1. Introduction
NLP 분야에 신경망을 접목시키는 연구는 꽤 많이 진행되어왔고 대표적인 예시로는 Socher e al.의 paraphrase detection, Mikolov et al.의 word embedding extraction논문리뷰 등이 있다. 그 중 이 논문에서는 Statistical Machine Translation (SMT)를 신경망과 접목시키는 새로운 연구를 소개하고 있다.
이 새로운 아키텍쳐는 RNN Encoder-Decoder 으로 명명하였으며, 인코더는 다양한 길이의 시퀀스를 고정된 길이의 벡터로 매핑하고, 디코더는 벡터 표현을 다시 다양한 길이의 시퀀스로 출력하는 역할을 한다. 이 두 네트워크는 같이 학습되어서 소스 시퀀스가 주어졌을 때 타겟 시퀀스의 조건부 확률을 극대화하도록 설계되었다. 또한 메모리 용량을 개선시키기 위해 히든 유닛을 사용한다.
2. RNN Encoder-Decoder
2.1 Preliminary RNN
GRU는 RNN을 기반으로 하기 때문에 이 챕터에서는 RNN에 대해 간략하게 설명하고 있다.
RNN은 hidden state 와 시퀀스 에서 선택적으로 (?) 도출된 아웃풋 로 이루어져 있다.
각 타임스텝(혹은 시퀀스)에서 hidden state는 다음과 같이 업데이트된다:
는 비선형의 활성화 함수로, 단순한 시그모이드 함수일 수도 있고, 복잡한 LSTM일 수도 있다.
RNN으로 각 타임스템 에서의 값을 조건부 분포로 구할 수 있다.
수식 쓰기 귀찮아서 생략
이렇게 학습된 분포로 각 타임스텝에서 심볼을 샘플링해서 새로운 시퀀스를 반복적으로 얻을 수 있다.
2.2 RNN Encoder-Decoder
몇번이고 말하고 있지만 이 논문은 RNN 인코더 + 디코더에 관한 논문이다.
encoder에서는 다양한 길이의 시퀀스를 고정된 길이의 벡터 표현으로 바꾸는 과정이고, decoder에서는 인코더에서 넘겨 받은 고정 길이의 벡터 표현을 다시 시퀀스로 변환한다.
즉 길이를 가지는 시퀀스로 길이의 시퀀스의 조건부 확률을 학습하는 방법이다. 인풋과 아웃풋 길이는 다를 수 있다.
encoder
시퀀스의 각 심볼을 차례대로 읽는대로 hidden state가 바뀌는데, 시퀀스가 end of sequence 심볼로 끝이 나면 총 인풋 시퀀스의 hidden state에 대해 로 정리한다.
decoder
로 다음 심볼 를 에측한다. 하지만 2.1에서 설명한 와는 식이 조금 다른데, encoder 단계에서 모든 인풋 시퀀스에 대해 hidden state가 정리된 역시 조건에 포함된다.hidden state of the decoder at time t
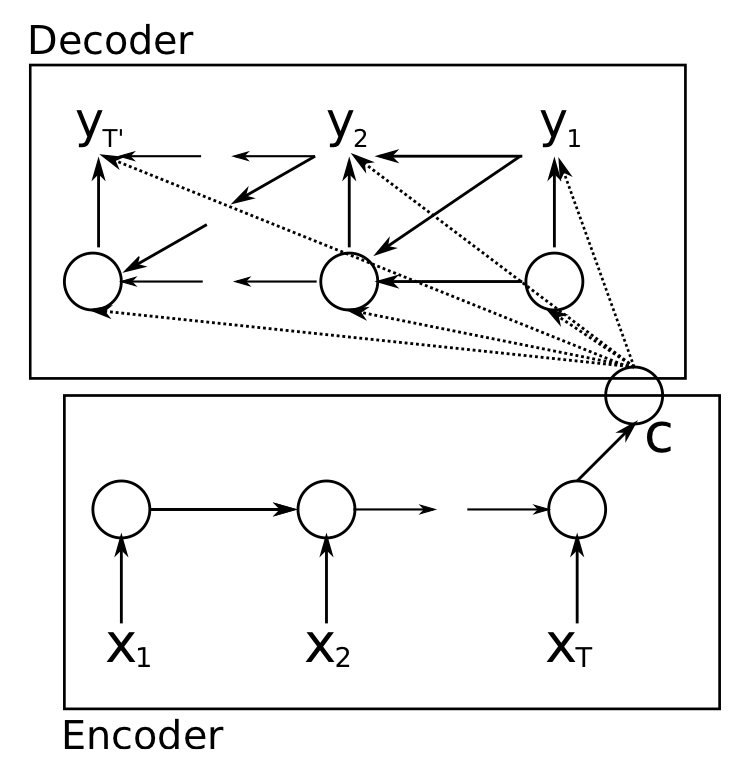
합치면 이렇게 생겼다.
