
데이터셋 분리 (Dataset Split)
딥러닝 모델을 학습시킬 때는 데이터를 어떻게 나눠 쓰느냐가 성능에 큰 영향을 준다.
처음부터 끝까지 똑같은 데이터로만 학습과 평가를 하면 모델이 “암기”만 하게 되고, 실제 새로운 데이터를 만나면 제대로 동작하지 않을 수 있다.
그래서 데이터셋은 보통 Training / Validation / Test 세 가지로 나눈다.
Training vs. Validation vs. Test
-
Training data (훈련 데이터)
모델의 파라미터(가중치, 편향 등)를 학습하는 데 사용된다.
쉽게 말해 “연습 문제”다. -
Validation data (검증 데이터)
학습 중간중간 모델의 성능을 확인하고, 하이퍼파라미터를 조정하는 데 사용된다. 시험에 대비한 “모의고사 문제” 역할이다.
→ Gradient 계산과 파라미터 업데이트에는 참여하지 않는다. -
Test data (테스트 데이터)
학습이 끝난 최종 모델이 새로운 데이터에 대해 얼마나 잘 작동하는지 평가하는 데 사용된다. 즉, 진짜 “수능 문제” 같은 역할이다.
→ Training에 포함되면 안 된다! (실전 적합성을 확인해야 하기 때문)
왜 Validation이 필요한가?
Training 데이터만 사용하면 언제 학습을 멈춰야 하는지 판단하기 어렵다.
너무 오래 학습하면 Training 성능은 좋아지지만, 새로운 데이터에서는 오히려 성능이 떨어지는 오버피팅(overfitting) 문제가 발생한다.
Validation 데이터는 이럴 때 학습이 과한지(early stopping 필요 여부)를 알려주는 지표가 된다.
K-Fold Cross Validation
데이터가 많다면 Training과 Validation을 넉넉하게 나눌 수 있다.
하지만 데이터가 적다면 Validation에 쓰는 데이터가 아까울 수 있다.
이럴 때 사용하는 방법이 K-Fold 교차 검증(Cross Validation) 이다.
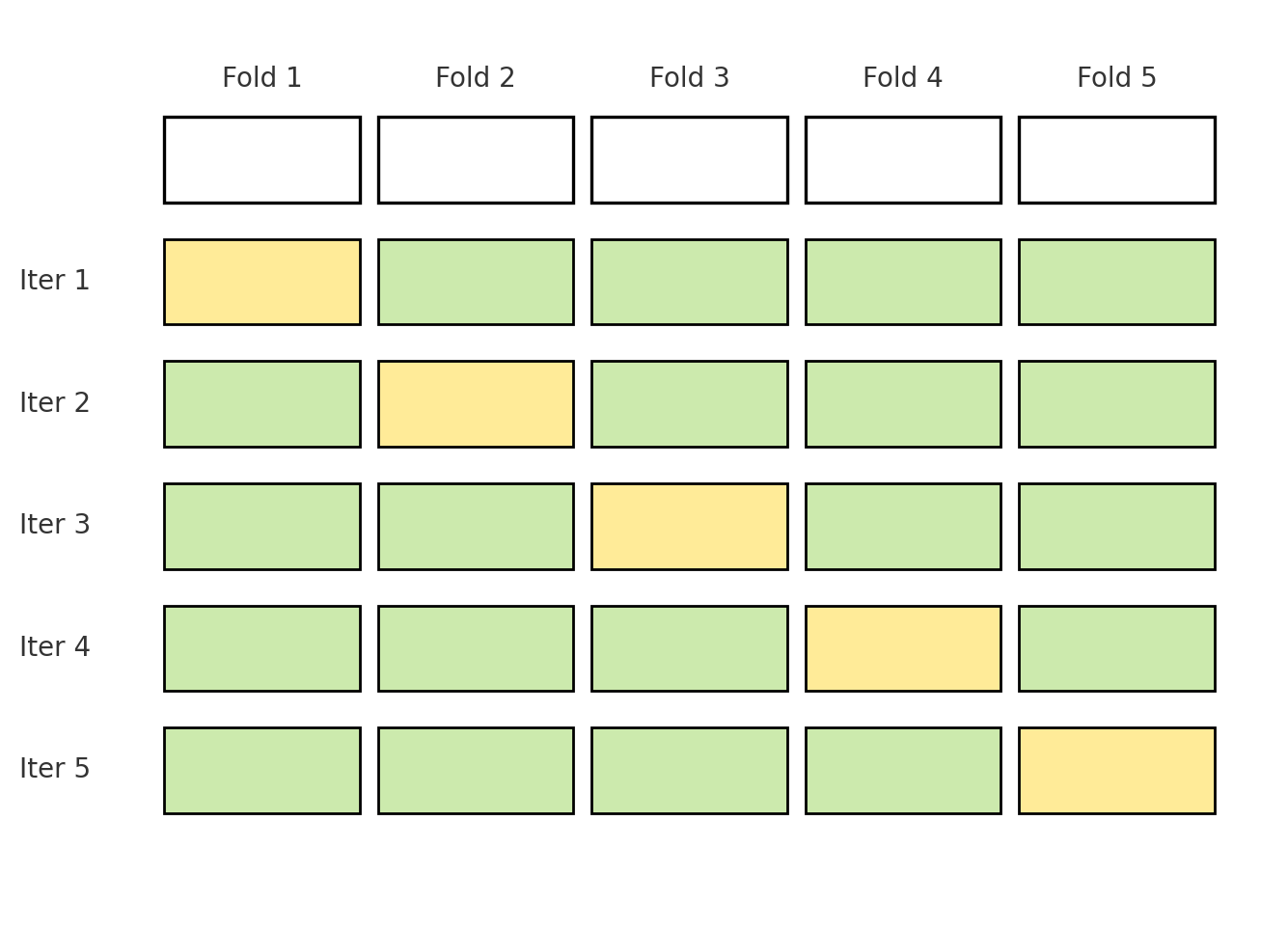
위 그림에서 K = 5.
- Training 데이터를 K등분으로 나눈다.
- 그중 1개는 Validation으로, 나머지 K-1개는 Training으로 사용한다.
- 이 과정을 K번 반복하면서 매번 다른 조합으로 Validation을 만든다.
- 최종적으로 K개의 Validation 성능을 평균 내어 모델의 일반화 성능을 평가한다.
→ 이렇게 하면 “편향된 Validation” 문제를 줄일 수 있다.
→ 하이퍼파라미터 튜닝에도 활용 가능하다.
→ 경우에 따라 학습된 K개의 모델을 앙상블(majority vote 등)로 합치기도 한다.
즉
- Training / Validation / Test 데이터는 각각 연습, 모의고사, 수능 같은 역할을 한다.
- Validation 데이터는 오버피팅을 방지하고 학습 중 모델 성능을 조율하는 데 필요하다.
- 데이터가 적을 때는 K-Fold Cross Validation으로 검증 안정성을 높일 수 있다.
