논문 링크 : https://arxiv.org/abs/1906.03731
Summary
- Attention weight가 prediction에 얼마나 많은 영향을 줄까?
- Attention weight가 큰 순서로 ranking을 매긴 후, 큰 weight를 조정한 후에 결과를 관찰해 보겠다.
- 대부분의 경우 결과에 영향이 없다.
- 그렇기 때문에 attention weight로 decision에 대한 interpretation을 하는 것은 모순이다.
- 하지만 이 논문은 classification 모델에만 적용했기 때문에 기계번역같은 큰 model에 적용하여 증명한다면 좋은 연구가 될 것이다.
Abstract
- Attention mechanism은 NLP의 Performance를 크게 올림.
- Attention layer가 input component들에 weight를 줌
- 우리는 attention weight를 조정했을때(already-trained text classification) prediction 결과가 어떻게 바뀌는지 알아볼 것이다.
- higher attention weights가 model prediction에 큰 impact를 준다고 알고 있지만 그렇지 않다.
1. Introduction
- Attention을 interpretation으로 사용한 과거 연구들이 많다.
- attention weight가 predict에 큰 영향을 주는지 보기 위해 intermediate representation을 지워볼 것이다.
- attention weight는 intermediate components의 변수일 뿐 decision에 대한 정당화가 될 수 없다.(즉, interpretation X)
2. Testing for Informative Interpretability
- 모델을 해석할 수 있으려면 납득할 수 있는 설명을 제시해야 할 뿐만 아니라 그러한 설명이 모델의 결정에 대한 이유를 설명해야 합니다.
- Attention weight에 중요도에 랭킹을 주고 시각화 $ L $
- 그렇다면 attention weight의 중요도 순위가 결과를 잘 설명?
2.1 Intermediate Representation Erasure
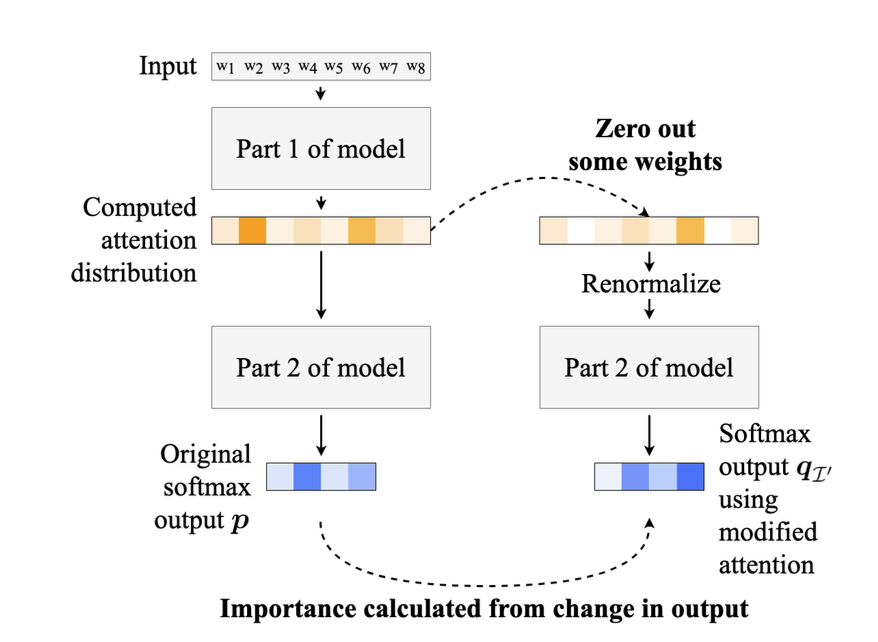
- input이 이미 해석할 수 없을 정도로 변했을 수 있는 중간 component를 봄으로써 상대적으로 낮은 interpretable을 함.
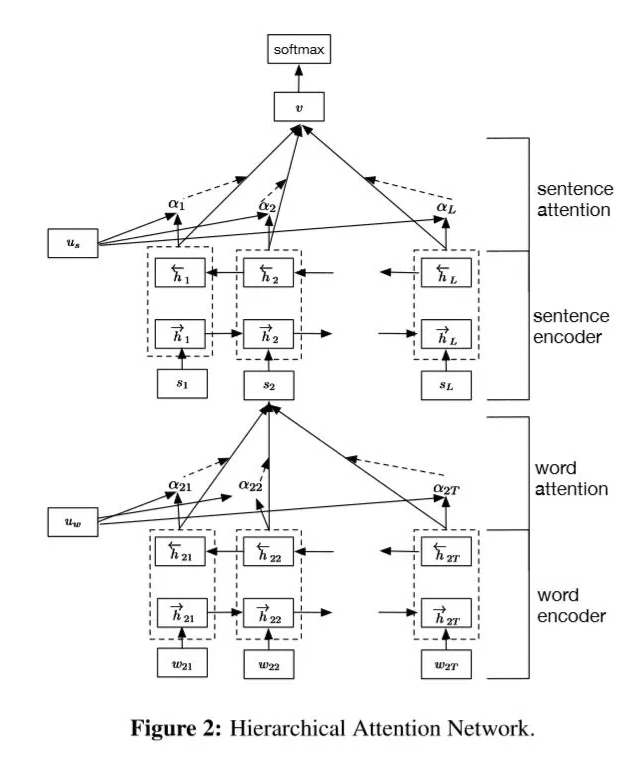
- Classification model(Hierarchical Attention Network) 변형
- some attention weights zeroed out
- Renormalize
- Output distribution의 차이
