32. IOCP란?
Reference : https://its-fusion-blog.tistory.com/18
Reference : https://sanghun219.tistory.com/104
IOCP란 무엇인가?
-
IOCP란 Input Output Completion Port의 약자로써 입출력 완료 포트라는 것이다.
IOCP는 window 환경에서 작동하는 논블로킹 프로세스로서 최소한의 스레드를 사용해서 Port와 관련된 입출력을 처리하는 기법이다. (여기서 Port는 기존 소켓에서 사용하던 Port번호가 아닌 목적지 느낌)
IOCP의 장점
-
위에서 서술한 것처럼 적은 수의 스레드만을 사용하여 구현할 수 있다.
-
적은 수의 스레드 사용으로 CPU점유율도 낮으며, Context switching 비용도 적다.
-> 윈도우 OS가 직접 스레드 풀링을 관리하기 때문에
-
winsock2 API중 가장 확장성과 성능이 뛰어나다.
-
Overrapped I/O를 확장 시킨 개념이기때문에 커널영역과 유저영역의 버퍼를 공유한다.
IOCP의 단점
-
프로그램 구현이 복잡해진다.
-
window 기반 플랫폼에서만 사용이 가능하다.
-
하나의 I/O operation 마다 버퍼영역에 대한 page-lock/unlock이 필요하다.
-> 특정 메모리에 대한 pin/unpin은 많은 CPU cycle을 요구한다.
-> recv 를 posting 할 때, page-locking을 피해서 zero-byte recv를 사용한다.
-> page-locking 찾아볼 것.
-
하나의 I/O operation 마다 시스템 콜을 호출한다.
-> 이로 인해 유저모드-커널모드 전환이 발생한다.
- zero-byte , zero-byte recv 찾아볼것
IOCP의 목적
-
IOCP의 목적은 동시에 수행되는 스레드의 상한을 설정해서 CPU의 자원을 최대한 효율적으로 사용하게 하는 것입니다.
IOCP는 Overlapped I/O가 완료되면 이를 감지해서 사용자에게 알려주는 역할을 합니다.
Overlapped I/O란?
- Overlapped I/O는 I/O에 대한 처리를 Device Driver에 권한을 넘김으로서 별도의 스레드 없이 비동기로 둘 이상의 데이터 전송을 중첩시키는 것을 의미합니다. Device Driver는 작업을 끝내면 유저 버퍼에 데이터를 채워넣기에 I/O에 대한 처리를 중첩해서 처리할 수 있습니다.
Overlapped I/O와 Nonblock Socket의 차이점
- Overlapped I/O는 I/O 처리를 비동기로 처리하기 때문에 데이터 복사과정에서 Block되지 않습니다. 그리고 I/O 처리를 순서대로 하지 않고 디스크에 가까운 순서대로 처리를 하며 Zero-Copy를 통해서 소켓 버퍼로의 복사를 건너뛰고 유저 버퍼에 바로 데이터를 복사할 수 있습니다.
Zero-Copy란?
- Zero-Copy의 목적은 디스크에 있는 데이터를 네트워크로 전송할 때 일어나는 바이트 카피를 최소화 하기위한 것입니다. 일반적으로 네트워크를 이용해서 데이터를 전송하려면 커널영역에서 사용자영역으로 데이터를 읽어들인 후 다시 사용자영역에서 커널영역으로 데이터를 복사해야합니다. 이러한 과정은 사용자영역에서 데이터를 조작하지 않고 바로 보내도 될시에 불필요한 과정이 됩니다. 그렇기 때문에 커널과 사용자 영역을 넘나드는 과정을 거치지 않고 커널의 Read Buffer에서 Socket Buffer로의 복사만을 거쳐서 커널과 사용자 영역간의 2번의 복사 과정을 생략할 수 있습니다.
Overlapped의 입출력이 완료되면 Completion port라고하는 queue에 Completion Packet을 기록되고 스레드가 queue를 확인하여 Completion Packet이 있으면 완료된 내용을 받아갈 수 있습니다.
Select 방식과 비교해 봤을 때 소켓 하나에 스레드 하나를 할당해주는 것과 비교하여 소수의 스레드로 I/O처리를 할 수 있다는 점에서 CPU자원을 효율적으로 사용한다고 할 수 있습니다.
33.애자일이란?
Reference : https://pmnagile.tistory.com/27
애자일 소프트웨어 개발 선언 4대 가치
- 공정과 도구보다 개인과 상호작용을
- 포괄적인 문서보다 작동하는 소프트웨어를
- 계약 협상보다 고객과 협력을
- 계획을 따르기보다 변화에 대응하기를 가치있게 여긴다
Agile Software Development
소프트웨어 개발 방법론의 하나로, 처음부터 끝까지 계획을 수립하고 개발하는 폭포수(Waterfall) 방법론과는 달리 개발과 함께 즉시 피드백을 받아서 유동적으로 개발하는 방법이다.
정식 명칭은 애자일 소프트웨어 개발(Agile Software Development). 한국에서는 주로 애자일 방법론 이라고 부른다. 켄트 벡이 주창한 익스트림 프로그래밍(XP, Extreme Programming)과 테스트 주도 개발이 대표적이다.
