
row 번호 지우기
read_csv() 할 때, usecols = [ ] 불러올 컬럼들 지정
index_col = False 인덱스 열 지정을 하면서 제대로 데이터를 불러올 수 있다.
data = pd.read_csv(data_path, usecols = ['HOUSE'], index_col = False)착각했던 것이! 아래의 붉은 부분은 행이 아니었다...
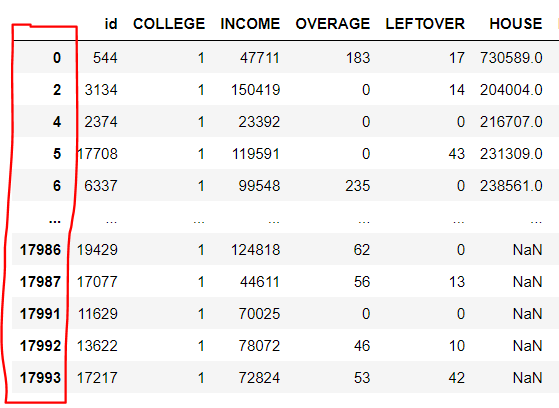
결과 부분을 저장할 때에 저기 저 보이는 부분을 저장하고 싶지 않으면
to_csv()에서 index = False라고 지정하면 가능하다.
new = data.to_csv('new.csv', index = False)하고 저장을 하면 짜잔! index 번호는 없이 저장이 완료된다.
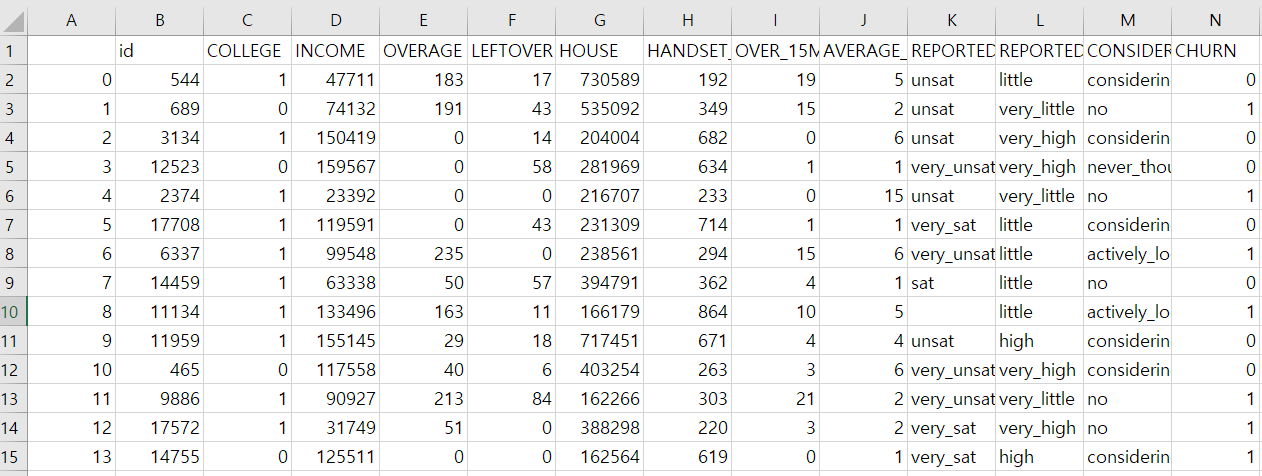
하기 전
