1. Introduction
DNN은
- 병렬 연산이 가능
- 훈련 데이터셋이 충분하면 backprop으로 훈련 가능
하다는 점에서 강력하다.
하지만 고정된 차원의 벡터로 임베딩해야 하기 때문에 인풋과 아웃풋의 차원 정보가 있어야 한다는 단점이 있다.
LSTM을 사용하면 이 문제를 해결할 수 있다. 인풋 시퀀스를 타임스텝 별로 읽어서 고정된 차원의 벡터 표현을 얻고, 다른 LSTM으로 벡터로부터 아웃풋 시퀀스를 추출한다.
2. Model
RNN은 시퀀스를 시퀀스에 매핑하기 쉬운 모델이지만 인풋과 아웃풋 시퀀스의 길이가 다를 때 RNN을 적용하기 쉽지 않다.
따라서 이 연구에서는 LSTM을 사용한다. 이 경우 RNN의 long term dependency 문제를 해결할 수 있다.
- 두 개의 LSTM 사용
하나는 인풋 시퀀스, 다른 하나는 아웃풋 시퀀스용. 이렇게 하면 모델 파라미터가 늘어나고 LSTM이 동시에 여러 개의 language pair(?)을 학습하기 쉬워진다. - 레이어 4개
깊은 LSTM이 얕은 LSTM을 유의미하게 능가해서, 층이 4개인 LSTM을 사용했다. - 인풋 시퀀스 순서 뒤집기
ㄱ, ㄴ, ㄷ -> a, b, c로 매핑하는게 아니라
ㄷ, ㄴ, ㄱ -> a, b, c로 매핑
이렇게 하면 ㄱ은 a에 가깝고, ㄴ은 b에 가깝게 된다. 또한 SGD가 인풋과 아웃풋 간의 소통을 할 수 있게 한다.
3. Experiments
3.1 Dataset Details
-
WMT'14 English to French 데이터셋
12M개의 문장-348M개의 불어 단어 + 304M의 영어 단어로 이루어져 있음 -
fixed vocabulary
가장 빈도가 높은 160000개의 영어 단어와 80000개의 불어 단어
3.2 Decoding and Rescoring
B개의 부분적인 가설을 만드는 빔 서치 디코더를 사용한다. (빔 서치가 뭐죠)
이 부분 가설은 번역의 머리 부분에 해당한다.
각 타임스텝에서 부분 가설을 모든 가능한 단어를 사용해서 빔 안에 (?) 확장하는데, 이렇게 되면 가설 개수가 너무 많아지니까 로그 확률을 기준으로 B개의 가장 유력한 가설만 남겨둔다.
가설 뒤에 EOS 토큰 붙으면 빔에서 제거하고 완전한 가설 리스트에 추가한다. 빔 사이즈 1에서도 성능이 괜찮았고, 2일 때 빔 서치가 가장 유용했다고 한다.
1000개의 베스트 리스트로 rescore 함.
빔 서치 코테 책에서 본 거 같은데 잘 기억이 안 나서,,,, 추가 공부 해야겟슴
공부해라 서연아
3.3 Reversing the Source Sentences
LSTM이 장기 의존성 문제를 해결할 수 있는 장점이 있지만, 문장을 뒤집었을 때 더 좋은 성능을 내는 것을 발견했다. 복잡도와 BLEU 점수 측면에서 둘 다 나아졌다고 한다.
소스 문장만 뒤집고 타겟 문장은 그대로 둔다
이 현상의 원인으로는 많은 단기 의존성 때문이라고 추측할 수 있다.
소스와 타겟 문장을 그대로 이으면 '최소한의 시간차(minimal time lag)'가 생길 수 밖에 없다. 소스 문장의 각 단어가 타겟 문장내에 해당하는 단어와 멀기 때문이다.
문장을 뒤집는다고 평균 거리가 줄어드는 것은 아니지만 소스 문장의 초반 몇 개 단어가 타겟 문장의 몇 개 단어와 더 가까워져서, 역전파가 소스와 타겟 문장 사이에 소통(?)을 할 수 있도록 한다.
