신경망 훈련에는 많은 수의 하이퍼파라미터 설정이 필요합니다.
빈번히 등장하는 하이퍼파라미터는 다음과 같습니다.
- 학습속도 초기값
- 각 레이어의 뉴런 수
- 배치 크기
- 정규화 강도 (Dropout strenth...)
- 매개변수 학습 시 가중치, 학습률의 경감
이번에는 하이퍼파라미터 최적화를 수행하기 위한 추가적인 방법에 대해 알아보겠습니다.
1. 검증 데이터 준비
데이터셋을 훈련을 위한 훈련데이터와 범용 성능을 테스트하기 위한 테스트 데이터로 나누는 것 외에 설정한 하이퍼파라미터의 성능을 평가하기 위한 또 다른 데이터를 준비해야 합니다.
만약 하이퍼파라미터의 성능평가를 훈련데이터 또는 테스트데이터로 같이 해버리면 하이퍼파라미터 또한 해당 데이터에 오버피팅(over-fitting) 되어 버리기 때문에 이를 피하기 위해 하이퍼파라미터 전용 확인 데이터가 필요합니다.
이를 일반적으로 검증 데이터(Validation data)로 부릅니다.
검증데이터를 얻는 가장 간단한 방법은 훈련 데이터 중 20%정도를 검증 데이터로 분리하여 사용하는 것입니다.

Python의 slice 기능을 사용하여 간단히 훈련 데이터와 훈련 데이터의 20%를 검증 데이터로 나누는 코드입니다.
2. 하이퍼 파라미터의 탐색
하이퍼파라미터 최적화의 핵심은 '최적값'이 존재하는 범위를 조금씩 줄여나간다는 것입니다.
우선 대략적인 범위를 설정하고 그 범위에서 무작위로 값을 샘플링한 후, 그 값으로 정확도를 평가합니다.
최종 정확도에 미치는 영향력이 하이퍼파라미터마다 다르기 때문입니다.
일반적으로 범위 내의 값을 그리드 서치(Grid Search)하는 것보다 무작위 샘플링이 더 낫다고 알려져있습니다.
(Random Search for Hyper-Parameter Optimization, “randomly chosen trials are more efficient for hyper-parameter optimization than trials on a grid”)
정확도를 살피면서 해당 작업을 여러 번 반복하며 하이퍼 파라미터의 '최적 값'의 범위를 좁혀갑니다.
3. 하이퍼 파라미터의 범위
하이퍼 파라미터의 범위는 '대략적으로' 지정하는 것이 효과적입니다.
실제로도 dropout(uniform(0,1)) 등을 제외한 경우
0.001에서 1,000사이 (10^-3 ~ 10^3)와 같이 로그 스케일(log scale) 단위로 범위를 제곱하며 지정합니다.
학습속도등의 하이퍼파라미터 값은 학습 동역학에 배수적인(multiplicative) 효과가 있기 때문에 빼거나 더하는 것보다 더 자연스럽습니다.
ex) 최초 학습속도가 0.001인경우 큰 영향을 미치지만 최고값이 10인 경우에는 거의 영향이 없음

4. 점점 촘촘한 검색으로
처음에는 10**[-6, 1] 정도로 넓찍하게 검색을 하다가 좋은 결과의 발생 부근으로 범위를 좁힐 수도 있습니다.
처음 구간에는 넓은 범위의 하이퍼파라미터 세팅에서는 하나도 학습하는 것이 없거나 무한대의 손실함수값으로 발산할 수 있으므로 1 epoch나 혹은 더 적게 훈련하는 게 도움이 될 수 있습니다.
그 다음 단계부터는 좀 더 좁은 범위에서의 검색을 5 epoch 등으로 차차 늘려가며 진행할 수 있습니다.
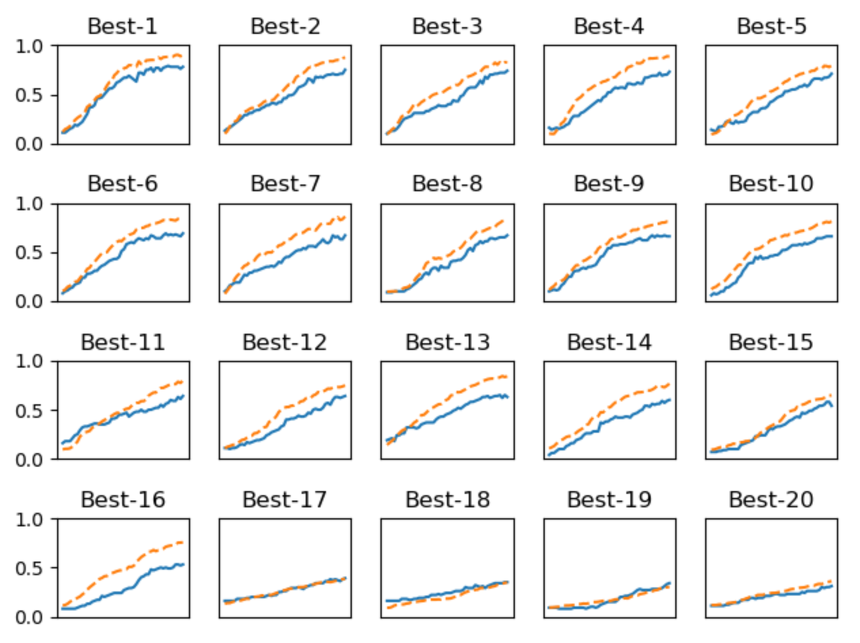
간단한 MNIST 신경망에 대해 learning rate 범위를 10^-6 ~ 10^-2, 가중치 감소 범위를 10^-8 ~ 10^-4,로하여 테스트한 후 정확도가 높은 순으로 나열한 결과는 다음과 같습니다.
(점선 : 훈련 데이터 정확도, 실선 : 검증 데이터 정확도)

Best-5까지는 학습이 순조롭게 진행되는 것으로 보아 해당 범위의 가중치 범위를 확인해보겠습니다

범위를 확인해본 결과 학습률은 0.001 ~ 0.01, 가중치 감소 계수는 10^-8 ~ 10^-6 으로 이루어져있는 것을 알 수 있습니다.
이부터 시작하여 점차 범위를 좁혀가며 특정 단계에서 최종 하이퍼 파라미터 값을 선택합니다.
Summary
1. 하이퍼 파라미터 초기 범위 설정
2. 설정된 범위에서 무작위 값 추출
3. 2단계에서 샘플링한 값으로 학습을 진행한 후 검증 데이터로 정확도를 평가 (단, epoch는 작게)
4. 2, 3단계를 특정 횟수 (100회 등) 반복하며, 그 정확도의 결과를 보고 하이퍼 파라미터의 범위를 좁혀갑니다