애자일 방법론의 진행 과정
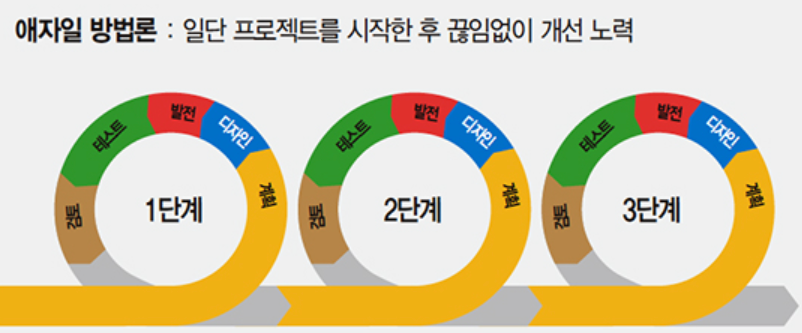
애자일 방법론은 계획 → 설계(디자인) → 개발(발전) → 테스트 → 검토(피드백) 순으로 반복적으로 진행된다. 계획을 세운 후 다음 단계까지 기다려서 절차대로 진행하는 폭포수 모델과 달리 먼저 진행 후 분석, 시험, 피드백을 통하여 개선하여 나가는 진행 모델이다.
 출처 : https://kkhipp.tistory.com/145
출처 : https://kkhipp.tistory.com/145
계획 및 분석 : 고객과 사용자가 원하는 바를 파악하여 타당성을 조사하고 SW 기능과 제약조건을 정의하는 명세서 작성, 대상이 되는 문제 영역과 사용자가 원하는 task를 이해하는 단계
설계(디자인) : 기획 의도에 맞는 설계 및 디자인 추가 및 수정하는 단계
개발(발전) : 설계단계에서 만들어진 설계서를 바탕으로 프로그램을 작성, 코딩, 디버깅, 단위/통합테스트 수행
테스트 : 발생할 수 있는 실행 프로그램 오류를 발견, 수정하는 단계
검토(피드백) : 기획 의도를 파악하고 시험 결과와 기획에 따라 수정할 부분을 제시하는 단계
34. 트랜잭션
Reference : https://siloam72761.tistory.com/30
트랜잭션의 개념
- 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 말한다.
- 하나의 트랜잭션에는 하나 이상의 SQL 문장이 포함된다.
- 트랜잭션은 분할할 수 없는 최소의 단위이다.
- 데이터베이스의 논리적 연산 단위다.
트랜잭션의 4가지 특성
원자성(automicity) - 트랜잭션에 정의된 연산들은 모두 성공적으로 실행되던지, 아니면 전혀 실행되지 않은 상태로 남아야 한다. (All or Nothing)
일관성(consistency) - 트랜잭션이 실행되기 전에 데이터베이스 내용이 잘못되어 있지 않다면, 트랜잭션이 실행된 이후에도 데이터베이스의 내용이 잘못되어선 안된다.
고립성(isolation) - 트랜잭션이 실행되는 중에 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들어서는 안된다.
지속성(durability) - 트랜잭션이 성공적으로 수행되면, 갱신된 데이터베이스의 내용은 영구적으로 저장된다.
트랜잭션 조작어 TCL(Transaction Control Language)
- COMMIT : 올바르게 적용된 데이터를 데이터베이스에 반영시키는 것
- ROLLBACK : 트랜잭션 시작 이전의 상태로 되돌리는 것
- SAVEPOINT : ROLLBACK할 때 현시점에서 SAVEPOINT까지 트랜잭션의 일부를 롤백할 수 있다.
- 트랜잭션의 대상이 되는 SQL문은 UPDATE, INSERT, DELETE 등 데이터를 수정하는 DML 문이다.
COMMIT, ROLLBACK 이전의 데이터 상태
단지 메모리 BUFFER에만 영향을 받았기 때문에 데이터의 변경 이전 상태로 복구 가능하다.
현재 사용자는 SELECT 문장으로 결과를 확인 가능하다.
다른 사용자는 현재 사용자가 수행한 명령의 결과를 볼 수 없다.
변경된 행은 잠금이 설정되어서 다른 사용자가 변경할 수 없다.
COMMIT 이후의 데이터 상태
데이터에 대한 변경 사항이 데이터베이스에 영구히 반영된다.
이전 데이터는 영원히 잃어버린다.
모든 사용자는 결과를 볼 수 있다.
관련된 행에 대한 잠금이 풀리고, 다른 사용자들이 행을 조작할 수 있게 된다.
ROLLBACK 이후의 데이터 상태
데이터에 대한 변경 사항은 취소된다.
이전 데이터는 다시 재저장된다.
관련된 행에 대한 잠금이 풀리고, 다른 사용자들은 행을 조작할 수 있게 된다.
