
26. 트랜지스터의 관점에서 CPU란?
Reference : https://chinggin.tistory.com/677
-
CPU는 트랜지스터라고 하는 반도체로 만들어졌다. 반도체는 주로 실리콘으로 만들어지고, 전자가 한 개 많거나(N형 반도체), 적을 때(P형 반도체) 전류가 흐르게되는 것을 원리로 반도체는 작동한다. 이러한 N, P형 반도체를 결합해 전압의 차이로 스위치 작용을 해주는 반도체를 트랜지스터라고 한다.
-
이러한 트랜지스터를 이용하면 논리회로를 만들 수 있다.
컴퓨터는 0과 1로 이루어진 디지털 신호를 인식하고 전류가 흐르면 1(참), 흐리지 않으면 0(거짓)으로 인식한다.
이러한 다양한 트랜지스터로 우리는 AND, OR, NOT 논리게이트를 만들어서 사용한다. -
CPU에는 산술 논리 장치가 존재하는데 이 장치는 산수를 계산하고 논리를 연산하는 역할을 한다. 앞에서 보았던 논리게이트를 이용하여 산술 논리 장치를 만들게 된다.
트랜지스터는 매우 작고 CPU에는 수십 억 개의 트랜지스터가 들어 있다. 모스펫이라는 트랜지스터가 CPU 내부에 구성되어있고 이러한 모스펫들이 모여 많은 논리게이트를 이루고 연산을 수행한다. -
우리의 프로그램은 하드디스크에 저장되어있다. 하지만 CPU의 속도에 비해서 하드디스크는 너무 느리기 때문에 CPU는 하드 대신 램과 통로를 구성하고 있다. 하지만 램도 CPU에 비해선 속도가 많이 느리기 때문에 CPU 내부나 근처에 캐시 메모리를 만들어 그 곳에 데이터를 저장한다. 다만 용량이 매우 적기 때문에 중요하다고 생각되는 데이터만 저장한다.
-
캐시 메모리는 L1~L3까지 단계를 나누어 사용한다. L1은 CPU가 가장 먼저 접근하는 메모리로 속도가 가장 빠르지만 용량은 적다, L3는 용량이 크지만 속도가 느리다.
CPU의 데이터 요청 순서는 L1 -> L3, 램 순서로 데이터를 찾게 된다. 우리는 램과 캐시 메모리를 통틀어 메모리라고 할 수 있다. -
마지막으로 컴퓨터의 기억장치는 하드, 램, 캐시, 레지스터가 존재한다. 레지스터는 CPU 내부에서 데이터를 일시적으로 저장하는 장치로 속도가 가장 빠른 메모리이다.
27. DB에서 트랜잭션이란?
Reference : https://coding-factory.tistory.com/226
트랜잭션의 정의
트랜잭션(Transaction)은 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미한다.
트랜잭션의 특징
-
트랜잭션은 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위이다.
-
사용자가 시스템에 대한 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업단위이다.
-
하나의 트랜잭션은 Commit되거나 Rollback된다.
트랜잭션의 성질
- Atomicity(원자성)
- 트랜잭션의 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다.
- 트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 모두가 완벽히 수행되지 않고 어느하나라도 오류가 발생하면 트랜잭션 전부가 취소되어야 한다.
- Consistency(일관성)
-
트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
-
시스템이 가지고 있는 고정요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.
- Isolation(독립성,격리성)
-
둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행중에 다른 트랜잭션의 연산이 끼어들 수 없다.
-
수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다.
- Durablility(영속성,지속성)
- 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
트랜잭션 연산 및 상태
- Commit연산
- Commit 연산은 한개의 논리적 단위(트랜잭션)에 대한 작업이 성공적으로 끝났고 데이터베이스가 다시 일관된 상태에 있을 때, 이 트랜잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산이다.
