이전에 파이콘 2020 에서 들었던 내용인데
세미나 발표 내용이 개인적으로 알게 된 부분들이 많았었습니다.👍
(김성렬님께 감사합니다🙏)
개인적으로 다시 한번 리마인드 차원에서 블로그에 한번 정리하려고 합니다.
발표 정보 👀
-
https://www.youtube.com/watch?v=EZgLfDrUlrk&ab_channel=PyConKorea
-
https://github.com/KimSoungRyoul/Django_ORM_pratice_project/issues/7
QuerySet을 통해 알아보는 ORM의 특징
1) Lazy Loading 지연로딩 : 정말 필요한 시점에 SQL을 호출
1-1) 실제로 쿼리가 호출되는 시점
- list()로 쿼리셋을 묶는 로직이 수행될때 SQL이 호출된다
- [내가 추가한 내용] : QuerySet을 만드는 동안에는 DB접근을 하지 않는다.
- print(query_set)
- iteration : for instance in query_set: print(instance)
- Slicing
- repr() : 파이썬 인터프리터를 위한 것, API를 인터프리터로 사용할 때 즉시 결과를 볼 수 있다.
- len()
- bool()
...
from .models import Post
query_set = Post.objects.all() # QuerySet. 아직 SQL 호출안됨.
list(query_set)1-2) 만약 QuerySet을 선언했지만 사용하지 않는다면 SQL은 호출되지 않는다.
from .models import Post
query_set = Post.objects.all() # QuerySet. 아직 SQL 호출안됨. 사용하는 곳 없음.1-3) 현 시점에 딱 필요한 만큼만 데이터를 가져옴
- ORM은 이후 로직을 알지 못한다.
- 현 시점에 딱 필요한 만큼만 데이터를 가져오려 하기 때문에 비효율적으로 데이터를 가져올 수 있다.
- SQL을 한번만 호출해서 데이터를 재사용할 것
# 불필요하게 SQL이 두번 호출
# 실수 예제
from .models import Post
query_set = Post.objects.all() # QuerySet. 아직 SQL 호출안됨.
first_post = query_set[0] # <Post: Post object (1)>
post_list = list(query_set) # [<Post: Post object (1)>, <Post: Post object (2)>, <Post: Post object (3)>]
2) Caching : QuerySet 캐싱을 재사용 하는 법
2-1) 쿼리셋을 호출하는 순서가 바뀌는것 만으로도 QuerySet 캐싱 때문에 발생하는 SQL이 달라질 수 있다.
1-3 실수예제를 해결 할 수 있음.- 모든 post 를 가져오는 sql이 호출되어서
post_list 쿼리셋에는 모든 post 데이터가 캐싱되어있음
from .models import Post
query_set = Post.objects.all() # QuerySet. 아직 SQL 호출안됨.
post_list = list(query_set)
first_post = query_set[0] # QuerySet 캐싱으로 인해서 SQL 호출되지 않음.
# 이미 모든 post_list 에 대한 정보를 가지고 있고
# 0번째 post 를 캐싱해서 가져옴.
3) Eager Loading 즉시로딩 : N+1 Problem
3-1) N+1 Problem ?
- 쿼리 1번으로 N건의 데이터를 가져왔는데 원하는 데이터를 얻기 위해
이 N건의 데이터를 데이터 수 만큼 반복해서 2차적으로 쿼리를 수행하는 문제다. - Lazy Loading 으로 인해서 발생되는 문제 중 하나이다.
(밑에 예제코드를 기준으로 설명)
- for post in posts:
- 모든 Post 조회함 (SQL 실행: 1)
- post.title
- 반복문 돌면서 title 접근 (SQL 실행: N번)
post의 title 값은 캐싱되어 있지 않아서 SQL 호출- 사실 모든 post 정보가 posts에 담겨있지만 QuerySet은 모른다.
