
📍목차
- 서버의 개요
- 서버의 수신 동작
- 웹 서버 소프트웨어가 리퀘스트 메시지의 의미를 해석하여 요구에 응한다
- 웹 브라우저가 응답 메시지를 받아 화면에 표시한다
1️⃣ 서버의 개요
본 포스팅은 패킷이 웹 서버 앞의 방화벽/캐시 서버/부하 분산 장치 등을 거친 후 웹 서버 안으로 들어와서 일어나는 일들에 대해 다룬다.
서버는 동시에 복수의 클라이언트와 통신을 하게 되는데, 이때 서버가 클라이언트와의 대화가 어디까지 진행되었는지 파악하기 어렵기 때문에 하나의 프로그램으로 여러 클라이언트들의 상대를 처리하는 것이 어렵다.
따라서 클라이언트가 접속할 때마다 새로운 서버 프로그램을 가동시켜 클라이언트와 1 대 1로 대화하는 구조가 일반적이다.
이에 착안하여 서버 프로그램의 구조를 살펴보면 아래와 같다.
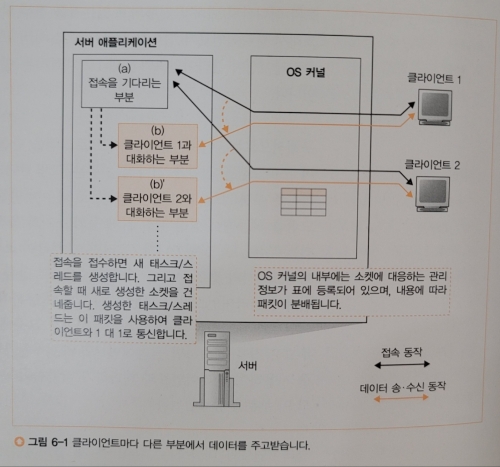
접속을 기다리는 부분과 클라이언트와 대화하는 부분으로 이루어지며,
서버 프로그램을 작동해 초기화가 끝나면 접속을 기다리는 부분을 실행하고,
이후 클라이언트가 접속하면 클라이언트와 대화하는 부분을 작동시켜 접속을 마친 소켓을 통해 통신을 시작한다.
서버 OS의 멀티 태스크 혹은 멀티 쓰레드라는 기능을 통해 이와 같이 동시에 여러 클라이언트와 통신할 수 있게된다.
이어서 각 부분의 구체적인 동작에 대해 알아보자.
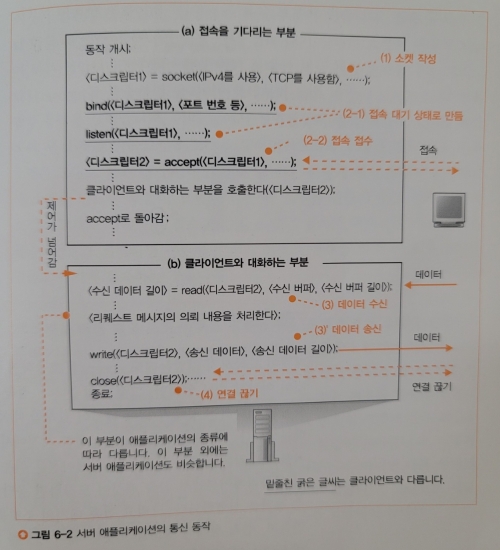
접속을 기다리는 부분
socket()을 호출해 소켓을 생성한다.bind()를 호출해 소켓에 포트 번호를 기록한다.
이때 포트 번호는 클라이언트가 서버측에 할당한 포트 번호이다.listen()을 호출해 클라이언트의 접속을 기다린다.accept()를 호출해 접속 접수 동작을 실행한다.
패킷이 도착하지 않아도 이를 호출하는데, 패킷이 도착하지 않는다면 도착을 기다리는 상태로 전환된다.패킷이 도착하면, 접속 대기 상태의 소켓을 복사한다. 이를 클라이언트와 대화하는 부분에 넘긴다.