- Rollback연산
-
Rollback 연산은 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관성을 깨뜨렸을 때, 이 트랜잭션의 일부가 정상적으로 처리되었더라도 트랜잭션의 원자성을 구현하기 위해 이 트랜잭션이 행한 모든 연산을 취소(Undo)하는 연산이다.
-
Rollback시에는 해당 트랜잭션을 재시작하거나 폐기한다.
- 트랜잭션의 상태
-
활동(Active) : 트랜잭션이 실행중인 상태
-
실패(Failed) : 트랜잭션 실행에 오류가 발생하여 중단된 상태
-
철회(Aborted) : 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태
-
부분 완료(Partially Committed) : 트랜잭션의 마지막 연산까지 실행했지만, Commit 연산이 실행되기 직전의 상태
-
완료(Committed) : 트랜잭션이 성공적으로 종료되어 Commit 연산을 실행한 후의 상태
28. DB에서의 데드락 문제는 어떤 상황에서 일어나는가?
Reference : https://blog.naver.com/ndb796/221243161017
운영체제에서 교착상태(Dead Lock)는 각각의 프로세스가 서로의 자원을 점유하기 위해 대기하면서 문제가 발생한다.
DB에서 교착상태는 여러 개의 트랜잭션(Transaction)들이 실행을 하지 못하고 서로 무한정 기다리는 상태를 의미한다
트랜잭션 1이 테이블 B에 insert하게 되면서 첫 번째 행의 Lock(잠금)을 얻는다. 트랜잭션 2도 테이블 A의 첫 번째 행의 Lock(잠금)을 얻는다.
Transaction 1> start transaction; insert into B values(1);
Transaction 2> start transaction; insert into A values(1);여기서 트랜잭션을 commit 하지 않은채 서로의 첫번째 행에 대한 잠금을 요청하면 Deadlock이 발생한다.
Transaction 1> insert into A values(1);
Transaction 2> insert into B values(1);
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction교착 상태 해결 방안
DB(데이터베이스)에서 교착상태(Dead Lock)을 해결하기 위한 방법은 아래와 같다.
- 예방 기법
- 회피 기법
- 낙관적 병행 제어 기법
- 빈도 줄이기 기법
-
예방 기법
각 트랜잭션이 실행되기 전에 필요한 모든 자원을 Lock(잠금)한다.
필요한 모든 데이터를 Lock(잠금)해야 하므로 병행성이 떨어진다.
SET LOCK_TIMEOUT문을 통해 일정 시간이 지나면 쿼리를 취소한다.
기존의 교착상태인 데이터가 있다면, 그 데이터에 접근하는 쿼리만 취소한다.
즉, 근본적인 해결책이 될 수 없다. -
회피 기법
회피 기법은 자원을 할당할 때 시간 스탬프(Time Stamp)를 활용해서 교착상태가 일어나지 않도록 회피하는 방법이다. 예방 기법의 단점 때문에 실제로는 회피 기법이 많이 사용된다.회피 기법의 종류는 크게 2가지가 있다.
Wait-Die 방식
트랜잭션 A가 트랜잭션 B에 의해 잠금된 데이터를 요청할 때 트랜잭션 A이 먼저 들어온 트랜잭션이라면 대기(Wait)한다.
트랜잭션 A가 나중에 들어온 트랜잭션이라면, 포기(Die)하고 나중에 다시 요청한다.Wound-Wait 방식
트랜잭션 A가 트랜잭션 B보다 먼저 들어온 트랜잭션이라면, 데이터를 선점(Wound)한다.
반면, 트랜잭션A가 트랜잭션 B보다 나중에 들어온 트랜잭션이라면 대기(Wait)한다. -
낙관적 병행 제어 기법
낙관적 병행 제어 기법은 트랜잭션이 실행되는 동안에는 검사를 수행하지 않고, 트랜잭션이 커밋된 후에 데이터에 문제가 있다면 롤백(Rollback)하는 방법이다.즉, 낙관적 병행 제어 기법은 판독->확인->기록 단계를 따른다. 확인 단계를 성공적으로 거친 트랜잭션만 기록 단계를 수행할 수 있다.