- Original distribution :
- Erase attention for
- Jensen-Shannon(JS) divergence & Decision flip 을 통해 두개의 분포 비교
3. Data and Model
- Dataset
- Yahoo Answers, IMDB, Yelp 2017, Amazon
- Model
- Hierarchical Attention Network(HAN; Yang et al., 2016)
- HAN architecture에서 변화하는 것 2가지
1) Number of attention layers - 'flat' attention networks 추가
2) Reach of encoder contextualization
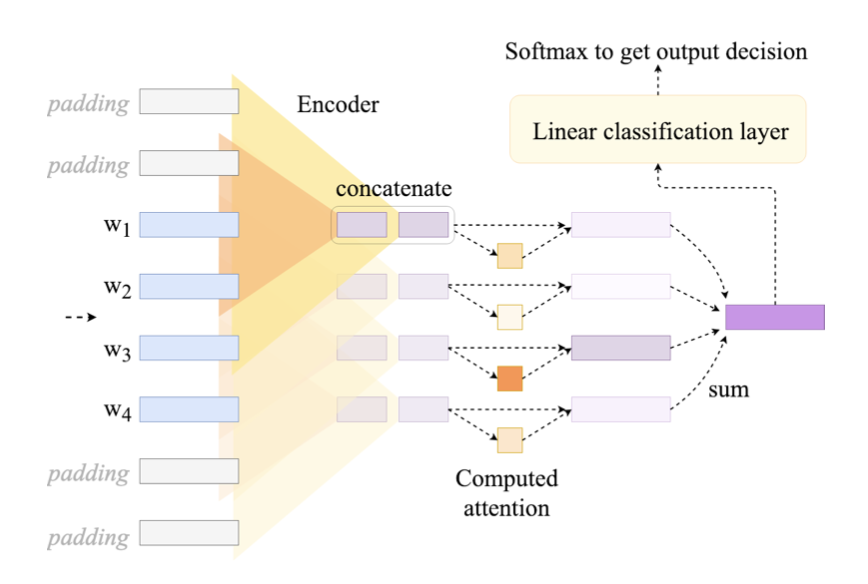
- original HAN network는 attention layer전에 recurrent encoders사용(bidirectional GRU)
- Flat attention architecture에 아이디어를 얻은 모델로 실험
4. Single Attention Weights' Importance
- 하나의 attention weight만 제거
- $ i^* \in L $ -> component with the highest attention
- $ \alpha_i^* $ -> attention
- $ i^* $ 를 두가지 방법으로 중요도를 평가
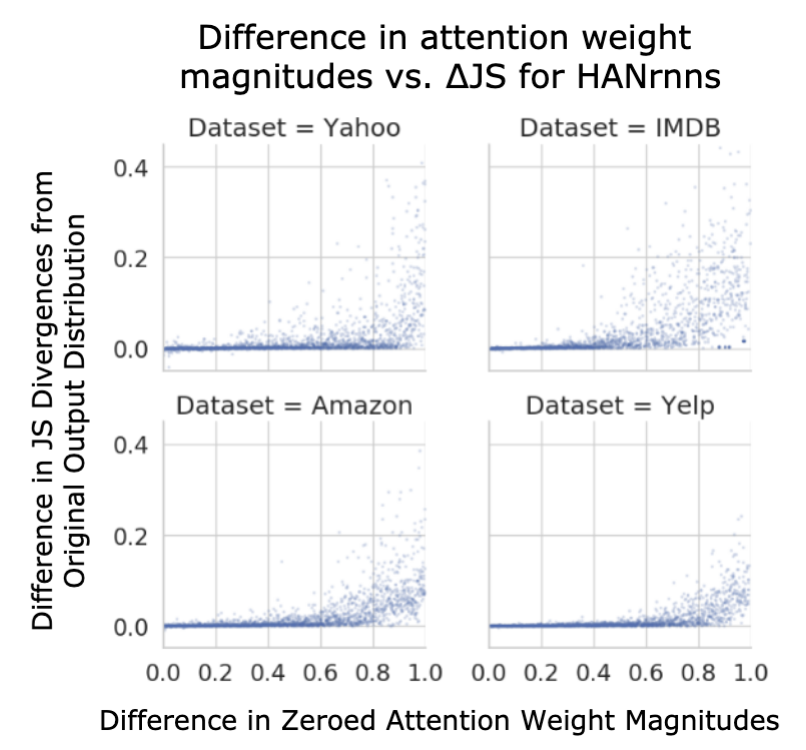
4.1 JS Divergence of Model Output Distributions
- 과 의 중요도 비교
- 은 에서 uniform하게 뽑은 원소
- 을 제거한 output distribution과 을 제거한 output distribution을 비교
- =
4.2 Decision Flips Caused by Zeroing Attention

- blue -> remove 했을때 flip decision
- orange -> remove 했을때 flip decision
5. Importance of Sets of Attention Weights
- 어떠한 attetion이 중요한가? 에 대한 서술내용
- weight를 어떻게 바꾸었을 때 classification이 바뀌었는가?
6. Limitation
- text classification에만 초점이 맞춰져있음
- language model이나 machine translation에는 적용 못함.
7. Conclusion
- attention이 모델 해석을 위한 도구라고 하는 경우가 많지만 반드시 중요성과 일치하지 않는다.
- 즉, attention의 importance ranking으로 모델 decision을 설명할 수 없다.

주피터...