들어가기 전에
‘크롤링’ 과 ‘스크래핑’은 뜻이 다르고 이 글은 ‘스크래핑’을 다루고 있습니다. 그러나 이 글을 찾아보는 분들은 두 단어의 차이점을 잘 모르는 비전공자들일 것이라 생각했기 때문에 이 글에서는 크롤링이라고 하겠습니다.
selenium은 사용하지 않습니다. 왜 why? 주기적으로 스크래핑하는 경우에는 속도가 많이 느려집니다. ( 저의 경우는 동적 웹페이지나 자동화 등 꼭 필요한 경우가 아닌경우에는 잘 사용하지 않습니다 )
이 글에서는 라이브러리에 대한 설명/설치 과정, html 파싱 과정은 자세히 다루지 않습니다. 제가 생각하는 효율적인 구글 검색의 크롤링 방법과 오류 해결 과정만 적었습니다.
구글 검색 사이트 구조 파악
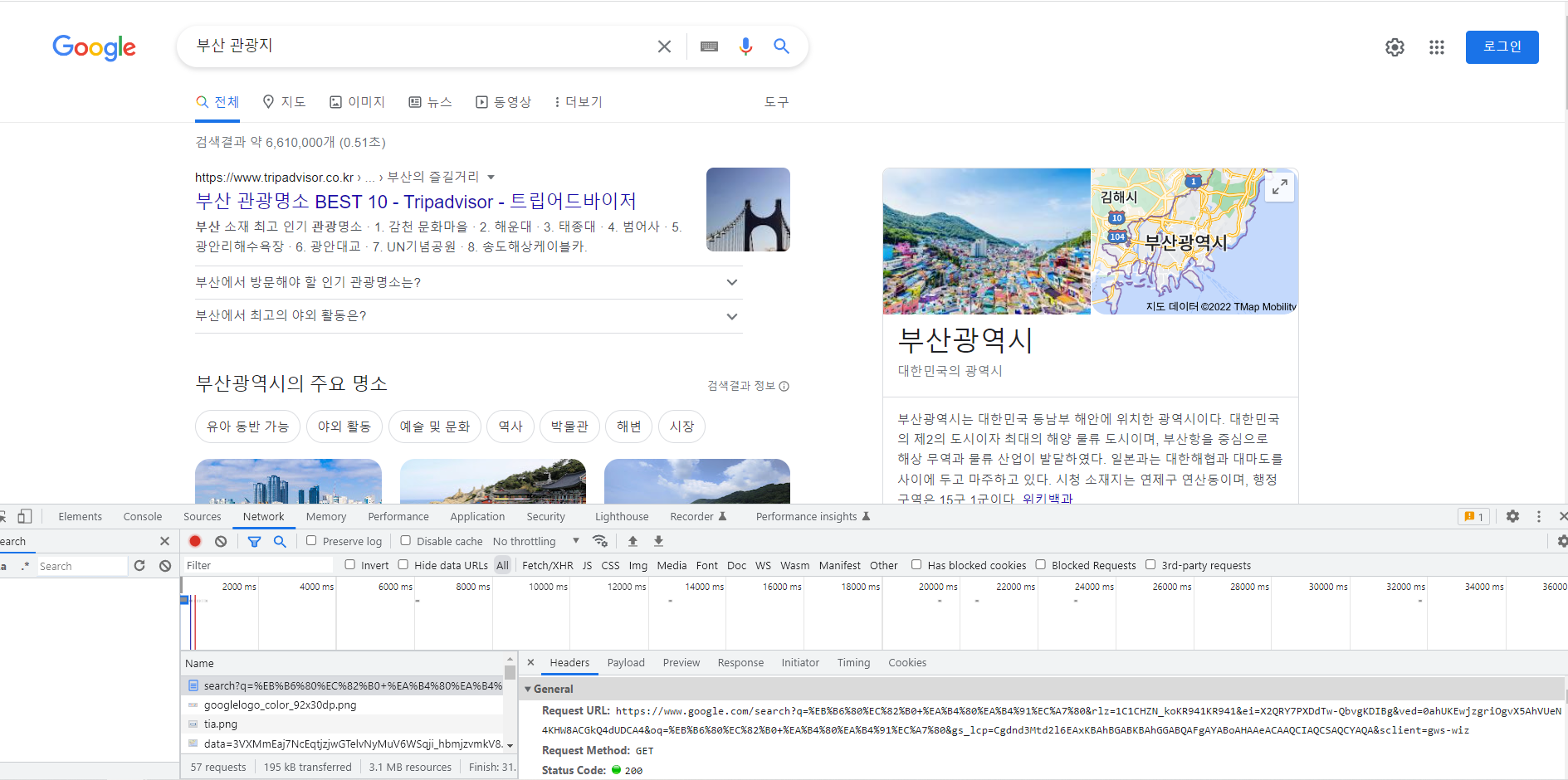
크롬을 열고 F12 버튼을 누르면 개발자 도구가 나옵니다. 이 상태에서 구글에 검색을 하고 Network 탭으로 들어가면 해당 페이지의 type이 document인 파일이 나옵니다. 이 파일이 검색했을 때 나오는 정보를 담고 있고, 우리가 얻어야되는 파일입니다. Requeest Method가 GET으로 되어있는 것을 보고 request get을 해야겠다고 생각했습니다.