클라이언트와 대화하는 부분
여기서는 read() write() close()를 통해 데이터 송수신을 진행하는데,
이 과정은 네트워크(1)에서 프로토콜 동작 과정과 마찬가지로 동작한다.
✔️ 소켓을 복사한다고 했는데, 그러면 포트 번호가 중복되는 것 아닌가?
포트 번호는 소켓을 식별하기 위한 것이므로, 접속 대기 상태의 소켓을 복사하면 동일한 포트 번호의 소켓이 중복된다는 문제점이 발생한다.
설령 포트 번호를 다르게 할당하더라도, 클라이언트가 요청한 상대로부터 응답받은 패킷이 맞는지 판별할 수 없다는 문제가 있다.
이를 해결하기 위해,
소켓을 지정할 때 클라이언트 IP, 서버 IP, 클라이언트 포트 번호, 서버 포트 번호를 사용해 구별한다.
추가적으로 "그러면 네 가지 정보로 모든 소켓을 구분할 수 있는데 디스크립터는 왜 써?" 에 대한 의문을 가질 수 있으나,
소켓을 만든 직후 클라이언트가 접속하지 않은 상태에서는 네 가지 정보가 준비되지 않기 때문에 디스크립터는 필요하다.
또한, 디스크립터라는 한 개의 정보로 식별하는 것이 훨씬 간편하다.
2️⃣ 서버의 수신 동작
앞서 서버의 구조를 살펴봤고, 서버의 수신 동작에 대해 전체적으로 살펴보자.
LAN 어댑터
클라이언트가 보낸 패킷을 서버의 LAN 어댑터에서 수신한 부분부터 살펴보자.
LAN 어댑터는 패킷의 신호를 디지털 데이터로 바꾸는데, 이때 패킷의 신호는 디지털 데이터의 신호와 클록 신호를 합성한 것이, 신호 변환 방식은 아래와 같다.
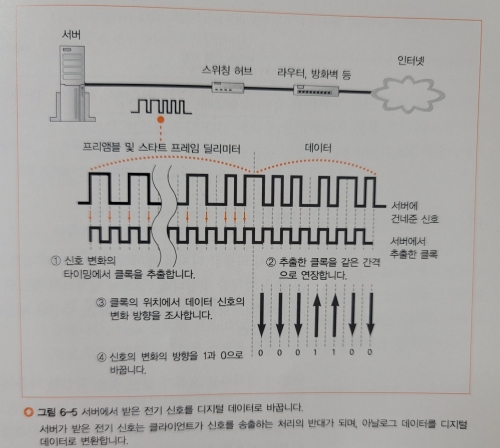
이와 같이 클록의 신호를 통해 패킷을 디지털 데이터로 변환한 뒤, 패킷 맨 끝의 FCS를 통해 데이터의 오류 유무를 검사한다.
FCS는 클라이언트가 패킷을 송신할 때 디지털 데이터를 바탕으로 계산한 값이며, 수신측에서 신호를 변환하며 계산식을 적용해 FCS와 비교하여 일치한다면 수신하고, 일치하지 않는다면 변형된 데이터로 간주하여 버리는 원리이다.
FCS와 일치한다면, MAC 헤더의 수신처 MAC 주소를 조사하여 자신이 수신처가 맞는지 판단한다.
이더넷의 기본 원리는 LAN 전체에 신호를 보내기 때문에, 이 과정이 필요하다.
수신처가 자신이 아니라면 패킷을 폐기한다.
자신이 수신처가 맞다면, 디지털 데이터를 LAN 어댑터 내부의 버퍼 메모리에 저장한다.
여기까지가 LAN 어댑터의 MAC 부분이 수행하는 역할이다.
즉, LAN 어댑터의 MAC 부분이 패킷을 신호로부터 디지털 데이터로 변환하고, FCS를 점검한 후 버퍼 메모리에 저장한다.