COMMIT과 ROLLBACK로 얻는 효과
데이터 무결성 보장
영구적인 변경을 하기 전에 데이터의 변경 사항 확인 가능
논리적인 연관된 작업을 그룹핑하여 처리 가능
35. 멀티스레드
쓰레드(Thread)의 개념
쓰레드는 프로세스를 여러 개로 나눈 조각과 같다고 설명할 수 있다. 워드를 사용하는 경우를 예로 들자. 워드에서 글자를 입력하는 동안 파일을 주기적으로 자동저장하고, 내용을 프린터에 출력하고 있고, 입력하는 동안 자동으로 맞춤법 검사를 수행한다. 사용자의 입력을 받는 동안 행하는 이 모든 작업들은 각각의 쓰레드에 의해서 이루어진다. 글자를 입력 받는 쓰레드, 파일을 디스크에 저장하는 쓰레드, 출력할 내용을 프린터에 보내는 쓰레드, 입력하는 동안 맞춤법 검사를 수행하는 쓰레드 등이 있다. 즉, 워드라는 큰 프로세스 하나에 여러 개의 쓰레드가 모여있는 것이다.
실제로 프로세스는 하나의 어드레스 공간을 갖고 있고, 모든 응용 프로그램은 메인 응응 프로그램을 위한 하나의 쓰레드를 갖는다. 물론 여기에 다른 쓰레드들이 함께 수행될 수 있고, 각각의 쓰레드들은 자신을 관리하는 프로세스의 어드레스를 갖고 있다. 즉, 프로세스는 쓰레드에 대한 일종의 컨테이너역할을 한다.
멀티 쓰레드(Thread)란
하나의 프로세스를 다수의 실행 단위로 구분하여 자원을 공유하고 자원의 생성과 관리의 중복성을 최소화하여
수행 능력을 향상시키는 것을 멀티쓰레딩이라고 한다. 하나의 프로그램에 동시에 여러개의 일을 수행할수 있도록 해주는 것이다.
멀티 쓰레드를 사용하는 이유
프로세스를 이용하여 동시에 처리하던 일을 쓰레드로 구현할 경우 메모리 공간과 시스템 자원 소모가 줄어들게 된다.쓰레드 간의 통신이 필요한 경우에도 별도의 자원을 이용하는 것이 아니라 전역 변수의 공간 또는 동적으로 할당된 공간인 힙(Heap) 영역을 이용하여 데이터를 주고받을 수 있다.
그렇기 때문에 프로세스 간 통신 방법에 비해 쓰레드 간의 통신 방법이 훨씬 간단하다.심지어 쓰레드의 문맥 교환은 프로세스 문맥 교환과는 달리 캐시 메모리를 비울 필요가 없기 때문에 더 빠르다.따라서 시스템의 처리량이 향상되고 자원 소모가 줄어들어 자연스럽게 프로그램의 응답 시간이 단축된다.
이러한 장점 때문에 여러 프로세스로 할 수 있는 작업들을 하나의 프로세스에서 여러 쓰레드로 나눠 수행하는 것이다.
멀티 쓰레딩의 장점
프로세스 생성은 많은 시간과 자원을 소비한다. 이러한 단점을 최소화 시킨 일종의 경량화된 프로세스 = 쓰레드를 만들게 된 것이다.멀티 쓰레드에서 쓰레드간 스택 영역만 비공유하고 데이터 영역과 힙 영역을 공유한다.
쓰레드의 생성 및 컨텍스트 스위칭은 프로세스의 생성 및 컨텍스트 스위칭보다 빠르다.멀티 쓰레드 컨텍스트 스위칭 시 데이터 영역과 힙을 뮤올리고 내릴 필요가 없다. 데이터 영역과 힙 영역을 통해 데이터 교환이 가능하다. 쓰레드 사이에서의 데이터 교환에서는 특별한 기법이 필요없다.
멀티 쓰레딩의 문제점
멀티 프로세스 기반으로 프로그래밍할 때는 프로세스 간 공유하는 자원이 없기 때문에 동일한 자원에 동시에 접근하는 일이 없었지만 멀티 쓰레딩을 기반으로 프로그래밍할 때는 이 부분을 신경써줘야 한다. 서로 다른 쓰레드가 데이터와 힙 영역을 공유하기 때문에 어떤 쓰레드가 다른 쓰레드에서 사용중인 변수나 자료 구조에 접근하여 엉뚱한 값을 읽어오거나 수정할 수 있다.
그렇기 때문에 멀티쓰레딩 환경에서는 동기화 작업이 필요하다. 동기화를 통해 작업 처리 순서를 컨트롤 하고 공유 자원에 대한 접근을 컨트롤 하는 것이다.하지만 이로 인해 병목 현상이 발생하여 성능이 저하될 가능성이 높다. 그러므로 과도한 락(lock)으로 인한 병목 현상을 줄여야 한다.공유 자원이 아닌 부분은 동기화 처리를 할 필요가 없다.
즉, 동기화 처리가 필요한 부분에만 synchronized 키워드를 통해 동기화하는 것이다.불필요한 부분까지 동기화를 할 경우 현재 쓰레드는 락(lock)을 획득한 쓰레드가 종료하기 전까지 대기해야한다. 그렇게 되면 전체 성능에 영향을 미치게 된다.즉 동기화를 하고자 할 때는 메소드 전체를 동기화 할 것인가 아니면 특정 부분만 동기화할 것인지 고민해야 한다.
