1. SCM (Structural Causal Model)
인과관계를 명시하기 위한 모델로, PCH (Pearl's Causal Hierarchy) 세 계층을 모두 만들어 낼 수 있다.
Notation
: Random Variable
: Value of the variable, where
: State space of variable z
Bold letters for sets of variables or values, V and v
Caligraphy for complex mathematical objects, e.g.
1.1 Probability Review
1) Marginalization
인과추론에서 가장 많이 사용하는 확률론적 성질로, Bayesian Network를 다룰 때 보통 많이들 사용하고, SCM 에서도 Causal Bayesian Network 로 인과 모형을 구성하기에, 꼭 알아두어야 하는 성질이다.
2) Conditional Probability
인과 모델에서의 변수 간 조건부 독립을 많이 고려하는 인과 추론의 특성 상, 조건부 확률은 Must-Know 라고 할 수 있음.
3) Chain Rule
임의의 joint distribution 는 로 나타낼 수 있다.
(Product Rule) 의 일반화 된 공식으로서 위와 같이 나타낼 수 있다.
그외에도 Sum of Products 또한 마찬가지로 중요하나, 이 글에선 생략하도록 하겠다.
2. Simpson's Paradox
2.1 Case Study : Drug with Allergic Reaction
ML, Causal Inference 등에서는 데이터가 생성되는 과정에 있어, 어떠한 모델에서 결정되지 않는 외생 변수 (Exogenous Varaible) 이 미리 결정되고,
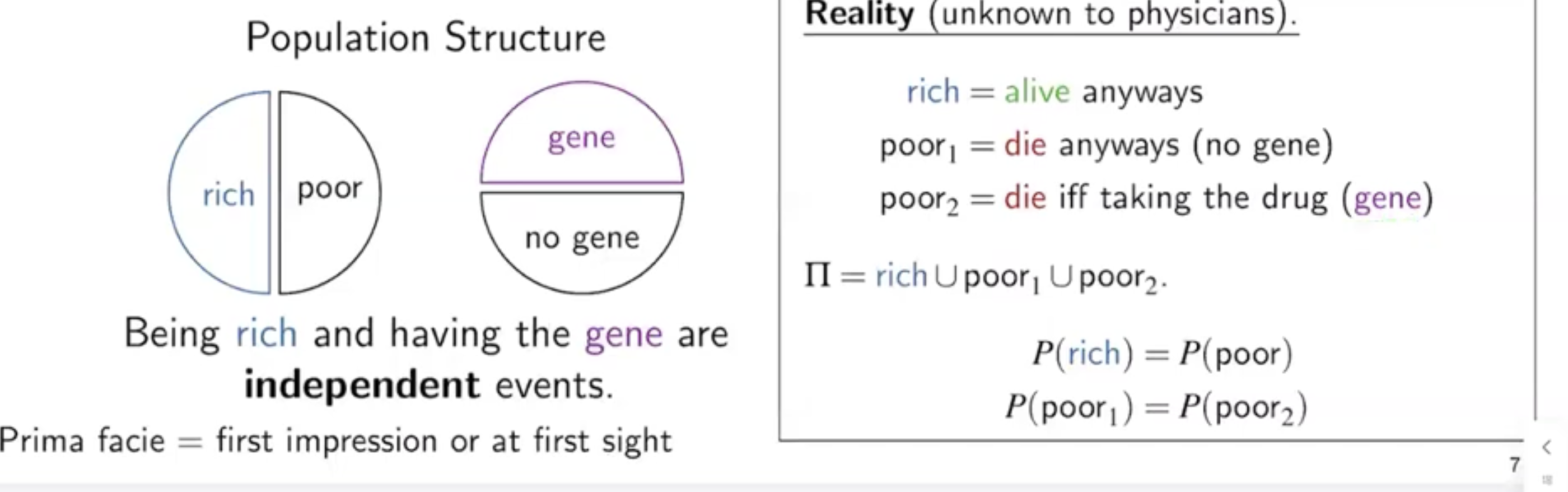
학자들에게 알려지지 않았지만, 감염으로부터 사람을 구한다고 믿어지는 약이 존재한다고 하자.
우리가 알 수 없는 Reality 가 다음과 같을 때, 우리는 이를 어떻게 나타낼 수 있을까?
Current Protocol
rich prescribe to the drug
rich don't prescribe to the drug
이때, 약의 비용이 높기 때문에 약사들은 위의 같은 정책으로 약물을 복용시킨다고 할 때 로, 약물을 복용시키는 것이 더 유리해보일 수 있음.
