
1. Introduction
이전 단어 표현 모델들은 문맥을 고려하지 못한다는 단점이 있었다.
ELMo의 목적은
- 단어 사용의 특성 ex. syntax, semantic 특성
- 문맥에 따라 달라지는 단어 사용
을 해결하자!
ELMo 는 Embeddings from Language Models 의 약자로, 이름에서 알 수 있듯이 언어 모델로 임베딩을 한다. 문장 전체를 넣어서 표현을 만든다는게 엘모의 특징. 각 표현은 사실 인풋 문장 전체의 함수와 같다. 즉 문장이 달라짐에 따라 단어 벡터도 달라진다는 뜻.
높은 레벨의 LSTM은 context-dependent 한 의미를 파악할 수 있고, 낮은 레벨의 LSTM은 구조적인 의미를 파악할 수 있다.
3. ELMo: Embeddings from Language Models
3.1. Bidirectional Language Models
- forward language model
input sentence가 N개의 토큰으로 이루어져 있다고 할 때, 의 정보를 가지고 토큰 의 확률을 계산한다.
context-dependent 한 토큰 를 L개의 층으로 이루어진 forward LSTM에 넣으면 아웃풋으로 벡터가 나온다. (
마지막 층의 아웃풋인 은 소프트맥스 층을 거쳐 다음 토큰인 을 예측하게 된다.
- backward language model
반대 방향도 방식은 똑같은데 대신 미래의 문맥 으로 이전 토큰 을 예측한다.
- biLM
forward, backward 붙이면 됨.
는 token representation(t1,...,tN)에 대한 parameter, 는 softmax layer에 대한 parameter이다. 얘네들은 방향 상관없이 같은걸 공유하지만, 이외 파라미터는 각 방향에 맞게 다른 값을 갖는다.
3.2. ELMo
토큰 에 대해서 L개 층의 biLM은 2L + 1 개의 표현을 가진다. 하나의 토큰 층과 L개의 forward, L개의 backward인 듯.
는 각 biLSTM 층의 아웃풋 벡터이고, 은 토큰 층이다.
밑의 식처럼 다시 쓸 수 있다.
인 것 같다.
는 L개 층의 표현을 다 모아놓은 것인데 이걸 한 벡터로 합칠 수 있다.
는 소프트맥스 정규화 가중치
는 전체 ELMo 벡터를 스케일링하는 파라미터. 최적화할 때 중요한 파라미터이다.
3.3. Using biLMs for supervised NLP tasks
사전학습된 biLM을 NLP 태스크에 활용하기
- biLM 돌리고 각 단어의 표현을 기록
- 태스크에 사용하는 모델이 이 표현의 선형결합을 학습
a. 모델의 제일 낮은 층에 ELMo 더함
b. 의 토큰이 주어지면 사전훈련된 워드 임베딩으로 context-independent 표현 을 만들 수 있음.
c. RNN, CNN 등으로 context-sensitive 를 만들 수 있음.
ELMo를 지도학습 모델에 추가하려면
biLM의 가중치 그대로 고정하고,
와 연결 후 RNN에 넘김
3.4. Pre-trained bidirectional language model architecture
이전pre-trained biLM과 다른 점은
양방향 사용 + residual connection
4. Evaluation
ELMo를 6개의 벤치마크 태스크 (Question Answering, Textual Entailment, Semantic Role Labeling, Conference Resolution, Named Entity Extraction, Sentiment Analysis) 로 평가해보았다.
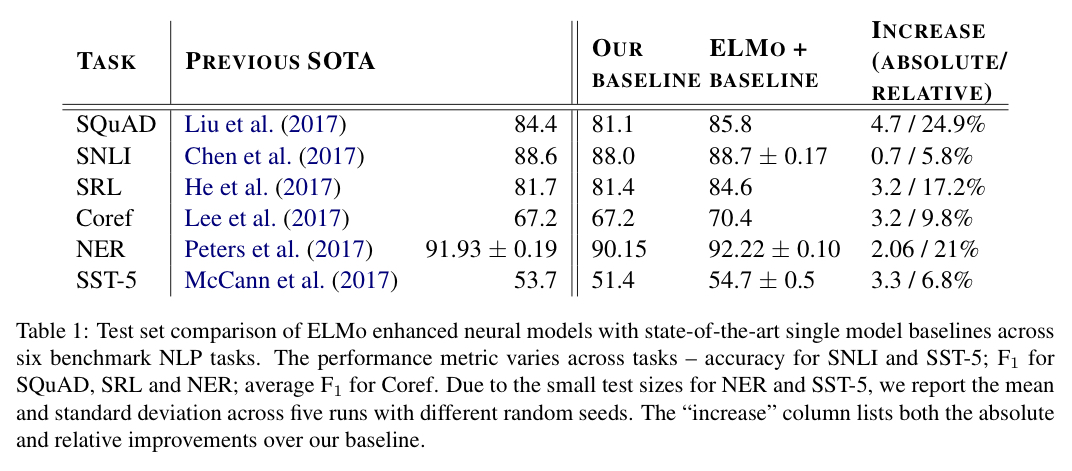
5. Analysis
5.1. Alternate layer weighting schemes
biLM이나 MT 인코더의 마지막 층만 사용하는 방법도 있다.
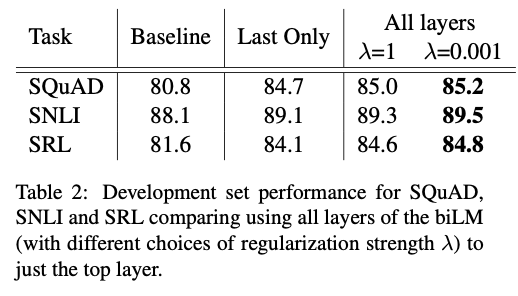
파라미터가 1일 때는 각 레이어의 아웃풋을 평균에 가깝게 내는 반면, 0.001일 때는 층마다의 가중치가 다르다.
5.2. Where to include ELMo?
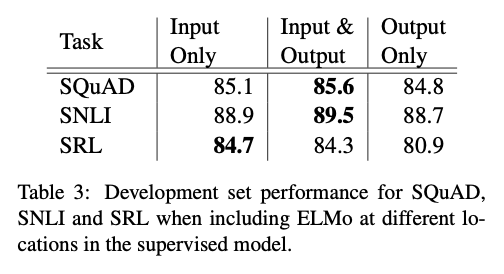
5.3. What information is captured by the biLM’s representations?
5.4. Sample efficiency
5.5. Visualization of learned weights
5.6. Contextual vs. sub-word information
5.7. Are pre-trained vectors necessary with ELMo?