- 빈도 줄이기
트랜잭션을 자주 커밋한다.
정해진 순서로 테이블에 접근한다. (위에서는 트랜잭션 1은 B->A 순, 트랜잭션 2는 A->B순으로 접근했다.)
읽기 잠금 (SELECT ~ FOR UPDATE)의 사용을 피한다.
테이블 단위의 Lock(잠금)을 획득해 갱신을 직렬화한다. (테이블의 복수행을 복수의 연결에서 순서 없이 갱신하면 교착상태가 자주 발생하기 때문)
Index 설계 (Update시 Index를 타지 않으면 테이블 전체에 Lock이 걸릴 수 있다.)
Isolation level(고립 수준)을 낮춘다. (서비스 검토 필요)
29. Reliable UDP
Reference : https://elky.tistory.com/258
Reliable UDP (이하 RUDP)는 신뢰성을 갖는 UDP를 의미한다.
일반적으로 TCP는 신뢰성을 갖는 대신 느리고, UDP는 신뢰성이 없고 빠르다고 알려져있다.
여기에 또 하나의 특징은, TCP는 서버 (Listener)와, 클라이언트 (Connector) 관계가 성립한다는 점이다.
즉, 서버건 클라이언트건 연결 관리가 필요하다는 것이다.
RUDP의 필요성은, 주로 클라이언트 끼리의 통신에서 대두되었다.
우선 일반적인 클라이언트/서버 구조에서의 클라이언트 끼리의 통신은 서버를 경유해서 데이터를 전송함으로써 신뢰성을 갖추는데, UDP보다 느리고 서버에 부하를 주기 때문에 클라이언트 끼리의 통신에서도 TCP의 장점은 신뢰성과, UDP의 장점은 속도를 모두 갖춘 Reliable UDP가 등장하게 된 것이다.
TCP는 한쪽이 서버가 되어서 대기 하고 있어야하지만, UDP는 그럴 필요가 없이 바로 통신이 가능하다는 점도 또 하나의 장점이다.
보통 RUDP는 Relay Server와 연동되어서 구현이 되는데, 모든 상황에서 UDP 통신이 가능한 것이 아니기 때문에, UDP 통신이 실패했을 때 신뢰성 갖춘 통신을 위해 Relay Server를 통한 데이터 전송을 해주기 위해서이다.
우선 UDP가 Reliable 해지기 위한 방법부터 알아본다면,
TCP가 UDP와 다른 점은 신뢰성이 있다고 얘기했었는데, TCP가 신뢰성을 갖추고 있는 이유를 먼저 얘기해본다면,
- 데이터의 순서를 보장해준다. 보낸 순서와 받는 순서가 일치하게 해준다는 의미이다.
- 데이터의 도착을 보장해준다. 보낸 데이터가 반드시 도착한다는 것을 보장해준다는 의미이다.
- 데이터의 무결성을 보장해준다. 즉, 보낸 데이터와 받는 데이터가 일치 하다는 것을 보장한다는 의미이다.
위의 세가지 조건을 만족하기에 TCP가 신뢰성을 갖추고 있다고 말하는 것이고, RUDP도 마찬가지로 위 세가지 조건을 UDP를 통해 만족하도록 구현함으로써 신뢰성을 갖게 되는 것이다.
순서를 보장하는 방법은 패킷에 번호를 붙이고, 번호순서대로 패킷이 도착할때까지 기다렸다가 패킷이 모두 모이면 그때 패킷을 풀면된다.
도착을 보장하는 방법은 패킷에 번호를 붙이고, 해당 번호의 패킷이 도착할때까지 재전송하면 된다.
보내는 입장에서 재전송을 하는 이유는, UDP이기에 받는 입장에서는 자신에게 보내려는 패킷이 있었는지 알 방법이 없기 때문이다.