36. 동시성 vs 병렬성
Reference : https://yeonyeon.tistory.com/270
- 동시성: 하나의 코어에서 여러 스레드가 번갈아가며 실행
- 병렬성: 멀티 코어에서 여러 스레드를 동시에 실행
동시성(Concurrency)
-
동시성은 여러 작업이 겹치는 기간에 실행될 수 있음을 의미한다. 동시에 실행하는 것이 아니라 CPU가 작업마다 시간을 분할해 적절하게 context switching을 해서 동시에 실행되는 것처럼 보이게 한다. 이렇기 때문에 동시성은 구현하는 것도 디버그하는 것도 어렵다.
-
동시성의 핵심 목표는 유휴 시간을 최소화하는 것이다. 유휴 시간은 컴퓨터가 작동 가능한데도 작업을 하지 않는 시간으로 아무것도 안하고 놀고 있는 시간이라고 생각하면 된다. 현재 프로세스 또는 스레드가 I/O 작업, DB 트랜잭션 등등 외부 프로그램 실행을 기다리는 동안에 다른 프로세스 또는 스레드가 CPU 할당을 받는다. 그림으로 표현하면 아래와 같다.
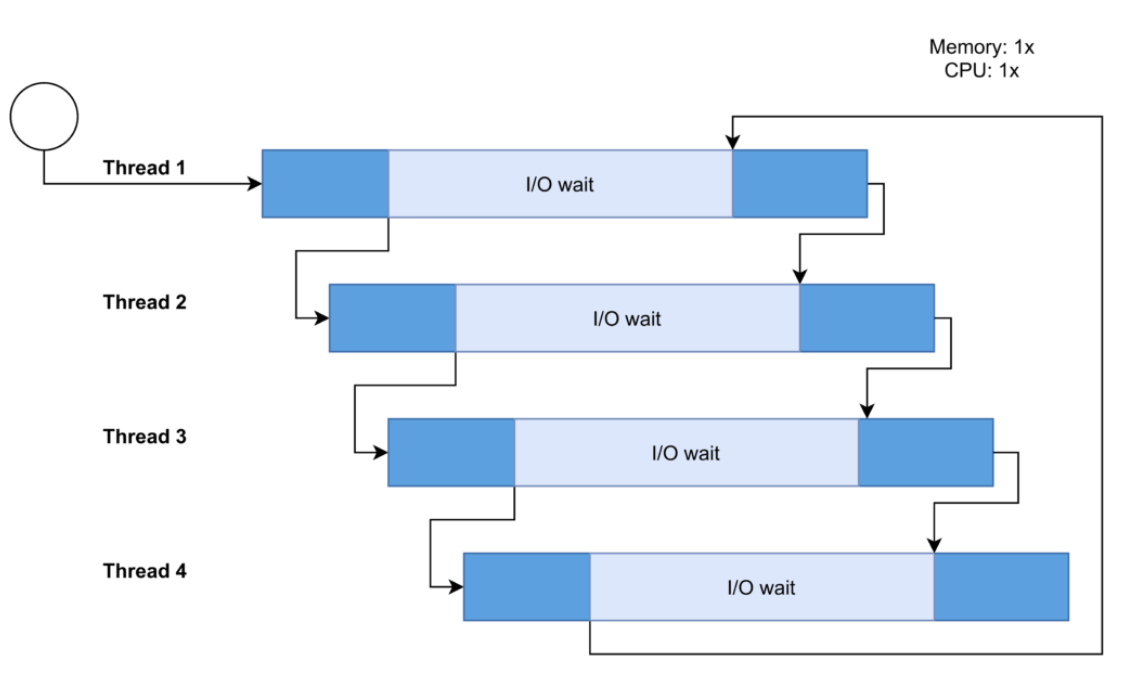
이 여러개의 task들은 하나 이상의 코어에서 실행된다. 같은 시간에 같은 자원에 접근하는 상황이 생길 수 있는데 해당 자원에 write 권한으로 접근하는 경우 '데이터의 무결성 유지' 를 꼭 염두해둬야 한다.
병렬성(Parallelism)
- 병렬성은 동일한 시간에 독립적인 작업을 실행할 수 있음을 의미한다. 동시성과는 달리 여러 작업을 다른 코어, 다른 프로세스, 별도의 컴퓨터 등에서 동시에 실행할 수 있다. 그래서 병렬 처리가 성능 향상에 필수적이라고도 한다.
-
한가지 예로 분산 컴퓨팅 시스템이 있다. 분산 컴퓨팅 시스템은 단일 시스템으로 실행하는 여러 컴퓨터 시스템들로 구성되어 있다. 각 컴퓨터에 존재하는 시스템들은 네트워크로 연결될 수 있다. (그림 참고) 해당 예제 외로도 하나의 컴퓨터에서 여러 코어를 사용하여 병렬 처리를 활용할 수도 있다.