각 타임스텝의 hidden state가 모여 c로 정리되고, 이게 디코더로 흘러가서 T'개의 아웃풋 y 시퀀스를 만들어냄을 알 수 있다.
의 조건부 분포는 다음과 같다:
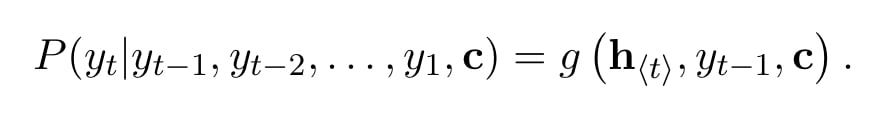
인코더와 디코더는 conditional log-likelihood를 최대화하기 위해 훈련된다.
는 모델 파라미터의 개수이다.
이렇게 훈련된 인코더 디코더 모델은 두 방향으로 사용이 가능하다:
- 인풋 시퀀스에 대해 타겟 시퀀스 생성
- 주어진 인풋-아웃풋 시퀀스 쌍을 평가
2.3 Hidden Unit that Adaptively Remembers and Forgets
이 챕터는 어떻게 보면 GRU라는 이름의 기원이기도 한 reset, update gate를 설명하고 있다.
hidden unit의 개념은 LSTM에서 영감을 받았지만 더 간단하다고 한다.
(참고로 LSTM에서는 메모리 셀과 4개의 게이트 유닛이 있다.)
reset gate
이름에서 알 수 있듯이 reset을 담당한다. 는 로지스틱 시그모이드 함수이고, 는 j번째 벡터, 와 은 이전 단계의 인풋과 hidden state, 그리고 , 은 학습된 가중치 행렬이다.
리셋 게이트 값 가 0에 가까우면, hidden state는 이전 hidden state를 무시하고 현재 인풋만을 가지고 리셋하게 된다.
이 방법은 미래와 관련이 없는 정보는 드랍함으로써 더 컴팩트한 표현을 만들 수 있다.
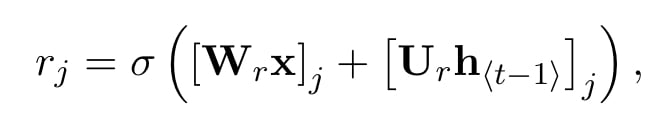
update gate
업데이트 게이트는 이전 hidden state의 정보가 현재 hidden state로 얼마나 흘러들어갈 것인지 조절하는 역할을 한다. LSTM의 메모리 셀과 비슷한 역할을 하며, RNN이 장기 정보를 기억할 수 있도록 한다. 또한 leaky-integration unit의 변형이라고 하는데 이게 뭔지 모르겠음
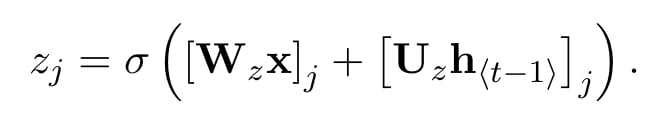
각 hidden unit은 리셋과 업데이트 게이트가 있고, 각 유닛이 시간에 걸쳐 의존성을 포착한다.(?)
단기 의존성을 포착하도록 학습한 유닛은 리셋 게이트가 활발,
장기 의존성을 포착한 유닛은 업데이트 게이트가 활발한 경향이 있다.
이 챕터 제목에 remember과 forget이 들어가는데, remember은 update gate의 역할, forget은 reset gate의 역할이 아닌가 싶다.
3. Statistical Machine Translation
SMT(에셈타운 아님)는 주어진 소스 문장 로 번역 문장 를 찾는다.
즉 최적의 를 찾기 위해 학습하는 모델이다.
우변은 translation model과 language model로, SMT는 translation model과 language model 의 곱에 비례하는 것을 알 수 있다.
주로 의 선형 로그 모델을 더 많이 사용한다고 한다.
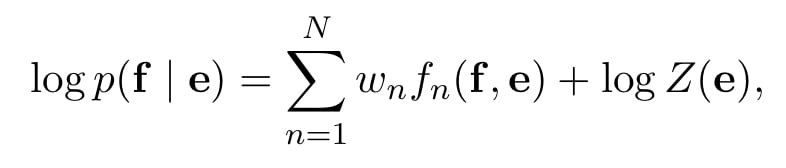
과 은 n번째 피쳐와 가중치이고, 는 정규화 상수이다. 얘네들은 BLEU 스코어를 최대화하기 위해 최적화된다.
Translation model 는 소스와 타겟 문장의 mathcing phrase(구쌍...? 어감 이상하다)의 번역 확률로 인수분해된다.