무결성을 보장하는 방법은 체크섬을 통해서, 데이터가 손실되지 않았는지 검증한다.
RUDP사용시 주의사항은, UDP로 연결을 시도하는 중에도 릴레이 서버를 통한 패킷 전달은 지속적으로 이루어 져야 한다는 점이다.
그리고 UDP연결이 성공했을 때 UDP를 통한 송신을 시작해야 한다.
UDP 송수신 중에는 연결 유지를 위해 일정 시간 간격으로 HeartBeat 패킷을 보내고, 일정 시간동안 해당 패킷이 도착하지 않는다면 UDP전송이 다시금 불가능해진 것으로 판단하여, 릴레이 서버를 이용하도록 하면서 지금껏 전송 확인이 안된 패킷들을 릴레이를 통해 전달하면 된다. 이렇게 해야 패킷의 지연은 있을 수 있으나 패킷의 소실은 발생하지 않는다.
30. 개방-폐쇄 원칙(OCP, Open-Closed Principle)
개방 폐쇄 원칙 - OCP (Open Closed Principle)
개방 폐쇄의 원칙(OCP)이란 기존의 코드를 변경하지 않으면서, 기능을 추가할 수 있도록 설계가 되어야 한다는 원칙을 말한다.
보통 OCP를 확장에 대해서는 개방적(open)이고, 수정에 대해서는 폐쇄적(closed)이어야 한다는 의미로 정의한다.
여기서 확장이란 새로운 기능이 추가됨을 의미한다.
따라서 해석하자면, 기능 추가 요청이 오면 클래스를 확장을 통해 손쉽게 구현하면서, 확장에 따른 클래스 수정은 최소화 하도록 프로그램을 작성해야 하는 설계 기법을 말한다고 보면 된다.
[ 확장에 열려있다 ]
- 모듈의 확장성을 보장하는 것을 의미한다.
- 새로운 변경 사항이 발생했을 때 유연하게 코드를 추가함으로써 애플리케이션의 기능을 큰 힘을 들이지 않고 확장할 수 있다.
[ 변경에 닫혀있다 ]
- 객체를 직접적으로 수정하는건 제한해야 한다는 것을 의미한다.
- 새로운 변경 사항이 발생했을 때 객체를 직접적으로 수정해야 한다면 새로운 변경사항에 대해 유연하게 대응할 수 없는 애플리케이션이라고 말한다.
- 이는 유지보수의 비용 증가로 이어지는 매우 안좋은 예시이다.
- 따라서 객체를 직접 수정하지 않고도 변경사항을 적용할 수 있도록 설계해야 한다. 그래서 변경에 닫혀있다고 표현한 것이다.
어렵게 생각할 필요없이, OCP 원칙은 우리가 객체 지향 프로그래밍을 하면서 질리도록 배웠던 추상화를 의미하는 것으로 보면 된다.
oop-solid-ocp
즉, OCP는 다형성과 확장을 가능케 하는 객체지향의 장점을 극대화하는 설계 원칙으로써, 우리는 코딩할때 강의에서 배운대로 객체를 추상화함으로써, 확장엔 열려있고 변경엔 닫혀있는 유연한 구조를 만들어 사용해오며 객체 지향 프로그래밍의 OCP 원칙의 효과를 이용해왔던 것이다.
그래서 클래스를 추가해야한다면 기존 코드를 크게 수정할 필요없이, 적절하게 상속 관계에 맞춰 추가만 한다면 유연하게 확장을 할 수 있었던 것이다.
31. OS에서의 멀티스레드
Reference : https://rebro.kr/174
Thread
스레드(Thread)는 CPU 수행의 기본 단위 또는 프로세스 안의 제어권의 흐름이다. 스레드가 수행되는 환경을 Task라고 부르는데, 전통적인 프로세스는 하나의 스레드가 있는 Task와 일치한다.