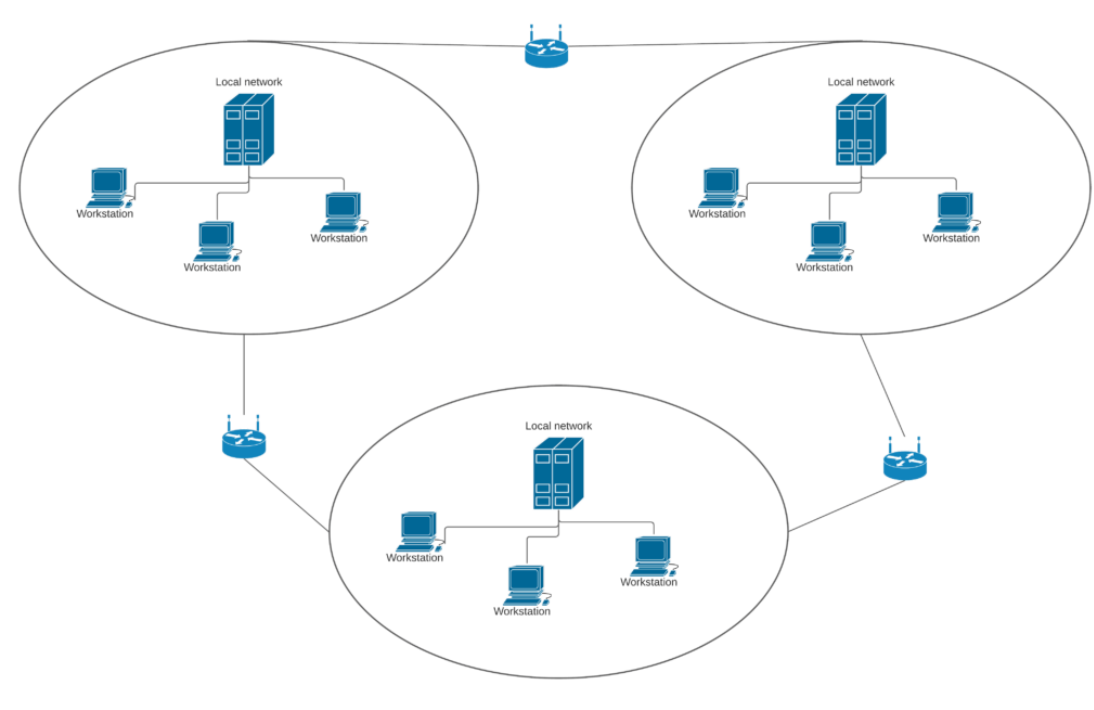
Concurrency vs Parallelism
나는 새로운 프로그래밍 강의를 들으려고 한다. 실습을 따라하며 진행해야 하는데 인강 속도를 따라잡을 수 없었다. 어쩔 수 없이 영상을 멈추고 코딩하고 다시 영상을 실행하는 행위를 반복했다. 이건 동시성이라고 부른다. 연로그는 여유롭게 음악을 들으면서 코딩을 한다. 이런 경우에는 병행성이라고 한다.
본격적으로 동시성과 병행성을 비교해보겠다. 아래 그림을 보자. 2개의 코어가 있다고 가정해보았다. 동시성의 경우에는 Core1에서만 Task를 실행하고 있다. 시간의 흐름에 따라 Task 1과 2를 번갈아가면서 실행한다. 병렬성의 경우에는 Task 1과 2를 번갈아가며 실행할 필요 없이 각 코어에서 Task를 독립적으로 실행한다.
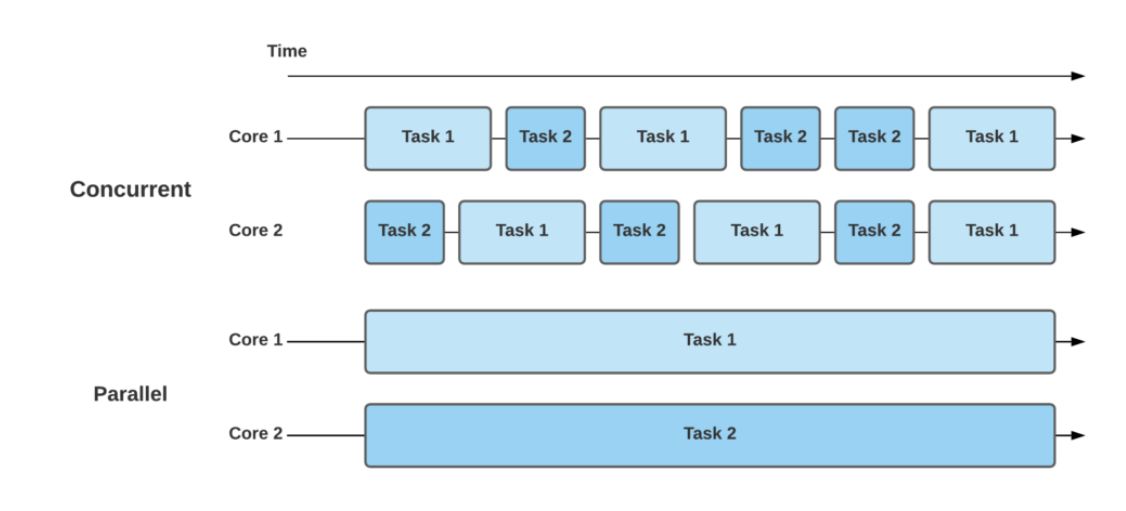
동시성은 여러 task를 계속 번갈아가면서 실행한다. task 1이 사용하던 자원이 있다고 가정해보자. task1이 미처 끝나기 전에 task 2가 같은 자원을 접근한다면? 자원의 값이 변경되며 서로의 실행 결과에 미칠 수 있다. 또 task를 어떤 기준으로 선택하고 교환할 것인지도 고려해야 한다. 따라서 Race Condition, Deadlock, Starvation 등의 문제가 생길 수 있다.