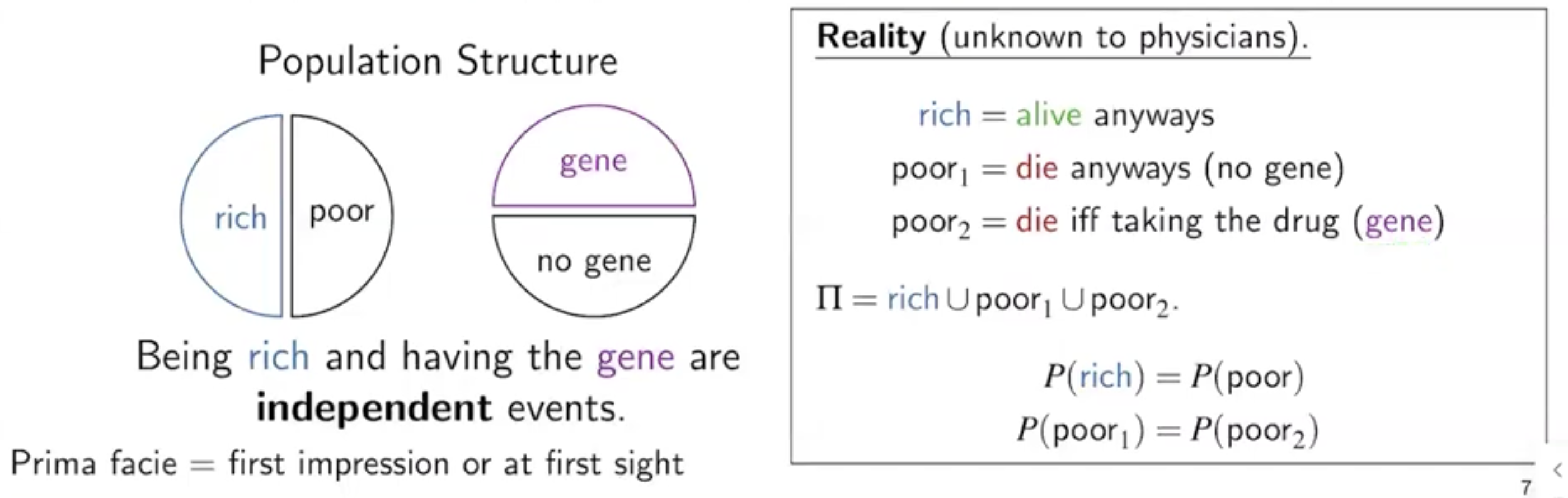
하지만 실제론 아래와 같이, drug 유무를 conditioning 했을 때 다른 결과를 얻을 수 있다.
이때, do-operation은 실험적으로 해당 값으로 강제 했음을 뜻하고, 아래의 diagram 을 통해 시각적으로 이해할 수 있다.
(곧, 우리가 데이터셋에서 관찰한 데이터가 아니라, 실험적으로 만들어진 데이터)
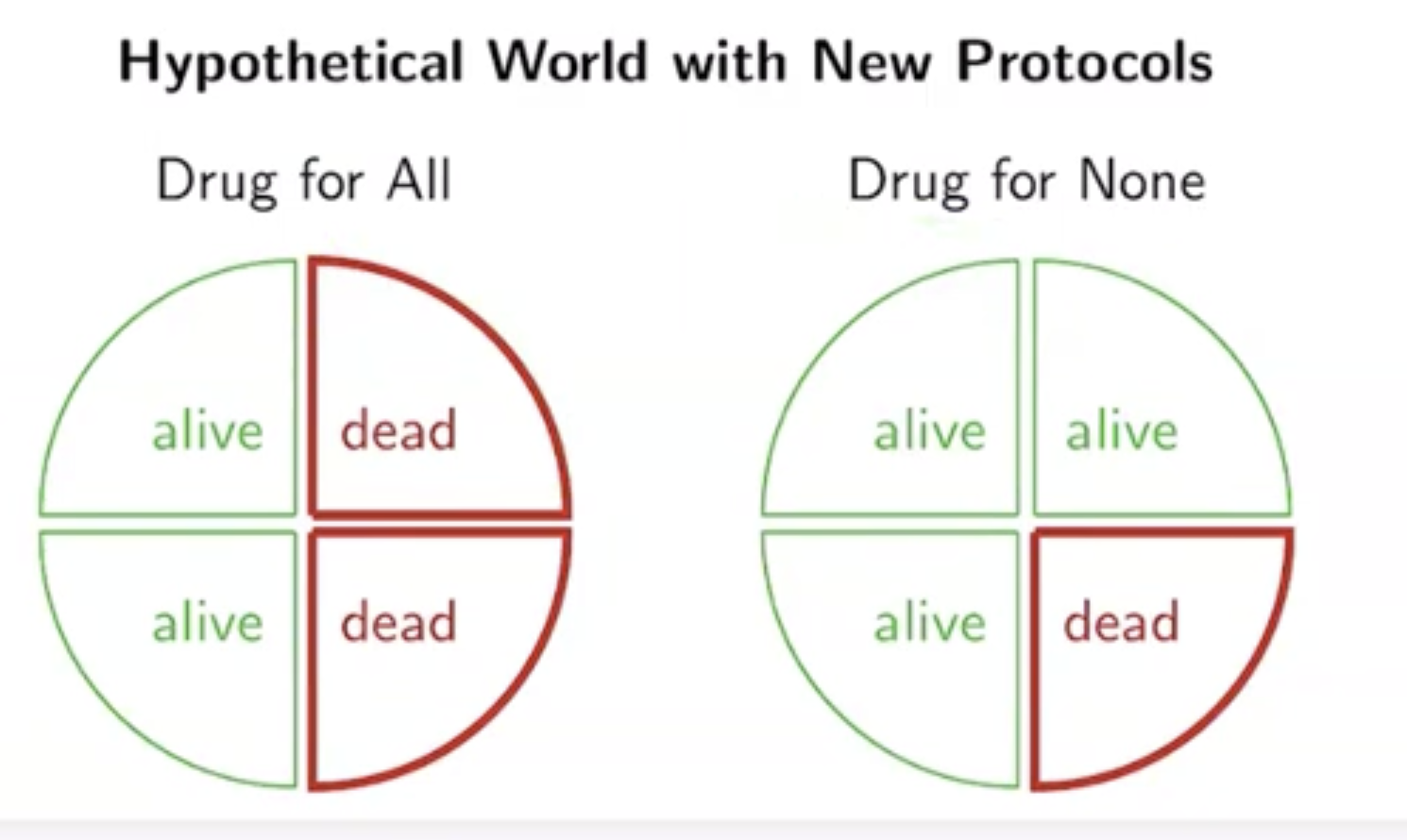
Q. 진정으로 약물을 복용하는 것이 더 좋은가?
A. 우린 그렇지 않다고 쉽게 결론 내릴 수 있다. 부자의 경우 약물을 복용하든 하지 않든 생존률이 동일하며, 가난한 이의 경우 오히려 생존률이 0으로 모두 죽는다.
전체 집단에선 더 좋아 보이지만 개별 부분 집단에선 반대의 결과가 나타나는 걸 우린 Simpson's Paradox 라고 하는데, 이는 각 집단 별로 약물을 섭취하는 데에 선택 편향(Selection Bias)이 발생하기에 이러한 문제가 생기는 것이다.
2.2. Modeling for given case

주어진 데이터셋에서 다음과 같이 변수를 선언하자. 이때, 우리는 다음과 같은 규칙이 성립함을 알 수 있다.