스레드는 Thread ID, Program counter, Register set, Stack space로 구성된다. 각각의 스레드는 주로 최소한 자신의 레지스터 상태와 스택을 갖는다.
반면 Code, Data 섹션이나 운영체제 자원들은 스레드끼리 공유한다. 아래 그림을 참고해보자.
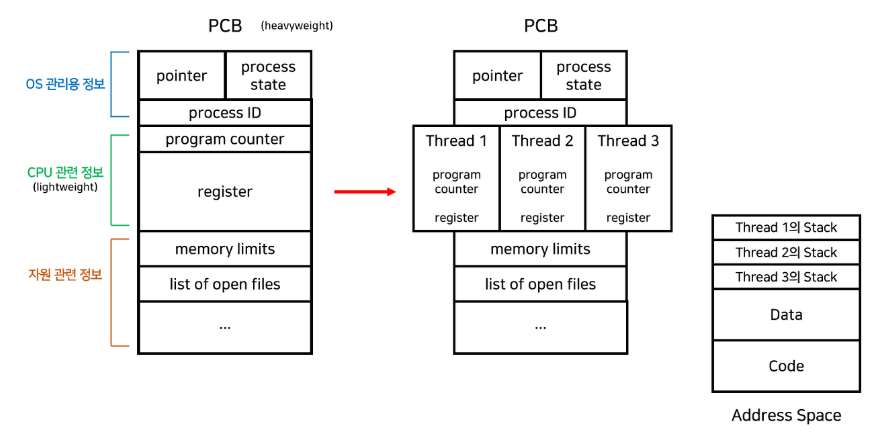
한 프로세스가 하나의 스레드를 이용하여 한 번에 한 작업만 수행하는 것은 싱글 스레드(Single thread), 한 프로세스가 여러 스레드로 동시에 여러 작업을 수행하는 것은 멀티 스레드(Multi thread)라고 한다. 프로세스 내의 스레드는 모두 각각 독립적인 실행 파일이며, 모든 스레드는 프로세스의 일부이다. 프로세스를 여러 개 수행해도 되지만 굳이 스레드를 사용하는 이유는 다음과 같다.
-
프로세스를 생성하거나 Context switching 하는 작업은 너무 무겁고 잦으면 성능 저하가 발생하는데, 스레드를 생성하거나 switching 하는 것은 그에 비해 가볍다.
-
두 프로세스가 하나의 데이터를 공유하려면 메시지 패싱이나 공유 메모리 또는 파이프를 사용해야 하는데, 이는 효율도 떨어지고 개발자가 구현, 관리하기도 번거롭다.
Multithreading
프로세서가 여러 개인 경우 멀티 스레드를 통해 병렬성(Parallelism)을 높일 수 있다. 즉, 여러 작업이 동시에 수행될 수 있다.
이는 프로세스의 스레드들이 각각 다른 프로세서에서 병렬적으로 수행될 수 있기 때문이다. 병렬성은 CPU의 개수에 비례한다.
만약 프로세서가 하나인 경우엔 멀티 스레드를 통해 동시성(Concurrency)을 높일 수 있다. 실제로는 각각의 시간에 한 작업만 수행되지만, 병렬적으로 수행되는 것처럼 보이는 것이다. 만약 한 스레드가 blocked(waiting) 되더라도 커널이 다른 스레드로 switch 시켜 실행할 수 있어서, 하나의 프로세서임에도 불구하고 빠른 처리가 가능하고 계산 속도가 증가한다.
멀티스레딩의 장점은 뭘까?
- 응답성(Responsiveness)
싱글 스레드인 경우, 작업이 끝나기 전까지 사용자에게 응답하지 않는다. 반면 멀티스레드인 경우 작업을 분리해서 수행하므로 실시간으로 사용자에게 응답할 수 있다.
- 자원 공유(Resource sharing)
프로세스는 오직 공유 메모리나 메시지 패싱을 이용해서 자원을 공유할 수 있지만, 스레드는 자신이 속한 프로세스 내의 스레드들과 메모리나 자원을 공유하여 효율적으로 사용할 수 있다.