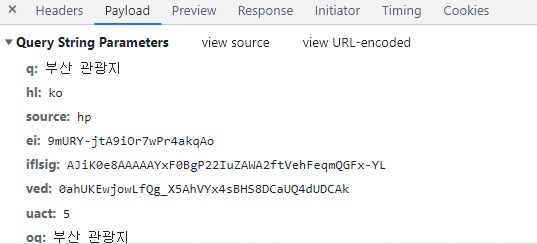
다음은 쿼리 스트링을 확인해야 됩니다. q는 검색어, hl은 ko인 것을 보아 언어인 것을 확인했습니다.
여기서 뉴스탭만 눌러봅니다. 그러면 tbm이라는 쿼리에 nws라는 값이 들어갑니다. 이미지 탭의 경우 tbm이 isch인것을 확인할 수 있습니다.
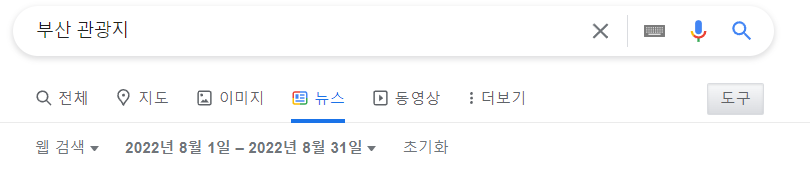
그리고 뉴스 탭에서 기간을 설정해봅니다. 그러면 tbs에는 설정된 기간이 들어간 것을 확인했습니다.
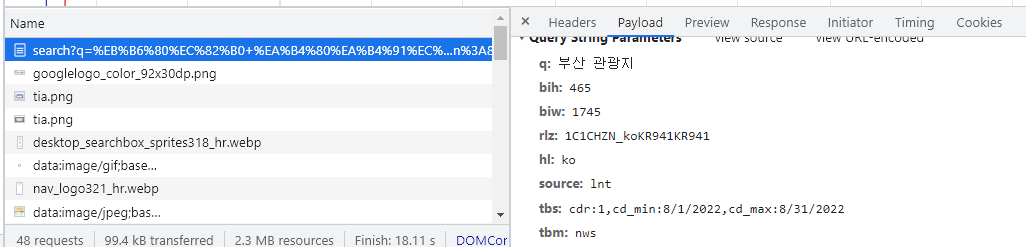
- q : 검색어
- hl : ko ( 언어 )
- tbm : nws ( 유형 )
- tbs : ( 기간 )
- start : 10 ( 뒤에 나오게 될 테지만 이 파라미터는 몇 페이지인지를 나타냅니다. 10은 2페이지 입니다. )
크롤링 ( 특정 콘텐츠, 특정 날짜, 특정 페이지 데이터 수집 )
- 구글 검색 특정 콘텐츠만 검색하기 ( 이미지, 뉴스, 동영상, 지도 등 )
- 특정 날짜에 해당하는 콘텐츠만 검색하기
- 특정 페이지만 가져오기
import requests
import lxml
from bs4 import BeautifulSoup as bs
from datetime import datetime라이브러리는 requests, lxml, BeautifulSoup, datetime을 사용했습니다.
