저번글에 이어 문자열 검색 알고리즘 중 보이어-무어 알고리즘, 라빈-카프 알고리즘의 구동원리에 대해 알아보겠습니다.
부르트포스, KMP 알고리즘보다 향상된 알고리즘이라고 할 수 있으며 실전에서 더 자주 쓰인다고 합니다. 구동 원리에 대해 알아보겠습니다.
보이어-무어 알고리즘
KMP 알고리즘의 개선판이라고 할 수 있습니다. 시간복잡도는 최악의 경우 이지만 평균 의 시간복잡도를 가진다고 합니다. 인 KMP 알고리즘보다 향상된 성능을 기대할 수 있습니다.
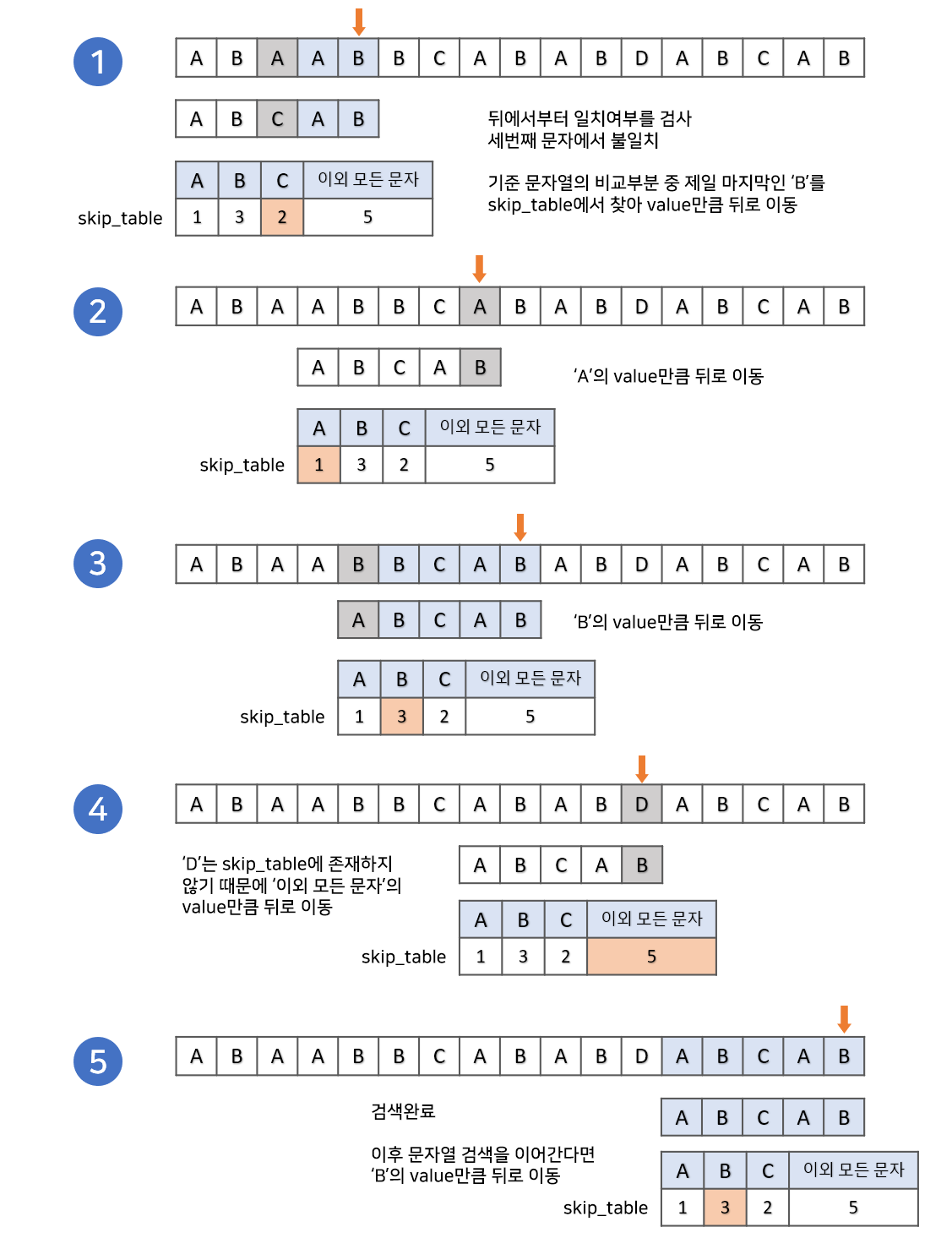
보이어-무어 알고리즘의 작동은 KMP 알고리즘과 유사하게 불필요한 비교는 건너뛰고 유의미한 비교만 진행하겠다는 것입니다. KMP 알고리즘의 경우에는 접두사와 접미사가 같은 최대길이를 저장하는 배열을 만들어 앞에서부터 검사를 진행하였다면, 보이어-무어 알고리즘은 문자열을 검색할때 주로 뒤에서 부터 확인합니다.
