뉴스 스크래핑 해서 어디다가 쓸까
1) 주식의 오르내림이 뉴스에도 영향을 받는다. 이런 매매를 재료매매, 테마매매라고 한다. 뉴스의 재료와 거래량, 가격을 보고 수요와 공급이 변하는 것이다.
2) 주식이 수요와 공급에 의해서 움직인다는 것은 이미 밝혀진 사실이고 뉴스가 재료를 만들고 재료로 인해 급격한 수요와 공급이 충분히 변할 수 있다고 판단했다. 나의 판단이 맞는지 확인하려면 텍스트 분석과 주가의 상승을 같이 분석해야 하는데... 텍스트 분석을 하기전에 뉴스들을 저장해놔야 하므로 스크래핑이 필요하다.
○ 구글 뉴스 페이지 구조
< 구글 뉴스탭에서 삼성전자를 검색했을 경우 >
구글 뉴스탭에서 삼성전자를 검색한 후 크롬 개발자 도구(F12) Network탭을 확인한 결과 얻을 수 있는 정보 1) Request 방식이 GET방식이다. 2) Reuqest URL이 https://www.google.com/search?이다.
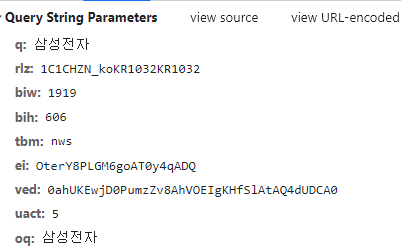
개발자도구를 확인해보면 요청 URL과 파라미터를 확인할 수 있다.
tbm이 nws인 것으로 보아서 뉴스탭을 지정하는 것을 알 수 있고 q는 삼성전자인 것으로 보아서 검색어이다.
그리고 중요한 게 있는데, 주가의 가격 변동과 뉴스의 시간을 일치시키기 위해서는 특정 기간안의 뉴스들만 가져올 필요도 있다.

구글 검색에서 기간을 설정하면 확인가능한 파라미터이다.
cd_min과 cd_max부분에 날짜를 넣으면 되는 것을 확인했다.
충분한 정보를 얻었으니 코드를 작성
○ 코드
import requests # get 요청 도와주는 라이브러리
from bs4 import BeautifulSoup as bs # 파싱 도와주는 라이브러리
from datetime import datetime #날짜 라이브러리 start_date = datetime(2022,8,1)
end_date = datetime(2022,8,31) # 주식데이터는 시계열이라서 index가 datetime 형태임
start_date = str(datetime.date(start_date)) #날짜 형식만 문자열로 변환
end_date = str(datetime.date(end_date))
# cd_min과 cd_max 형태에 맞게끔 문자열 생성
cd_min = start_date[6:7] + '/' + start_date[8:10] + '/' + start_date[:4]
cd_max = end_date[6:7] + '/' + end_date[8:10] + '/' + end_date[:4]
search_name = '삼성전자' #검색어
params = {'q' : search_name, 'hl' : 'ko', 'tbm' : 'nws', \
'tbs' : f'cdr:1,cd_min:{cd_min},cd_max:{cd_max}'} # 파라미터 딕셔너리 생성
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/84.0.4147.135 Safari/537.36'}
# get 요청 보냄
res = requests.get(url, params = params, headers = headers, cookies = {'CONSENT' : 'YES+'})
print(res.url)
print(res.text)코드에서 제일 중요한 부분은 request 할 때 요청인자로 cookies = {'CONSENT' : 'YES+'}를 넣어주는 것이다. 안 넣으면 스크래핑이 안된다.
이유는 구글 스크래핑 시행착오 여기를 참고
url과 html을 잘 가져온 것을 확인할 수 있다.
다음은 스크래핑을 할 차례이다.

AI로 사회에 긍정적인 영향을 줄 수 있는 개발자가 되기 위해 성장하고 있습니다.