인터럽트
위 과정이 진행되는 동안, CPU는 패킷의 존재를 인지하지 못한 채 다른 일을 수행 중이다.
따라서 수신 처리가 진행되지 못하므로 LAN 어댑터에서 이를 알리는데, 이때 인터럽트를 사용한다.
인터럽트를 통해 CPU에게 패킷의 도착을 알리면, CPU는 수행하던 작업을 멈추고 LAN 드라이버를 실행한다.
그러면 LAN 드라이버는 LAN 어댑터의 버퍼 메모리에서 패킷을 추출하고, MAC 헤더에 기록된 값에 따라 프로토콜을 판별하여 해당 프로토콜을 처리하는 프로토콜 스택을 호출한다. 이어서 프로토콜 스택에 패킷을 전달한다.
LAN 어댑터는 인터럽트를 발생시켜 CPU를 통해 프로토콜 스택에 패킷을 전달한다.
IP 담당 부분
이렇게 프로토콜 스택에 패킷이 전달되면, 우선 IP 담당 부분이 동작하여 IP 헤더에서 수신처 IP를 조사해 자신이 수신처가 맞는지 점검한다.
이때 서버에 라우터 기능이 활성화된 경우에는, 라우팅 테이블에서 중계 대상을 판단해 그곳에 패킷을 전달한다.
자신이 수신처가 맞다면, 패킷이 분할되었는지 조사한다.
패킷이 분할된 경우에는 메모리에 일시적으로 저장한 후, 모든 패킷 조각이 모였을 때 패킷을 합친다.
이어서 IP 헤더의 프로토콜 번호를 조사해 해당 부분에 패킷을 건네주는데,
TCP 담당 부분에 패킷을 건네주는 경우를 예로 들어 동작을 살펴보자.
프로토콜 스택의 IP 담당 부분은 IP 헤더를 점검해 자신이 수신처인지 판단하고, 패킷의 분할 여부를 조사한 뒤 TCP 혹은 UDP 담당 부분에 패킷을 전달한다.
TCP 담당 부분
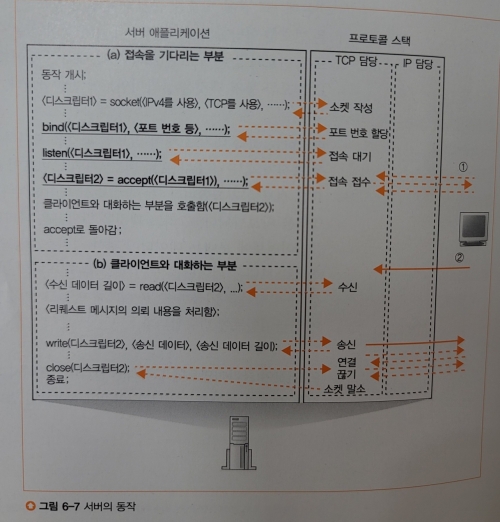
접속 동작의 패킷
TCP 헤더의 SYN 값이 1이라면 이는 접속 동작의 패킷이다.
가장 먼저, 수신처 포트 번호를 조사하여 해당 번호의 소켓이 있는지 확인하고, 없다면 패킷을 폐기한다.
소켓이 존재한다면, 해당 소켓을 복사하여 IP, 포트 번호, 시퀀스 번호 등의 제어 정보를 기록하고 메모리 영역또한 확보한다.
또한 패킷을 수신했음을 알리기 위한 ACK 번호와 시퀀스 번호, 윈도우 값 등을 기록한 TCP 헤더를 만들어 IP 담당 부분에 송신을 의뢰한다.
이후 클라이언트로부터 ACK 번호가 돌아오면 접속 동작이 완료된다.
TCP 담당 부분은 SYN 비트를 통해하여 접속용 패킷인지 확인한 후, 수신처 포트 번호를 조사한 뒤 접속 대기 소켓을 복사하여 제어 정보를 기록한다.