- 반복문 돌면서 title 접근 (SQL 실행: N번)
- N+1 Problem을 해결하기 위해 (==즉시로딩을 하기위해) Django는 select_related()와 prefetch_related() 라는 메서드를 제공
from .models import Post
posts = Post.objects.all() # QuerySet. 아직 SQL 호출안됨.
# 개발자 입장에서는 각 post의 title 정보가 posts에 담겨 있는 것을 알지만 QuerySet은 모른다.
for post in posts: # 모든 Post 조회함 (SQL 호출: 1)
# QuerySet 입장에서는 post의 title 정보가 필요한 시점은 여기.
# 따라서 title 를 알기위해서 SQL이 for 문을 돌때마다 N번 호출한다. (SQL 호출: N번)
post.title # post.title를 조회할때마다 sql이 계속 호출되는 문제가 발생
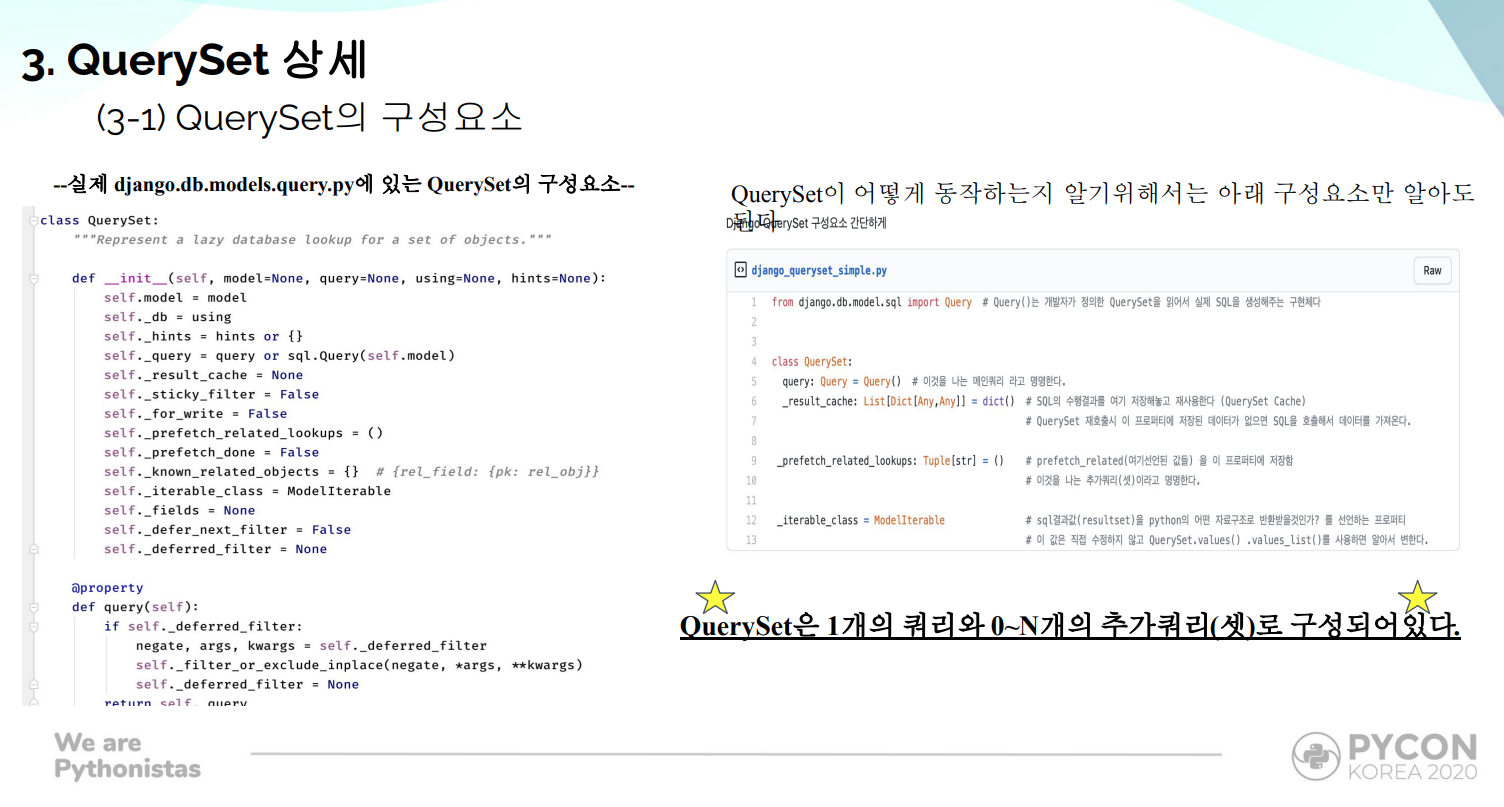
4) QuerySet 상세
4-1) QuerySet은 1개의 쿼리와 0~N개의 추가쿼리(셋)로 구성되어있다.
