Background
RNN Encoder-Decoder 설명
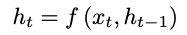
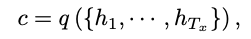
는 t시점에서 히든 스테이트, 는 히든 스테이트 시퀀스에서 나온 벡터
Decoder는 context vector c가 encoder로부터 주어졌을 때, c와 이전에 예측한 결과 을 기반으로 다음 단어 예측.
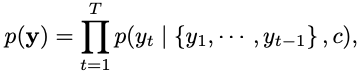
이 조건부 확률을 최대화하는 모델을 찾는게 목표.
Learning to Align and Translate
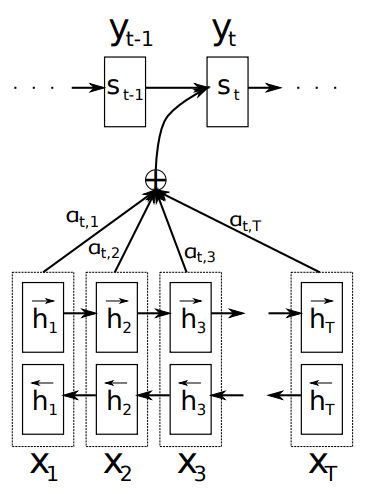
디코더
일반적인 encoder-decoder 구조와 달리 context vector 는 target word 에 고유한 값이다.
-
context vector
에 의해 결정됨. -
annotation
인풋 문장 전체의 정보를 가지고 있고 i번째 단어에 강조 -
Alignment Model
j 위치의 인풋과 i위치의 아웃풋이 얼마나 잘 매치하는지 계산하는 함수
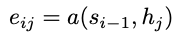
는 feedforward neural network
'soft alignment' -> 비용 함수의 그레디언트가 역전파되도록 함.
- 에서의 가중치 수식
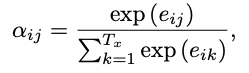
는 target word 가 source word 와 얼만큼의 연관이 있는지 나타내고, decoder는 이걸 바탕으로 어떤 위치의 단어에 더 attention을 줄지 판단 가능.
-> 모든 문장을 하나의 고정된 길이의 벡터로 변환하지 않고도 더 좋은 성능 낼 수 있음.
인코더
뒷 내용까지 읽기 위해 bidirectional RNN 사용
Forward RNN은 생성, Backward RNN은 생성
j시점의 hidden state 는 forward hidden state와 backward hidden state가 연결된 결과
최근 인풋의 정보를 더 많이 가지고 있는 RNN의 특성상 와 가까운 위치에 있는 단어들의 정보를 더 많이 가지게 됨.
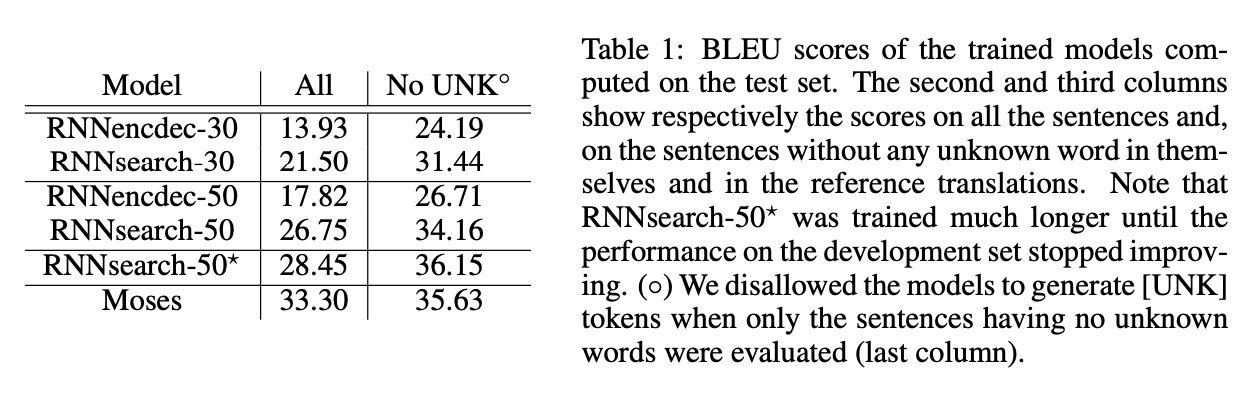
Results
Source 1

RNNencdec-50

RNNsearch-50

Source 2
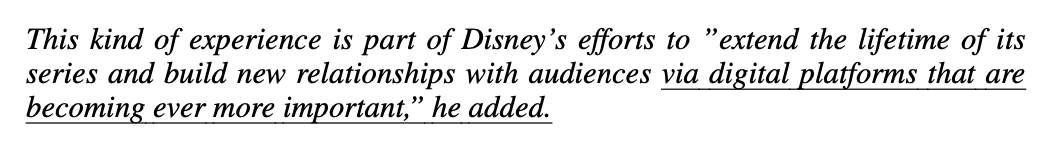
RNNencdec-50

RNNsearch-50

RNNsearch-50가 좀 더 괜찮음.
Related Work
Conclusion