Race Condition, Deadlock, Starvation
- Race Condition: 여러 프로세스가 하나의 자원에 접근해 서로의 실행 결과에 영향을 주는 현상
- Deadlock: 여러 프로세스가 서로 상대방의 작업이 끝나기를 무한히 기다리는 현상
- Starvation: 특정 프로세스가 우선순위가 낮아 원하는 자원을 계속 할당 받지 못하는 현상
병렬성은 여러 task가 어떤 자원을 공유하고 있는지 고려해야 하기 때문에 메모리 손상, 누수 등의 문제가 발생할 수 있다.
37. 멀티스레드 동기화
Reference : https://velog.io/@octo__/%EC%8A%A4%EB%A0%88%EB%93%9C-%EB%8F%99%EA%B8%B0%ED%99%94
스레드 동기화 필요성
-
멀티스레드를 이용하는 프로그램에서 스레드 2개 이상이 공유 데이터에 접근하면 다양한 문제가 발생할 수 있다.
이러한 멀티스레드 환경에서 발생하는 문제를 해결하기 위해 일련의 작업을 스레드 동기화(thread synchronization)라 한다. 윈도우 운영체제는 프로그래머가 상황에 따라 적절한 동기화 기법을 선택할 수 있도록 다양한 API 함수를 제공한다. -
윈도우 운영체제에서 사용할 수 있는 대표적인 스레드 동기화 기법

스레드 동기화 기본 개념
스레드 동기화가 필요한 상황은 크게 다음 2가지 경우이다.
둘 이상의 스레드가 공유 자원에 접근한다.
한 스레드가 작업을 완료한 후, 기다리고 있는 다른 스레드에 알려준다.
두 경우 모두 각 스레드가 독립적으로 실행하지 않고 다른 스레드와의 상호 작용을 토대로 자신의 작업을 진행한다는 특징이 있다. 스레드 동기화를 하려면 스레드가 상호작용해야 하므로 중간 매개체가 필요하다. 두 스레드가 동시에 진행하면 안되는 상황이 있을 때, 두 스레드는 매개체를 통해 진행 가능 여부를 판단하고 이에 근거해 자신의 실행을 계속할지를 결정한다.
윈도우 운영체제에서 이러한 매개체 역할을 할 수 있는 것을 통틀어 동기화 객체(synchronization object)라고 한다. 동기화 객체의 특징은 아래와 같다.
Create()함수를 호출하면 커널(kernel: 운영체제의 핵심 부분을 뜻함) 메모리 영역에 동기화 객체가 생성되고, 이에 접근할 수 있는 핸들(HANDLE 타입)이 리턴된다.
평소에는 비신호 상태(non-signaled state)로 있다가 특정 조건이 만족되면 신호 상태(signaled state)가 된다. 비신호 상태에서 신호 상태로 변화 여부는 Wait()함수를 사용해 감지할 수 있다.
사용이 끝나면 CloseHandle() 함수를 호출한다.
Wait()함수는 스레드 동기화를 위한 필수 함수로, 동기화를 진행할때 비신호 -> 신호, 신호 -> 비신호 상태 변화 조건을 잘 이해해야 하며, 상황에 맞게 Wait() 함수를 사용할 수 있어야 한다.
임계 영역(critical section)
임계 영역(critical section)은 둘 이상의 스레드가 공유 자원에 접근할 때, 오직 한 스레드만 접근을 허용해야 하는 경우에 사용한다. 임계 영역은 대표적인 스레드 동기화 기법이지만, 생성과 사용법이 달라서 앞에서 소개한 동기화 객체로 분류하지는 않는다.
임계 영역은 일반 동기화 객체와 달리 개별 프로세스의 유저(user) 메모리 영역에 존재하는 단순한 구조체다. 따라서 다른 프로세스가 접근할 수 없으므로 한 프로세스에 속한 스레드 간 동기화에만 사용한다.
일반 동기화 객체보다 빠르고 효율적이다.
#include <windows.h>
CRIRICAL_SECTION cs; // 1
DWORD WINAPI MyThread1(LPVOID arg)
{
...
EnterCriticalSection(&cs); // 3
// 공유 자원 접근
LeaveCriticalSection(&cs); // 4
...
}
DWORD WINAPI MyThread2(LPVOID arg)
{
...
EnterCriticalSection(&cs); // 3
// 공유 자원 접근
LeaveCriticalSection(&cs); // 4
...
}
int main(int argc, char **argv)
{
...
InitializeCriticalSection(&cs); // 2
// 스레드를 두개 이상 생성해 작업을 진행
// 생성한 모든 스레드가 종료할 때까지 기다린다.
DeleteCriticalSection(&cs); // 5
...