4-2) select_related() 와 prefetch_related()
- select_related()
- join을 통해서 데이터를 즉시 로딩하는 방식
- prefetch_related()
- 추가 쿼리를 통해서 데이터를 즉시 로딩하는 방식
- 모델M:모델R 가 (1 : N) 관계 일때
- 모델M 입장에서 모델R은
역방향 참조 모델 - 모델R 입장에서 모델M은
정방향 참조 모델
- 모델M 입장에서 모델R은
- 역방향참조 모델은 select_related()에 줄수없다.
- Model.objects().filter(조건절).prefetch_related().select_related()
- 위의 순서 django 에서 지원 안됨.
- Model.objects().filter(조건절).select_related().prefetch_related()
- django 에서 지원 됨.
- Model.objects().filter(조건절).prefetch_related().select_related()
- 정방향참조 모델은 select_related(), prefetch_related()에 옵션으로 둘다 가능
하지만 특별한 이유가 없다면 select_related를 권장함
(
Model.objects
.filter(조건절)
.select_related('정방향 참조 필드') # join으로 가져옴
.prefetch_related('역방향 참조 필드') # 추가쿼리로 가져옴
)- inner/outer 여부는
QuerySet조건절 변경에 따라 JOIN 옵션이 변할수있음
하지만 일반적으로
ForiegnKey(null=True) 이면 OUTER JOIN
ForigenKey(null=False) 이면 INNER JOIN
select * from 'Model' m
(inner OR left outer) join '정방향 참조 필드' r on m.r_id == r.id where 조건절;
select * from '역방향 참조 필드' where id in ('첫번째 쿼리 결과의 id 리스트');
4-3) prefetch_related()는 추가 쿼리셋이다
- QuerySet은 1개의 쿼리와 N개의 쿼리(셋)로 이루어져있다.
- 1개의 메인 쿼리
- N개의 추가 쿼리
- prefetch_related()에 주어진 옵션들은 전부 새로운 쿼리셋으로 수행된다.
- query_set_1 과 query_set_2 의 SQL 문은 동일하다.
예제 코드1
"""
1. 메인모델에 역참조된 모델들을 전부 조회하고 싶다면
단순히 역참조필드만 선언해주면
해당 필드를 조회하기위한 SQL이 1개가 더 수행된다.
(이 예제의 경우는 2개를 선언했기때문에 SQL이 2개 더 추가 수행된다.)
"""
query_set_1 = (
AModel.objects.
prefetch_related(
'b_model_set',
'c_models',
)
)
from djngo.db.models import Prefetch
query_set_2 = (
AModel.objects.
prefetch_related(
Prefetch(to_attr='b_model_set', queryset=BModel.objects.all()),
Prefetch(to_attr='c_models', queryset=CModel.objects.all())
)
)
예제 코드1 : SQL 결과
select * from a_model;
select * from b_model where id in (~~~);
select * from c_model where id in (~~~);
예제 코드2
"""
2. 추가적인 조건절을 걸고싶다면 ?
Prefetch() 문법을 사용해서 추가쿼리(셋)을 제어하면된다.