보통 SMT에서 신경망은 번역 가설을 rescore(??)하기 위해 쓰였으나, 최근에는 번역된 문장이나 구쌍을 소스 문장 표현을 사용해서 신경망을 학습시키는 방법이 연구되고 있다고 한다. (무슨 말인지 약간 배경지식 부족)
3.1 Scoring Phrase Pairs with RNN Encoder-Decoder
RNN Encoder-Decoder을 phrase 쌍 테이블에 학습시키고 선형로그 모델의 피쳐로 점수를 낸다.
각 phrase 쌍의 정규화된 빈도는 무시하는데, 이는 1. 정규화된 빈도로 phrase 쌍을 랜덤으로 고르는 계산 비용을 줄이고, 2. E-D가 등장수에 따라 phrase 쌍을 학습하지 않도록 하기 위해서이다. 이렇게 할 수 있는 이유는 phrase table의 번역 확률이 이미 빈도를 가지고 있기 때문이다. 대신, 이 모델은 언어적 규칙성(가능/불가능한 번역 식별, 여러 방법의 번역 학습)을 학습하는 데에 초점을 둔다.
E-D가 학습되었으면, 테이블에 새로운 점수를 더한다. 이는 새 점수가 비용을 최소화하면서 알고리즘에 포함될 수 있도록 한다.
정리는 했지만 크게 중요한 부분인지는 모르겠음
3.2 Related Approaches: Neural Networks in Machine Translation
이전 연구 설명
4. Experiments
4.1 Data and Baseline System
영-불 번역 태스크
데이터 다 조합한다고 성능이 좋아지는 것은 아니다. 따라서 데이터 중에서 유사한 하위집합만을 추출했다. 이 방법으로 언어 모델링을 위한 418M 단어, E-D 학습을 위한 348M 단어를 선택했다.
또한 E-D 훈련을 위해 소스와 타겟 단어를 15000개의 가장 빈도수가 높은 영어, 불어 단어로 제한했다.
4.1.1 RNN Encoder-Decoder
- 인풋과 hidden unit 사이에 들어가는 행렬을 100차원으로 설정해서 100차원의 임베딩 학습할 수 있도록 했다.
- 활성화 함수는 하이퍼볼릭 탄젠트 함수를 사용
4.1.2 Neural Language Model
RNN E-D 말고 전통적인 language model 학습방법도 시도해보았다.
4.2 Quantitative Analysis
연구에서는 4가지 방법으로 태스크를 진행했다.
1. Baseline
2. RNN
3. CSLM + RNN
4. CSLM + RNN + WP (word penalty)
성능은 4번째가 가장 좋았다. 이를 통해 CSLM과 RNN이 크게 상관관계가 있지는 않으며 독립적으로 개선시키는 것으로도 성능을 높일 수 있음을 확인했다. 또한 모르는 단어 개수, 즉 리스트에 없는 단어들에 페널티를 부여했는데, 선형로그 모델에 모르는 단어 개수만큼 피쳐를 추가하는 방식으로 구현했다.
하지만 development set(훈련셋 말하는 거겠지?)에만 좋은 성능을 보였고, 테스트셋에는 그렇지 못했다.
4.3 Qualitative Analysis
시퀀스가 길고(한 source phrase 당 단어 3개 이상) 빈도수가 높은 phrase와 길고 빈도수가 낮은 phrase를 비교해보았다.
대부분의 경우에서 타게 phrase 는 실제로 또는 단어 그대로 번역인 것들과 가까웠다. RNN E-D는 짧은 phrase를 선호하는 것을 알 수 있었다.
번역 모델과 E-D가 점수 낸 쌍이 다른 것들도 있었는데, 이는 E-D가 유니크한 쌍에 학습되어서 빈도수가 높은 pair만 학습하는 것을 막았기 때문이라고 해석할 수 있다.
E-D는 실제 phrase table을 보지 않고도 타겟을 잘 생성하는 것을 볼 수 있는데, 생성된 phrase가 타겟 phrase 와 완전히 일치하지는 않았다. 이를 통해 추후에는 phrase table을 RNN E-D로 대체하는 방안도 가능성이 있을 것으로 보인다.
4.4 Word and Phrase Representations
E-D도 단어 시퀀스를 연속적인 공간 벡터로 매핑하기 때문에, semantically 의미 있는 임베팅을 잘 할것으로 기대한다.