- 경제성(Economy)
프로세스를 새로 생성하는 비용보다 스레드를 새로 생성하는 게 훨씬 싸다. 그리고 Context switching의 오버헤드 또한 스레드가 더 경제적이다. 실제로 Solaris에서 프로세스 생성은 스레드 생성보다 30배 느리고, switching은 5배 느리다.
- 확장성(Scalability)
싱글 스레드인 경우 한 프로세스는 오직 한 프로세서에서만 수행 가능하다. 반면 멀티 스레드인 경우 한 프로세스를 여러 프로세서에서 수행할 수 있으므로 훨씬 효율적이다.
User-level Thread vs Kernel-level Thread
유저 스레드(User-level Thread)는 커널 위에서 커널의 지원 없이 유저 수준의 스레드 라이브러리(Thread Library)가 관리하는 스레드다. 반면 커널 스레드(Kernel-level Thread)는 커널이 지원하는 스레드다.
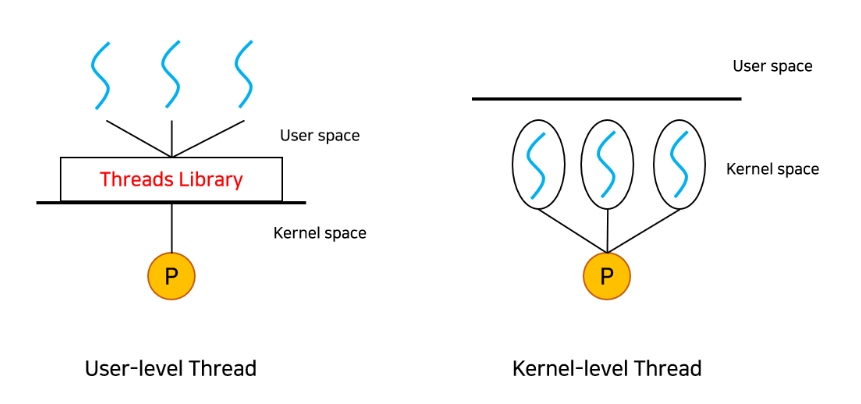
커널 스레드를 사용하면 안정적이지만 유저 모드에서 커널 모드로 계속 바꿔줘야 하기 때문에 성능이 저하된다. 반대로 유저 스레드를 사용하면 안정성은 떨어지지만 성능이 저하되지는 않는다.
유저 스레드와 커널 스레드 사이에 어떠한 관계가 항상 존재한다. 이 관계를 설계하는 여러 가지 방법이 있다.
- Many-to-One Model
하나의 커널 스레드에 여러 유저 스레드를 연결하는 모델이다. 유저 공간의 스레드 라이브러리를 통해서 스레드가 관리되므로 효율적이다. 라이브러리를 위한 모든 코드나 자료구조가 유저 공간에 존재하므로 라이브러리의 함수 호출이 시스템 콜이 아니라 지역 함수 호출의 결과를 낳기 때문이다.
반면, 한번에 한 유저 스레드만 커널에 접근할 수 있기 때문에 멀티 프로세서 시스템에서 병렬적인 수행을 할 수 없어 요즘에는 잘 사용되지 않는 방식이다. 한 유저 스레드의 시스템 콜로 인해 block 되면 프로세스 전체가 block 되기 때문이다.
- One-to-One Model
하나의 커널 스레드에 하나의 유저 스레드가 대응하는 모델이다. 동시성(Concurrency)을 높여주고, 멀티 프로세서 시스템에서 동시에 여러 스레드를 수행할 수 있도록 해준다.
단점으로는, 유저 스레드를 늘리면 커널 스레드도 똑같이 늘어나는데, 커널 스레드의 생성은 오버헤드가 크기 때문에 성능 저하가 발생할 수 있다.