3.4 Training details
디테일-별로 안 중요한 부분
3.5 Parallelization
병렬처리-별로 안 중요한 부분
3.6 Experimental results
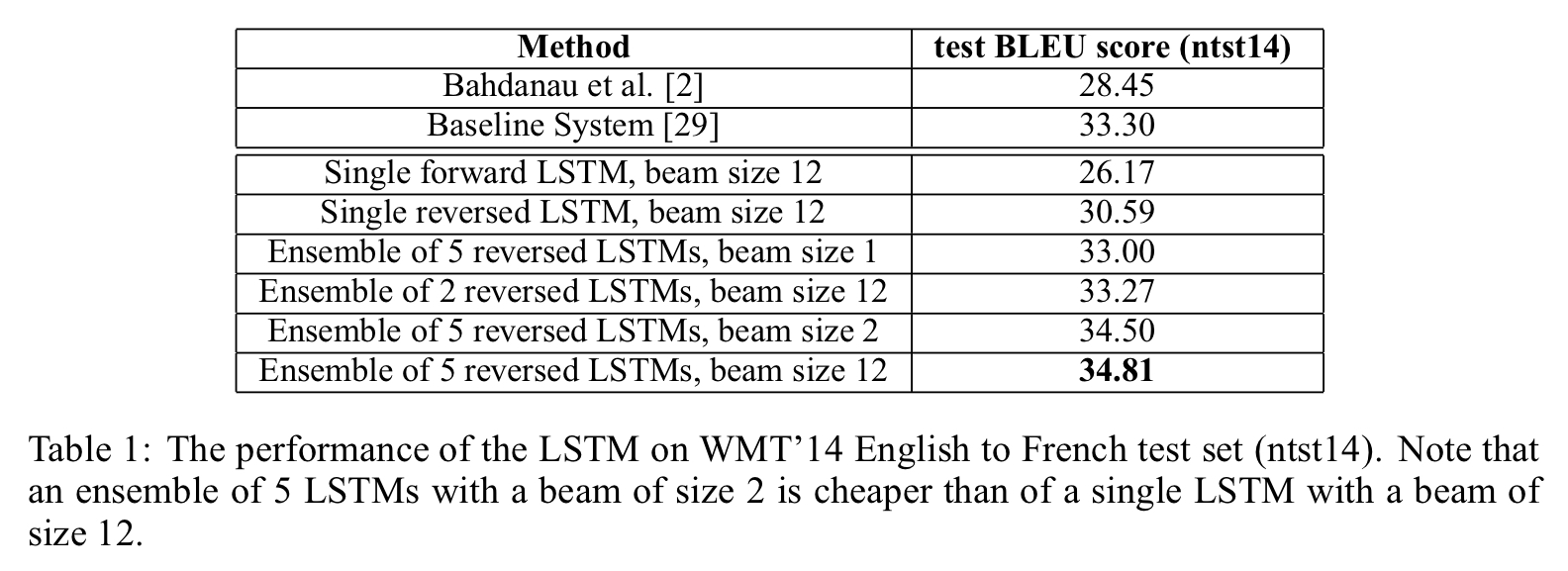

비록 WMT 최고 기록은 못 넘겼지만 순수한 신경망 번역이 SMT(표에서 Baseline System)를 뛰어넘은게 처음이라고 한다.
3.7 Performance on long sentences
긴 문장에도 성능이 좋았다는데 불어를 몰라서 잘 한건진 모르겠고 암튼 결과가 잘 나왔다고 함
3.8 Model Analysis
이 모델의 특징자랑거리 중 하나가 단어의 시퀀스를 벡터로 변환할 수 있는 능력이다. 매핑이 단어의 순서에는 민감하고, 수동/능동태에는 별로 민감하지 않다고 한다.