"""python
from djngo.db.models import Prefetch
query_set_2 = (
AModel.objects.
prefetch_related(
Prefetch(to_attr='b_model_set', queryset=BModel.objects.filter(is_deleted=False)),
Prefetch(to_attr='c_model', queryset=CModel.objects.all())
)
)
예제 코드2 : SQL 결과
select * from a_model;
select * from b_model where id in (~~~) and is_deleted is False;
select * from c_model where id in (~~~);
4-4) SQL Preformance를 커버하는 Testcase [CaptureQueriesContext를 활용하자]
- N+1문제로 인한 크리티컬한 성능 이슈만 커버할때 사용
- assertNumQueries()로 테스트케이스를 작성해놓으면
API가 수정될때 마다 달라지는 SQL갯수를 체크해줘야됨.
5) 실수하기 쉬운 QuerySet의 특성들
5-1) prefetch_related() 와 filter() 는 완전 별개다
실수 예제 : 비효율적
- 실제 SQL 동작: 메인쿼리에서 JOIN하고 추가쿼리에서 한번더 조회하게 됨.
- 실제 SQL 동작 순서: filter -> prefatch_related
- filter 에서 join 하고
prefatch_related 에서 추가 쿼리
- filter 에서 join 하고
company_queryset = (
Company.objects.
prefatch_related('prodcut_set').
filter(name='company_name1', BModel__name__isnull=False)
)
# SQL: 1번째 호출: Company, filter
select * from "company"
inner join "product"
on ("company"."id" = "product"."product_owned_company_id")
where ("company"."name" = "company_name1"
and "product"."name" IS NOT NULL)
# SQL: 2번째 호출
# prefatch_related
select * from "product"
where "product"."product_owned_company_id" in (1, 43, 75, 23)
해결방법 예제1) prefatch_related 옵션 제거
queryset = (
Company.objects.
# prefatch_related('product_set').
filter(name='company_name1', product__name__isnull=False)
)해결방법 예제2) filter()에 넣었던 BModel 관련 조건절을 Prefetch() 에 제공
- 추가쿼리에 where문이 수정됨
queryset = (
Company.objects.
filter(name='company_name1').
prefatch_related(
'product_set',
Prefetch(queryset=Product.objects.filter(BModel__name__isnull=False))
)
)6) QuerySet 작성 순서

7) queryset 캐시를 재활용하지 못하는 queryset 호출
- first_company.product_set.all()
- all() 로 질의 하면 result_cache 를 재사용함.
- first_company.product_set.filter(name="상품명_1")
- 이전에 all()이 캐싱되어 있었음.
filter 를 통해서 특정 상품을 찾으려 하면 result_cache 를 재사용하지 않고 SQL 로 질의함.
- 이전에 all()이 캐싱되어 있었음.
company_list = list(Company.objects.prefetch_related("produtct_set".all()) # EagerLoading함
first_company = company_list[0]
first_company.product_set.all() # 여기서는 EagerLoading해서 SQL 발생 안함
first_company.product_set.filter(name="상품명_1") # 하지만 이러면 SQL이 발생됨
# sql 을 발생시키지 않으려면 아래처럼 써야됨.
filtered_product_list = [product for product in first_company.product_set.all() if product.name=="상품명1"]8) RawQuerySet은 NativeSQL이 아니다
- QuerySet 과 RawQuerySet 의 가장 큰 차이점은
- QuerySet._query 는 sql.Query
- sql.Query: django 에서 제공해주는 query 구현체
- RawQuerySet._query 는 sql.RawQuery
- sql.RawQuery: 사용자가 입력해주는 SQL 문
- QuerySet._query 는 sql.Query
- RawQuerySet은 QuerySet의 또다른 유형이기 때문에 prefetch_related(), Prefetch()는 사용가능
- RawQuerySet은 아래와 같은 메서드는 사용할 수 없다. (아래의 메서드를 사용하려면 NativeSQL로 작성해야됨)
.select_related()- 메인쿼리의 JOIN 옵션을 주는 메서드
FilterRelation()- JOIN이 안되니 ON절 제어 옵션 사용 불가
.annotate()- 메인쿼리에 AS 옵션을 주는 메서드
.order_by()- 메인쿼리에 order by 옵션 주는 메서드
- '.extra()'
- 메인쿼리에 sql을 추가 반영하는 메서드
- '[:N]'
- 메인쿼리에 limit 옵션을 걸수 없음
from django.db.models.query import RawQuerySet
from django.db.models import QuerySet
# RawQuerySet
a_model_queryset = (
AModel.objects.