보이어-무어 알고리즘은 두가지 이동 방법이 존재하지만 주로 사용하는 bad match table 방법으로 작성해보겟습니다.
구현과정
KMP 알고리즘과 같이 건너뛰는 경우를 저장하는 배열(skip_table)을 만들어야 합니다. 이때 배열은 본문 문자열이 비교 문자열에 존재하는지, 존재한다면 불일치 시 얼만큼 건너뛰는지를 판단하는 정보를 가지고 만들게 됩니다.
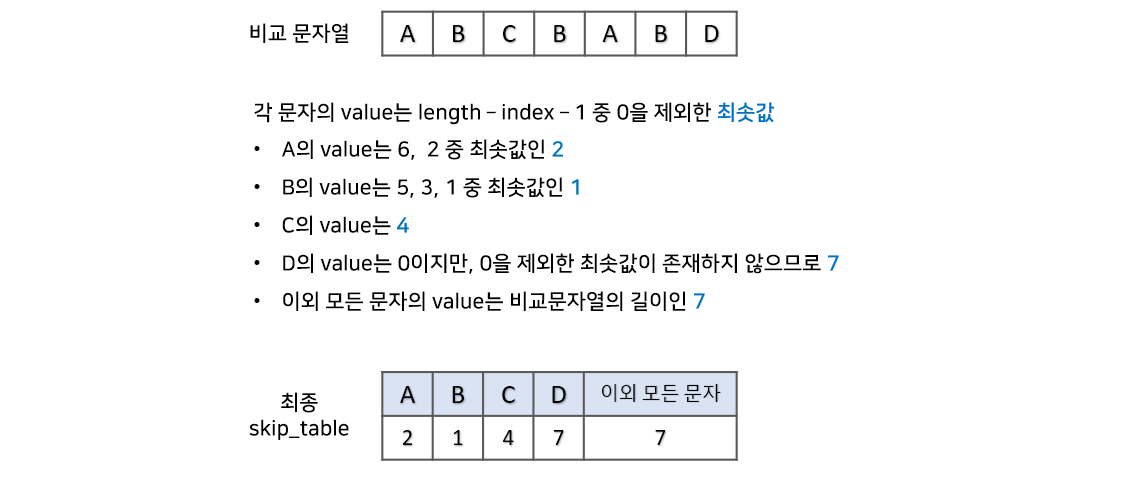
비교 문자열의 각 문자마다 건너뛰는 value 값을 가지는 skip_table이 만들어져야 합니다. value의 의미는 '문자열에 불일치가 일어나면 마지막 문자를 기준으로 skip_table의 value만큼 뒤로 이동시키겠다' 입니다. 각 문자의 value는 비교문자열 길이(length) - 문자열 index - 1 중 0을 제외한 최솟값으로 계산할 수 있습니다. 이외 모든 문자는 비교문자열의 길이(length)로 계산합니다.