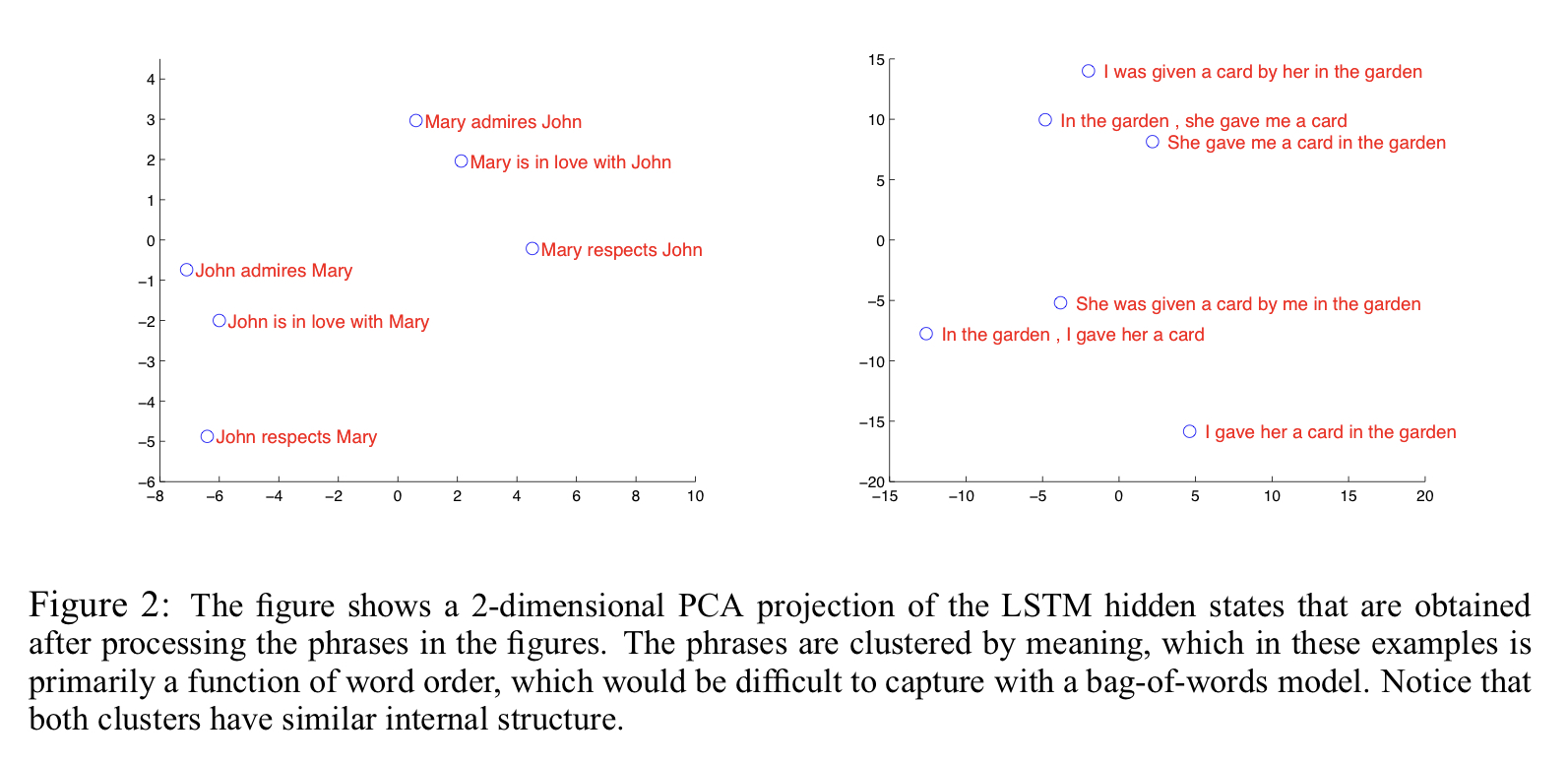
🤔 여기 설명 보면 The phrases are clustered by meaning, which in these examples is primarily a function of word order 이라고 되어 있는데 이게 뭔소린지 모르겠음
4. Related Work
이 연구와 유사한 연구 간략하게 소개
5. Conclusion
제한된 vocabulary와 태스크에 대한 사전지식(맞게 해석한건가..)이 없는 채로 LSTM이 기본적인 SMT를 넘어설 수 있다는 것을 보여주었다. 이를 통해 충분한 데이터셋만 있다면 시퀀셜한 학습 태스크에 적용할 수 있는 가능성을 보여주었다 .
또한 문장을 뒤집음으로써 성능이 좋아질 수 있다는 사실을 발견했다. 단기 의존성을 많이 만들어냄으로써 학습을 더 쉽게 만들었다.
또한, 이 모델은 매우 긴 문장도 제대로 번역할 수 있다. LSTM은 제한된 메모리 때문에 긴 문장을 번역을 잘 못할 것이라는 우려와 달리 뒤집은 문장 데이터셋으로는 긴 문장 번역도 별 어려움 없이 해냈다.