}임계 영역 사용 시 주의점
임계 영역을 이용할 때 임계 영역을 이용해 공유 자원 접근을 제한하는 것으로 스레드 동기화 문제를 해결했다고 생각하는 것을 주의해야 한다. 반드시 기억해야 하는 것은 임계 영역만으로는 어느 스레드가 먼저 리소스를 사용할지 결정할 수 없다는 것이다. 즉, 어떤 스레드가 먼저 접근할 지 알 수 없다.
이벤트(event)
이벤트(event)는 사건 발생을 다른 스레드에 알리는 동기화 기법이다.
이벤트를 사용하는 전형적인 절차는 다음과 같다.
이벤트를 비신호 상태로 생성
한 스레드가 작업을 진행하고 나머지 스레드는 이벤트에 대해 Wait() 함수를 호출해 이벤트가 신호 상태가 될 때가지 대기한다.(sleep)
스레드가 작업을 완료하면 이벤트를 신호 상태로 바꾼다.
기다리고 있던 스레드 중 하나 혹은 전부가 깨어난다.(wakeup)
이벤트는 대표적인 동기화 객체로, 신호와 비신호 2가지 상태를 가진다. 또한 상태를 변경할 수 있도록 다음과 같은 함수가 제공된다.
BOOL SetEvent(HANDLE hEvent); // 비신호 -> 신호
BOOL ResetEvent(HANDLE hEvent); // 신호 -> 비신호이벤트는 특성에 따라 2종류가 있으며, 용도에 맞게 선택할 수 있어야 한다.
자동 리셋(auto-reset) 이벤트: 이벤트를 신호상태로 바꾸면, 기다리고 있는 스레드 중 하나만 깨운 후 자동으로 비신호 상태가 된다. 즉, 자동 리셋 이벤트에 대해서는 ResetEvent() 함수를 사용할 필요가 없다.
수동 리셋(manual-reset) 이벤트: 이벤트를 신호 상태로 바꾸면, 기다리고 있는 스레드를 모두 깨운 후 계속 신호 상태를 유지한다. 자동 리셋 이벤트와 달리 비신호 상태로 바꾸려면 명시적으로 ResetEvent() 함수를 호출해야 한다.
이벤트는 아래 이벤트 생성 함수 CreateEvent()를 사용해 생성한다.
// 성공: 이벤트 핸들, 실패: NULL
HANDLE CreateEvent(
LPSECURITY_ATTRIBUTES lpEventAttributes,
BOOL bManualReset,
BOOL bInitialState,
LPCTSTR lpName
);lpEventAttributes: 핸들 상속(handle inheritance)과 보안 디스크립터(security descriptor) 관련 구조체로, 대부분은 기본값인 NULL을 사용하면 된다.
bManualReset: TRUE면 수동 리셋, FALSE면 자동 리셋 이벤트가 된다.
bInitialState: TRUE면 신호, FALSE면 비신호 상태로 시작한다.
lpName: 이벤트에 부여할 이름이다. NULL을 사용하면 이름 없는(anonymous) 이벤트가 생성되므로 같은 프로세스에 속한 스레드 간 동기화에만 사용할 수 있다. 서로 다른 프로세스에 속한 스레드 간 동기화를 하려면 같은 이름으로 생성해야 한다.
이벤트 연습 예제
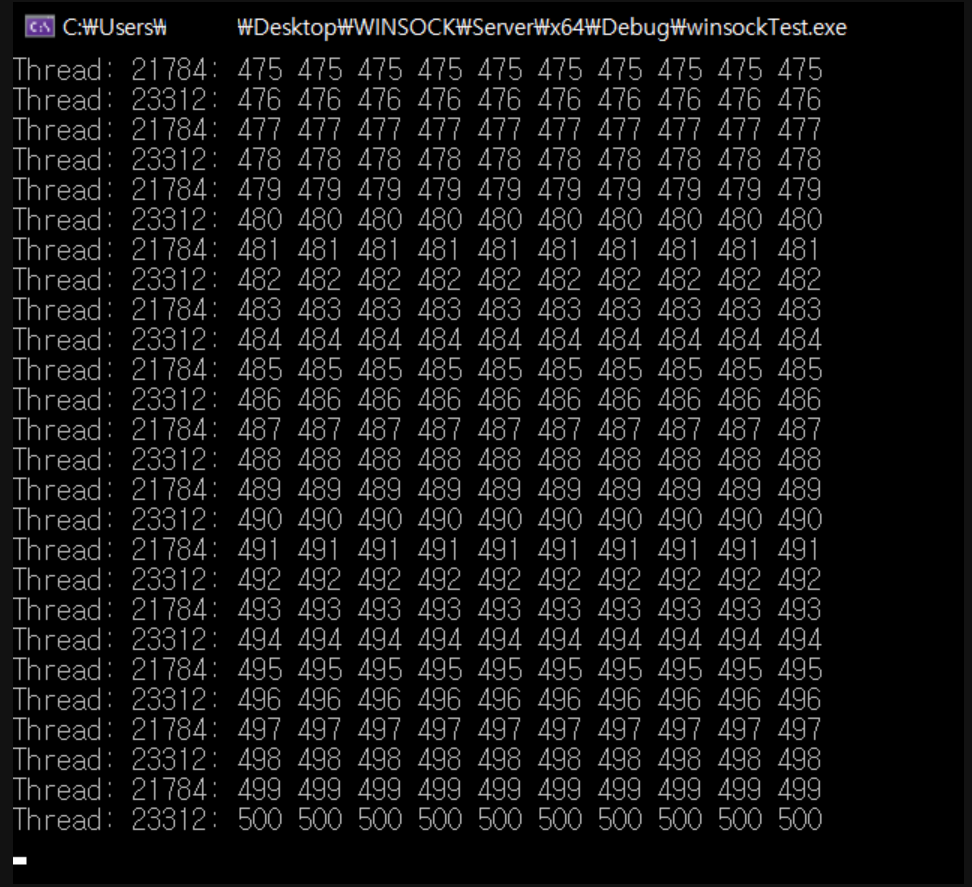
데이터를 생성해 공유 버퍼에 저장하는 스레드 1개와 공유 버퍼에서 데이터를 읽어서 처리하는 스레드 2개를 생성할 것이다. 이 경우 한 스레드만 버퍼에 접근할 수 있게 해야하고, 접근 순서도 정해야한다. 스레드 실행 순서에 대한 제약 사항은 다음과 같다.