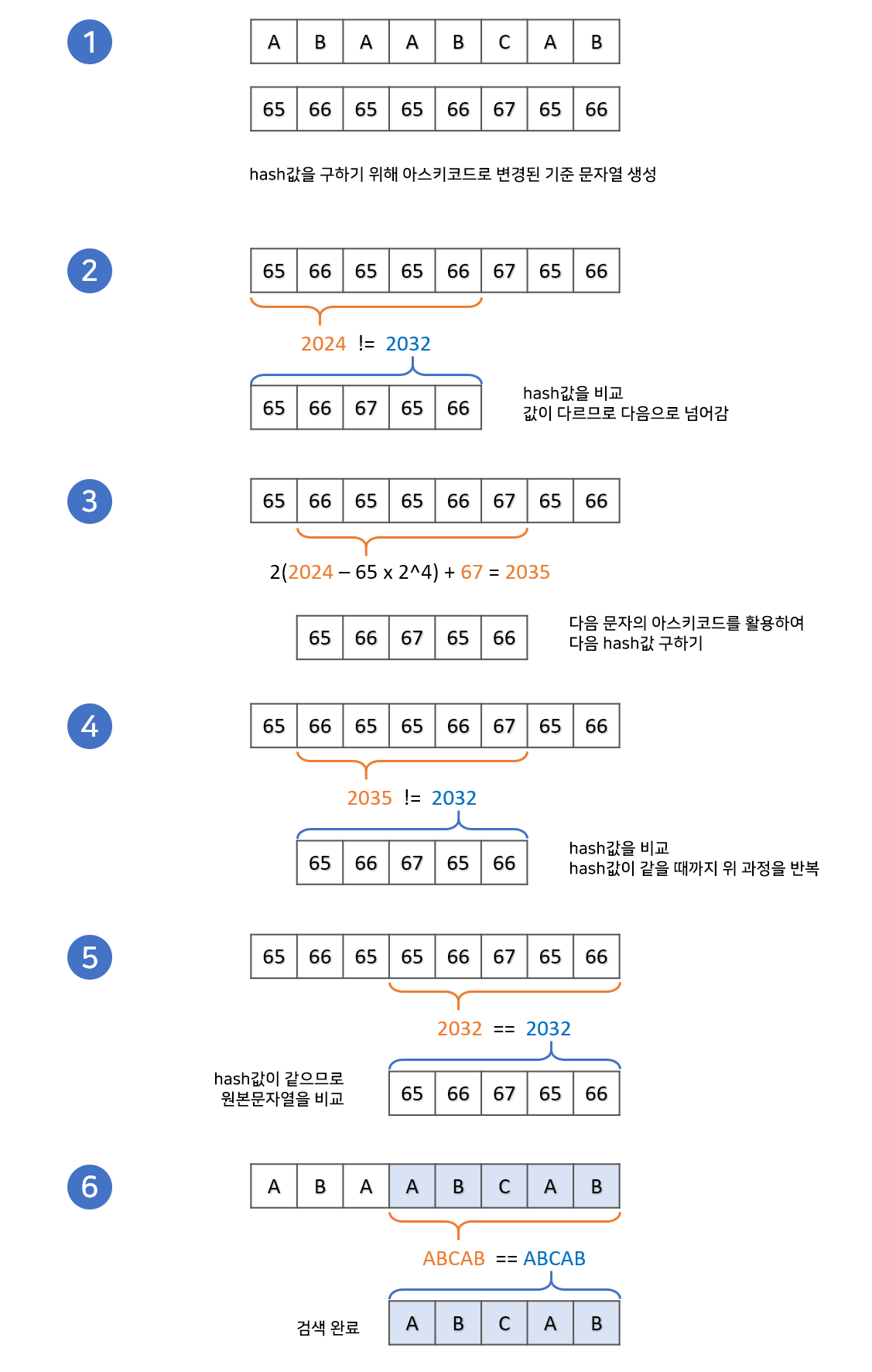
skip_table을 구했다면 문자열 검색을 시작합니다.
라빈-카프 알고리즘
문자열 검색에 hash값을 이용하는 알고리즘입니다. 문자열의 hash값을 한칸씩 옆으로 이동하면서 구하고, 해당 값을 비교 문자열의 hash값과 같은지 확인합니다. hash값이 똑같다면 두 문자열을 직접 비교하여 문자열을 검색합니다.
다만 의문점이 드는건 '매번 문자열의 hash값을 만들게 되면, 과 같은 시간복잡도를 만들게 되는 것 아닌가?' 입니다. 이런 부분을 Rabin-Karp fingerprint라는 해쉬함수를 사용하여 해결합니다. Rabin-Karp fingerprint 해쉬함수는 다음 문자열의 hash값을 에 계산할 수 있습니다.