데이터 패킷
접속 단계를 마치고, 데이터 송수신 단계에서 TCP 담당 부분은 송수신처의 IP 주소와 포트 번호가 일치하는 소켓을 찾는다.
소켓을 발견하면, 소켓에 기록된 제어 정보와 패킷의 TCP 헤더 정보를 비교해 송수진 동작의 정상 여부를 판단한다.
이는 구체적으로 소켓에 기록된 시퀀스 번호와 데이터 조각의 길이를 통해 다음 시퀀스 번호를 계산하고, 도착한 패킷의 TCP 헤더에 기록된 시퀀스 번호를 비교하는 과정이다.
상태가 정상이라면, 패킷에서 데이터 조각을 추출해 메모리 영역에 저장한다.
이때 지난 패킷에서 수신한 데이터 조각에 연결하는 형태이다.
이후 수신 확인 응답용 TCP 헤더를 만들어 IP 담당 부분에 의뢰해 클라이언트에게 반송한다.
데이터의 패킷을 수신한 경우, TCP 담당 부분은 송수신처의 IP, 포트 번호를 통해 소켓을 찾아 데이터를 수신하여 저장한다. 이후 클라이언트에게 ACK를 반송해 수신했음을 알린다.
다음으로는, 애플리케이션이 read()를 호출해 메모리 영역에 저장된 데이터를 가져와 HTTP 리퀘스트 메시지를 조사하고 데이터를 브라우저에 출력하는 동작이 이어진다.
3️⃣ 웹 서버 소프트웨어가 리퀘스트 메시지의 의미를 해석하여 요구에 응한다
프로토콜 스택의 read()가 수행되면, HTTP 리퀘스트 메시지를 읽는다.
HTTP 메서드나 URI의 내용에 따라 작업 내용은 매우 다양하며, 서버 내부의 동작이 달라진다.
가상 디렉토리
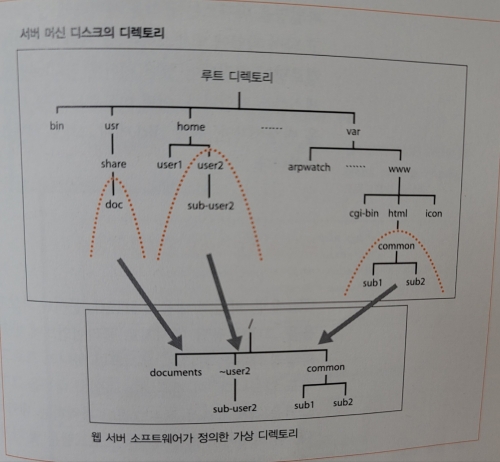
이때 URI에 기록된 경로명의 파일을 읽어오면 디스크의 파일이 모두 노출되므로,
웹 서버에서 공개하는 디렉토리는 실제 디렉토리명을 가상 디렉토리명으로 변환하는 과정을 거친다.
액세스 제어
웹 서버의 기본 동작은 리퀘스트 메시지에서 데이터 출처를 판단하고, 그곳에서 클라이언트에게 반송한다는 것이다.
그러나 사전에 설정해 둔 조건에 해당하는지 조사하고, 해당하는 경우에만 이후 동작을 수행하는 기능을 액세스 제어라고 한다.
주요 조건은 아래와 같다.
1. 클라이언트의 IP
가장 단순한 방식으로, accept()를 통해 파악한 클라이언트의 IP와 조건으로 설정한 IP와의 일치 여부를 판단한다.
2. 클라이언트의 도메인명
클라이언트측에서 DNS 서버를 통해 도메인명으로부터 IP를 알아낼 수 있듯이, 서버측에서는 역으로 IP로부터 도메인명을 파악하는 과정을 거쳐 조건과의 일치 여부를 파악한다.
그러나 DNS 조회 과정에서 메시지의 왕복 시간이 늘어나 응답 시간이 길어진다.