start_date = datetime(2022,8,1)
start_date = str(start_date)[:10]
end_date = datetime(2022,8,31)
end_date = str(end_date)[:10]
cd_min = start_date[6:7] + '/' + start_date[8:10] + '/' + start_date[:4]
cd_max = end_date[6:7] + '/' + end_date[8:10] + '/' + end_date[:4]
tbs = f'cdr:1,cd_min:{cd_min},cd_max:{cd_max}'datetime 날짜 형식은 tbs의 형식에 맞게 무식한 방법으로 바꿔주었습니다.
search = '부산 관광지'
params = {'q' : search , 'hl' : 'ko', 'tbm' : 'nws', 'tbs' : tbs}
header = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36'}
url = 'https://www.google.com/search?'
res = requests.get(url, params = params, headers = header)
print(res)
print(res.text)params 인자에 q, hl, tbm, tbs를 넣어줍니다.
headers 부분에 user-agent를 넣어 로봇이 아니라고 어필해줍니다. 이게 빠져있으면 차단당합니다.
url은 아까 F12로 확인했떤 request url에서 q앞부분까지 넣어줍니다.
이렇게 하면 <Response [200]> 라고 나오지만 가져온 내용은 정상적이지가 않을 것입니다.
왜 그런 문제가 발생할까요
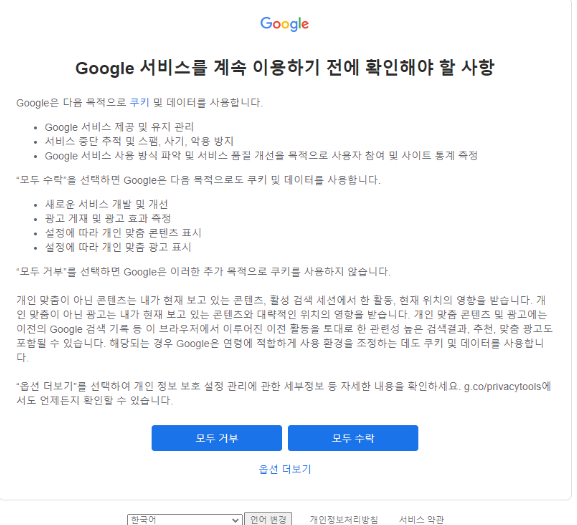
구글에서 쿠키 수집에 동의 하냐는 페이지를 보내기 때문입니다. 따라서 저는 쿠키 정보에 동의한다는 정보를 쿠키에 담아서 전송할 겁니다. cookie = {'CONSENT' : 'YES'} 라는 쿠키 데이터를 만들고 request get에 인자로 넣어줍니다.
search = '부산 관광지'
params = {'q' : search , 'hl' : 'ko', 'tbm' : 'nws', 'tbs' : tbs}
header = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36'}
cookie = {'CONSENT' : 'YES'}
url = 'https://www.google.com/search?'
res = requests.get(url, params = params, headers = header, cookies = cookie)
soup = bs(res.text, 'lxml')
# 기사제목 파싱하는 부분
list = soup.find_all('div', 'mCBkyc y355M ynAwRc MBeuO nDgy9d')
for i in list:
print(i.get_text())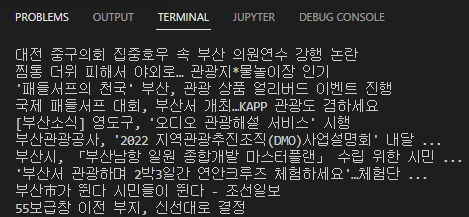
성공적으로 기사들의 제목이 파싱되는것을 확인했습니다.
마지막으로 특정 페이지만 가져와보겠습니다.
페이지를 2페이지 3페이지 … 계속 넘기다 보면 start라는 파라미터가 바뀌는 것을 볼 수 있는데,
2페이지는 start가 10, 3페이지는 start가 20이었습니다. 그렇다면 4페이지는 start가 30이 아닌가 싶어서 params = {'q' : search , 'hl' : 'ko', 'tbm' : 'nws', 'tbs' : tbs, 'start' : '30'}
동일한 코드에 start : 40을 파라미터에 넣어주면 4페이지가 가져와진 것을 확인할 수 있습니다.
잘못된 정보가 있거나 질문이 있으시다면 댓글이나 이메일로 말씀해주시면 감사하겠습니다.