스레드 1이 쓰기를 완료 후 스레드 2나 스레드 3이 읽을 수 있다. 이때 스레드 2와 스레드 3 중 1개만 버퍼 데이터를 읽을 수 있으며, 일단 한 스레드가 읽기 시작하면 다른 스레드는 읽을 수 없다.
스레드 2나 스레드 3이 읽기를 완료하면 스레드 1이 다시 쓰기를 할 수 있다.
#include <windows.h>
#include <stdio.h>
#define BUFSIZE 10
HANDLE hReadEvent;
HANDLE hWriteEvent;
int buf[BUFSIZE];
DWORD WINAPI WriteThread(LPVOID arg)
{
DWORD retval;
for (int i = 0; i <= 500; i++)
{
// 읽기 완료 대기
// 읽기 이벤트가 신호 상태가 되기를 기다린다. 최초에는 읽기 이벤트가 신호 상태로 시작하기 때문에 곧바로 리턴해 다음 코드로 진행할 수 있다.
retval = WaitForSingleObject(hReadEvent, INFINITE);
if (retval != WAIT_OBJECT_0)
break;
// 공유 버퍼에 데이터 저장
for (int j = 0; i j < BUFSIZE; j++)
buf[j] = i;
// 쓰기 완료 알림
// 쓰기 이벤트를 신호 상태로 만들어 두 읽기 스레드 중 하나을 대기 상태에서 깨운다.
SetEvent(hWriteEvent);
}
return 0;
}
DWORD WINAPI ReadThread(LPVOID arg)
{
DWORD retval;
while (1)
{
// 쓰기 완료 대기
// 쓰기 이벤트가 신호 상태가 되기를 기다린다. 최초에는 비신호 상태로 시작하기 때문에 이 지점에서 읽기 스레드는 대기 상태가 된다.
retval = WaitEventSingleObject(hWriteEvent, INFINITE);
if (retval != WAIT_OBJECT)
break;
// 읽은 데이터 출력
printf("Thread %4d: ", GetCurrentThreadId());
for (int i = 0; i < BUFSIZE; i++)
printf("%3d\n", buf[i]);
printf("\n");
// 버퍼 초기화
// 만약 데이터를 새로 쓰지 않은 생태에서 다시 읽게 된다면 0을 출력될 것이므로 오류 여부를 확인할 수 있다.
ZeroMemory(buf, sizeof(buf));
// 읽기 완료 알림
// 읽기 이벤트를 신호 상태로 만들어 쓰기 스레드를 대기 상태에서 깨운다.
SetEvent(hReadEvent);
}
return 0;
}
int main(int argc, char **argv)
{
// 자동 리셋 이벤트 2개 생성(각각 비신호, 신호 상태)
hWriteEvent = CreateEvent(NULL, FALSE, FALSE, NULL); // 비신호
if (hWriteEvent == NULL)
return 1;
hReadEvent = CreateEvent(NULL, FALSE, TRUE, NULL); // 신호
if (hReadEvent == NULL)
return 1;
// 스레드 3개 생성
HANDLE hThread[3];
hThread[0] = CreateThread(NULL, 0, WriteThread, NULL, 0, NULL); // 쓰기 스레드
hThread[1] = CreateThread(NULL, 0, ReadThread, NULL, 0, NULL); // 읽기 스레드
hThread[2] = CreateThread(NULL, 0, ReadThread, NULL, 0, NULL); // 읽기 스레드
// 스레드 3개 종료 대기
// 스레드 3개가 종료하기를 기다린다. 읽기 스레드는 별도의 루프 탈출 조건이 없어 사실상 영원히 리턴하지 못한다.
WaitForMultipleObjects(3, hThread, TRUE, INFINITE);
// 이벤트 제거
CloseHandle(hWriteEvent);
CleseHandle(hReadEvent);
return 0;
}실행 결과는 다음과 같다.