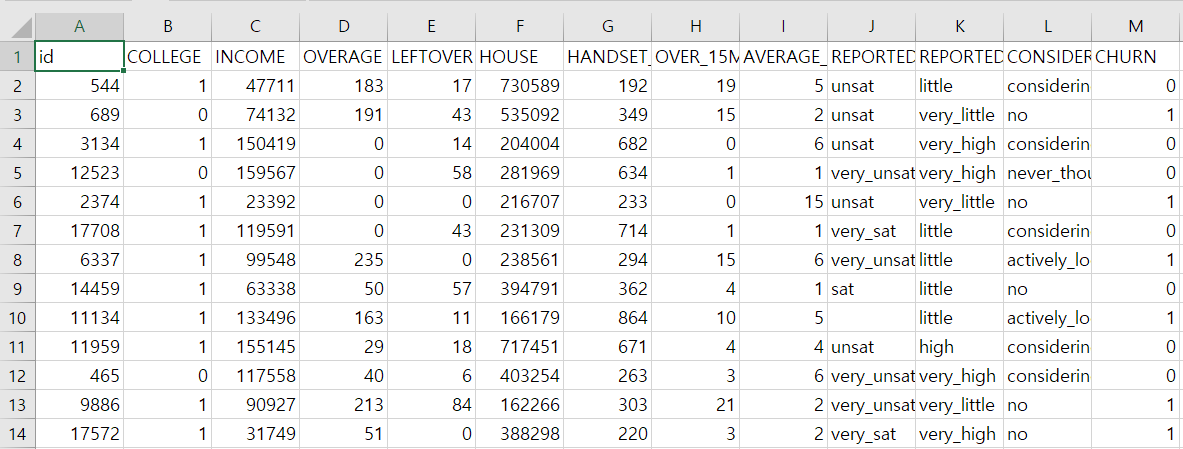
하고 나서
조건에 맞는 행들만 모아서 보기
data.loc[data['COLLEGE'] == 1] 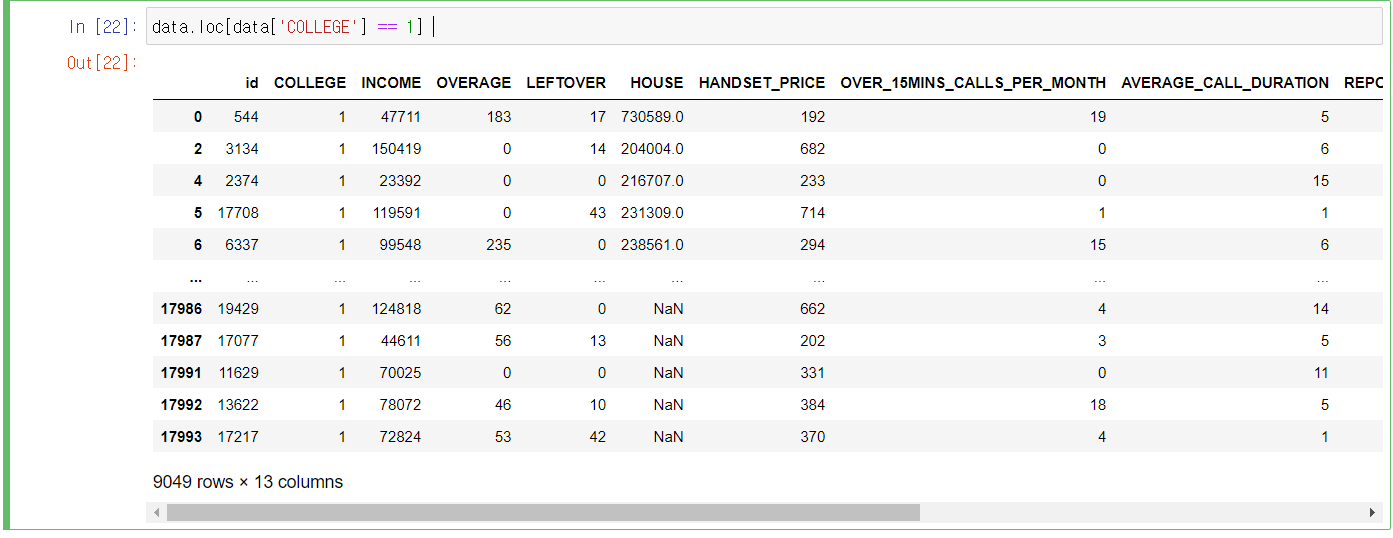
numpy 배열로 보고 싶을 때, np.where(조건문)
dataframe으로 보고 싶을 때, data.loc[조건문]
컬럼 이름 변경하기
전체 변경
df.columns = ['이름', '나이', '성별']일부 변경
df.rename(columns = {'name':'이름'}, inplace = True)인덱스를 설정하기
df.set_index('컬럼 이름')
df2 = df.set_index('사용일자')
df2.head(3)설정 전
설정 후
다시 설정 전으로 바꾸는 방법
df.reset_index(inplace = True)
끝까지 가자!
아자아자!!