구글 검색 스크래핑 하는데 단순히 검색만 하는게 아니라 뉴스 선택하고 기간까지 선택해서 스크래핑 해야해서 selenium을 쓰거나 쿼리문을 조작해야되는데 셀레니움보다는 beautiful soup가 더 빠르기 때문에 실시간으로 정보 계속 받아올거라서 soup로 해결할 방법 찾아야함.
chrome으로 Google 리퀘스트 쿼리문을 봤을 때는 
이렇게 나와서 parameter 만들어서 넘겨줬는데

안됨...
그런줄 알았는데? 되는거였음 request.url 불러와보면 삼성전자로 검색했을때 뉴스탭으로 이동한게 보임
기간은 tbs 값 만들어서 넣어줬더니

잘됨
근데 왜 html중에서 css만 있지?....
ㅜ래ㅑ누댜루나우레ㅐㄴ두 왜 정상적인 html이 아닐까
로봇 크롤링 막아놓은거 같다는 생각이 들었음 user-agent 설정만으로는 속일 수가 없나?..
그냥 셀레니움 써야될거 같은데
보니까 쿠키 쪽에서 문제가 생긴듯 쿠키 생성 안돼서 값이 안넘오나? 그래서 requests에 cookie 만들어서 넘겼는데도 똑같은 문제가 발생