raw(raw_query="""
SELECT *
FROM "order"
INNER JOIN "user" on ("order"."order_owner_id" = "user"."id")
WHERE "user"."username" = %(name_param1)s
"""),
params={"name_param1": "name_test"}
).
prefetch_reladted('product_set_included_order')
)
# 위의 Raw 쿼리셋과 아래 쿼리셋은 동일한 SQL 문을 수행
a_model_queryset = (
AModel.objects.
select_related('order_owner').
filter(order_owner_username='name_test').
prefetch_related('product_set_included_order')
)
9) 서브쿼리 발생 조건 : QuerySet In QuerySet
- 서브쿼리를 사용하면 slow query 가 야기됨
실수 예제
- django ORM에서 서브쿼리를 발생시키는 옵션을 주지 않고 발생되는 예제
company_queryset = Company.objects.filter(id__lte=20).values_list("id", flat=True) # 아직 SQL문 실행안됨
product_queryset = Product.objects.filter(product_owned_company__id__in=company_queryset)
# company_queryset 은 product queryset안으로 들어가는 시점에도 아직 queryset 상태임
# 그래서 product queryset과 company_queryset 이 합쳐져서 수행하게됨.
select * from product
where "product"."product_owned_company_id" in (
select U0."id" from "company" U0
where U0."id" <= 20
);
해결방법 예제
- list 묶어서 querset을 바로 수행
company_queryset = list(Company.objects.filter(id__lte=20)) # SQL 수행됨.
product_queryset = Product.objects.filter(product_owned_company__id__in=company_queryset)
# 첫번째 SQL
select * from company
where "company"."id" <= 20;
# 두번째 SQL
select * from product
where "product"."product_owned_company_id" in ('첫번째 SQL 실행 결과')
10) 서브쿼리 발생 조건 : .exclude() 조건절의 함정
- 역방향참조모델을 filter()절에 넣어서 JOIN을 유도함 (의도한SQL이 정상적으로 수행됨)
역방향 참조 모델에서.exclude() 조건 절 사용시 서브쿼리 발생- 역방향 참조 모델을 exclude()절에 넣어서 JOIN을 유도. 서브쿼리 발생
- ~Q() 절로 바꿔서 filter()절에 넣어줘도 여전히 서브쿼리 발생
- 이런경우 JOIN으로 풀리게 유도하는 것이 불가능해서 차선책으로 prefetch_related(Prefetch()) 를 사용하는 방식으로 대체
정방향참조모델은 exclude()절에 넣어서 JOIN을 유도하면의도한SQL수행
11) values() values_list() 사용시 주의점 : EagerLoading 옵션 무시
-
values(),values_list() 사용하면 해당 QuerySet에 주어진 select_related(), prefetch_related()옵션들을 전부 무시
- 단 select_related (join) 하려면 values()안에 join해야지만 가져올 수 있는 데이터를 명시해야지 join 을 함.
11-1) select_related(), prefetch_related()옵션들 전부 무시는 어찌보면 당연한 결과
-
values(), values_list()를 사용하면 아래와 같은 DB Raw단위로 데이터를 반환한다
- Object(객체)와 Relational(관계지향) 간에 Mapping(매핑)이 일어나지 않는다.
-
ORM EagerLoading이란 개념의 구현체인 select_related()&prefetch_related()
는 DB Raw단위로 데이터를 조회하는 values() values_list() 에서는 무의미한 옵션

자동화 개발