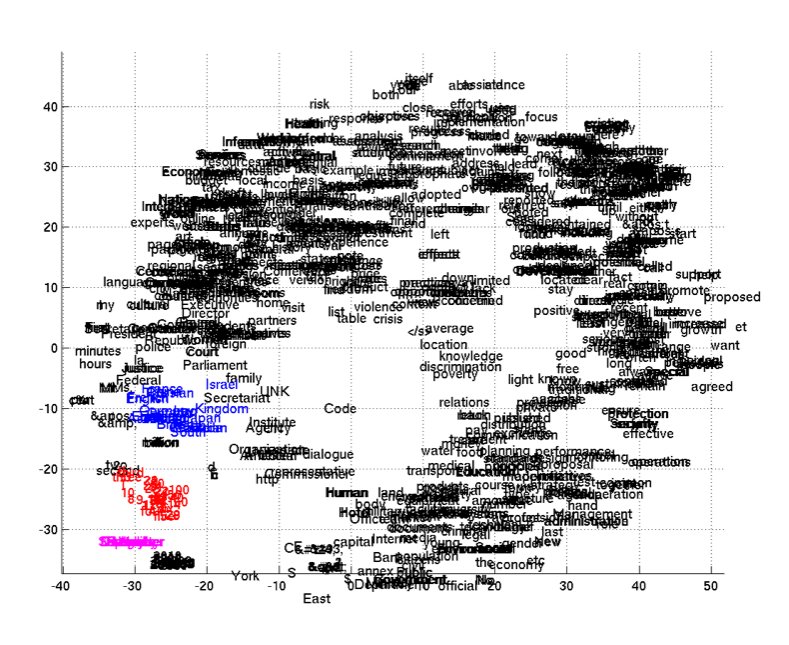
의미적으로 유사한 단어가 같이 클러스터된 것을 볼 수 있다.
또한, 단어 임베딩 말고 phrase 임베딩도 해보았는데, 역시 의미적, 통사적 구조를 고려하여 유사한 phrase들끼리 모여있다.
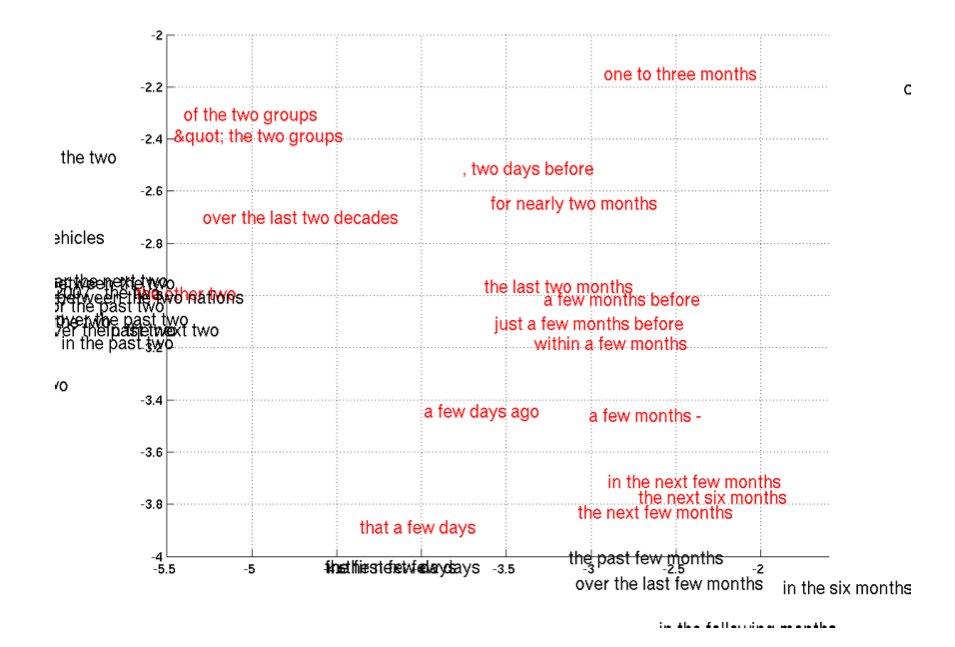
얘는 color-coded 된 특정 지역에 해당하는 phrase cluster이다.
5. Conclusion
그냥 내용 정리 문단임
RNN Encoder-Decoder
- 임의 길이의 시퀀스를 다른 임의 길이의 시퀀스로 매핑
- 시퀀스 쌍의 조건부 확률을 계산하거나
- 소스 시퀀스로부터 타겟 시퀀스를 생성할 수 있음.
- reset gate와 update gate를 포함하는 hidden unit
- 번역 태스크를 통해 이 모델이 phrase pair의 언어적 규칙성을 잘 포착하는 것을 확인 -> 타겟 phrase 잘 생성할 것으로 기대
- orthogonal to the existing approach of using neural networks in the SMT -> RNN E-D와 신경망 언어 모델 같이 쓸 수 있음 (???)
- 다양한 레벨 (syntactic, semantic 등) 에서 언어적 규칙성 포착
- written language 말고 다른 분야, 이를테면 speech trascription 등에 사용이 가능할 것으로 기대
아아악 수학 잘 하고 싶다 수식 다 이해하고 싶다 공부 더 하게 시간 많았으면 좋겠다 개똑똑하고 싶다.........

밥오가튼 내 자신이 실허....