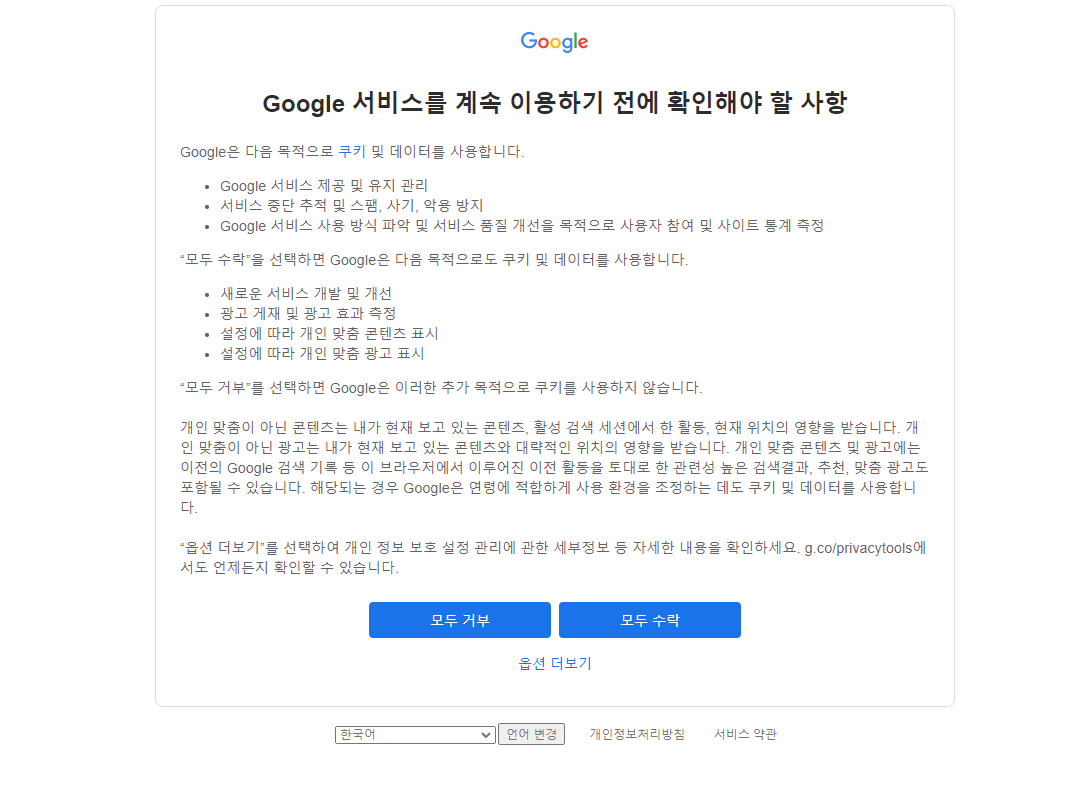
그런건 아닌거 같고 html 찾아보니까 이런 페이지가 떠서 여기 해당하는 html을 불러오는 거였다...
url로 접근할때는 저게 안떴는데
저거 안뜨게 하는 방법 없나
스택오버플로우 찾다가 발견함 ㅠㅠㅠㅠㅠ 역시 스택오버플로우
https://stackoverflow.com/questions/70560247/bypassing-eu-consent-request
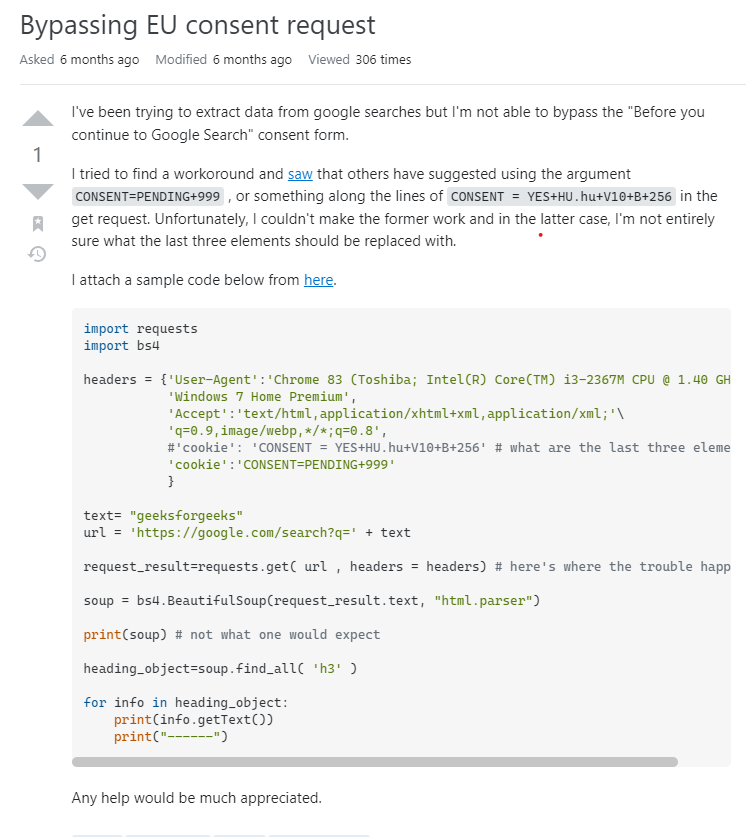
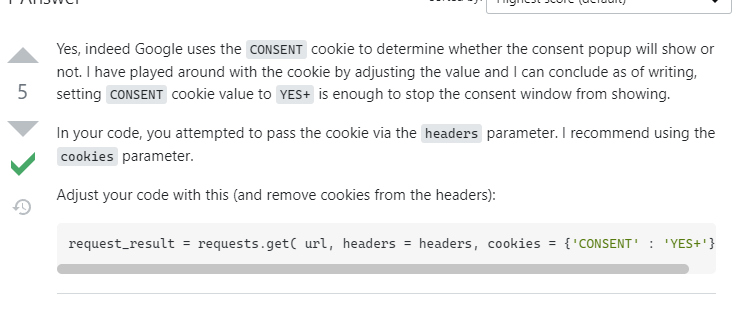
쿠키값에 consent yes 넣어주니까 해결됐음

삼성전자로 검색한 기사들 가져와지는거 확인
이제 정규표현식 써서 데이터 정제하고 KoNLPy 써서 명사 추출한다음 ( 복합어 등록하는 작업이 필요함.. 오래걸릴듯 ) 빈도수 계산해서 키워드분석 하면 될듯