이때 각 unobserved variables 에 대한 확률은 다음과 같다고 가정하자.
where
주의 : 물론 현실에서는 우리는 이러한 Ground Truth Model 를 모른다고 가정한다.
3. Structural Causal Model
3.1 Definition of SCM (Structural Causal Model)

SCM 의 수학적 정의는 위와 같다.
간략하게 말해서, 관찰 가능한 변수 집합 의 원소들은 관찰 불가능한 변수 집합 에 의해 deterministic 하게 결정된다고 가정한다.
e.g)
Endogenous 모델에 의해 결정되는 값들
Exogenous 모델 바깥에서 결정되는 값들
는 쉽게 말해, 해당 변수 를 결정 짓는데에 직접적인 영향 (인과 관계) 을 주는 변수 집합이라 볼 수 있다.
(이렇게만 보면 말이 어려운데, 원인결과 형태로 그래프로 나타내었을 때, 원인이 되는 변수들을 모아둔 게 라고 보면 됨.)
나중에 Local Markovian Property 랑 엮어서, Chain-Rule 에서의 given condition 변수를 획기적으로 줄일 수 있음.
(아직은 이해하지 않아도 됨. 그렇다고 우선 받아들일 것)
이러한 인과관계를 그래프로 나타내면 아래와 같다.
는 PCH 에서의 Layer 1 에 해당한다고 볼 수 있다.