- Many-to-Many Model
여러 유저 스레드에 더 적거나 같은 수의 커널 스레드가 대응하는 모델이다. 운영체제는 충분한 수의 커널 스레드를 만들 수 있으며, 커널 스레드의 구체적인 개수는 프로그램이나 작동 기기에 따라 다르다. 멀티 프로세서 시스템에서는 싱글 프로세서 시스템보다 더 많은 커널 스레드가 만들어진다.
완전한 동시성은 아니지만, Many-to-one Model에 비해 더 높은 동시성을 갖는다. 그리고 One-to-One Model의 단점이었던 커널 스레드 생성의 오버헤드도 걱정할 필요 없다.
- Two-level Model
Many-to-Many Model에서 확장된 개념이다. 특정 유저 스레드를 위한 커널 스레드를 별도로 제공하는 모델이다. 점유율이 높아야 하는 유저 스레드를 더 빠르게 처리할 수 있다.
Threading Issues
Multi-threaded 프로그램을 디자인할 때 고려해야 할 몇 가지가 있다.
- Semantics of fork( ) and exec( ) system calls
만약 fork( ) 이후에 exec( )을 바로 호출한다면 exec( )으로 인해 스레드를 포함한 전체 프로세스가 대체되기 때문에 모든 스레드를 복제하는 것은 불필요할 것이다. 그렇지 않으면 모든 프로세스를 복제해야 한다.
따라서 몇몇 UNIX 시스템은 두 버전의 fork( )를 가진다.
- Signal Handling
시그널(Signal)은 특정한 사건이 발생했다고 프로세스에게 알려주기 위해 UNIX 시스템에서 사용하는 것이다. 자원이나 시그널의 원인에 따라 두 종류로 나뉜다.
1) Synchronous signals
- 시그널을 일으킨 작업을 수행한 프로세스에 전달된다. (ex. division by 0, illegal memory access)
2) Asynchronous signals
- 수행중인 프로세스의 외부 사건에 의해 만들어진다. (ex. Ctrl+C과 같은 특정 키 입력으로 인한 종료, 타이머 종료)
시그널을 다루는 방법 또한 다양하다.
싱글 스레드 프로그램에서는 시그널이 특정 사건에 의해 생성되고, 프로세스에 전달된 후 다뤄진다.
멀티 스레드 프로그램에서는 시그널을 제공한 스레드로 시그널이 전달되거나(ex. Synchronous signals), 프로세스 내의 모든 스레드에 전달되거나(ex. process termination signal), 프로세스 내의 특정한 스레드에 전달될 수 있다(some asynchronous signals to non-blocking threads). 혹은 프로세스의 모든 시그널을 전달받는 특별한 스레드를 할당하는 방법도 있다.
- Thread Cancellation
스레드가 끝나기 전에 종료시키는 두 방식이 있다.
1) Asynchronous cancellation : 목표 스레드(Target thread)를 즉시 종료시킨다.
2) Deferred cancellation : 목표 스레드가 종료되어야 하는지 주기적으로 체크한다.
- Thread Pools
스레드를 요청할 때마다 매번 새로운 스레드를 생성, 수행, 삭제를 반복하면 성능이 저하된다. 따라서 미리 스레드 풀(Thread pools)에 여러 스레드를 만들어두고 요청이 오면 스레드 풀에 기존에 존재하던 스레드를 할당해주는 방법을 사용한다.
새 스레드를 만드는 것보다 기존에 존재하는 스레드를 사용하는 것이 약간 더 빠르고, 많은 양의 스레드를 일정한 크기의 pool 안에 묶어둘 수 있는 장점이 있다.
- Thread Local Storage
각각의 스레드들이 자신의 영역을 만들어 관리할 수 있도록 해주는 것이다. static data와 유사하다.
로컬 변수(local variable)와 혼동하면 안 된다. 로컬 변수는 한 함수가 수행되는 동안만 visible 하다.


잘봤습니다 ^^7