ;원래 pc로 return - Nested subroutine : func1에서 func2를 부르면 link register에 있던 주소값이 overwrite됨
⇒ 원래 r14에 있던 주소값을 stack에 넣어야 함.
BL SUB1 ;SUBR로 branch
...
SUB1 ...
STMFD r13!, {r0-r2, r14} ;subroutine1의 work와 link register를 stack에 저장
BL SUB2 ;nested subroutine2로 branch
...
LDMFD r13!, {r0-r2, pc} ;subroutine1을 작업하기 전으로 복귀
SUB2 ...
MOV pc, r14 ;다시 sub1으로 복귀 (BL 다음 명령어로)CFI : Supervisor calls (system calls)
- Supervisor(routine) : privileged level(운영체제, 시스템 프로그램)에서 작동하는 program
- user-level program은 작업하지 못 함
- 확실히 검증된 코드를 사용하여 system resources에 접근해야해
- Ex. display에 text 전송- 하드웨어에 접근할 수 있는 권한을 가짐
- ARM ISA는 SWI를 포함함 (SoftWare Interrupt; supervisor call)
- system-dependent (시스템에 따라 코드가 의미하는 바가 달라져)
BL SUBR ;SUBR로 branch
...
SWI_WriterC EQU &0
SWI_Exit EQU &11 ;EQU : 변수에 값을 할당
SWI SWI_WriterC ; = SWI &0 : output r0[7:0]
SWI SWI_Exit ;= SWI &11 : user program에서 moniter로 제어권을 넘김
; 디스플레이에 어떤 값을 출력하는 ARM 명령어CFI : Jump tables
- program에서 계산된 값에 따라 여러 개의 subroutine들의 집합에서 하나를 골라 call
BL JTAB ;SUBR로 branch
...
JTAB CMP r0, #0 ;r0가 0이면 SUB0 선택
BEQ SUB0
CMP r0, #1 ;r0가 1이면 SUB1 선택
BEQ SUB1
CMP r0, #2 ;r0가 2이면 SUB2 선택
BEQ SUB2- 이러한 subroutine list가 너무 길거나, 모든 subroutine의 빈도가 비슷하면 오래 걸림
- 아래 코드는 이런 오래 걸리는 문제를 해결한 코드
BL JTAB ;SUBR로 branch
...
JTAB ADR r1, SUBTAB ;r1이 SUBTAB의 주소를 가리키게 함
CMP r0, #SUBTAB ;r0(원하는 subroutine 번호)와 SUBTAB의 개수 비교
LDRLS pc, [r1, r0, LSL #2] ;r0가 SUBTAB개수보다 작으면 pc에다가 r1+4*r0를 넣어 -> 원하는 subroutine 실행
B ERROR ;r0가 SUBTAB의 개수보다 많으면 ERROR
SUBTAB DCD SUB0 ;subroutine entry point의 table ;r0=0 일때의 subroutine entry point
DCD SUB1 ;r0=1 일때의 subroutine entry point
DCD SUB2 ;r0=2 일때의 subroutine entry point4. Writing simple assembly language programs
"Hello World" program
AREA HelloW, CODE, READONLY ;code area 선언
SWI_WriteC EQU &0 ;r0에 있는 character를 출력(system call)
SWI_Exit EQU &11 ;EQU : 변수에 값을 할당 ;finish program (system call)
ENTRY
START ADR r1, TEXT ;r1에 문자열이 저장되어 있는 메모리의 주소를 넣어
LOOP LDRB r0, [r1], #1 ;byte 단위로 data 읽어와(byte 단위라서 #1를 주소에 더해줌)
CMP r0, #0 ;r0가 0인지 확인 (문자열이 끝났는지 확인하는 코드)
SWINE SWI_WriteC ;r0가 문자열의 끝이 아니면 문자열 print
BNE LOOP ;r0가 문자열의 끝이 아니면 다시 LOOP으로 돌아가서 data 읽어와
SWI SWI_Exit ;r0에 0이 들어가 있으면 시스템 종료
TEXT = "Hello ARM World", &0a, &0d, 0 ;0은 string의 끝을 의미 Block copy
AREA BlkCpy, CODE, READONLY ;code area 선언
SWI_WriteC EQU &0 ;r0에 있는 character를 출력(system call)
SWI_Exit EQU &11 ;EQU : 변수에 값을 할당 ;finish program (system call)
ENTRY
START ADR r1, TABLE1 ;r1에 TABLE1이 시작되는 주소를 넣어
ADR r2, TABLE2 ;r2에 TABLE2이 시작되는 주소를 넣어
ADR r3, T1END ;r3에 T1END이 시작되는 주소를 넣어
LOOP1 LDR r0, [r1], #4 ;TABLE1의 data를 읽어와(한번에 4개의 character -> 맨 처음엔 This 읽어옴)
STR r0, [r2], #4 ;TABLE2에 TABLE1에서 읽어온 4개의 문자를 저장
CMP r1, r3 ;문자열이 끝났는지 아닌지 확인
BLT LOOP1 ;TABLE1의 문자열을 다 안 읽어왔으면 block copy 더 진행
ADR r1, TABLE2 ;TABLE1의 문자열을 TABLE2로 다 복사했으면 r1이 TABLE2의 주소를 가리키게 함
LOOP2 LDRB r0, [r1], #1 ;byte 단위로 data 읽어와(byte 단위라서 #1를 주소에 더해줌)
CMP r0, #0 ;r0가 0인지 확인 (문자열이 끝났는지 확인하는 코드)
SWINE SWI_WriteC ;r0가 문자열의 끝이 아니면 문자열 print
BNE LOOP2 ;r0가 문자열의 끝이 아니면 다시 LOOP2으로 돌아가서 data 읽어와
SWI SWI_Exit ;r0에 0이 들어가 있으면 시스템 종료
TABLE1 = "This is the right string!", &0a, &0d, 0 ;0은 string의 끝을 의미
T1END
ALIGN ;word align을 보장하는 코드
TABLE2 = "This is the wrong string!", &0a, &0d, 0 ;0은 string의 끝을 의미
;프로그램이 끝났을 때 wrong이 right으로 바껴야 제대로 코드가 실행된거임
END