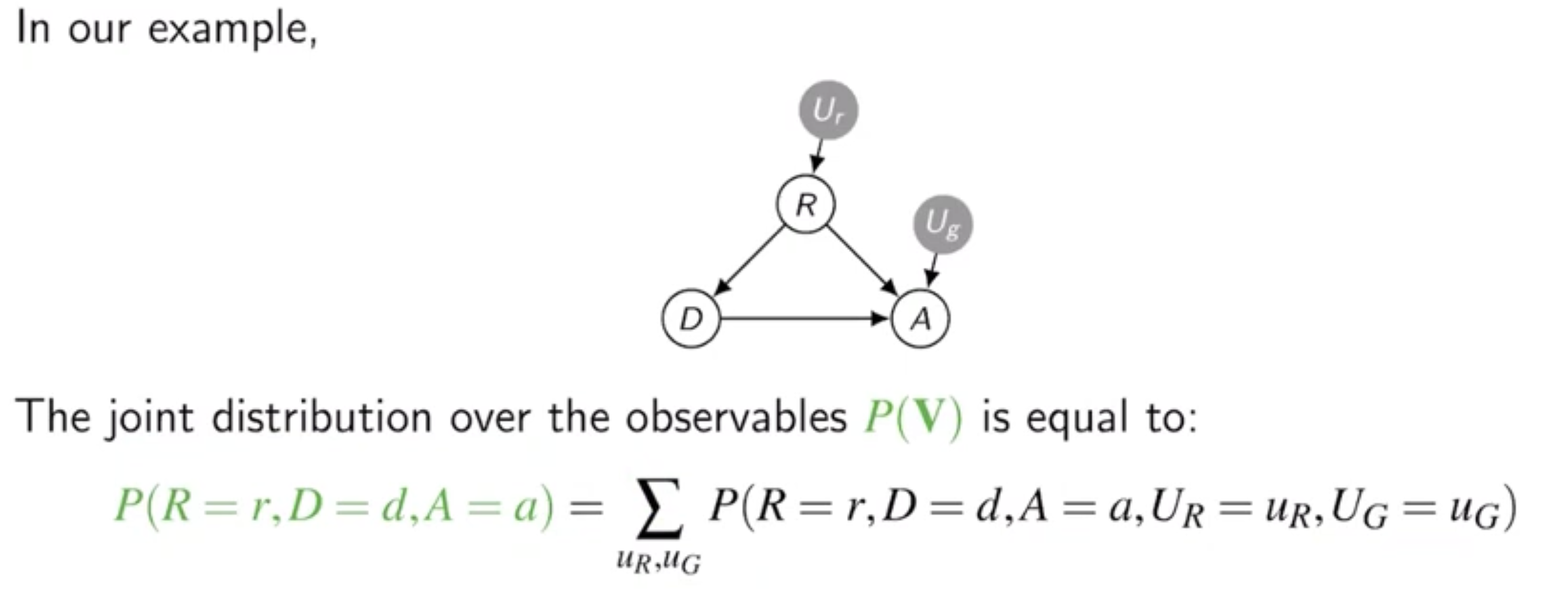
3.2 SCM of drug with allergic reaction example

여기서 함수 집합 F는 주어진 외생(Exogenous) 변수 집합 U와, 다른 내생(Endogenous) 변수의 값에 의해 결정론적으로 생성된다.
이로 인해 P(V)는 아래와 같이 결정된다.
| R=1,D=1,A=1 | R=0,D=0,A=1 | R=0,D=0,A=0 |
|---|---|---|
3.3 Causal Diagram
Causal Diagram 이란, 변수들 간의 인과관계를 나타내는 방식으로, 관찰 가능한 변수에 대해서만 표현한다.