Rabin-Karp fingerprint
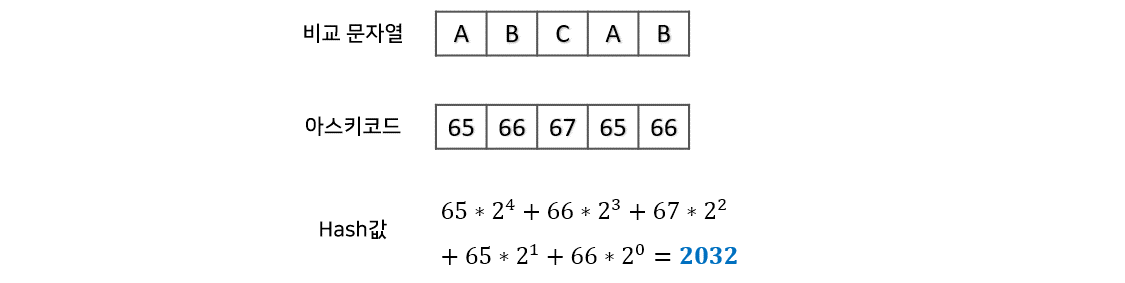
Hash는 hash값, S는 문자열의 아스키코드, i는 인덱스, n은 문자열의 길이라고 하면 Rabin-Karp fingerprint의 해쉬 함수는 아래와 같습니다.
간단히 말하면 문자열의 아스키코드 값마다 을 순서대로 곱하여 hash값을 구해주는 방식입니다. 여기서 O(1)로 다음 hash값을 구하는 방법은 다음과 같습니다.
아래 그림으로 보면 치환되는 부분을 더 직관적으로 알 수 있습니다.
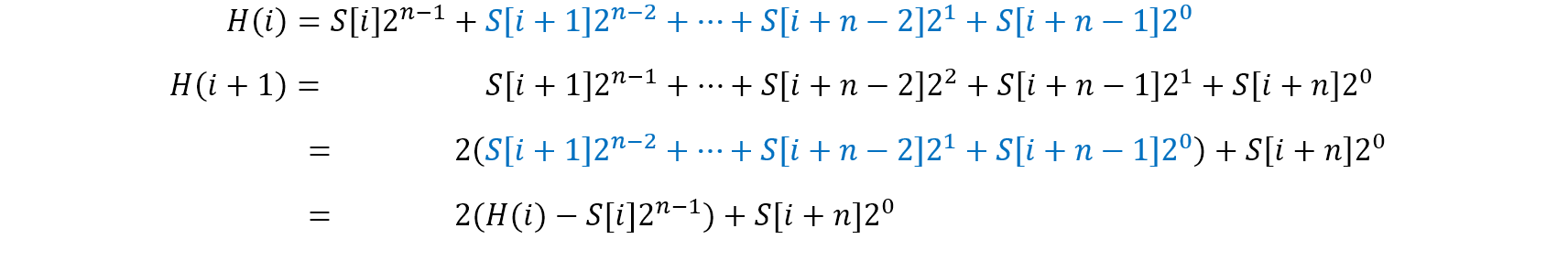
이렇게 맨 앞 문자의 아스키코드값, 바로 다음 문자의 아스키코드값만 알고있으면 로 다음 hash값을 구할 수 있습니다.
대표적으로 밑을 2로 사용한다고 합니다. 경우에 따라서 밑을 문자의 종류에 따라 바꿀 수 있다고 합니다. 아스키코드 모든 문자열을 포함한다면 256 등으로 설정이 가능하다고 합니다. 단 매우 큰 수 가 나외기 때문에 큰 수를 처리하는 연산이 필요하다고 합니다.
구현과정
해쉬값을 구했다면 작동원리는 부르트포스와 다르지 않습니다. 먼저 비교 문자열의 hash값을 구해줍니다.
이후 기준 문자열의 가장 처음 hash값을 구해주고, 차례대로 hash값을 구하면서 비교합니다.