이번 포스팅에서는 문자열 검색 알고리즘 중 부르트포스, KMP 알고리즘에 대해서 적어보겠습니다.
1. 부르트포스(단순비교)
브루트포스는 통상적으로 모든 경우를 검색하는 과정을 얘기하죠. 선형검색을 기반으로 순차적으로 단순비교를 진행하는 문자열 검색 알고리즘으로 가장 기초적이고 원시적인 방법입니다.
두 문자열의 길이의 곱만큼 연산을 진행하기에 시간복잡도는 입니다.
구현과정
문자열ABABCB에서 문자열ABC를 검색하는 경우입니다. 순차적인 비교이기 때문에 어렵지 않습니다.

2. KMP알고리즘
부르트포스 알고리즘에서 개선된 문자열 검색 알고리즘입니다. 비교가 필요하지 않은 부분은 건너뛰고 비교가 필요한 부분만 비교함으로써 성능을 개선시키는 알고리즘입니다.
부르트포스 알고리즘의 시간복잡도가 이었다면, KMP 알고리즘의 시간복잡도는 입니다. 브루트포스에 비하면 상당한 속도 개선이 이루어집니다. 하지만 패턴안에 반복이 없으면 효율이 좋지 않다는 단점이 있습니다.
구현과정
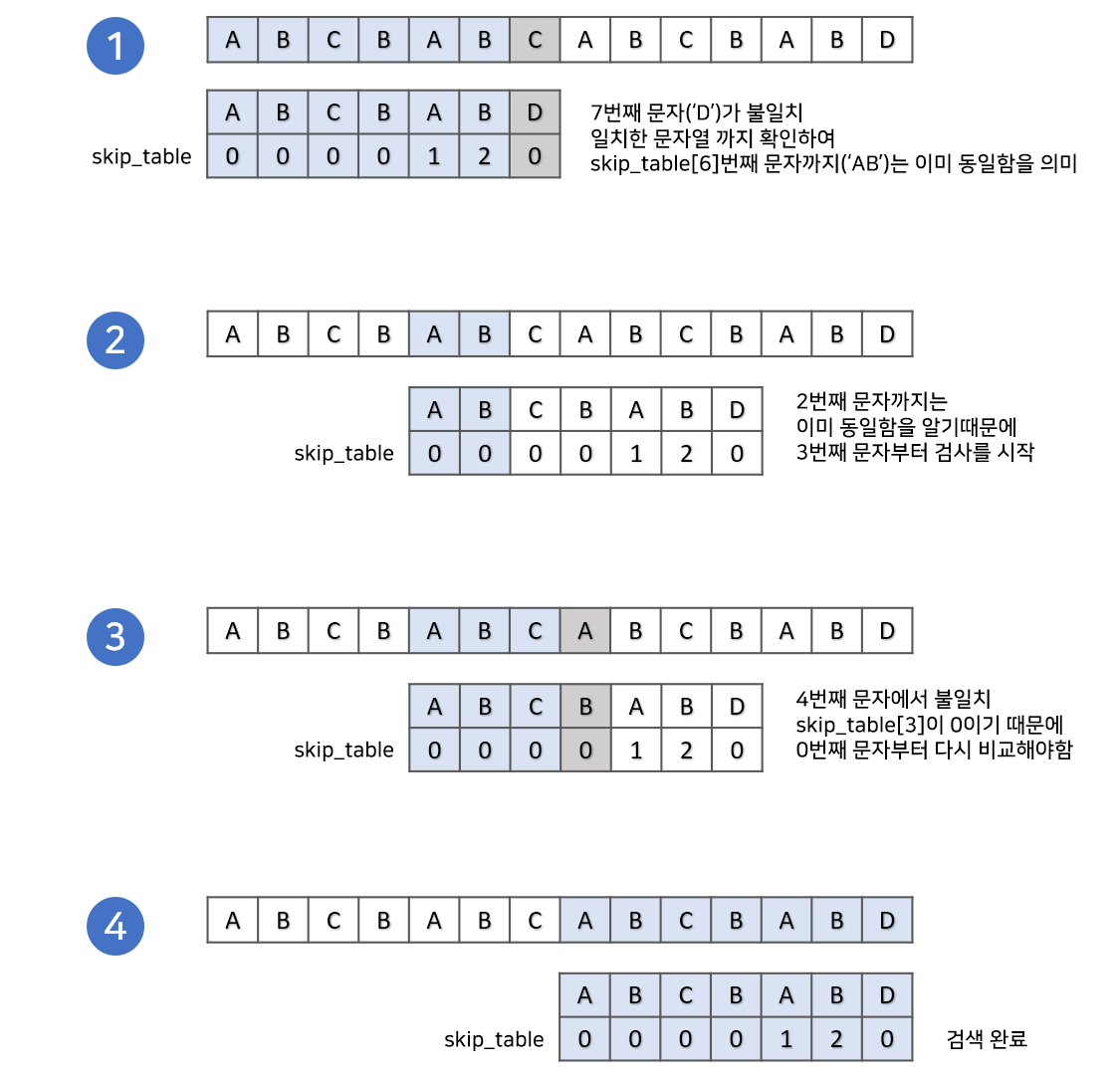
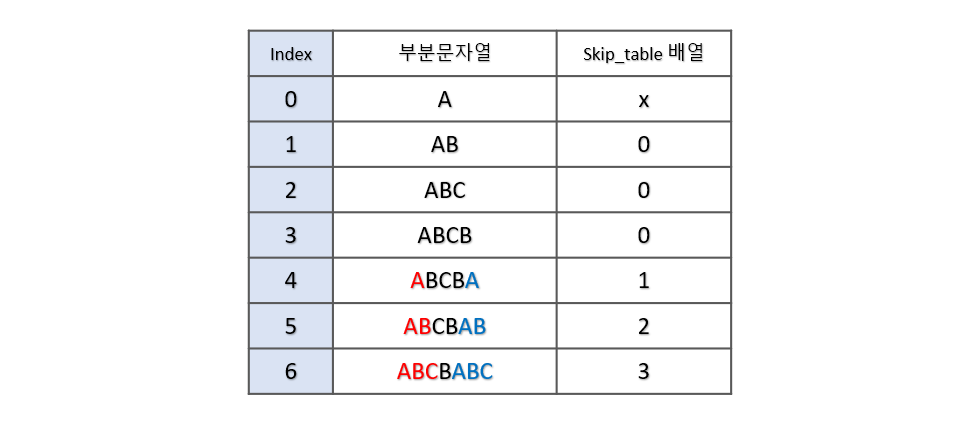
검색과정 이전에 먼저 건너뛰는 경우를 저장하는 배열(skip_table)을 만들어야 합니다. 배열은 접두사, 접미사의 정보를 이용하여 만들게 됩니다. 비교할 문자열의 부분문자열을 길이 순서대로 구한 후, 접두사와 접미사가 같으면서 제일 긴 경우의 길이를 저장합니다.
문자열 ABCBABC의 경우 아래와 같이 skip_table 배열로 [0, 0, 0, 0, 1, 2, 3]을 가지게 됩니다. 접미사와 접두사는 원본 배열의 길이보다 작아야 합니다. index = 0 에서는 접미사 접두사가 생기지 않기 때문에 그림에서 x로 표기하였습니다.
위에서 구한 skip_table정보를 이용하여 문자열 검색을 시작합니다. 핵심은 본문 문자열과 비교 문자열이 달라지는 부분이 있다면 이전까지 중 접두사와 접미사가 가장 큰 부분을 다시 검사하지 않는 것 입니다.