(자료구조 에서의 Directed Acyclic Graph (DAG) 로 모델링 한다)
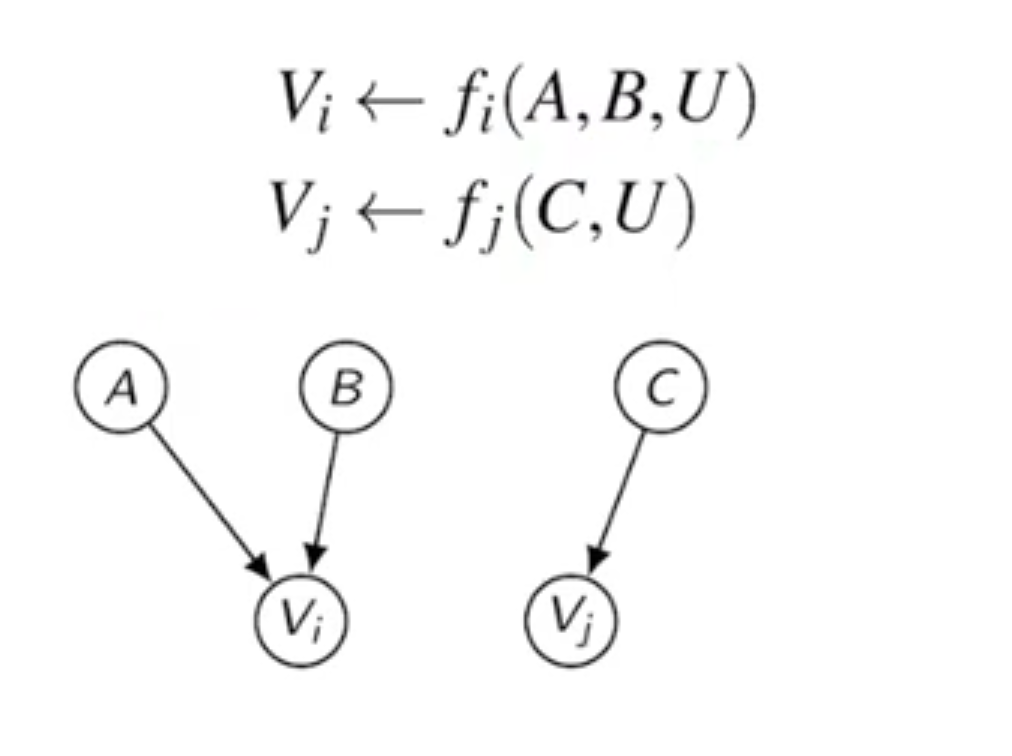
이때 양 변수 에 양 방향으로 영향을 주는 미관찰 변수 U를 포함하여 고려하여 함수에 표기한다.
엄밀하게는 와 에 영향을 주는 각 미관측 변수들에 상관관계가 있을 때
곧 를 만족할 때 아래와 같이 표기함.
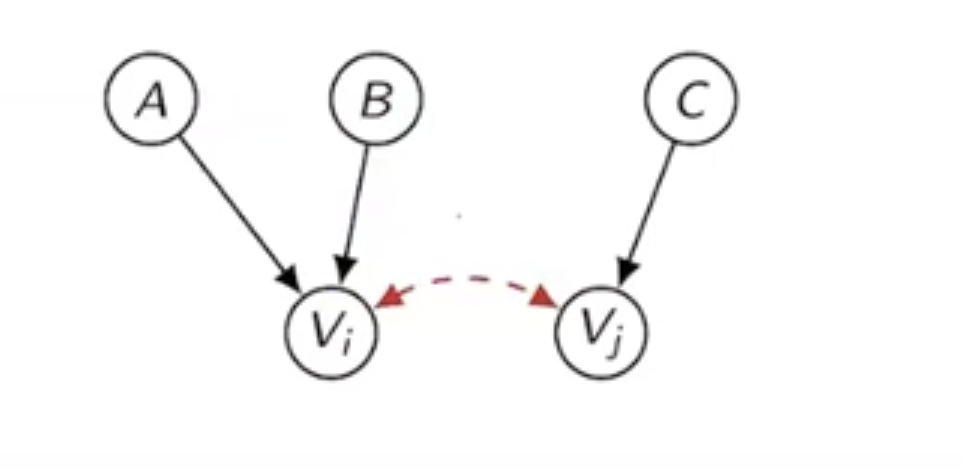
저런 내생 변수들에게 동시에 영향을 미치는 변수들을 Confounder 라고 일컬으며, 여기선 특히 관찰 불가능한 변수 이므로 Unobserved Confounder 라고 말한다.
이러한 변수들이 존재할 때, 상관관계와 인과관계를 구분하기 어려워지므로, 명확하게 알고 넘어가야 한다.

앞서 Section 2 에서 다룬 Causal Diagram 을 그림으로 나타내면 다음과 같다.

물론 Unobserved variable 은 보통 제거하지만, 이해를 위해 다음과 같은 형태로 표기한 것. (U를 생략하는 걸 Left-Implicit Convention 이라 함.)

이러한 인과 그래프를 우리는 자료구조에서 배운 DAG 로 모델링 하기에, 용어는 위와 같이 동일하게 정의 내린다.
이처럼 SCM 을 만들고 나서, 우리는 "어떻게" Layer 1 확률 분포 ()를 만들어낼 수 있을까?
Marginalization 을 활용하여 Joint-Distribution 을 Marginal-Distribution 으로 변환한다.
이때, DAG 에서, topological ordering (위상적 순서) 순으로 열거하여 Chain-Rule 에 따라 표기하게 되면, 결국 한 노드가 결정 되는 것은 자신의 부모에 의해 결정되기 때문에 given condition 에서 부모 노드만 남기면 되는데, 이때 Chain-Rule 에서의 변수상의 순서를 위해 위상 정렬을 수행하는 것.