3. 사용자명과 패스워드
보통 리퀘스트 메시지는 사용자명이나 패스워드를 포함하지 않으므로, 웹 서버가 사용자명과 패스워드를 보내도록 클라이언트에게 요구한다.
브라우저가 이 메시지를 받으면 사용자명과 패스워드를 입력할 수 있는 화면을 표시하는 원리이다.
사전에 설정된 사용자명과 패스워드를 클라이언트가 입력한 값과 대조하여 접근 여부를 판단한다.
4️⃣ 웹 브라우저가 응답 메시지를 받아 화면에 표시한다
웹 서버가 응답 메시지를 보내면 패킷이 분할되어 클라이언트에게 도달하고, 클라이언트 또한 위에서 살펴본 과정을 거친다.
즉, LAN 어댑터가 신호로부터 디지털 데이터로 변환한 후 프로토콜 스택이 분할된 패킷을 모아 데이터를 추출한다.
이후 응답 메시지를 브라우저에게 건네고, 브라우저의 화면 표시 동작이 진행된다.
이때 데이터의 종류에 따라 표시 과정이 다르기 때문에, 데이터의 종류부터 판단해야한다.
데이터 종류 판단 근거
대표적인 데이터의 종류 판단 근거로는 응답 메시지 헤더의 Content-Type 값을 이용하는 것이다.
text/html과 같은 형식으로 나타나며, 왼쪽은 주 타입, 오른쪽은 서브 타입을 의미한다.
Content-Type을 조사한 경우 Content-Encoding도 조사해야하는데, 특정 기술로 원래 데이터를 변환한 경우 이곳에 기록해야하기 때문이다.
그러나 Content-Type에 값이 올바르게 설정되지 않는 경우가 있는데, 이런 경우 파일 확장자나 데이터 포맷 등을 종합적으로 보고 판단하기도 한다.
예를 들어 파일의 확장자가 .html이거나 데이터가 <html>으로 시작한다면 HTML 문서로 판단하는 것이다.
데이터 종류를 파악했다면, 화면 표시 프로그램을 호출해 데이터를 표시한다.
HTML, 일반 텍스트, 화상 등의 기본적인 데이터는 브라우저가 자체적으로 화면 표시 기능을 가지며,
OS에게 화면의 어디에/무엇을/어떤 글꼴로 표시할지 명령한다.
브라우저가 자체 표시 기능을 가지지 않는 경우에는,
데이터의 종류에 따라 데이터 표시를 위해 호출하는 프로그램이 정해져있으며, 해당 프로그램에 데이터를 건네면 화면에 표시되는 과정을 거친다.
👏 마무리
이로써 시리즈 포스팅을 통해 브라우저에 URL을 입력하고 응답 메시지를 화면에 노출하는 순간까지의 과정을 모두 알아봤다.
7주간 스터디를 통해 꾸준히 시간을 투자한 덕에 흐름이 끊기지 않고 네트워크의 큰 흐름을 파악할 수 있게 되었다.

그런데, 이제 디테일을 곁들인.
다른 일정과 병행하다보니 꽤나 타이트하게 공부했던 것같다.
그 사례로 네트워크(2)는 존재하지 않는걸 알 수 있는데... 해당 포스팅은 시간이 부족해 글의 퀄리티가 낮아 비공개 처리해뒀기때문이다.
빡빡한 시간 속에 놓쳤던 디테일들을 채워넣기 위해선 꾸준한 복습과 N회독이 필요해보인다.
어쨌거나, 막학기에 들어서서야 처음으로 CS를 각잡고 하게됐는데, 좋은 스터디원들과 훌륭한 성과를 거둬서 뿌듯하다.
이제 OS도 비슷한 방식으로 공부할 것 같다. 앞으로도 파이팅이다.
해당 포스팅을 보신 분도 파이팅하시고, 열람해주셔서 감사합니다!🙏
참고 자료
💕좋아요와 댓글은 큰 힘이 됩니다.💕
